
เกริ่นกันก่อนคือไอเดียของ Ai ตัวนี้เกิดจากการดูอนิเมะเรื่อง No Game No Life โดยเรามีต้นแบบ Ai เกมเป่ายิ้งฉุบมาจากเว็บนี้
https://rockpaperscissors-ai.vercel.app
Github ของทางต้นฉบับ https://github.com/arifikhsan/batu-gunting-kertas-nuxt
โดยบทความนี้จะเน้นการใช้วิธีการคาดเดาของ Ai และการชั่งน้ำหนักว่า Ai ควรจะออกอะไรเพื่อที่จะชนะผู้เล่น
โดยหลักการของบทความนี้คือการจะออกอะไรไม่ว่า กรรไกร ค้อน หรือ กระดาษ ก็คือเมื่อฝั่งของ Ai มีการหลอกว่าจะออกกระดาษ ทำให้อัตราการที่จะไม่เสียแต้มคือ 2/3 จากทั้งหมด
ตารางการชนะและเสมอจึงเป็นดังนี้

รูปภาพจาก NO Game No Life ตอนที่ 2
ในรูปมีกติการอื่นของอนิเมะอยู่ด้วยแต่อยากให้สนใจตารางเป็นหลักนะคับ
https://youtu.be/3OayLAQil2Y?si=hEBWE9YhyaR_7Tnm&t=317
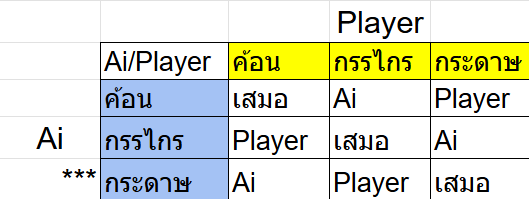
อันนี้คือตารางแบบปกติแบบที่ยังไม่มีการหลอก
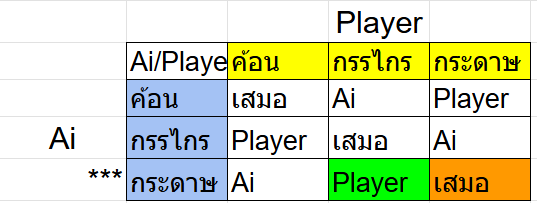
และอันนี้คือกรณีที่ Ai ออกกระดาษจริงๆตรงตามที่เราคิดโดยไม่มีการหลอกเกิดขึ้น
และในส่วนสุดท้ายคือกรณีที่ Ai หลอกเราสำเร็จไม่ว่าจะเป็นการล่อให้เราออกกรรไกร หรือ ทำให้เราเชื่ออีกทีว่า Ai จะออกค้อนมาเพื่อชนะผู้เล่น
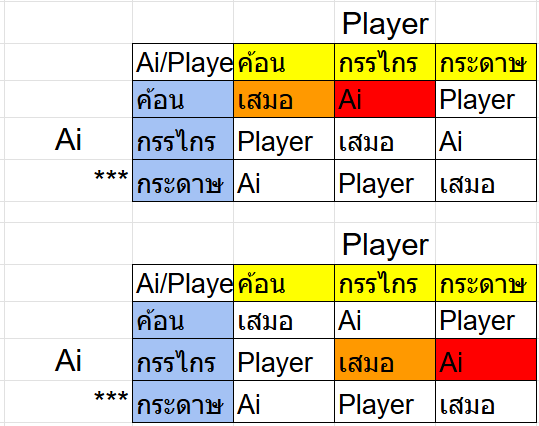
แต่ที่นี้ถ้าเราอยากทำให้ Ai ชนะเราได้ละเราต้องทำยังไง ❓
ผมเลยจึงเอาหลักการของ Ai จากทางต้นฉบับนี้มาปรับเปลี่ยนเพื่อให้เข้ากับกติกาของเราแทน
โดยหลักการของทางต้นฉบับที่ใช้หลักๆเลยจะเป็น
Markov Chains หรือก็คือการคาดเดาความน่าจะเป็นในปัจจุบันโดยไม่อิงข้อมูลจากอดีต
ตัวอย่าง
การคาดเดาสภาพอากาศ
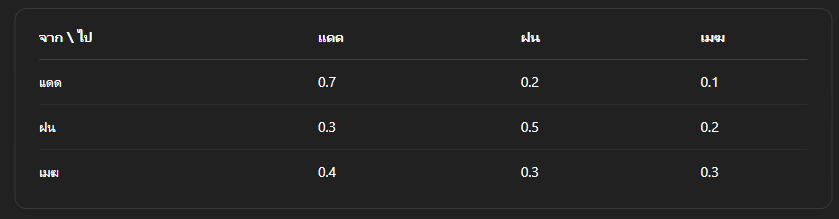
โดยถ้าเป็น Markov Chains จะใช้ข้อมูลของวันนี้เพื่อเดาสภาพอากาศของวันพรุ่งนี้ตามค่าความน่าจะเป็น เช่นวันนี้แดดออกก็จะใช้ตารางของการที่แดดออกในการคาดเดา เช่นวันนี้แดดออกพรุ่งนี้ก็มีโอกาสแดดออกอีก 0.7 เป็นค่าน้ำหนักที่นำไปคำนวนต่อ 0.7 = 70% เป็นต้น
เราจึงได้นำสิ่งนี้มาปรับใช้ในงานของเรานั้นเองโดยอาจจะไม่ได้ใช้ตรงๆแต่เป็นการนำมาเพื่อเป็นแนวคิด
โดยหลักการที่เราจะนำมาใช้คือ
Rule-Based System เพื่อใช้กำหนดกติกาเกม
Behavioral Pattern Recognition ใช้เพื่อมีการจำรูปแบบของผู้เล่นเพื่อทำเป็นค่าน้ำหนักสำหรับคำนวณต่อว่าผู้เล่นจะออกอะไร
Probabilistic Reasoning สำหรับการคาดการณ์โดยอิงจากความน่าจะเป็น
Utility-Based Decision Making หรือก็คือการประเมินค่าน้ำหนักของแต่ละตัวเลือกเพื่อเลือกทางที่ดีที่สุด
โดยอธิบายกติกาก่อนที่จะเริ่มอธิบายโค้ด
เกมเป่ายิ้งฉุบนี้จะให้ผู้เล่นแข่งกับ Ai โดย Ai จะทำการบอกว่าจะออกอะไรโดยจริงหรือหลอกผู้เล่นไม่มีทางรู้และเมื่อมีใครได้แต้มครบ 10 แต้มก่อนจะเป็นผู้ชนะ โดยจะเล่นกันบน Terminal
ขั้นตอนที่ 1 คือการกำหนดข้อมูลพื้นฐานก่อน
เป็นการกำหนดข้อมูลพื้นฐานสำหรับเกมๆนี้และกำหนดไฟล์สำหรับเซฟข้อมูลต่างๆ
import random
import os
# === CONFIG ===
choices = ["rock", "paper", "scissors"]
choice_map = {1: "scissors", 2: "rock", 3: "paper"}
beats = {"rock": "scissors", "paper": "rock", "scissors": "paper"}
score_file = "rock_paper_score.txt"ขั้นตอนที่ 2 เก็บข้อมูลต่างๆ
โดยจะมีหลักๆคือประวัติการออกของผู้เล่นและผลแต่ละรอบ
# === GAME STATE ===
rounds = 0
player_score = 0
ai_score = 0
player_history = []
round_history = []
bluff_success_count = 0
bluff_attempts = 0ขั้นตอนที่ 3 ล้างหน้าจอเพื่อที่จะให้ Ui ดูง่ายตอนเล่น
def clear_screen():
os.system('cls' if os.name == 'nt' else 'clear')ขั้นตอนที่ 4 วิเคราะห์ความน่าจะเป็นการออกของผู้เล่น
โดยวิเคราะห์แนวโน้มการเล่นของผู้เล่น จากสิ่งที่ผู้เล่นเคยออกแต่ถ้าเป็นตาแรก total จะเท่ากับ 0 จึงให้เป็นการเดาออกไปแบบ 1/3 ทุกอัน และตรงนี้ยังใช้เพื่อให้ Ai นำข้อมูลไปใช้ต่อได้ว่าจะออกอะไรหรือล่อให้ Player ออกอะไรเหมือนเพิ่มอัตราการสิ่งๆนั้นของผู้เล่นเพิ่มขึ้น
def predict_player_probabilities():
total = len(player_history)
if total == 0:
return {"rock": 1/3, "paper": 1/3, "scissors": 1/3}
return {
"rock": player_history.count("rock") / total,
"paper": player_history.count("paper") / total,
"scissors": player_history.count("scissors") / total
}ขั้นตอนที่ 5 เลือกว่าจะหลอกอะไรผู้เล่น
โดยส่วนนี้นั้นจะเป็นการหลอกผู้เล่นว่าจะออกอะไรโดยการนำข้อมูลขั้นตอนที่ 4 มาโดยเมื่อ Ai หาได้แล้วว่าผู้เล่นชอบออกอะไรก็จะทำการหลอกสิ่งที่แพ้สิ่งที่ผู้เล่นชอบออกออกไปยังผู้เล่น
เช่น
probs = {"rock": 0.6, "paper": 0.3, "scissors": 0.1} ดังนั้น likely_player_move = "rock"
ส่วนที่อธิบายมาจากโค้ดตรงนี้
likely_player_move = max(probs, key=probs.get)
def choose_bluff(probs):
likely_player_move = max(probs, key=probs.get)
bluff = beats[likely_player_move]
return bluff, likely_player_moveขั้นตอนที่ 6 เลือกสิ่งที่ AI จะออกจริง โดยรวม bluff เข้าไปด้วย
โดยค่า blend_factor=0.5 คือค่าที่จะกำหนดว่าให้ใช้ Logic เป็นหลักหรือการหลอกเป็นหลักซึ่ง
ในกรณี 0.5 คือใช้ทั้งสองฝั่งแบบสมดุล
โดยฟังก์ชันนี้นั้นที่ทำให้ AI ฉลาด
โดยการ “ตัดสินใจอย่างมีเหตุผล” + “ใช้กลยุทธ์บัฟ” เพื่อเลือกสิ่งที่มีโอกาสชนะสูงที่สุด
def ai_choice_with_bluff_blend(player_probs, expected_player_move, blend_factor=0.5):
win_weights = {
"rock": player_probs["scissors"],
"paper": player_probs["rock"],
"scissors": player_probs["paper"]
}
bluff_target = beats[expected_player_move]
for move in win_weights:
if move == bluff_target:
win_weights[move] += blend_factor
best_move = max(win_weights, key=win_weights.get)
return best_move, win_weightsขั้นตอนที่ 7 เช็คผู้ชนะ
def get_result(player, ai):
if player == ai:
return "Draw!"
elif beats[player] == ai:
return "You win!"
else:
return "AI wins!"ขั้นตอนที่ 8 แสดงผลลัพธ์ของรอบและ Ui ต่างๆ
def display_round(player_move, ai_move, result, bluff, round_num):
clear_screen()
print("=" * 40)
print(f"🎮 Round {round_num}")
print(f"🤖 AI says: 'This round I will choose {bluff.upper()}...'")
print(f"🧍♀️ You chose: {player_move.upper()}")
print(f"🤖 AI actually chose: {ai_move.upper()}")
print(f"🏆 Result: {result}")
print("-" * 40)
print(f"📊 Score: You {player_score} - {ai_score} AI")
print("Your options: [1] Scissors ✌️ [2] Rock ✊ [3] Paper ✋")
print("=" * 40)ขั้นตอนที่ 9 แปลง dictionary เป็นข้อความ (ใช้ในบันทึกผล)
def format_dict(d):
return "\n".join([f" - {k}: {v:.2f}" for k, v in d.items()])ขั้นตอนที่ 10 บันทึกผลทั้งหมดตอนจบเกมลงไฟล์ .txt
def save_score():
probs = predict_player_probabilities()
final_ai_move, final_weights = ai_choice_with_bluff_blend(probs, max(probs, key=probs.get))
with open(score_file, "w", encoding="utf-8") as f:
f.write(f"🎯 Final Score\n")
f.write(f"- Player: {player_score}\n")
f.write(f"- AI: {ai_score}\n")
f.write(f"- Total Rounds: {rounds}\n\n")
f.write("🔎 Final Predicted Player Move Probabilities:\n")
f.write(format_dict(probs) + "\n\n")
f.write("🤖 Final AI Utility Weights (after bluff boost):\n")
f.write(format_dict(final_weights) + "\n\n")
bluff_rate = (bluff_success_count / bluff_attempts) * 100 if bluff_attempts > 0 else 0
f.write(f"🎭 Bluffing Success Rate: {bluff_success_count} out of {bluff_attempts} rounds ({bluff_rate:.2f}%)\n\n")
f.write("📜 Round History:\n")
for i, line in enumerate(round_history, start=1):
f.write(f"Round {i}:\n")
f.write(f" - {line['result']}\n")
f.write(f" - AI Bluff: {line['bluff']} (Expected to trigger: {line['expected_player']})\n")
f.write(f" - Player chose: {line['player_move']}\n")
f.write(f" - Bluff {'Success' if line['bluff_success'] else 'Failed'}\n")
f.write(f" - PlayerProbs:\n{format_dict(line['player_probs'])}\n")
f.write(f" - AIWeights:\n{format_dict(line['ai_weights'])}\n\n")ขั้นตอนที่ 11 เริ่มเกม
clear_screen()
print("🎮 Welcome to Rock-Paper-Scissors with Bluffing Strategy AI! 🎮")
print("Press 1 = Scissors ✌️ | 2 = Rock ✊ | 3 = Paper ✋ | 0 = Exit")ขั้นที่ 12 ลูปเกม
โดยหน้าที่ของส่วนนี้นั้นจะแสดงออกมาได้ง่ายๆเป็น
รับอินพุตผู้เล่น → วิเคราะห์พฤติกรรม → Bluff → ตัดสินใจ AI → แสดงผล → บันทึกประวัติ
while True:
if player_score >= 10:
print("\n🏁 Congratulations! You won the game! 🎉")
break
if ai_score >= 10:
print("\n💀 The AI wins this game... Better luck next time!")
break
player_probs = predict_player_probabilities()
bluff, expected_player_choice = choose_bluff(player_probs)
bluff_attempts += 1
print(f"\n🤖 AI says: 'This round I will choose {bluff.upper()}... 😏'")
try:
user_input = int(input("Your choice (1-3) or 0 to exit: "))
if user_input == 0:
print("👋 Thanks for playing! Game results saved to file.")
break
if user_input not in choice_map:
print("⚠️ Please choose 1, 2, or 3 only!")
continue
player_move = choice_map[user_input]
player_history.append(player_move)
bluff_success = (player_move == expected_player_choice)
if bluff_success:
bluff_success_count += 1
ai_move, ai_weights = ai_choice_with_bluff_blend(player_probs, expected_player_choice)
result = get_result(player_move, ai_move)
rounds += 1
if "You win" in result:
player_score += 1
elif "AI wins" in result:
ai_score += 1
display_round(player_move, ai_move, result, bluff, rounds)
round_history.append({
"result": f"Player({player_move}) vs AI({ai_move}) -> {result}",
"bluff": bluff,
"expected_player": expected_player_choice,
"player_move": player_move,
"bluff_success": bluff_success,
"player_probs": player_probs,
"ai_weights": ai_weights
})
except ValueError:
print("❌ Please enter numbers only (1, 2, 3, or 0).")
save_score()
print(f"\n📁 Game results saved to: {score_file}")และอันนี้คือสรุปการทำงานของ Ai ในเกมนี้
player_history
↓
┌──────────────────────────────────┐
│ predict_player_probabilities() │ ← วิเคราะห์พฤติกรรม
└──────────────────────────────────┘
↓
┌──────────────────────────────────┐
│ choose_bluff(probs) │ ← หลอก (Bluff)
└──────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ ai_choice_with_bluff_blend(probs, bluff) │ ← ตัดสินใจจริง
└─────────────────────────────────────────────┘
↓
get_result(player, ai)อันนี้คือส่วนของฟังก์ชั่นสำคัญที่ใช้ใน Ai นี้
วิเคราะห์พฤติกรรมผู้เล่น
ใช้หลัก Behavior Prediction
def predict_player_probabilities(player_history):
total = len(player_history)
if total == 0:
return {"rock": 1/3, "paper": 1/3, "scissors": 1/3}
return {
"rock": player_history.count("rock") / total,
"paper": player_history.count("paper") / total,
"scissors": player_history.count("scissors") / total
}เลือกสิ่งที่จะหลอก(กลยุทธ์หลอกล่อ)
beats = {"rock": "scissors", "paper": "rock", "scissors": "paper"}
def choose_bluff(probs):
likely_player_move = max(probs, key=probs.get)
bluff = beats[likely_player_move]
return bluff, likely_player_moveตัดสินใจจริงของ AI (การหลอก + ความน่าจะเป็น)
ใช้หลัก Utility-Based Decision Making
def ai_choice_with_bluff_blend(player_probs, expected_player_move, blend_factor=0.5):
win_weights = {
"rock": player_probs["scissors"],
"paper": player_probs["rock"],
"scissors": player_probs["paper"]
}
bluff_target = beats[expected_player_move]
for move in win_weights:
if move == bluff_target:
win_weights[move] += blend_factor
best_move = max(win_weights, key=win_weights.get)
return best_move, win_weightsตัวอย่างการเล่น
กรณีที่ยังไม่มีการตัดสินใจที่มีการใช้การหลอกร่วมด้วย หรือ blend_factor = 0
========================================
🎮 Round 26
🤖 AI says: 'This round I will choose SCISSORS...'
🧍♀️ You chose: ROCK
🤖 AI actually chose: PAPER
🏆 Result: AI wins!
----------------------------------------
📊 Score: You 9 - 10 AI
Your options: [1] Scissors ✌️ [2] Rock ✊ [3] Paper ✋
========================================
💀 The AI wins this game... Better luck next time!
📁 Game results saved to: rock_paper_score.txt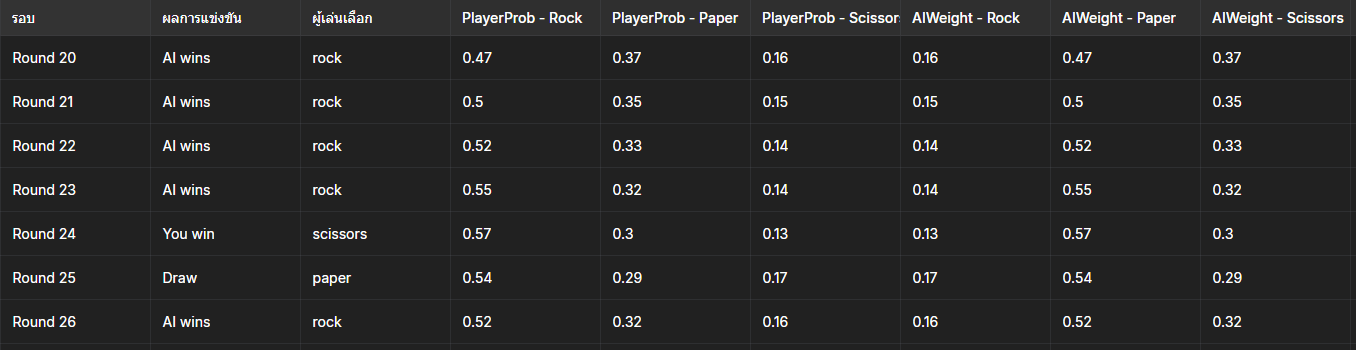
จากตารางรอบ 20-26 ก็จะเห็นได้ว่า Player มีโอกาสออกค้อนเท่ากับเท่าไหร่จากการที่ Player Spam ออกค้อนนั้นเอง
(เล่นโดย Player ที่รู้หลักในการเป่ายิ้งฉุบอยู่แล้วและใช้เวลาเล่นประมาณ 2 นาทีเพราะไม่จำเป็นต้องคิด)
กรณีที่มีการใช้การหลอกร่วมด้วย หรือ blend_factor = 0.5
========================================
🎮 Round 24
🤖 AI says: 'This round I will choose SCISSORS...'
🧍♀️ You chose: ROCK
🤖 AI actually chose: SCISSORS
🏆 Result: You win!
----------------------------------------
📊 Score: You 10 - 9 AI
Your options: [1] Scissors ✌️ [2] Rock ✊ [3] Paper ✋
========================================
🏁 Congratulations! You won the game! 🎉
📁 Game results saved to: rock_paper_score.txt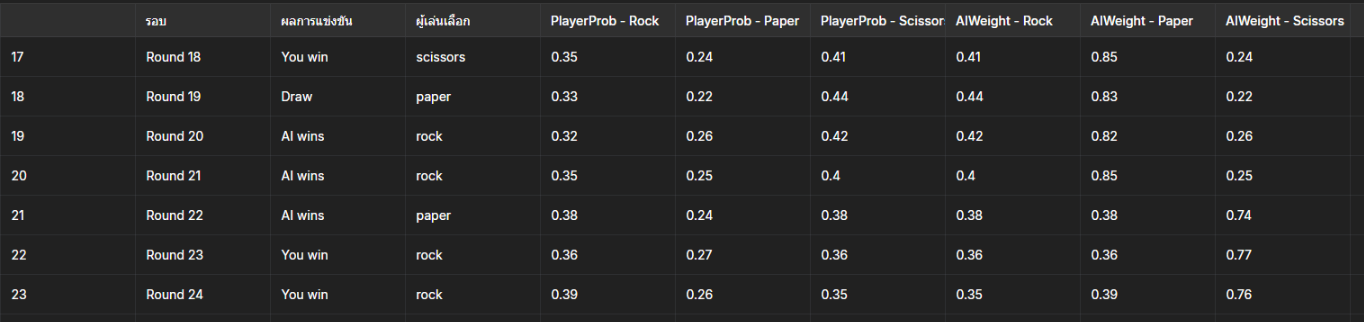
จากตารางที่แสดงให้เห็นจะเห็นได้ค่าที่ Player มีโอกาสออกแต่ละอย่างจะกระจายกันมากขึ้นเพราะมีการหลอกออกมาทำให้ผู้เล่นต้องคิดก่อนออกอย่างหนักค่าจึงออกมากระจาย และในส่วนของ Ai มาการคำนวนค่าออกมารวมกับที่มีการหลอกผู้เล่นทำให้ค่าต่างๆมีการมีการโดดเด่นในแต่ละรอบ
(เล่นโดย Player ที่รู้หลักในการเป่ายิ้งฉุบอยู่แล้วจึงคิดนำหน้า Ai ได้เกิน 2 ก้าวและใช้เวลาเล่นประมาณ 10 นาที)
สรุป
การทำ Ai เกมเป่ายิ้งฉุบโดยที่ Ai สามารถหลอกเราได้ว่า Ai จะออกอะไรและออกจริงหรือไม่ นั้นทำให้ได้ดาต้าการคาดเดาของผู้เล่นออกมาเมื่อสถานการณ์นั้นมีเงื่อนไขโดยเราจะได้เห็นจากตารางมาว่ากรณีที่ไม่มีเงื่อนไขหรือไม่ได้มีการหลอกนั้น Player จะมีการออกที่ไม่ตายตัวและไม่มีแบบแผน
ในขณะที่เมื่อมีการหลอกเกิดขึ้น Player จะมีกระบวนการคิดที่มากขึ้นและคำตอบเองก็จะมีแบบแผนมากขึ้น ดังนั้น Ai นี้สามารถนำไปต่อยอดได้ในเกมจำพวก เกมวางแผนการรบ เกมปริศนา และ Ai ในเกมต่างๆที่ต้องมีการเลือกตัวเลือกและมีเงื่อนไขให้กับผู้เล่น และยังใช้ในการคาดเดาได้ว่าผู้คนนั้นจะเลือกอะไรในสถานการณ์ที่มีเงื่อนไขเช่นการซื้อของระหว่างของ ลดราคา กับ ของที่ต้องการ
จะยังไงก็ลองเอาไปปรับใช้ได้ตามต้องการเลยนะครับ 😁 ขอบคุณครับ
ต้นแบบ
https://rockpaperscissors-ai.vercel.app
https://github.com/arifikhsan/batu-gunting-kertas-nuxt
อ้างอิง
การเป่ายิ้งฉุบ https://www.scimath.org/article-mathematics/item/7801-2017-12-19-01-42-39?utm_source=chatgpt.com