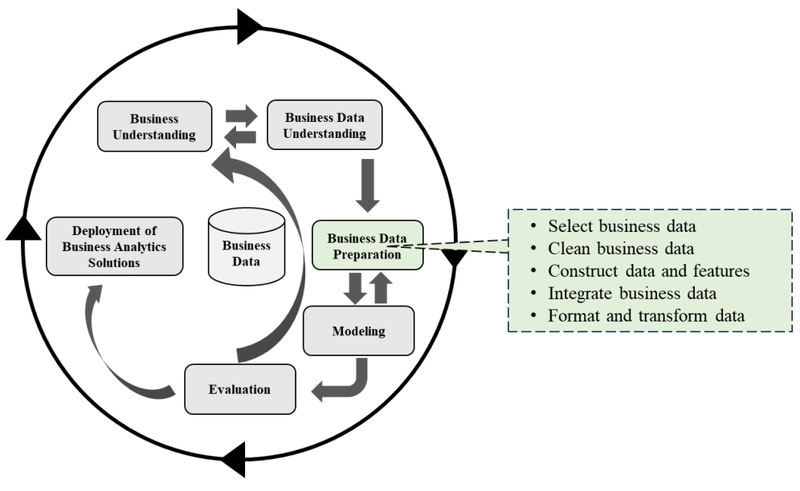
🛠️ Fase 3: Preparação dos Dados do Negócio (Business Data Preparation)
A Fase 3 do framework CRISP-DM é a fase de Preparação dos Dados do Negócio (Business Data Preparation). Esta fase é crucial e frequentemente a mais demorada em projetos de análise.
O objetivo principal da fase de Preparação dos Dados é construir o conjunto de dados final que será utilizado para modelagem ou a análise principal a partir dos dados brutos iniciais. Envolve todas as atividades necessárias para transformar os dados brutos em um formato bem estruturado, limpo e compreensível, pronto para análise.
As tarefas desta fase não são estritamente sequenciais e muitas vezes são realizadas várias vezes, com necessidade de retornar a passos anteriores. A fase de Preparação dos Dados do Negócio requer colaboração entre analistas de dados de negócio, cientistas de dados e engenheiros de dados. Os engenheiros de dados limpam, integram e transformam os dados, enquanto os analistas de dados de negócio garantem que os dados estejam em um formato adequado para análise, com qualidade e acessibilidade garantidas. Os cientistas de dados colaboram para definir os passos de preparação e validar sua eficácia. Se o projeto for pequeno ou a preparação for direta, um analista de dados de negócio ou cientista de dados pode realizar essas tarefas.
📝 Atividades centrais da fase de Preparação dos Dados do Negócio
Seleção dos Dados (Select Data): Decidir quais dados serão usados no projeto com base nos objetivos identificados na fase de Compreensão do Negócio, na qualidade dos dados e em quaisquer limitações técnicas. Isso inclui a seleção de características (colunas) e observações (linhas). Deve haver uma justificativa para inclusão/exclusão dos dados.
-
Limpeza dos Dados (Clean Data): Elevar a qualidade dos dados ao nível exigido pelas técnicas de análise selecionadas. Isso pode envolver a seleção de subconjuntos limpos dos dados, a inserção de valores padrão apropriados ou técnicas mais avançadas como a estimação de dados faltantes. É fundamental documentar as escolhas feitas e as ações tomadas para resolver problemas de qualidade de dados, como o Relatório de Limpeza de Dados (Data cleaning report). A limpeza de dados pode incluir lidar com valores ausentes, corrigindo inconsistências, removendo dados corrompidos ou irrelevantes. O princípio "garbage in, garbage out" (GIGO) ressalta que se dados de baixa qualidade forem usados, os resultados serão não confiáveis.
- Exemplo: Remover uma linha específica com erros conhecidos ou uma coluna inteira que não é relevante para a análise. Lidar com valores faltantes preenchendo-os com a média ou mediana.
-
Construção de Dados e Atributos (Construct Data): Derivar novas características (variáveis) e gerar registros, se necessário. A Engenharia de Atributos (Feature Engineering) é realizada aqui para criar novas variáveis a partir das existentes que possam melhorar o poder preditivo.
- Exemplo: Criar uma nova variável que categorize clientes com base em seus padrões de uso ("segmentando clientes com base no uso"). Calcular a idade de um cliente a partir de sua data de nascimento.
-
Integração de Dados (Integrate Data): Lidar com a questão da integração quando múltiplos dados brutos de diferentes fontes são adquiridos. Isso envolve extrair dados de várias fontes e juntá-los em uma única tabela para análise posterior, se necessário. O resultado é tipicamente dados mesclados (Merged data).
- Exemplo: Combinar dados de vendas, clientes e estoque de diferentes bancos de dados em uma única tabela para analisar padrões de devolução de produtos. Merging dados de diferentes fontes, como arquivos de endereços com a própria base de clientes.
-
Formatação e Transformação (Format Data): Transformar os dados para formatos mais gerais que podem ser facilmente usados e compartilhados. Formatá-los para a fase de modelagem, criando um ou múltiplos conjuntos de dados finais e documentando-os. Isso pode incluir transformar, normalizar ou reduzir características redundantes. Assegurar que os dados estejam em um formato organizado ("tidy form"), onde cada variável é uma coluna, cada observação é uma linha e cada tipo de unidade observacional forma uma tabela. Se os dados não estiverem tidy, eles devem ser pré-processados e reestruturados. Pode envolver a padronização de recursos numéricos ou a codificação de variáveis categóricas (como dummy encoding).
- Exemplo: Normalizar valores numéricos para uma escala comum (por exemplo, entre 0 e 1). Converter variáveis categóricas textuais em representações numéricas ou binárias adequadas para algoritmos de modelagem. Salvar o dataset final em um formato específico como CSV para uso posterior.
A validação da qualidade dos dados deve ser contínua ao longo do projeto, não apenas uma atividade única nesta fase.
🧠 A Fase de Business Understanding (Compreensão do Negócio)
📊 A Fase de Business Data Understanding (Compreensão dos Dados do Negócio)
🛠️ A Fase de Preparação dos Dados do Negócio (Business Data Preparation)
📈 A Fase de Modeling (Modelagem)
🧪 A Fase de Avaliação (Evaluation)
🚀 A Fase de Implantação (Deployment)
