This is a Plain English Papers summary of a research paper called AI Creates Editable 3D Scenes: HiScene's Breakthrough. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Creating Hierarchical 3D Scenes with HiScene
Creating 3D scenes with manipulatable objects remains one of computer graphics' most challenging problems. While recent advances in AI have made remarkable progress in generating 2D images and single 3D objects, creating complete, editable 3D scenes has remained elusive—until now.
Researchers from Zhejiang University and ByteDance have developed HiScene, a framework that bridges the gap between 2D image generation and 3D object creation, delivering high-fidelity interactive scenes where each object remains fully manipulatable.
The Challenge of Creating Interactive 3D Scenes
Current approaches to 3D scene generation face significant limitations. Methods relying on large language models (LLMs) with handcrafted rules often produce unrealistic layouts due to limited spatial understanding. Meanwhile, approaches that lift 2D images into 3D scenes typically produce inseparable wholes, making interactive applications like object manipulation impossible.
An ideal scene generation method requires three key properties:
- Realistic layout & assets: natural object arrangements with diverse content beyond a few simple categories
- Compositional & complete instances: objects that can be individually manipulated without disrupting the scene
- Spatial alignment & plausibility: faithful representation of user intentions while maintaining physical coherence
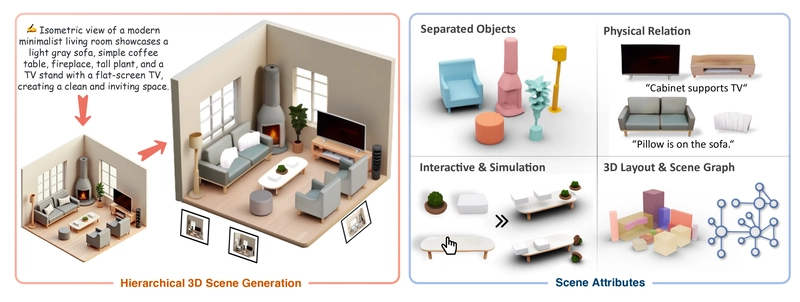
HiScene adopts a novel hierarchical approach. Rather than using handcrafted rules to determine scene layout, it leverages knowledge embedded in image generation models about aesthetically pleasing and reasonable arrangements. The key insight: treating scenes as hierarchical "objects" under isometric views, where a room functions as a complex object that can be further decomposed into manipulatable items.
HiScene allows users to generate scene-level 3D assets with natural layout and appealing visual quality, while delivering compositional items for versatile applications such as interactive editing and simulation.
Building Blocks of 3D Generation
The Evolution of 3D Object Generation
Recent years have seen rapid advancement in 3D object generation methods. DreamFusion pioneered the application of diffusion models to 3D generation using score distillation sampling. Zero123 enabled single-image to 3D conversion by constructing viewpoint data and fine-tuning latent diffusion models. Recent native 3D generation models like Shape2Vecset, CLAY, and TRELLIS have further improved by adopting decoupled strategies that separate geometric structure from texture generation.
HiScene builds upon these advances, treating scenes as hierarchical levels of "objects" to achieve interactive scene generation with high-quality components.
Challenges in Text-to-3D Scene Generation
Text-to-3D scene generation has evolved through several approaches, each with limitations:
Text2Room and similar works leverage latent diffusion models and monocular depth estimators to generate textured 3D meshes, but produce coupled scenes where object instances can't be isolated.
Some methods like SceneCraft first generate 3D scene layouts, then obtain individual objects through retrieval or generation, but are typically limited to specific categories from training data.
Recent approaches like ARCHITECT use Large Language Models to construct 3D layouts while generating individual objects through score distillation sampling, but LLMs still lack sufficient spatial understanding for complex, physically plausible layouts.
HiScene takes a different approach, adopting top-down hierarchical generation that ensures global layout and appearance coherence while maintaining the separability of individual objects.
From Image Inpainting to Amodal Completion
Image inpainting and amodal completion represent two different approaches to recovering missing parts of images. Image inpainting restores masked regions in images but requires manually specified inpainting areas. In contrast, amodal completion generates the complete form of an object from its visible parts, with observed regions automatically obtained through segmentation networks.
This distinction is crucial for HiScene's automated generation of candidate images during hierarchical scene parsing. The system adopts amodal completion rather than image inpainting precisely because it doesn't require manual mask specification.
The HiScene Framework
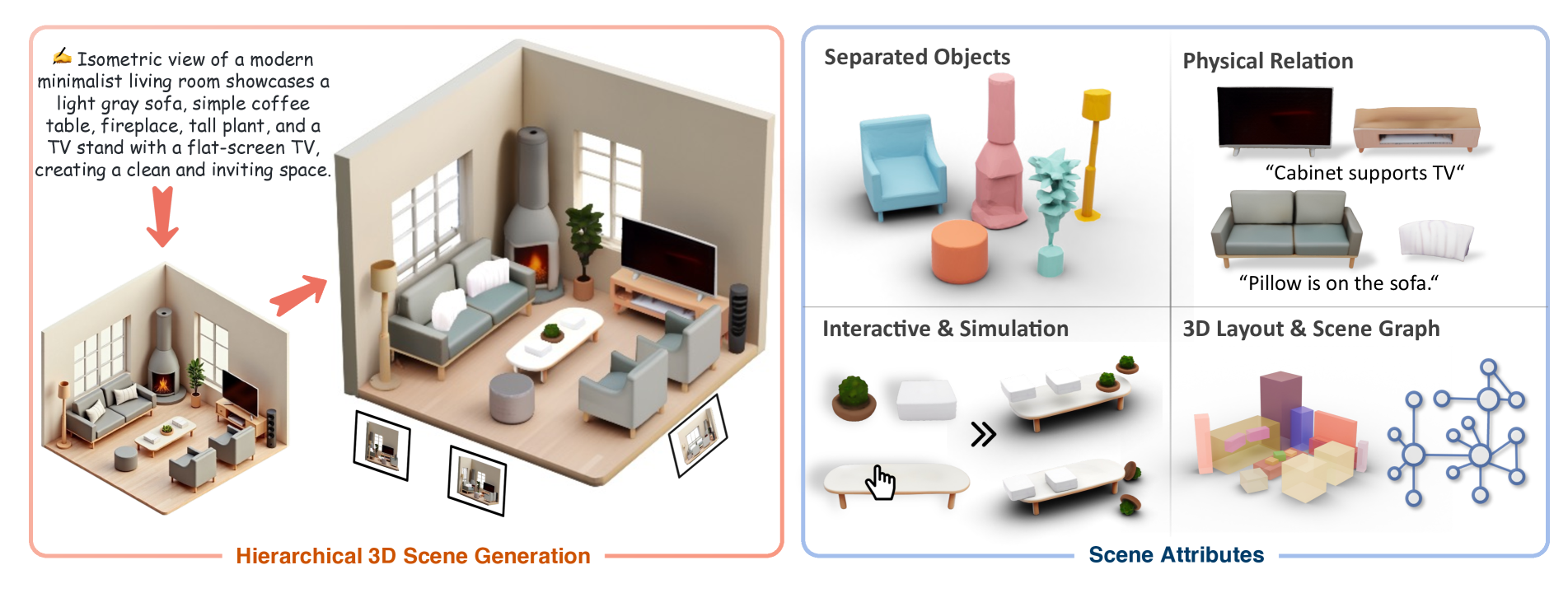
HiScene generates compositional 3D scenes through three main stages: initializing a 3D scene from an isometric view, performing hierarchical scene parsing with semantic segmentation, and conducting video-diffusion-based amodal completion to address occlusions and generate intact objects.
Overview of HiScene. The hierarchical framework generates 3D scenes with compositional identities through three main stages: creating a 3D scene from a generated isometric view, performing scene parsing with multi-view rendering and occlusion analysis, and applying video-diffusion-based amodal completion to generate complete views for regenerating intact objects with proper spatial alignment.
Understanding Isometric Views and 3D Generation
Isometric view offers three key advantages for scene-level generation:
- Distortion-free: Unlike perspective projection, isometric view maintains consistent proportions without perspective distortion.
- Minimal-occlusion: Isometric views capture scenes from an elevated angle, revealing multiple faces simultaneously while minimizing occlusion between elements.
- Scene-as-object: The unified representation allows entire scenes to be treated as cohesive entities, enabling direct generation with object-centric models.
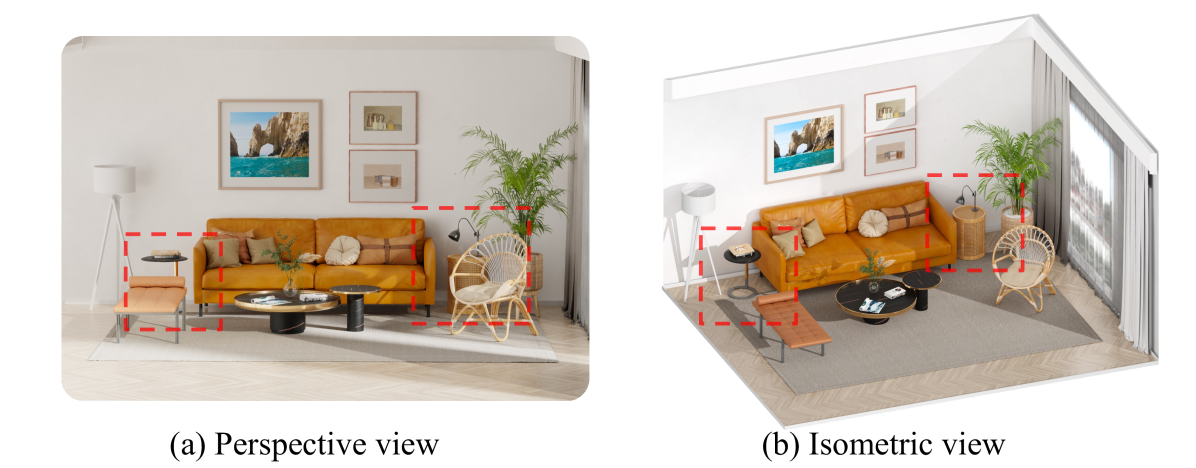
Comparison of perspective view and isometric view of a living room scene. The isometric view provides better visibility of multiple object faces with minimal distortion.
HiScene leverages the TRELLIS native 3D generation model, which uses a Structured LATent (SLAT) representation to characterize 3D assets. TRELLIS employs a two-stage generation pipeline: first generating sparse structure coordinates, then producing corresponding structure features for these coordinates.
Breaking Down Scenes through Hierarchical Parsing
The hierarchical scene parsing stage begins by initializing a scene from a user's text prompt. First, the system prepends "Isometric view of" to the prompt to generate isometric view candidate images, then obtains the initial scene representation through TRELLIS with 3D Gaussian Splatting.
For 3D semantic segmentation, HiScene employs OmniSeg3D-GS, a contrastive learning-based method. The system renders multi-view images from predefined viewpoints, and uses EntitySeg to generate class-agnostic instance-level 2D segmentation masks for these images.
The challenge in this stage is that objects in 3D scenes typically appear incomplete due to occlusion. To recover complete objects, HiScene renders multi-view images of each object in its local coordinate system and analyzes occlusions with the help of visual-language models.
Recovering Complete Objects through Amodal Completion
Unlike existing methods, HiScene formulates amodal completion as a temporal transition video effect, where occlusions gradually dissolve to reveal the complete object. This approach leverages video models trained on large-scale data, which possess stronger prior knowledge for accurately inferring the complete form of occluded parts.
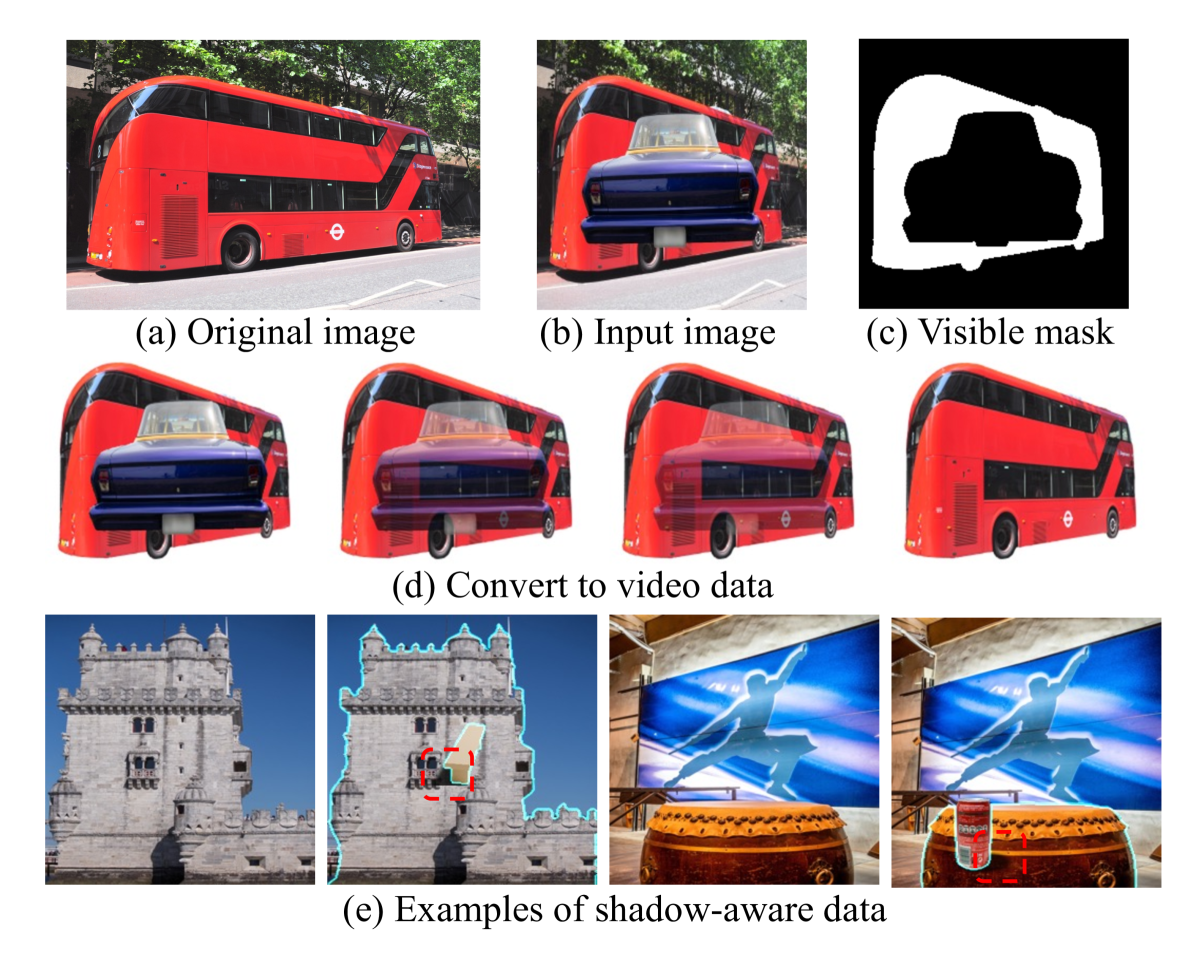
Data curation example of amodal completion, including original image (a), occluded input image (b), visible mask (c), and the linear blended video (d), along with shadow-aware data examples (e).
To train this model, the researchers constructed a large-scale dataset of objects with shadow occlusions using synthetic data. They filtered the Objaverse dataset to obtain 181,000 high-quality 3D objects, used rigid body simulation to place them naturally on the ground, and employed path-tracing rendering to generate 468,000 synthetic images. Combined with existing data, this resulted in a training set of 1.32 million image pairs.
The system employs the Stable Video Diffusion model, where the visible part of an image serves as the first frame input, concatenated with a downsampled visible region mask. The CLIP features of the whole image are injected via cross-attention, and the model predicts noise to minimize a specific loss function during training.
Maintaining Spatial Context through Aligned Generation
After obtaining occlusion-free views, the challenge becomes regenerating each object as an intact instance while preserving its original scale and pose. Directly applying native 3D generative models often results in canonical objects that lose alignment with the original scene context.
To solve this, HiScene injects spatially aligned shape priors derived from multi-view large reconstruction models into the native 3D generation process.
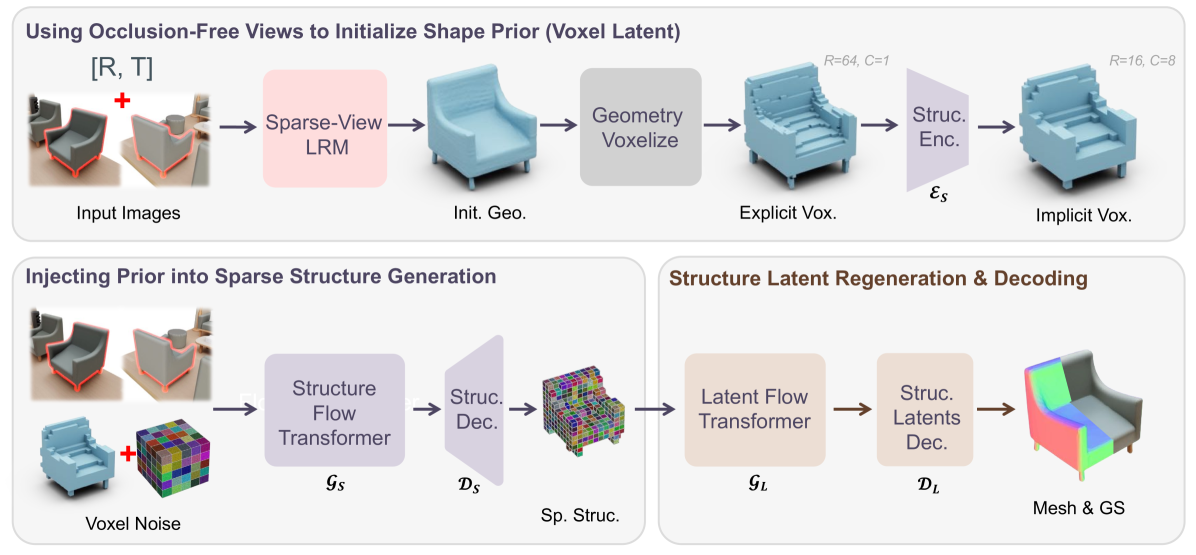
An illustration of Spatial Aligned Generation. The system uses sparse-view LRM to initialize spatially aligned shape prior (voxel latent), and injects this prior by initializing voxel noises upon it during native 3D generation, ensuring regenerated assets adhere to the original scene.
For each incomplete object, the system first reconstructs an initial geometric structure from input observation views and their camera parameters, obtains an explicit voxel representation, and compresses it into a latent feature. This coarse 3D structure guides refinement by serving as the voxel latent initialization with added noise corresponding to an intermediate timestep of the rectified flow model.
Evaluating HiScene: Performance and Comparisons
Creating Interactive 3D Scenes from Text Prompts
HiScene was compared with two state-of-the-art decoupable scene generation methods: GALA3D and DreamScene. While these methods employ large language models for generating initial layouts and implementing various optimization mechanisms, they require predefined 3D layouts as input—a significant barrier for novice users. HiScene addresses this limitation by providing a more intuitive approach without requiring explicit layout specifications.

Comparison of Interactive Scene 3D generation with GALA3D and DreamScene, showing HiScene's superior object quality and scene layouts.
Qualitatively, scenes and objects generated by GALA3D and DreamScene exhibit artifacts, with layouts that often violate physical constraints and common sense spatial relationships. Individual objects frequently suffer from oversaturation and multi-face problems. HiScene generates complex yet plausible scenes with individual objects of significantly higher quality.
Quantitatively, HiScene was evaluated using CLIP Score to assess text-scene alignment, and ImageReward and Aesthetic Score to evaluate overall generation quality:
| Method | Ours | GALA3D [93] | DreamScene [29] |
|---|---|---|---|
| $\uparrow$ Aesthe. Score [47] | $\mathbf{5 . 4 6}$ | 4.74 | 4.71 |
| $\uparrow$ ImageReward [68] | $\mathbf{- 0 . 2 8}$ | -1.67 | -0.73 |
| $\uparrow$ CLIP Score $_{\%}$ [56] | $\mathbf{2 6 . 0 7}$ | 23.50 | 21.91 |
| $\uparrow$ Matching Degree | $\mathbf{2 . 9 0}$ | 1.76 | 1.40 |
| $\uparrow$ Overall Quality | $\mathbf{2 . 7 6}$ | 1.75 | 1.73 |
Table 1. Quantitative evaluation and user studies on the Interactive Scene Generation task, showing HiScene's superior performance across all metrics.
A user study involving 20 participants rating 12 different scenes on text-scene alignment and overall quality confirmed HiScene's superior performance from a human perception perspective.
Advancing Amodal Completion Technology
The researchers assessed the performance of amodal segmentation against existing zero-shot methods, evaluating on the Amodal COCO (COCO-A) and Amodal Berkeley Segmentation (BSDS-A) datasets using mean intersection-over-union (mIoU).

In-the-wild Amodal Completion and Segmentation, showing HiScene's ability to recover occluded objects and remove shadows caused by occlusions.
Compared with state-of-the-art methods like pix2gestalt and zero-shot approaches, HiScene achieved superior performance on both datasets:
| Zero-shot Method | COCO-A | BSDS-A |
|---|---|---|
| SAM [25] | 60.27 | 60.20 |
| SD-XL Inpainting [52] | 70.08 | 66.57 |
| Pix2gestalt [49] | 82.59 | 79.59 |
| Ours | $\mathbf{8 3 . 8 4}$ | $\mathbf{7 9 . 8 0}$ |
Table 2. Comparisons with zero-shot methods on amodal segmentation tasks, showing HiScene's state-of-the-art performance.
Qualitative experiments on everyday scenes demonstrated that while pix2gestalt can reconstruct reasonable shapes, it often produces darkened textures in shadowed regions due to the absence of shadow considerations in its training data. SD-XL Inpainting tends to be influenced by mask boundaries, generating completions that conform to the mask but are semantically unreasonable.
Understanding Component Contributions: Ablation Studies
To understand the contribution of different components, the researchers conducted several ablation studies:
Image vs. Video Model in Amodal Completion: Both image and video models were trained using the same data, with the video model outperforming the image model across all metrics:
| Datasets & Method | COCO-A | BSDS-A | ||
|---|---|---|---|---|
| I2I | I2V | I2I | I2V | |
| $\uparrow$ Aesthe. Score [47] | 4.16 | $\mathbf{4 . 3 0}$ | 4.17 | $\mathbf{4 . 3 8}$ |
| $\uparrow$ Q-Align IAA $_{\%}$ [68] | 12.65 | $\mathbf{2 3 . 4 8}$ | 14.59 | $\mathbf{2 3 . 4 6}$ |
| $\uparrow$ Q-Align IQA $_{\%}$ [68] | 35.43 | $\mathbf{4 5 . 8 0}$ | 35.06 | $\mathbf{4 4 . 4 2}$ |
| $\uparrow$ CLIP Score $_{\%}$ [56] | 20.27 | $\mathbf{2 0 . 7 8}$ | 20.63 | $\mathbf{2 1 . 2 0}$ |
Table 3. Evaluation of the effectiveness of the video model compared to image model for amodal completion tasks.
The superior performance is attributed to the video model's powerful prior knowledge of object continuity and temporal consistency, enabling more coherent and realistic completions.
Shadow-Aware Completion for Object Generation: The researchers demonstrated the importance of proper amodal completion by attempting object generation without it. Since object generation models are trained on complete observations, when presented with partial inputs, the models generated incorrect geometric structures with black textures in missing regions.
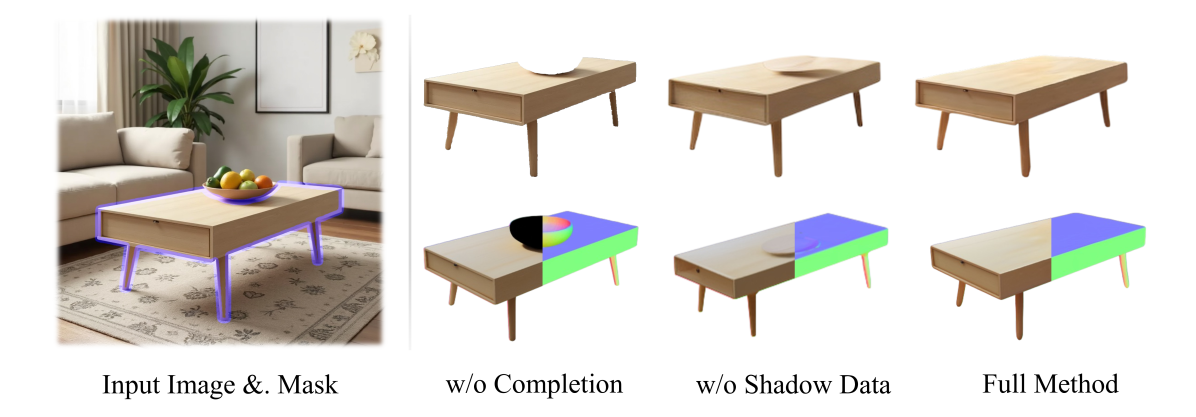
Analysis of the necessity of shadow-aware amodal completion, showing how improper completion leads to geometric errors and texture problems.
Even when amodal completion was performed but shadow artifacts remained, the generated results still exhibited black geometric errors. HiScene's shadow-aware approach effectively addressed these issues by properly handling both occlusions and shadows.
Spatial Alignment: The effectiveness of spatial aligned generation was evaluated against direct native 3D generation and standalone LRM generation:

Analysis of the effectiveness of Spatial Aligned Generation, comparing direct methods with HiScene's combined approach.
Without spatial alignment, native 3D generation produced objects with incorrect orientation and positioning, while LRM generation alone resulted in compromised appearance fidelity. By leveraging LRM's spatial alignment capabilities as a shape prior for native 3D generation, HiScene achieved precise scale and pose matching with the original scene while preserving visual quality.
Conclusion and Future Directions
HiScene presents a significant advance in 3D scene generation through its hierarchical framework, video-diffusion-based amodal completion, and spatial alignment capabilities. By treating scenes as hierarchical compositions of objects under isometric views, it enables effective scene-level synthesis using pretrained object generation models.
Despite these advances, the framework has limitations. Currently, scenes generated by HiScene have textures with baked lighting, lacking PBR materials needed for modern rendering pipelines. Future work will focus on training generative models to produce scenes that support PBR textures, further enhancing the utility of these generated assets in professional graphics workflows.
The approach demonstrated in HiScene points toward a future where creating interactive, high-quality 3D scenes becomes as accessible as generating images is today—a breakthrough that could transform fields from game development to architectural visualization and virtual reality content creation.
