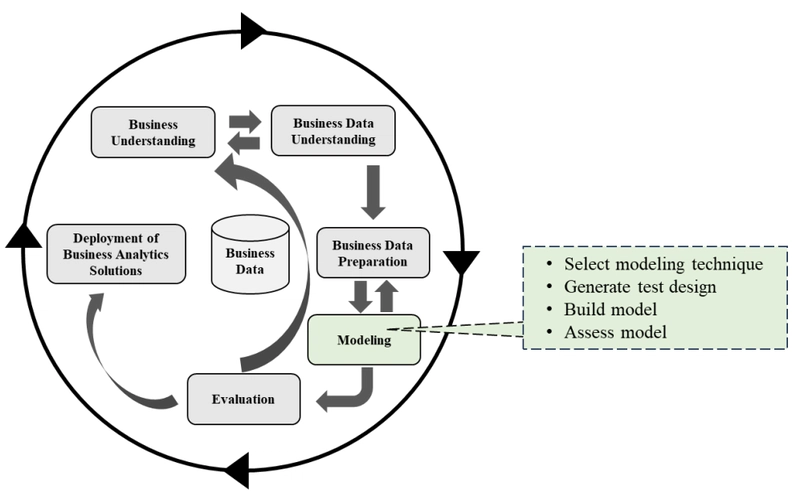
📈 Fase 4: Modeling (Modelagem)
O objetivo principal da fase de Modelagem é construir e avaliar modelos (descritivos ou preditivos) que abordem os objetivos de negócio e de mineração de dados definidos nas fases iniciais. Envolve selecionar as técnicas analíticas apropriadas, aplicar essas técnicas aos dados preparados, calibrar parâmetros e gerar um ou mais modelos.
A fase de Modelagem foca em selecionar e aplicar diversas técnicas de modelagem para construir e calibrar modelos que abordem os objetivos de negócio e de mineração de dados definidos anteriormente. A escolha da técnica é o primeiro passo essencial nesta fase.
É importante notar que a fase de Modelagem é iterativa. Pode ser necessário voltar à fase de Preparação dos Dados (Fase 3) se a técnica de modelagem escolhida tiver requisitos específicos sobre o formato ou a qualidade dos dados que não foram totalmente atendidos. Além disso, a avaliação inicial dos modelos construídos (tarefa 4.4) pode levar à necessidade de ajustar parâmetros e construir novos modelos, criando um ciclo interno de construção e avaliação dentro desta fase.
📝 Principais tarefas dentro da fase de Modelagem
-
Select Modeling Technique (Selecionar Técnica de Modelagem): Nesta primeira etapa, a técnica ou algoritmo específico a ser utilizado é selecionado. Embora uma ferramenta possa ter sido escolhida na fase de Compreensão do Negócio, esta tarefa foca na técnica em si, como regressão logística, árvores de decisão, redes neurais, k-means, ARIMA, Naive Bayes, SVM, entre outras. A escolha da técnica depende do tipo de problema de mineração de dados (por exemplo, classificação, regressão, clustering, análise de associação) e das características dos dados. É crucial estar ciente das suposições que a técnica de modelagem faz sobre os dados (como qualidade, formato ou distribuição). A fase de modelagem pode (e muitas vezes deve) incluir modelos descritivos mais simples, especialmente quando os objetivos de negócio não exigem técnicas preditivas complexas.
- Exemplo: Para prever se um cliente fará churn (uma variável categórica), você pode selecionar técnicas como árvores de decisão ou regressão logística. Se o objetivo for identificar grupos de clientes semelhantes, você selecionaria uma técnica de clustering como o k-means. Para identificar produtos frequentemente comprados juntos, a análise de associação é a técnica adequada.
- Exemplo: Quantidade de Produtos Vendidos por Fornecedor.
- Exemplo: Produtos com Ordem de Compra vs. Produtos Faturados (últimos 3 meses). Objetivando analisar eficiência no atendimento de pedidos através de uma taxa de conversão de pedidos em faturamento.
- Exemplo: Descobrir quais produtos são frequentemente comprados juntos em um supermercado online. Escolher a análise de associação, utilizando algoritmos como Apriori. Entender que a análise de associação busca regras de relacionamento e requer dados em formato de transações.
-
Generate Test Design (Gerar Desenho de Teste): Antes de construir o modelo, é fundamental definir um procedimento ou mecanismo para testar sua qualidade e validade. Para tarefas de mineração de dados supervisionadas, como classificação, medidas como taxas de erro são comuns. Um componente primário deste plano é decidir como dividir o conjunto de dados disponível em conjuntos de treinamento, teste e, possivelmente, validação. O modelo é geralmente construído no conjunto de treinamento e avaliado em um conjunto de teste separado para estimar sua qualidade em dados não vistos. Práticas comuns incluem divisões aleatórias de 80%/20% ou 70%/30%. Técnicas como validação cruzada (k-fold) também fazem parte do desenho de teste para garantir que o modelo generalize bem.
- Exemplo: Dividir o conjunto de dados de clientes em um conjunto de treinamento (80%) para ensinar o modelo de churn e um conjunto de teste (20%) para avaliar quão bem ele prevê churn em novos dados. Planejar o uso de validação cruzada de 10 folds para treinar e testar um modelo de regressão, garantindo uma avaliação mais robusta do desempenho.
-
Build Model (Construir Modelo): Esta tarefa envolve executar a ferramenta ou algoritmo de modelagem no conjunto de dados preparado (geralmente o conjunto de treinamento) para criar um ou mais modelos. Envolve a configuração e ajuste dos parâmetros do modelo. O processo de construção é frequentemente iterativo, com refinamento contínuo para alcançar o melhor desempenho possível. Os resultados da mineração de dados podem necessitar de pós-processamento (como edição de regras ou exibição de árvores).
- Exemplo: Executar o algoritmo de árvores de decisão no conjunto de treinamento para gerar um modelo. Usar a função train() em R com um algoritmo específico (como Rede Neural ou GBM) no conjunto de treinamento. Configurar um modelo em Keras, definindo otimizadores e funções de perda (como 'adam' e 'binary_crossentropy') antes de treiná-lo.
-
Assess Model (Avaliar Modelo): Os modelos construídos são avaliados tecnicamente nesta etapa. A avaliação baseia-se nos critérios de sucesso de mineração de dados e nos critérios do desenho de teste definido anteriormente. É uma avaliação puramente técnica, distinta da fase de Avaliação subsequente (Fase 5), que considera os objetivos de negócio e todos os outros resultados do projeto. A avaliação pode incluir a interpretação dos modelos e a análise de métricas de desempenho (por exemplo, acurácia, precisão, recall, matriz de confusão para classificação; medidas específicas para regressão ou clustering). Verificar o overfitting é parte importante desta avaliação. Os resultados desta avaliação podem levar a revisões nos parâmetros ou na técnica, reiniciando o ciclo de construção/avaliação.
- Exemplo: Calcular a acurácia e gerar a matriz de confusão de um modelo de classificação no conjunto de teste. Comparar o desempenho técnico (usando métricas) de vários modelos gerados com diferentes algoritmos (SVM, Naive Bayes, KNN, etc.) para ver qual se saiu melhor nos dados de teste. Utilizar os resultados da validação cruzada (por exemplo, AICc ou performance no fold de teste) para selecionar o melhor modelo de um conjunto de candidatos.
A fase de Modelagem culmina com um ou mais modelos que foram avaliados tecnicamente e considerados promissores. Esses modelos tornam-se candidatos para uma avaliação mais aprofundada e focada nos objetivos de negócio na próxima fase, a Fase 5 (Evaluation).
🧠 A Fase de Business Understanding (Compreensão do Negócio)
📊 A Fase de Business Data Understanding (Compreensão dos Dados do Negócio)
🛠️ A Fase de Preparação dos Dados do Negócio (Business Data Preparation)
📈 A Fase de Modeling (Modelagem)
🧪 A Fase de Avaliação (Evaluation)
🚀 A Fase de Implantação (Deployment)
