In this guide, we will walk you through the process of building a real-time weather data pipeline using Apache Kafka for streaming and MongoDB for storage. The pipeline collects weather data from the OpenWeatherMap API, streams it via Kafka, and stores it in MongoDB for real-time analysis and querying. By the end of this tutorial, you’ll have a working solution capable of streaming live weather data and storing it for further analysis.
Overview
This project demonstrates how to create a real-time data pipeline that extracts weather data from the OpenWeatherMap API, streams it through Apache Kafka, and stores it in MongoDB. The data will be available for querying and analysis in near real-time. Here's how each component works:
- Weather Data Extraction: Using the OpenWeatherMap API, we fetch live weather data for a given city.
- Kafka Producer: The producer sends weather data to Kafka, which allows the data to be streamed to multiple consumers.
- Kafka Consumer: The consumer retrieves weather data from Kafka and stores it in MongoDB for persistence.
Prerequisites
Before proceeding with the tutorial, ensure that you have the following installed:
- Python 3.x
- Apache Kafka and Zookeeper
- MongoDB (or MongoDB Atlas if you prefer a cloud-based instance)
- Apache Kafka (with Zookeeper)
- Confluent Kafka Python library
- Pandas for data transformation
- OpenWeatherMap API key
Setting Up Apache Kafka
Apache Kafka is the backbone of our real-time streaming solution. It allows us to decouple the producer and consumer, ensuring that weather data can be streamed. Kafka operates by sending data to topics, which can be consumed by the consumer.
Start Zookeeper (Kafka depends on it):
bin/zookeeper-server-start.sh config/zookeeper.propertiesStart Kafka in another terminal:
bin/kafka-server-start.sh config/server.propertiesCreate a Kafka Topic
Kafka uses topics to organize data. For our weather data, we will create a topic called weather_topic.
To create the topic, run:
bin/kafka-topics.sh --create --topic weather_topic --bootstrap-server localhost:9092 --partitions 6 --replication-factor 1Setting Up MongoDB
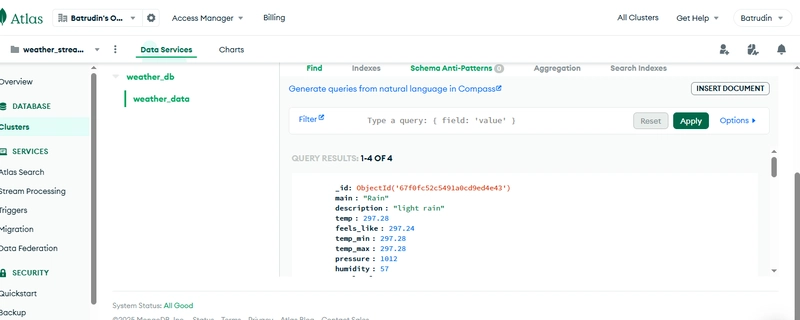
We will use MongoDB to store the weather data in a database for real-time querying and analysis. In this tutorial we use mongodb on the cloud and created a database called weather_db and a collection called weather_data. To secure our application we store our mongo uri in a .env file.
Mongodb
Building the Weather Data Extraction Script
We will now create the script to extract weather data from OpenWeatherMap. The script will fetch the current weather for a city and format the data into a JSON object suitable for Kafka streaming.
import requests
import pandas as pd
import json
from dotenv import load_dotenv
import os
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
load_dotenv() # Load env
uri = os.getenv('DB_STRING')
# Create a new client and connect to the server
client = MongoClient(uri, server_api=ServerApi('1'))
def extract_data():
city_name = 'Nairobi'
# get API KEY
KEY = os.getenv('WEATHER_KEY')
#load weather data in Nairobi,KE from openweathermap
url = f"https://api.openweathermap.org/data/2.5/weather?q={city_name}&appid={KEY}"
weather_data = requests.get(url=url)
df_weather = pd.DataFrame(weather_data.json()['weather'], index=[1])
df_temp = pd.DataFrame(weather_data.json()['main'], index=[1])
country = weather_data.json()['sys']['country']
df_loc = pd.DataFrame(
{
'country': country,
'city': city_name
},
index=[1]
)
#merge data frame
merged_df = pd.merge(pd.merge(df_weather, df_temp, left_index=True, right_index=True, how='outer'),
df_loc, left_index=True, right_index=True, how='outer'
)
return merged_df
def transform_data(merged_df):
# drop columns
df = merged_df.drop(columns=['id', 'icon'])
#tranform temp from kelvin to celcius
temp_list = ['temp', 'feels_like', 'temp_min', 'temp_max']
df[temp_list] = df[temp_list] - 273
data_dict = df.to_dict(orient="records") #Convert the DataFrame to a list of dictionaries
return data_dict
def load_data(data_dict):
#load to mongodb
db = client['weather_db'] #create db
collection = db['weather_data'] #creates collection
# data_dict = df.to_dict(orient="records") #Convert the DataFrame to a list of dictionaries
# print(data_dict)
collection.insert_many(data_dict) # insert the entire DataFrame into the collectionKafka Producer Implementation
from confluent_kafka import Producer
from app import extract_data, transform_data
import json
import time
conf = {
'bootstrap.servers': 'localhost:9092',
'client.id': 'python-producer'
}
producer = Producer(conf)
topic = 'weather_topic'
# Delivery callback
def delivery_report(err, msg):
if err is not None:
print(f"Delivery failed: {err}")
else:
print(f"Message delivered to {msg.topic()} [{msg.partition()}]")
while True:
#call functions
extracted_data = extract_data()
data = transform_data(extracted_data)
for record in data:
producer.produce(topic, value=json.dumps(record), callback=delivery_report)
producer.poll(0) # Trigger delivery callback
time.sleep(180) #after 3 minutes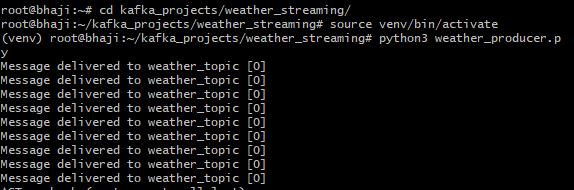
Kafka Consumer Implementation
from confluent_kafka import Consumer, KafkaError,KafkaException
from app import load_data
from dotenv import load_dotenv
import os
import json
import time
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
load_dotenv() # Load env
uri = os.getenv('DB_STRING')
# Create a new client and connect to the server
client = MongoClient(uri, server_api=ServerApi('1'))
# Kafka Consumer configuration
conf = {
'bootstrap.servers': 'localhost:9092', # Kafka broker(s)
'group.id': 'weather-consumer-group', # Consumer group ID
'auto.offset.reset': 'earliest' # Start consuming from the earliest message
}
# Create Consumer instance
consumer = Consumer(conf)
# Kafka topic to consume messages from
topic = 'weather_topic'
# Subscribe to the topic
consumer.subscribe([topic])
# Delivery callback to handle message processing
def delivery_report(err, msg):
if err is not None:
print(f"Message delivery failed: {err}")
else:
print(f"Message delivered to {msg.topic()} [{msg.partition()}] at offset {msg.offset()}")
# Main consumer loop
while True:
try:
# Poll for a message (timeout )
msg = consumer.poll(180.0) # 3 minutes timeout
if msg is None:
print("No message received within the timeout period.")
elif msg.error():
# Handle errors from the consumer
if msg.error().code() == KafkaError._PARTITION_EOF:
print(f"End of partition reached: {msg.partition()} at offset {msg.offset()}")
else:
raise KafkaException(msg.error())
else:
# Successfully received a message
print(f"Received message: {msg.value().decode('utf-8')}")
# Deserialize the message (assuming the message is in JSON format)
message_data = json.loads(msg.value().decode('utf-8'))
# Load data in db
load_data([message_data]) #list message data
# Optional: You can print or handle the processed data here
print(f"Processed data: {message_data}")
time.sleep(180)
except Exception as e:
print(f"An error occurred: {str(e)}")
break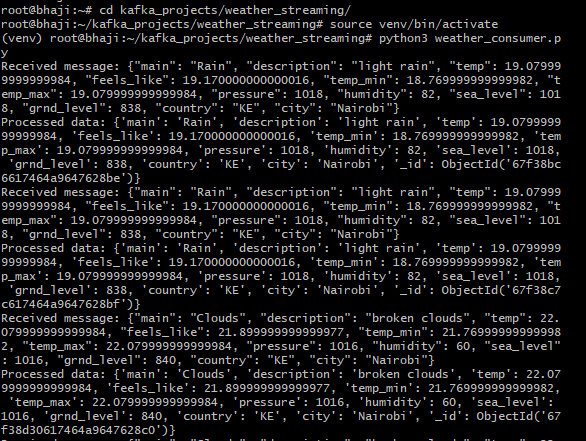
Streaming Data in the DB
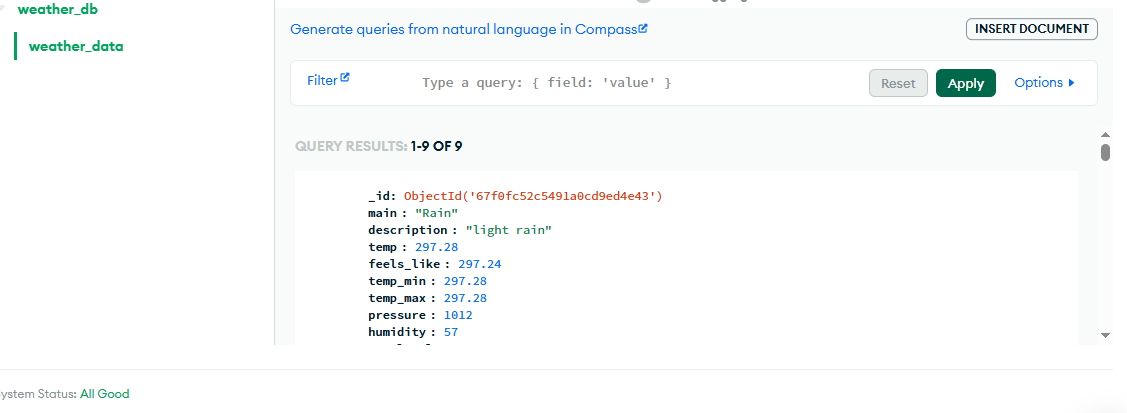
Conclusion and Recommendation
In this guide, we've built a real-time weather data pipeline using Apache Kafka and MongoDB to fetch, stream, and store weather data. While this setup works well for basic use, there are several ways to improve and expand it.
Recommendations:
Dashboard Visualization
Integrate tools like Grafana to visualize real-time weather data with charts and graphs for better insights.
Alert Systems
Set up automatic notifications via email or SMS when the weather conditions exceed a predefined threshold.
Analytics Integration
Use machine learning or statistical models to analyse long-term weather trends and predict future conditions.
For complete code and further details, visit the project on Github.