This is a Plain English Papers summary of a research paper called AI Model Security: Anti-Distillation Stops Copycat AI. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Protecting AI Models from Copy-Cats: Introduction to Antidistillation
Large language models (LLMs) that produce detailed reasoning traces inadvertently create valuable data that competitors can exploit. When these models generate step-by-step solutions to complex problems, they reveal rich token sequences that facilitate model distillation—where another model learns to replicate the original model's capabilities at a fraction of the training cost.
This vulnerability creates several problems for companies operating frontier reasoning models:
- Intellectual property loss - Companies effectively give away valuable proprietary capabilities
- Reduced transparency - Providers become incentivized to hide token probabilities and restrict user interaction
- Safety concerns - Distilled models often don't inherit important safety behaviors from the original models
To address these issues, researchers have developed antidistillation sampling—a method that strategically modifies a model's next-token probability distribution to "poison" reasoning traces. This approach renders the traces significantly less effective for distillation while preserving the model's practical utility.
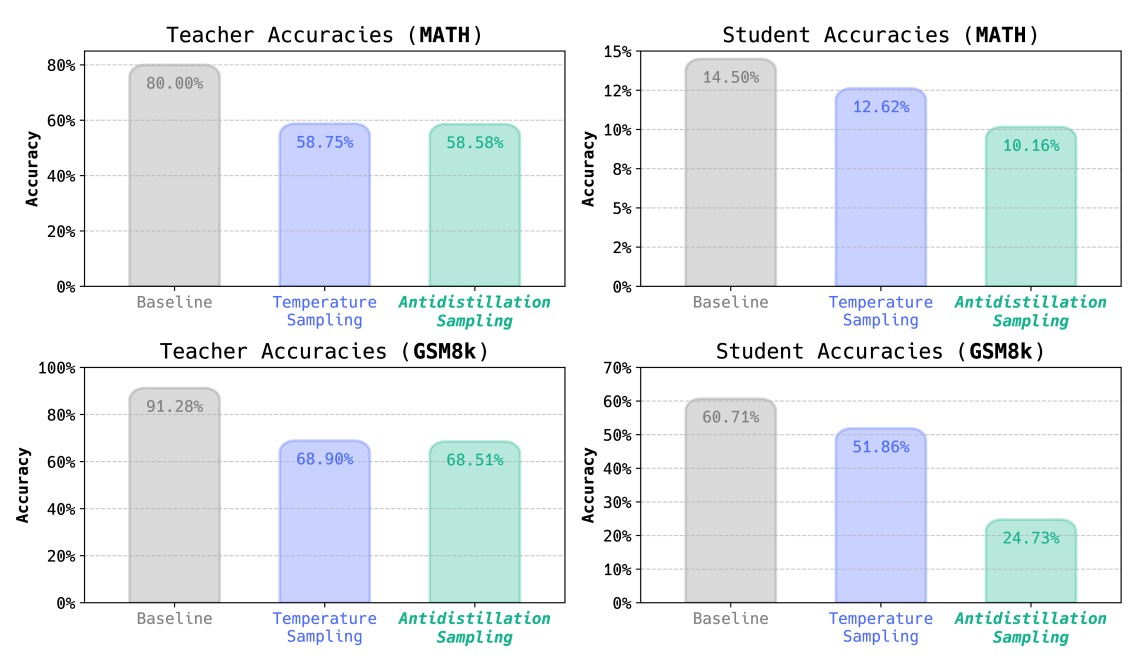
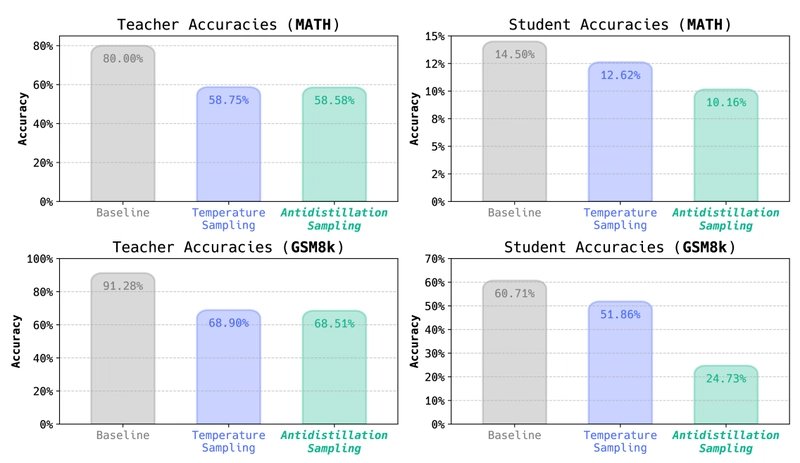
Reasoning traces generated via antidistillation sampling poison distillation attempts, while simultaneously preserving the teacher's downstream performance. The top and bottom rows shows results for MATH and GSM8K, respectively. The left columns shows teacher accuracies under different sampling schemes, and the right column shows the performance of students distilled on traces sampled via these different sampling schemes.
Various AI labs already recognize and benefit from the effectiveness of model distillation. OpenAI even offers distillation as a service within their API. The concept dates back to Schmidhuber's work and was further popularized by Hinton et al., who demonstrated that distilled "specialist" models could achieve impressive performance in multiple domains.
Industry speculation suggests that some labs train commercial LLMs partly via distillation, possibly by harvesting reasoning traces from competitor models. This represents a strategic vulnerability for frontier model providers and underscores the importance of antidistillation techniques.
How Antidistillation Sampling Works: Technical Foundations
The Technical Building Blocks
Antidistillation sampling balances two competing goals: sampling tokens with high likelihood under the original distribution and sampling tokens that effectively poison distillation attempts.
The method must satisfy two key requirements:
Non-distillability: Student models trained on tokens sampled via antidistillation should perform worse on downstream tasks compared to training on tokens from the teacher's normal distribution.
Nominal utility: Tokens sampled via antidistillation should remain probable under the teacher's unadjusted sampling scheme, ensuring the model's output still serves its intended purpose.
In a typical language model, tokens are generated according to a scaled version of a probability distribution. With temperature sampling (the standard approach), tokens are sampled using:
xt+1 ~ (1/Z) * exp(log p(·|x1:t;θ)/τ)Where τ is the temperature parameter and Z is a normalization term. Temperature sampling allows control over the randomness of outputs, but it doesn't specifically target distillation resistance.
Antidistillation sampling, by contrast, modifies this distribution to include a term that specifically poisons distillation attempts. This approach bridges data poisoning and privacy techniques to protect valuable knowledge encoded in frontier models.
Mathematical Derivation
The core insight of antidistillation sampling is to incorporate a metric directly into the teacher's sampling distribution that quantifies how model distillation impacts student performance.
The method starts by defining a differentiable, real-valued downstream loss ℓ that measures model performance on a given task (such as the negative log-likelihood for generating tokens on a benchmark dataset). The goal is to make this loss increase whenever the student is fine-tuned on the teacher's outputs.
To accomplish this, antidistillation sampling strategically adjusts the next-token distribution to balance high likelihood under the original model with tokens that will lead to poor student performance when used for distillation.
The full mathematical derivation involves computing a directional derivative that captures the change in the teacher's sampling distribution along the update direction in the student's weight space. Since this is computationally expensive, the researchers developed an efficient finite-difference approximation that maintains effectiveness while being practical to compute.
The result is a modified sampling distribution that preserves the utility of the original model while poisoning distillation attempts. This approach shares conceptual similarities with other controlled decoding methods for LLMs, but solves a different problem by implementing a distillation-aware penalization term.
Proving It Works: Experimental Results
To demonstrate antidistillation sampling's effectiveness, the researchers conducted experiments using:
- Teacher model: deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
- Proxy model: Qwen/Qwen2.5-3B
- Student model: meta-llama/Llama-3.2-3B
They evaluated performance on two challenging benchmarks:
- GSM8K: A grade school math word problem dataset
- MATH: A competition-level mathematics problem dataset
Both benchmarks require high-quality reasoning traces, making them ideal for testing distillation effectiveness.
The primary baseline for comparison was temperature sampling, which approximates what an API endpoint might typically use.
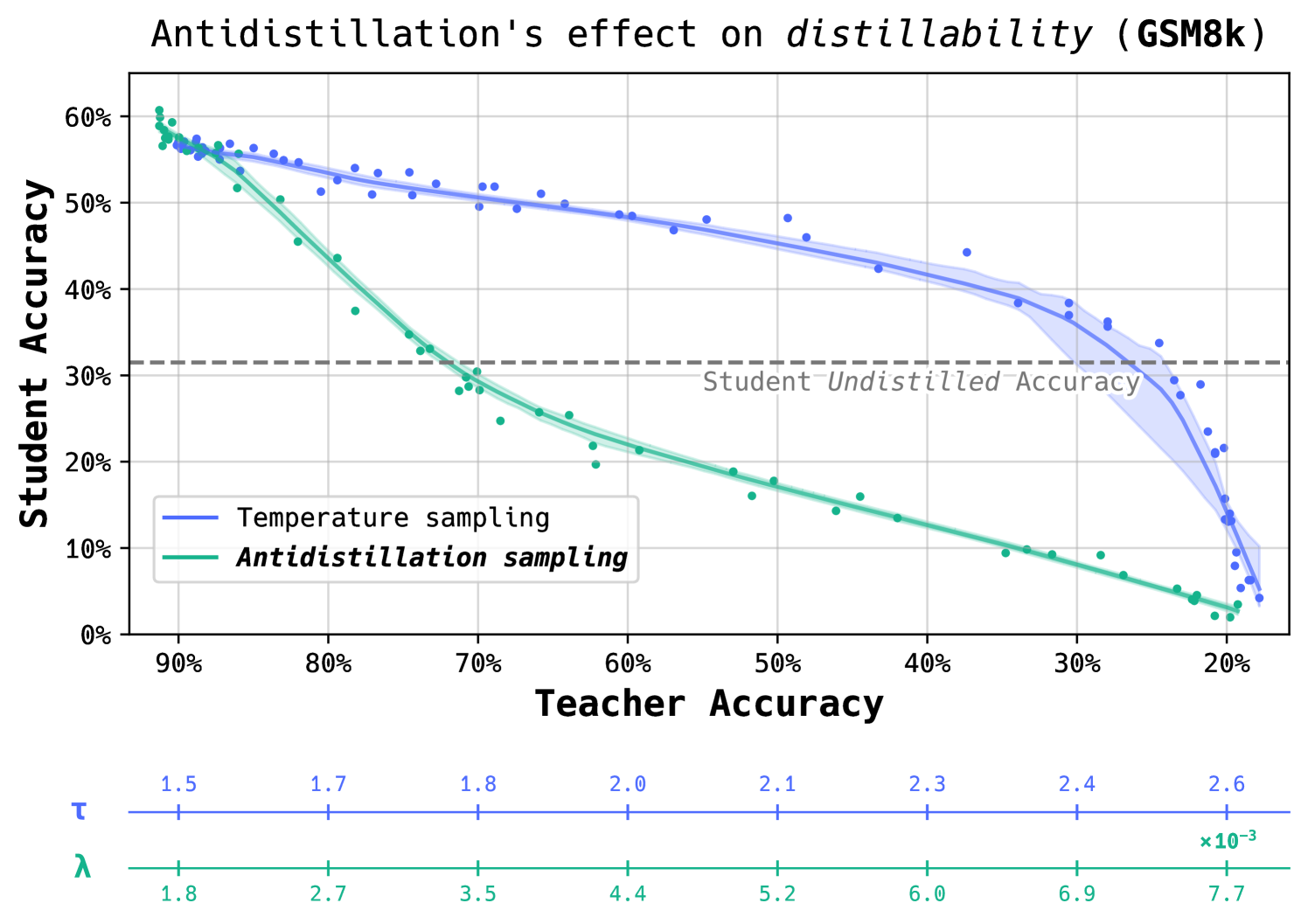
Antidistillation sampling uses a tunable parameter λ to control the trade-off between teacher accuracy and distillability. One important feature of the temperature sampling curve is that bringing student accuracy below undistilled accuracy requires teacher performance to drop to 20%. With antidistillation sampling, the teacher can maintain 70% accuracy while producing traces that reduce student performance below undistilled accuracy.
The results demonstrate that antidistillation sampling effectively meets its design goals. For the same teacher accuracy on both datasets, students distilled from traces sampled via antidistillation sampling performed significantly worse than those trained on temperature sampling traces.
A key parameter in antidistillation sampling is λ, which controls the trade-off between teacher performance and distillability. By varying λ, model owners can precisely tune how much they want to prioritize maintaining original model performance versus preventing effective distillation.
Notably, the researchers used different architectures for student and proxy student models, indicating that antidistillation sampling can generalize across different model architectures. This is crucial for real-world applications where the architecture of potential distillation attempts may be unknown. These findings align with other research on inference-time distillation techniques, but apply them in a novel protective context.
Implications and Future Directions
The value of proprietary frontier LLMs necessitates that their owners protect their assets. While companies already limit exposure to their models via black-box APIs, this research provides a proof-of-concept that antidistillation sampling can effectively block distillation attacks while maintaining model utility.
The approach intersects with several aspects of model privacy and security, including model extraction attacks and training data extraction attacks. While antidistillation sampling may offer some protection against these broader threats, its primary purpose is to prevent capability transfer through distillation.
This technique provides model owners with a practical tool for protecting their intellectual property without compromising user experience. By implementing antidistillation sampling, companies can continue to offer powerful reasoning capabilities without inadvertently enabling competitors to replicate their models.
Future work could focus on refining and scaling this approach, particularly as frontier models continue to evolve. Additional research might explore the interplay between antidistillation and other security considerations, such as training data extraction and model extraction attacks.
Additional Technical Details and Resources
Alternative Approaches Compared
To ensure the computation involved in antidistillation sampling is worthwhile, the researchers compared it to a baseline method called "permutation sampling." This approach adds random perturbations to the logits by randomly permuting and flipping the sign of the perturbations computed with antidistillation sampling.
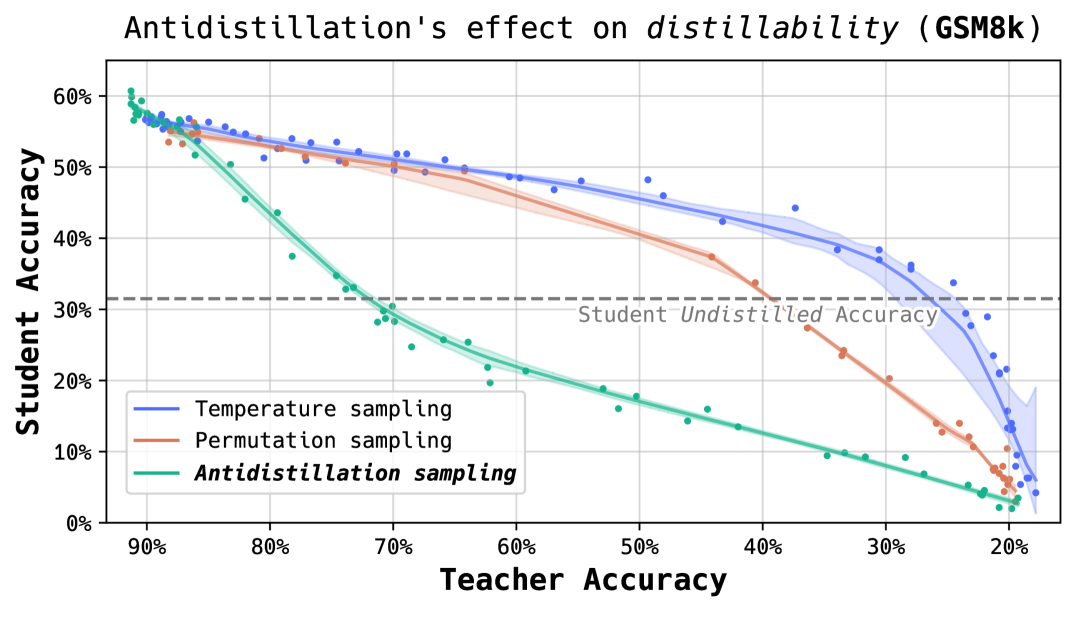
Permutation sampling is a strong baseline where we destroy the information in antidistillation sampling while preserving statistical properties via random permutation and sign flipping.
The comparison helps validate that the specific perturbation pattern computed by antidistillation sampling—not just any perturbation—is what creates the desired effect.
Additional example traces can be found at https://antidistillation.com/traces, providing real-world illustrations of how antidistillation sampling affects model outputs.
Validating the Mathematical Approximations
A critical component of antidistillation sampling is the finite difference approximation used to estimate directional derivatives. The researchers empirically verified that this approximation behaves as expected by computing the relative error between the finite difference result and term produced from autograd.

Relative error between the finite difference and the JVP results.
Due to memory constraints, this verification was performed using GPT2-Large. The analysis demonstrates that finite differences can effectively estimate derivatives in low-precision BFloat16 format, which is common in large model deployments.
The choice of epsilon (ε) is crucial: too small a value leads to round-off error in the perturbation, while too large a value causes high truncation error in the Taylor expansion. For their main experiments, the researchers empirically determined ε = 10^-4 to be effective for the BFloat16 models used.
This validation helps ensure that the simplified computational approach maintains the desired theoretical properties while remaining practical for real-world implementation with large language models.
