This is a Plain English Papers summary of a research paper called AI Learns Phone: Few-Shot Agent Masters Mobile Apps with Demos. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Enhancing Mobile GUI Agents Through Demonstration Learning
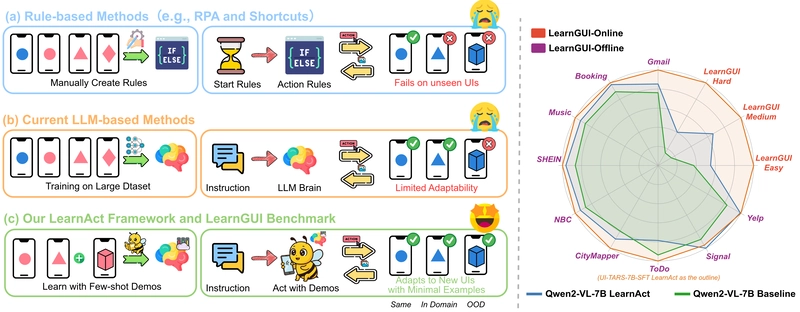
Mobile GUI agents have evolved significantly from simple rule-based scripts to AI-powered assistants that can automate complex tasks on smartphones. Despite promising advances, these agents struggle with generalization challenges in diverse real-world scenarios. The immense variety of mobile applications and user-specific tasks creates "long-tail" scenarios where current approaches fail to perform effectively.
The LearnAct Framework and LearnGUI Benchmark addressing long-tail challenges in mobile GUI agents through demonstration-based learning, showing evolution from rule-based automation to LLM-powered agents.
Traditional approaches to building mobile GUI agents rely on either pre-training or fine-tuning with massive datasets. But these methods face fundamental limitations when confronted with the diversity of real-world usage scenarios. With billions of users interacting with over 1.68 million applications on Google Play alone, pre-training or fine-tuning datasets cannot feasibly cover this immense variety, leading to poor performance in unseen scenarios and hindering widespread adoption.
To address these limitations, researchers from Zhejiang University and vivo AI Lab propose a novel paradigm that enhances mobile GUI agent capabilities through few-shot demonstration learning. Unlike traditional approaches that rely on massive datasets, this demonstration-based approach achieves both robustness and personalization by learning from a small number of user-provided examples. This approach is particularly valuable for tasks with stable patterns but variable elements, such as smart home control with dynamic configurations or health monitoring with personalized parameters - scenarios that create a "personalization gap" pre-trained models cannot bridge.
The work connects to broader efforts in the field, including improvements in mobile GUI agents as proficient smartphone assistants and innovations in breaking data barriers for building GUI agents.
Current Approaches to Mobile GUI Agent Benchmarking
Existing benchmarks for mobile GUI agents can be categorized into static datasets and dynamic benchmarking environments. Static datasets provide natural language task descriptions, UI states, and corresponding user actions but lack the capability to evaluate few-shot learning. Dynamic benchmarking environments offer interactive testing but typically focus on a limited number of tasks and applications without few-shot demonstration capabilities.
| Dataset | # Inst. | # Apps | # Step | Env. | HL | LL | GT | FS |
|---|---|---|---|---|---|---|---|---|
| PixelHelp [15] | 187 | 4 | 4.2 | # | ✓ | # | ✓ | # |
| MoTIP [4] | 276 | 125 | 4.5 | # | ✓ | ✓ | ✓ | # |
| UIIberl [3] | 16,660 | - | 1 | # | # | ✓ | ✓ | # |
| UGIF [27] | 523 | 12 | 6.3 | # | ✓ | ✓ | ✓ | # |
| AITW [24] | 30,378 | 357 | 6.5 | # | ✓ | # | ✓ | # |
| AITZ [45] | 2,504 | 70 | 7.5 | # | ✓ | ✓ | ✓ | # |
| AndroidControl [14] | 15,283 | 833 | 4.8 | # | ✓ | ✓ | ✓ | # |
| AMEX [5] | 2,946 | 110 | 12.8 | # | ✓ | # | ✓ | # |
| MobileAgentBench [30] | 100 | 10 | - | # | ✓ | # | # | # |
| AppAgent [44] | 50 | 10 | - | # | ✓ | # | # | # |
| LlamaTouch [47] | 496 | 57 | 7.01 | ✓ | ✓ | # | ✓ | # |
| AndroidWorld [23] | 116 | 20 | - | ✓ | ✓ | # | # | # |
| AndroidLab [40] | 138 | 9 | 8.5 | ✓ | ✓ | # | # | # |
| LearnGUI (Ours) | 2,353 | 73 | 13.2 | ✓ | ✓ | ✓ | ✓ | ✓ |
Table 1: Comparison of different datasets and environments for benchmarking Mobile GUI agents, showing number of instructions, applications, steps per task, and support for various features.
The LearnGUI dataset distinguishes itself through three key innovations. First, it specifically supports few-shot learning capabilities with a comprehensive collection of 2,252 offline tasks and 101 online tasks. Second, it standardizes action space, constructs systematic k-shot task combinations, and implements multi-dimensional similarity measurement. Third, it provides a unified framework for both offline and online evaluation.
This comprehensive approach aligns with broader efforts in the field to create qualified evaluation benchmarks for LLM-based mobile agents and establishes a foundation for systematic research into demonstration-based learning for mobile GUI agents.
The LearnGUI Dataset: A Framework for Demonstration-Based Learning
Mobile GUI tasks require agents to interact with digital environments by executing actions to fulfill user instructions. These tasks can be formally described as a Partially Observable Markov Decision Process (POMDP), with the key innovation in this approach being the integration of human demonstration knowledge into this framework.
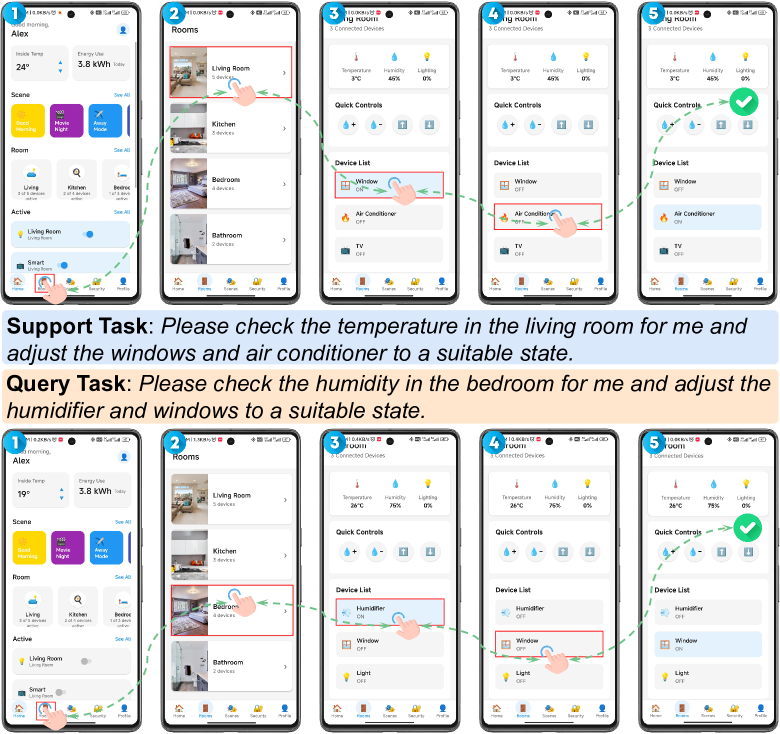
A toy example showing demonstration learning on mobile GUI Agent, highlighting the multi-dimensional metrics for task similarity, UI similarity, and action similarity between support and query tasks.
To study how demonstration-based learning affects mobile GUI agents, LearnGUI provides various k-shot demonstrations with controlled similarity relationships between support and query tasks. This allows systematic investigation of how demonstration quantity and task similarity affect agent performance. While cross-application knowledge transfer remains an interesting research direction, the dataset focuses on within-application task learning, as this represents the most practical use case where users would provide demonstrations for applications they frequently use.
LearnGUI's action space is standardized across both offline and online components:
| Action | Definition |
|---|---|
| CLICK $[\mathrm{x}, \mathrm{y}]$ | Click at coordinates $(\mathrm{x}, \mathrm{y})$. |
| TYPE $[$ text $]$ | Type the specified text. |
| SWIPE [direction] | Swipe in the specified direction. |
| PRESS_HOME | Go to the home screen. |
| PRESS_BACK | Go back to the previous app screen. |
| PRESS_ENTER | Press the enter button. |
| TASK_COMPLETE[answer] | Mark the task as complete. Provide answer inside brackets if required. |
Table 2: LearnGUI Action Space defining the standardized actions available to agents.
LearnGUI-Offline was built by restructuring and enhancing the AMEX dataset. The researchers refined the action space, constructed k-shot task combinations by computing instruction similarity between tasks within the same application, and measured similarity across three key dimensions: instruction, UI, and action. LearnGUI-Online was developed based on the AndroidWorld environment, with human demonstrations collected for 101 tasks suitable for real-time evaluation.
The dataset is systematically divided into training and testing splits, with detailed statistics provided:
| Split | K-shot | Tasks | Apps | Step actions | Avg Ins $_{\text {Sim }}$ | Avg UI $_{\text {Sim }}$ | Avg Act $_{\text {Sim }}$ | $\mathrm{UI}{\mathrm{SH}} \mathrm{Act}{\mathrm{SH}}$ | $\mathrm{UI}{\mathrm{SH}} \mathrm{Act}{\mathrm{SL}}$ | $\mathrm{UI}{\mathrm{SL}} \mathrm{Act}{\mathrm{SH}}$ | $\mathrm{UI}{\mathrm{SL}} \mathrm{Act}{\mathrm{SL}}$ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Offline-Train | 1 -shot | 2,001 | 44 | 26,184 | 0.845 | 0.901 | 0.858 | 364 | 400 | 403 | 834 |
| Offline-Train | 2 -shot | 2,001 | 44 | 26,184 | 0.818 | 0.898 | 0.845 | 216 | 360 | 358 | 1,067 |
| Offline-Train | 3 -shot | 2,001 | 44 | 26,184 | 0.798 | 0.895 | 0.836 | 152 | 346 | 310 | 1,193 |
| Offline-Test | 1 -shot | 251 | 9 | 3,469 | 0.798 | 0.868 | 0.867 | 37 | 49 | 56 | 109 |
| Offline-Test | 2 -shot | 251 | 9 | 3,469 | 0.767 | 0.855 | 0.853 | 15 | 42 | 55 | 139 |
| Offline-Test | 3 -shot | 251 | 9 | 3,469 | 0.745 | 0.847 | 0.847 | 10 | 36 | 49 | 156 |
| Online-Test | 1 -shot | 101 | 20 | 1,423 | - | - | - | - | - | - | - |
Table 3: Statistics of LearnGUI dataset splits showing task counts, application coverage, similarity metrics, and distribution across similarity profiles.
Based on empirical analysis, the researchers established threshold values to classify tasks into high (SH) and low (SL) similarity categories for both UI and action dimensions, enabling systematic analysis of how different similarity types affect learning from demonstrations.
Joint distribution of UI similarity and action similarity in LearnGUI-Offline, showing the quadrant divisions representing task categorization into four profiles for analyzing how different similarity combinations affect learning transfer.
This categorization enables detailed analysis of how different types of similarity affect learning efficacy, investigating whether UI similarity or action similarity has a greater impact on successful knowledge transfer from demonstrations.
The LearnAct Framework: A Multi-Agent Approach to Demonstration Learning
Building on the insights from LearnGUI, the researchers introduce LearnAct, a sophisticated multi-agent framework designed to break through the limitations of traditional training approaches. Rather than pursuing universal generalization through extensive training data, LearnAct establishes demonstration-based learning as a paradigm for developing more adaptable, personalized, and deployable mobile GUI agents.

Architecture diagram of the LearnAct framework showing the three main components (DemoParser, KnowSeeker, ActExecutor) and their interconnections, including data flow from human demonstrations to execution.
The LearnAct framework consists of three specialized components, each addressing a critical aspect of demonstration-based learning:
- DemoParser: A knowledge generation agent that extracts usable knowledge from demonstration trajectories to form a knowledge base
- KnowSeeker: A knowledge retrieval agent that searches the knowledge base for demonstration knowledge relevant to the current task
- ActExecutor: A task execution agent that combines user instructions, real-time GUI environment, and retrieved demonstration knowledge to perform tasks effectively
The DemoParser transforms raw human demonstrations (consisting of coordinates-based clicks, swipes, and text inputs) into structured demonstration knowledge. It utilizes a vision-language model to generate semantically descriptive action descriptions that capture the essence of each demonstration step (e.g., "On Search Page, click the search box, to enter keywords").
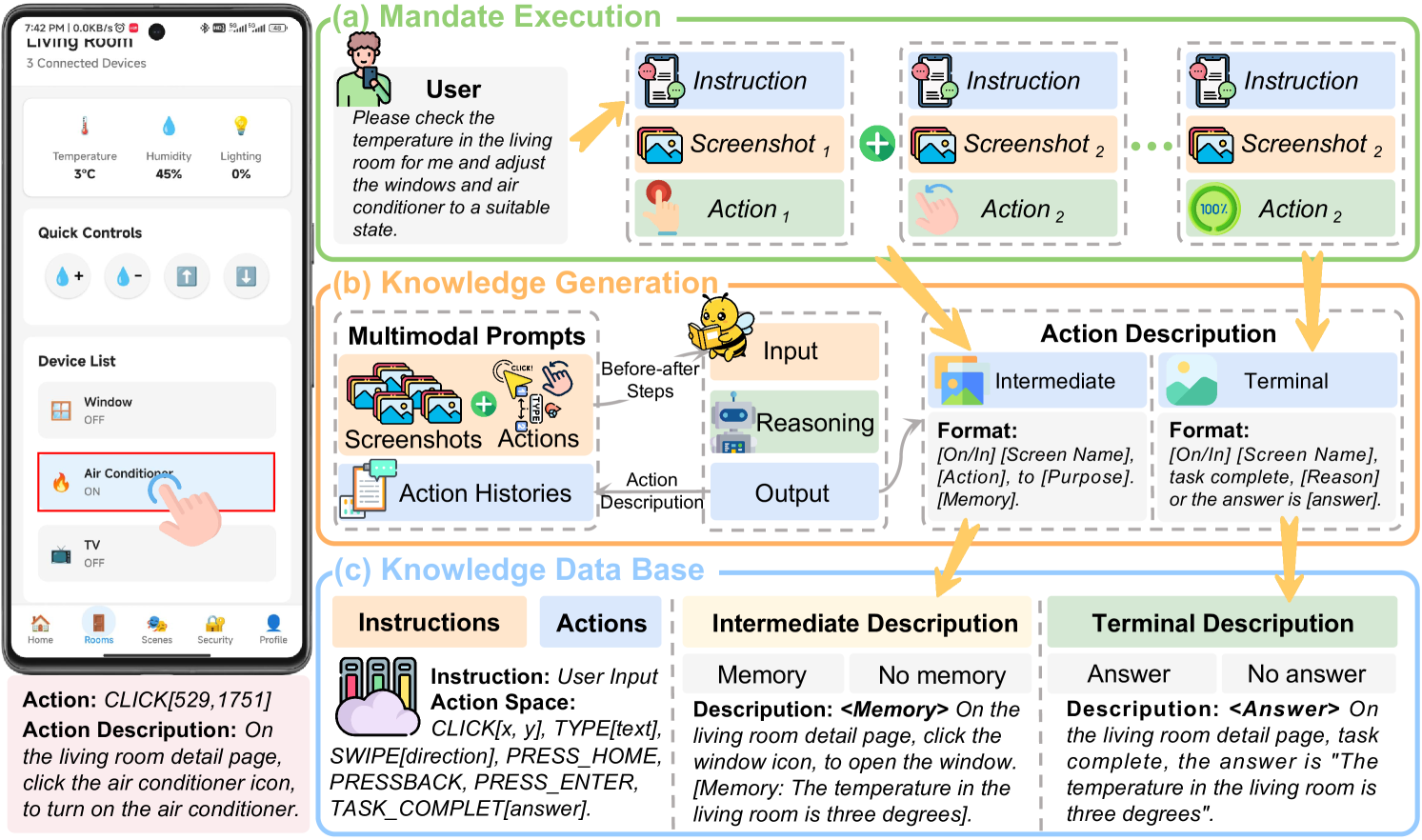
Pipeline of DemoParser Agent showing how it transforms high-level user instructions into precise operation sequences while building a reusable domain knowledge base.
KnowSeeker serves as the retrieval component of the framework, identifying demonstration knowledge most relevant to the current task context. It acts as the bridge between the knowledge base generated by DemoParser and the execution environment of ActExecutor.
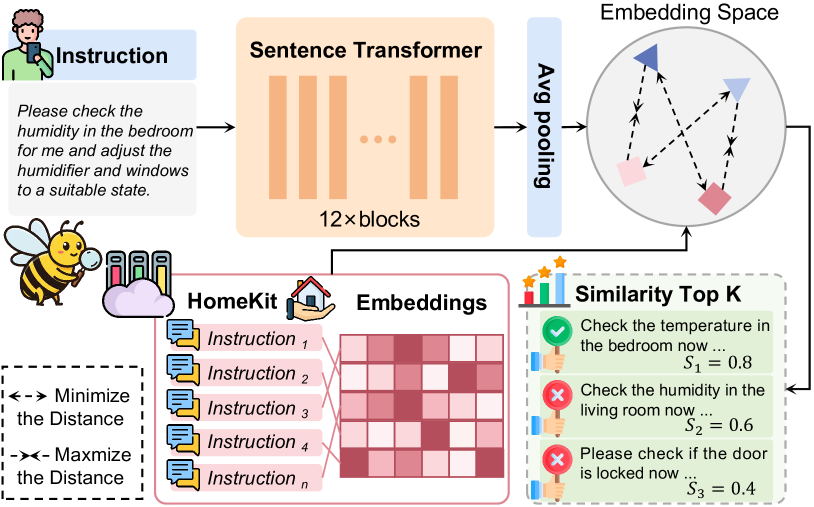
Pipeline of KnowSeeker Agent showing how it converts demonstration trajectories into a vector database and retrieves the top-k relevant demos to assist with new task execution.
ActExecutor is the execution component that translates retrieved demonstration knowledge into effective actions in the target environment. It represents the culmination of the LearnAct pipeline, integrating user instructions, real-time GUI observations, and demonstration knowledge to navigate even unfamiliar mobile applications successfully.

Pipeline of ActExecutor Agent showing how it executes low-level actions using knowledge from demonstrations retrieved by the KnowSeeker.
This comprehensive framework connects to efforts in creating unified benchmarks for advancing autonomous GUI testing, providing a sophisticated approach to leveraging human demonstrations for mobile GUI automation.
Experimental Validation of Demonstration-Based Learning
The researchers conducted comprehensive evaluations of the LearnAct framework through both offline and online experiments. The offline experiments were performed on the LearnGUI-Offline dataset to evaluate step-by-step task execution capabilities, while the online experiments utilized the LearnGUI-Online platform to assess end-to-end task completion in real-world interactive scenarios.
For offline experiments, the team used Gemini-1.5-Pro, UI-TARS-7B-SFT, and Qwen2-VL-7B models. For UI-TARS-7B-SFT and Qwen2-VL-7B, they employed parameter-efficient fine-tuning using LoRA. For online experiments, all models except Gemini-1.5-Pro were deployed to the LearnGUI-Online environment.
| Models | Method | Supports | Average | Gmail | Booking | Music | SHEIN | NBC | CityMapper | ToDo | Signal | Yelp |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SPHINX-GUI Agent[5] | AMEX | 0-shot | 67.2 | 45.9 | 64.5 | 74.4 | 71.8 | 70.3 | 67.4 | 79.3 | 64.9 | 66.3 |
| gemini-1.5-pro | Baseline | 0-shot | 19.3 | 20.1 | 16.4 | 24.5 | 10.2 | 35.6 | 14.1 | 17.4 | 27.9 | 15.2 |
| 1-shot | 51.7 [+32.4] | 55.5 | 47.1 | 60.0 | 35.7 | 56.4 | 54.7 | 60.6 | 63.1 | 54.6 | ||
| LearnAct | 2-shot | 55.6 [+36.3] | 57.5 | 53.2 | 55.3 | 39.6 | 56.1 | 58.2 | 68.1 | 69.7 | 60.0 | |
| 3-shot | 57.7 [+38.4] | 58.4 | 56.6 | 54.6 | 43.9 | 53.9 | 69.4 | 69.2 | 70.5 | 57.6 | ||
| UI-TARS-7B-SFT | Baseline | 0-shot | 77.5 | 68.1 | 81.0 | 81.1 | 72.9 | 80.9 | 70.6 | 66.0 | 92.6 | 82.4 |
| 1-shot | 82.8 [+5.3] | 79.9 | 82.9 | 86.6 | 75.7 | 86.3 | 79.4 | 84.0 | 89.3 | 83.0 | ||
| LearnAct | 2-shot | 81.9 [+4.4] | 80.1 | 80.7 | 86.2 | 76.1 | 87.2 | 80.0 | 83.7 | 84.4 | 84.2 | |
| 3-shot | 82.1 [+4.6] | 79.9 | 80.9 | 86.2 | 75.7 | 86.9 | 81.2 | 85.8 | 84.4 | 84.2 | ||
| Qwen2-VL-7B | Baseline | 0-shot | 71.8 | 60.8 | 73.9 | 76.0 | 65.5 | 75.5 | 62.9 | 78.7 | 82.8 | 69.1 |
| 1-shot | 77.3 [+5.5] | 75.0 | 77.5 | 77.8 | 69.8 | 83.5 | 72.9 | 78.0 | 83.6 | 78.8 | ||
| LearnAct | 2-shot | 78.5 [+6.7] | 75.0 | 78.0 | 77.8 | 73.3 | 86.0 | 73.5 | 81.9 | 87.7 | 77.6 | |
| 3-shot | 79.4 [+7.6] | 75.0 | 78.8 | 78.6 | 72.6 | 87.8 | 77.1 | 82.6 | 87.7 | 80.6 |
Table 4: Performance comparison of mobile GUI agents on LearnGUI-Offline dataset showing action match accuracy percentages and relative improvements compared to baselines.
The results demonstrate substantial improvements achieved by the LearnAct framework across all tested models. Gemini-1.5-Pro shows the most dramatic improvement, with performance increasing from 19.3% to 51.7% (+32.4%) with just a single demonstration, and further improving to 57.7% (+38.4%) with three demonstrations. This represents a 198.9% relative improvement, highlighting the powerful potential of demonstration-based learning even for advanced foundation models.
UI-TARS-7B-SFT, despite already having strong zero-shot performance (77.5%), still achieves significant gains with LearnAct, reaching 82.8% (+5.3%) with a single demonstration. Qwen2-VL-7B demonstrates consistent improvement from 71.8% to 77.3% (+5.5%) with one demonstration, and to 79.4% (+7.6%) with three demonstrations.
| Models | Supports | $\mathbf{U I}{\mathbf{S H}} \mathbf{A c t}{\mathbf{S H}}$ | $\mathbf{U I}{\mathbf{S H}} \mathbf{A c t}{\mathbf{S L}}$ | $\mathbf{U I}{\mathbf{S L}} \mathbf{A c t}{\mathbf{S H}}$ | $\mathbf{U I}{\mathbf{S L}} \mathbf{A c t}{\mathbf{S L}}$ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| type | match | type | match | type | match | type | match | |||
| gemini-1.5-pro | 1-shot | $79.5[+12.8]$ | $50.2[+35.6]$ | $78.1[+12.3]$ | $47.8[+33.2]$ | $77.5[+9.2]$ | $52.3[+30.5]$ | $77.9[+14.1]$ | $44.2[+29.3]$ | |
| 2-shot | $77.7[+13.0]$ | $53.9[+37.3]$ | $73.2[+10.8]$ | $49.9[+34.7]$ | $80.0[+9.0]$ | $56.5[+34.8]$ | $77.2[+12.9]$ | $48.9[+34.4]$ | ||
| 3-shot | $72.3[+15.8]$ | $53.5[+39.6]$ | $72.8[+12.9]$ | $49.5[+34.6]$ | $78.7[+10.4]$ | $60.0[+38.4]$ | $79.2[+12.8]$ | $51.6[+36.3]$ | ||
| Qwen2-VL-7B | 1-shot | $86.0[+5.3]$ | $72.2[+6.3]$ | $85.4[+4.9]$ | $69.6[+5.5]$ | $86.0[+2.0]$ | $76.2[+5.4]$ | $82.9[+1.3]$ | $69.4[+4.3]$ | |
| 2-shot | $85.0[+67.4]$ | $75.6[+9.3]$ | $84.0[+67.2]$ | $71.2[+5.7]$ | $86.9[+73.3]$ | $76.8[+6.3]$ | $84.0[+68.5]$ | $70.5[+5.5]$ | ||
| 3-shot | $80.2[+5.0]$ | $70.3[+7.9]$ | $82.9[+4.7]$ | $70.2[+5.7]$ | $85.6[+1.9]$ | $77.5[+8.4]$ | $85.6[+3.4]$ | $72.8[+6.6]$ | ||
| UI-TARS-7B-SFT | 1-shot | $88.1[+1.9]$ | $77.8[+6.6]$ | $87.2[+2.1]$ | $75.3[+6.4]$ | $87.7[+0.3]$ | $80.1[+5.9]$ | $85.0[-0.2]$ | $75.0[+2.8]$ | |
| 2-shot | $85.5[+2.1]$ | $76.7[+8.3]$ | $85.7[+1.6]$ | $75.9[+4.9]$ | $87.3[-0.4]$ | $79.1[+5.9]$ | $84.9[-0.8]$ | $74.1[+2.1]$ | ||
| 3-shot | $87.1[+7.9]$ | $78.2[+13.9]$ | $85.5[+2.6]$ | $75.4[+4.9]$ | $86.0[-0.9]$ | $78.9[+6.8]$ | $85.5[-0.9]$ | $75.2[+2.7]$ |
Table 5: Performance breakdown of LearnAct-Offline on different UI and action combinations, showing type and match accuracy across four similarity quadrants.
The results across different similarity profiles reveal that both UI similarity and action similarity influence learning efficacy, with action similarity sometimes compensating for UI differences. For Gemini-1.5-Pro, the UISLActSH category (low UI similarity but high action similarity) shows strong performance improvement, suggesting that similar action patterns can enable effective knowledge transfer even when interfaces differ.
For online evaluation, LearnAct enhances UI-TARS-7B-SFT's task success rate from 18.1% to 32.8%, a significant 14.7% absolute improvement. This brings its performance close to GPT-4o's 34.5%, despite using a much smaller model.
| Input | Models | # Params | LearnGUI-Online ${ }_{3 R}$ |
|---|---|---|---|
| Image + AXTree | GPT-4ol [12] | - | 34.5 |
| Image + AXTree | Gemini-Pro-1.5[26] | - | 22.8 |
| Image | Claude Computer-Use[2] | - | 27.9 |
| Image | Agusis[41] | 72B | 26.1 |
| Image | Qwen2-VL-7B + 0-shot | 7B | 9.9 |
| Image | Qwen2-VL-7B + LearnAct | 7B | 21.1 [+11.2] |
| Image | UI-TARS-7B-SFT + 0-shot | 7B | 18.1 |
| Image | UI-TARS-7B-SFT + LearnAct | 7B | 32.8 [+14.7] |
Table 6: Performance comparison of different models on the LearnGUI-Online benchmark, showing task success rates with improvements for models enhanced with LearnAct.
To understand the contribution of each component in the LearnAct framework, the researchers conducted ablation experiments. Both DemoParser and KnowSeeker are essential, as removing either component leads to substantial performance degradation compared to the full framework.
| Ablation Setting | Average | Gmail | Booking | Music | SHEIN | NBC | CityMapper | ToDo | Signal | Yelp | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DemoParser | KnowSeeker | |||||||||||
| Baseline | 19.3 | 20.1 | 16.4 | 24.5 | 10.2 | 35.6 | 14.1 | 17.4 | 27.9 | 15.2 | ||
| $\checkmark$ | 40.6 | 47.7 | 31.3 | 55.4 | 29.1 | 47.0 | 43.0 | 58.2 | 48.8 | 50.7 | ||
| $\checkmark$ | 41.6 | 46.9 | 34.1 | 52.7 | 27.9 | 51.9 | 45.3 | 51.4 | 61.1 | 51.8 | ||
| $\checkmark$ | $\checkmark$ | 51.7 | 55.5 | 47.1 | 60.0 | 35.7 | 56.4 | 54.7 | 60.6 | 63.1 | 54.6 |
Table 7: Ablation study of LearnAct components showing performance comparison across four configurations and per-application breakdown across nine applications.
These findings validate the multi-agent framework design, confirming that both knowledge extraction (DemoParser) and relevant demonstration retrieval (KnowSeeker) play complementary and essential roles in enabling effective demonstration-based learning for mobile GUI agents.
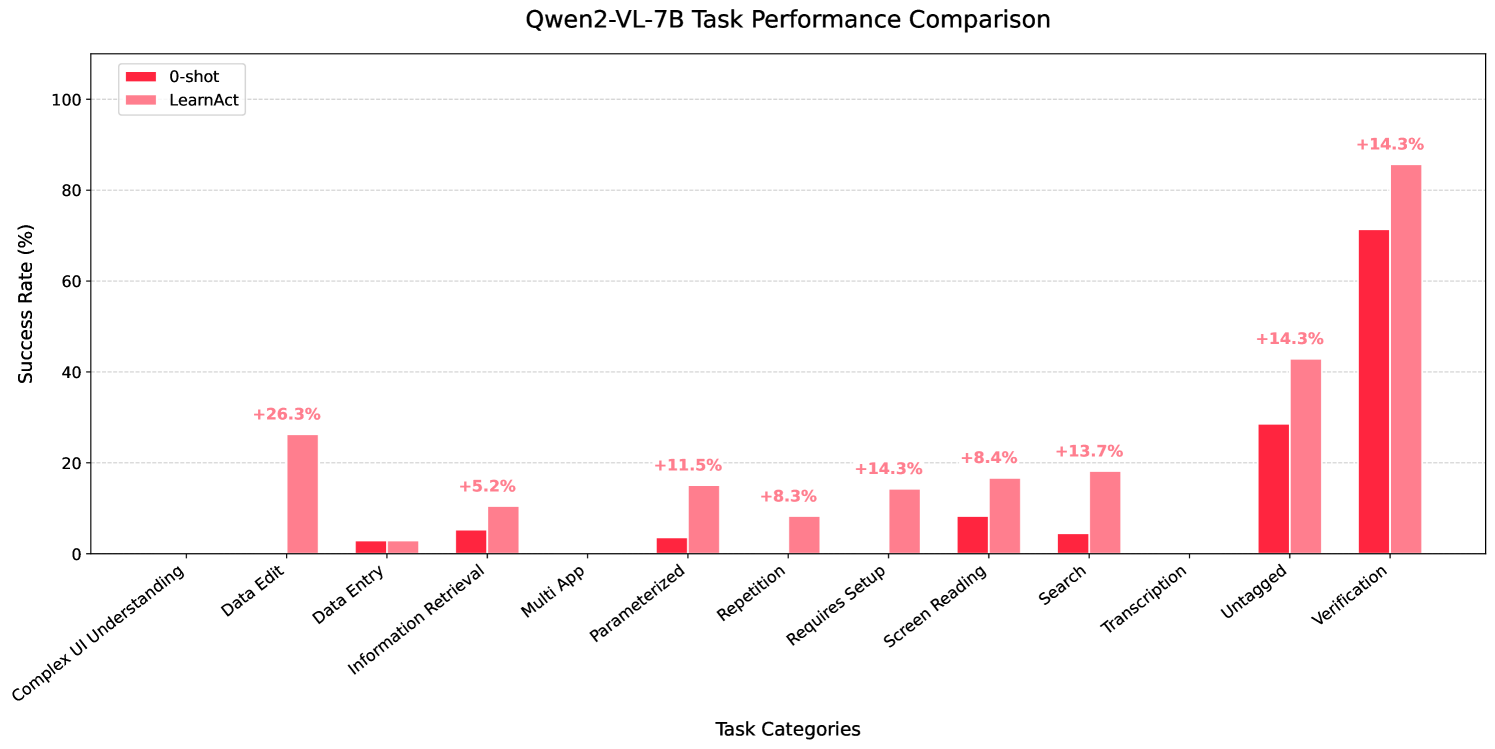
Detailed performance comparison of Qwen2-VL-7B with and without LearnAct on LearnGUI-Online, showing task success rates across different dimensions.
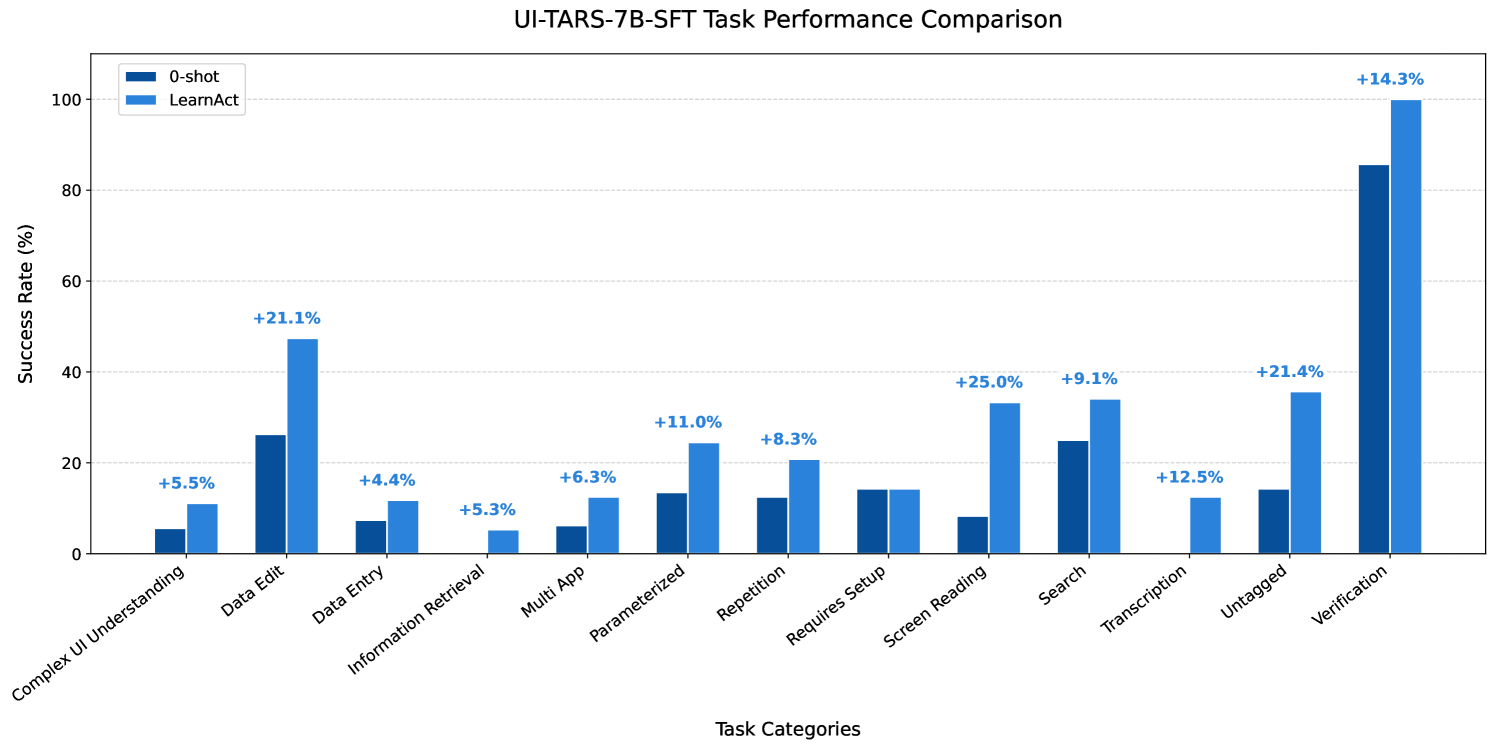
Detailed performance comparison of UI-TARS-7B-SFT with and without LearnAct on LearnGUI-Online, showing task success rates across multiple dimensions.
The comprehensive experimental results demonstrate that demonstration-based learning represents a promising direction for developing more adaptable, personalized, and deployable mobile GUI agents. For detailed information about this research, visit the LearnAct official paper resources.
Future Directions for Demonstration-Based Learning in Mobile GUI Agents
While the LearnAct approach shows promising results, several limitations and future directions warrant consideration.
First, regarding data collection and dataset expansion, the current dataset, while comprehensive, could benefit from greater diversity. Future work should expand to include a broader range of applications, particularly those with complex interaction patterns and specialized domains.
Second, k-shot learning analysis is currently limited to k=1, 2, and 3 demonstrations. A more comprehensive analysis of how demonstration quantity affects performance would be beneficial, potentially identifying optimal demonstration counts for different scenarios and model architectures.
Third, enhanced learning and execution strategies could better leverage the relationship between support tasks and query tasks. More sophisticated methods could be developed to extract and transfer knowledge more efficiently, including techniques for abstracting common patterns across demonstrations, identifying critical decision points, and adapting demonstrated strategies to novel scenarios.
Finally, agent self-learning represents a promising direction where agents learn from their own successful executions. By incorporating successful agent executions into the knowledge base, a form of "self-learning" could enable agents to continuously improve their capabilities through their own experiences.
By addressing these limitations and pursuing these research directions, demonstration-based learning can evolve into a robust paradigm for developing adaptable, personalized, and practically deployable mobile GUI agents that effectively address the diverse needs of real-world users.
Conclusion: Towards More Adaptable and Personalized Mobile Automation
The LearnAct framework introduces a novel demonstration-
