
This is a Plain English Papers summary of a research paper called AI Overthinking? New Tool Cuts Wasteful Token Use in Reasoning Models. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Problem of Overthinking in AI Reasoning Models
Reasoning models are delivering impressive performance on challenging tasks, but they have a costly flaw: they generate excessive tokens that don't improve accuracy. This problem, known as overthinking, wastes computational resources and increases inference costs unnecessarily.
The researchers introduce three key contributions to address this issue: 1) developing measures of problem-level difficulty that demonstrate the relationship between difficulty and optimal token spend, 2) creating the dumb500 dataset to evaluate overthinking on extremely simple problems, and 3) introducing ThoughtTerminator, a training-free decoding technique that significantly improves reasoning model calibration.

Figure 1: Question-level difficulty vs average token spend across models for three reasoning datasets. Difficulty scores are scaled by 10 and mapped to integers from 1 to 10 for readability. A clear relationship exists between question difficulty and token spend distribution.
This research builds on prior work exploring efficient reasoning in large language models, but uniquely focuses on difficulty-calibrated token budgeting to maximize efficiency without sacrificing performance.
How Difficulty Relates to Token Spend in Reasoning
The researchers formalize question difficulty as the inaccuracy rate of models when answering a specific question. This operational definition captures how challenging a problem is for current AI systems rather than relying on human judgment.
Their analysis reveals a clear relationship between question-level difficulty and the average token spend across multiple datasets: MATH500, GPQA, and ZebraLogic. As questions get harder, models naturally spend more tokens attempting to solve them, but they do so inconsistently.
| Model | Local overthinking $O_{\text {env }} \downarrow$ | Global overthinking $O_{g} \downarrow$ |
|---|---|---|
| Non-reasoning language models | ||
| Qwen2-7B-Instruct | 291 | 219 |
| Llama-3.2-1B-Instruct | 542 | 354 |
| Llama-3.2-3B-Instruct | 708 | 473 |
| Llama-3.1-8B-Instruct | 1971 | 1755 |
| gemma-2-2b-it | 148 | 152 |
| gemma-2-9b-it | 131 | 161 |
| gemma-2-27b-it | 178 | 187 |
| deepseek-1lm-7b-chat | 155 | 90 |
| Reasoning language models | ||
| QwQ-32B-Preview | 2923 | 3698 |
| QwQ-32B | 13662 | 11248 |
| DeepSeek-R1-Distill-Qwen-1.5B | 5730 | 4262 |
| DeepSeek-R1-Distill-Llama-8B | 4232 | 5755 |
| DeepSeek-R1-Distill-Qwen-7B | 3881 | 4001 |
Table 1: Local and global overthinking scores across various reasoning and non-reasoning language models, showing that reasoning models have considerably higher overthinking tendencies.
This finding relates to other research on reasoning efficiency, such as thoughts being all over the place in underthinking models, which explores the inverse problem of insufficient token allocation.
Measuring Overthinking Quantitatively
The researchers define two key metrics to measure overthinking:
Global overthinking score (Og): The mean difference between a model's average token spend and the global minimum spend observed across all models for each question.
Local envelope overthinking score (Oenv): The mean difference between the maximum and minimum token spend within a single model for each question.
These metrics reveal that reasoning models (QwQ and DeepSeek-R1 variants) exhibit significantly higher overthinking tendencies than non-reasoning models, with some wasting over 10,000 tokens per question on average.
The dumb500 Dataset: Testing Models on Simple Questions
While overthinking on hard problems is expected, a crucial gap existed in evaluating how models handle extremely simple questions. The researchers created dumb500, a dataset of 500 deliberately simple questions that humans can answer with minimal cognitive effort.
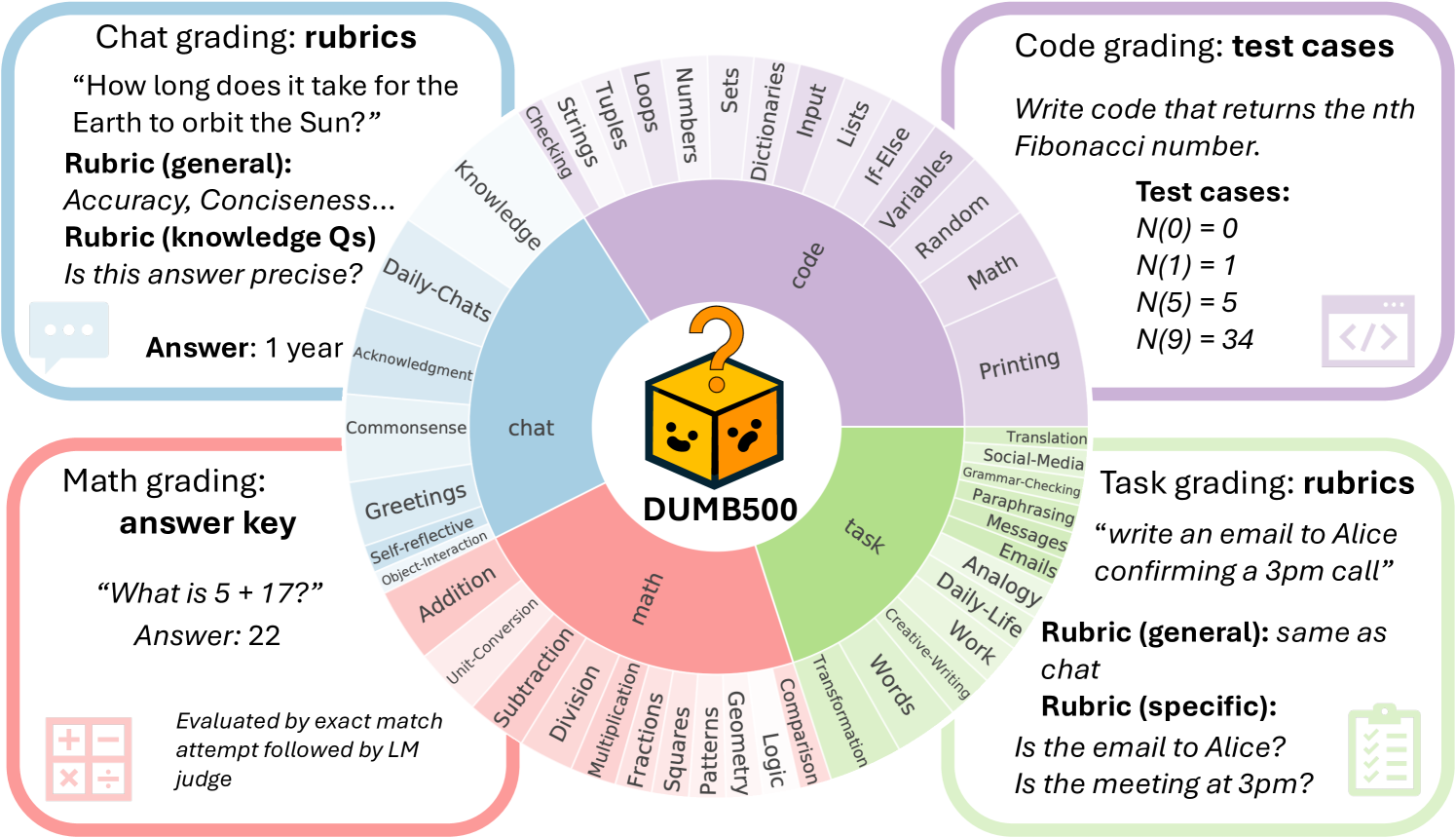
Figure 2: dumb500 dataset composition and grading method. The dataset contains four subsets (chat, code, task & math), each evaluated with domain-specific methods.
dumb500 spans four domains:
- Mathematics: Basic arithmetic, comparisons, and simple logical reasoning
- Conversational Interaction: Casual dialogue, self-reflection, common knowledge
- Programming & Computing: Fundamental coding concepts and data structures
- Task Execution: Simple natural language processing tasks
The goal is to evaluate models on two dimensions: accuracy (can they answer correctly?) and efficiency (can they do so concisely?).
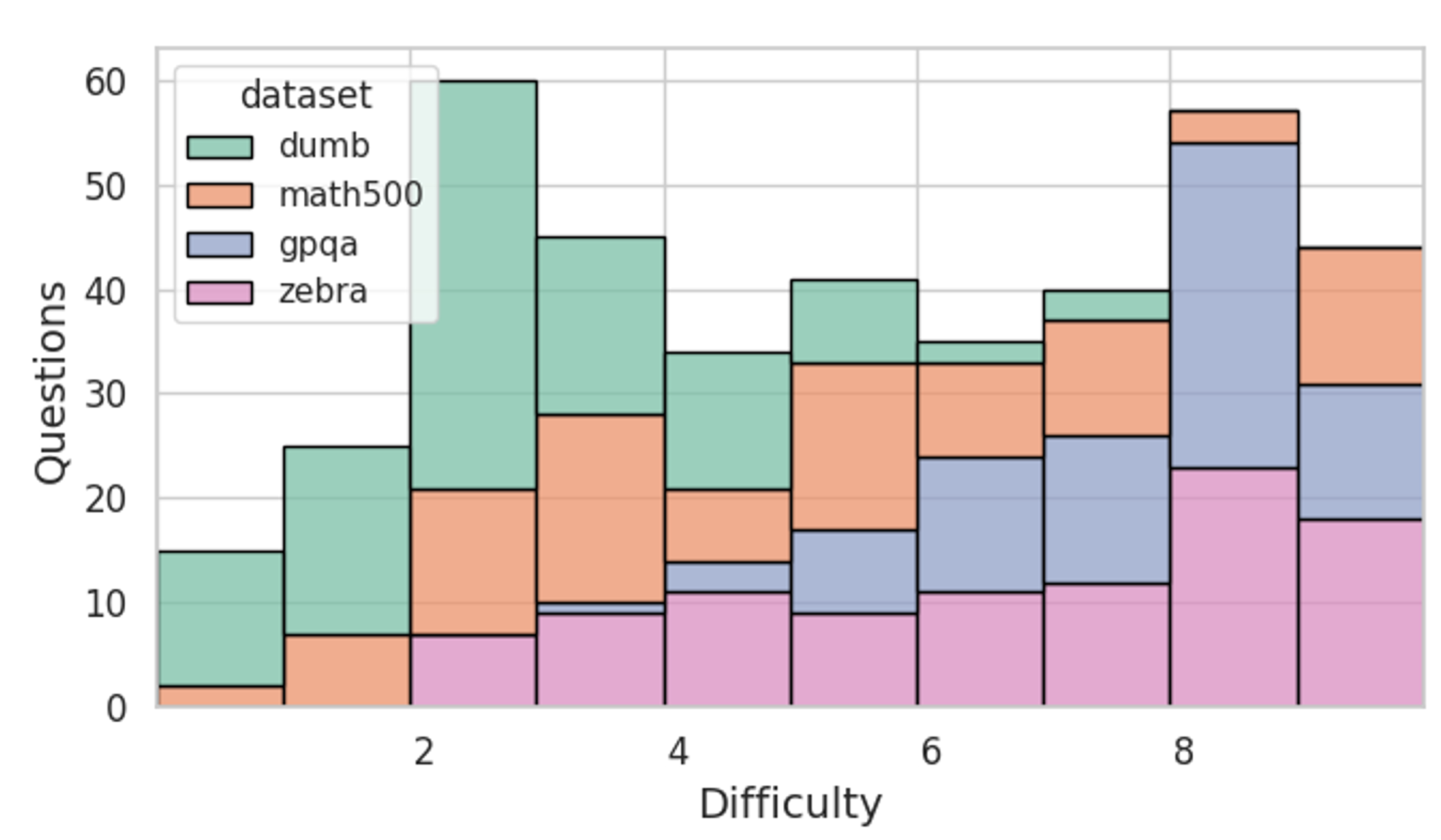
Figure 3: Total difficulty distribution of the four datasets evaluated in this work. By including dumb500 in the analysis, the researchers can characterize overthinking behavior more consistently across the difficulty spectrum.
Specialized Evaluation Methods for Different Question Types
Each domain in dumb500 requires different evaluation approaches:
- Math questions: Evaluated using simple accuracy methods, identical to MATH500, GPQA, and ZebraLogic
- Code questions: Include test cases for the program described in the prompt, with a Python-based autograder
- Chat questions: Evaluated on requirements like appropriateness and conciseness using a GPT-4o judge
- Task questions: Assessed based on generic requirements and question-specific criteria for following instructions
This comprehensive evaluation framework allows for consistent assessment across diverse question types.
Analyzing Model Performance from Easy to Hard Questions
When testing the same models on dumb500, the researchers found that token spend has no positive correlation with accuracy on simple math questions - and sometimes even shows a negative relationship for other domains.
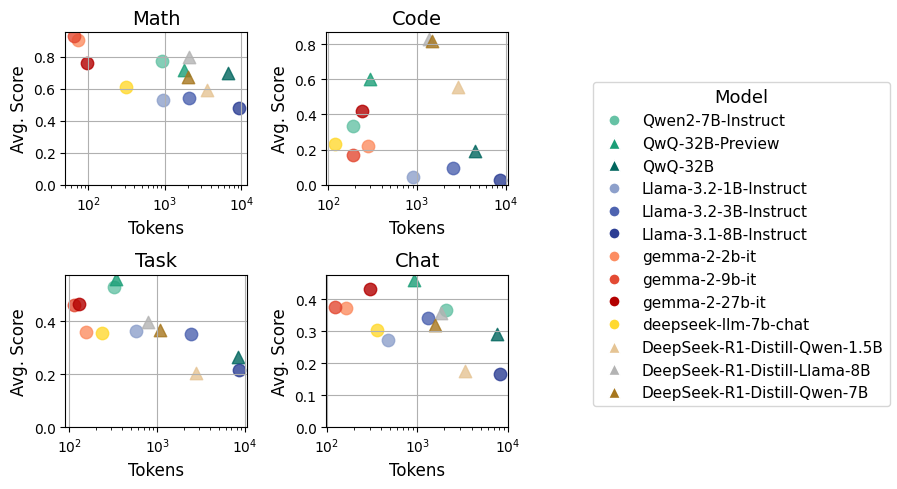
Figure 4: Relationship between average token spend and average score for the evaluated models on each subset of dumb500.
This confirms that models are poorly calibrated on easy problems, often spending unnecessary tokens without improving performance. This finding aligns with research on thinking in tokens in language modeling, which examines how models allocate computational resources during inference.
ThoughtTerminator: A Solution to Control Overthinking
ThoughtTerminator addresses overthinking by leveraging an insight: reasoning models often express uncertainty through phrases like "wait..." or "let me check this..." when they need to think longer. By using simple text-augmentation methods, the system reminds models how long they've been generating output and nudges them to provide answers more efficiently.

Figure 5: ThoughtTerminator uses a reasoning model's calibrated estimate of the difficulty of a problem to set its intervention, periodically interrupting the reasoning model's output to remind it of the amount of remaining tokens. Once the token allotment has been used, it forces the model to provide an answer with constrained decoding.
ThoughtTerminator operates in three stages:
- Scheduling: Estimates the necessary token budget based on question difficulty
- Running: Periodically interrupts generation with messages showing tokens used and remaining
- Terminating: Forces answer generation with constrained decoding if the budget is exhausted
This approach doesn't require model retraining and operates as a black-box solution, making it broadly applicable across reasoning models. This aligns with research on token-budget-aware LLM reasoning.
Experimental Results: ThoughtTerminator's Effectiveness
ThoughtTerminator dramatically reduces overthinking while maintaining or even improving accuracy across multiple datasets and models.
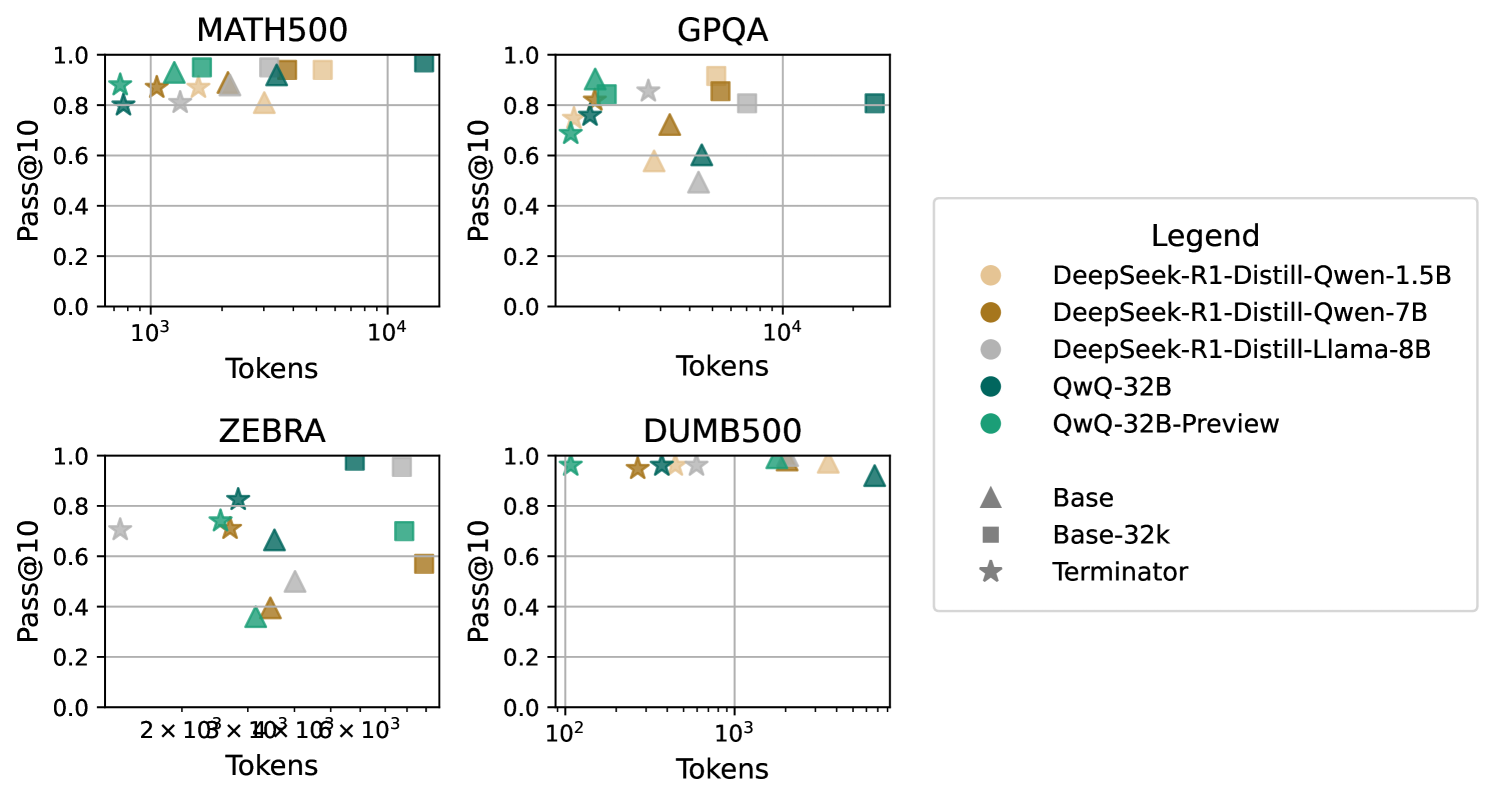
Figure 6: Comparison of the relationship between Pass@10 and token spend for the evaluated reasoning models in the "Base" setting and with ThoughtTerminator.
The results show significant reductions in token usage:
| Model | Base | Thought Terminator | ||||
|---|---|---|---|---|---|---|
| Local $O_{\text {env }} \downarrow$ | Global $O_{g} \downarrow$ | Accuracy $\uparrow$ | Local $O_{\text {env }} \downarrow$ | Global $O_{g} \downarrow$ | Accuracy $\uparrow$ | |
| QwQ-32B-Preview | 2923 | 3698 | 0.80 | 518 (-82\%) | 693 (-81\%) | $0.79(-1 \%)$ |
| QwQ-32B | 13662 | 11248 | 0.94 | 215 (-98\%) | 1021 (-91\%) | $0.80(-15 \%)$ |
| R1-1.5B | 5730 | 4262 | 0.50 | 696 (-88\%) | 882 (-79\%) | $0.80(+59 \%)$ |
| R1-7B | 3881 | 4001 | 0.73 | 678 (-83\%) | 948 (-76\%) | $0.81(+11 \%)$ |
| R1-8B | 4232 | 5755 | 0.92 | 725 (-83\%) | 1148 (-80\%) | $0.80(-13 \%)$ |
Table 2: Local and global overthinking scores, along with accuracy for reasoning models under the Base setting and with ThoughtTerminator. The technique reduces overthinking by up to 98% while maintaining or improving accuracy.
Finding the Optimal Token Budget
A critical aspect of ThoughtTerminator is determining the right token budget for each question. The researchers compared different methods for setting deadlines, including fixed token counts and difficulty-based predictions.
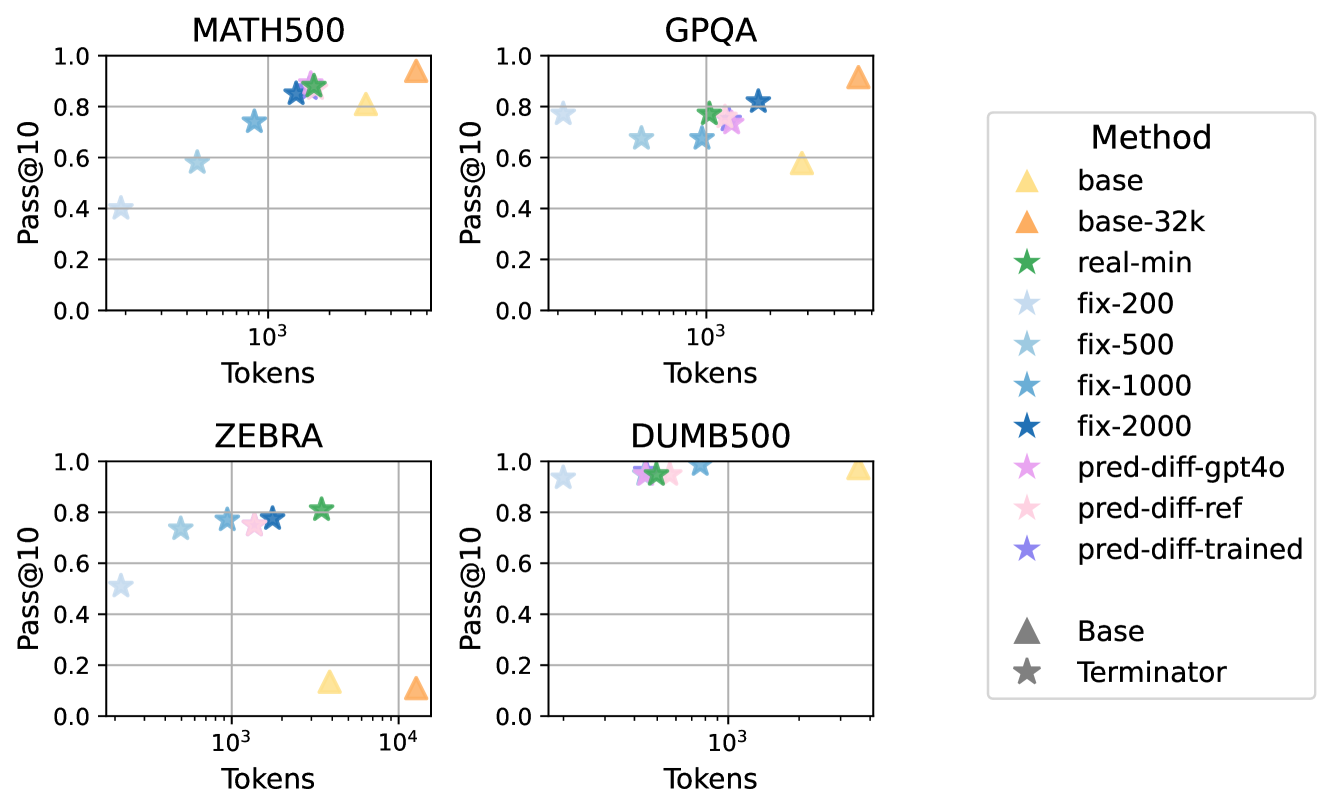
Figure 7: Calibration ablation experiment using DeepSeek-R1-1.5B. Various methods for setting token deadlines are compared, with difficulty-based predictions (pred-diff-trained) achieving optimal or near-optimal performance while minimizing token spend.
Their trained difficulty predictor (pred-diff-trained) achieved optimal results on MATH500 and dumb500, and nearly optimal results on ZebraLogic and GPQA, confirming that difficulty-calibrated token budgeting is more effective than fixed limits.
The Impact of Periodic Reminders
The periodic interrupt messages in ThoughtTerminator play an important role in its effectiveness. Compared to a naïve baseline that simply cuts off generation at a deadline without warning, ThoughtTerminator shows better performance, especially on mathematical tasks.
| Setting | Acc. | Pass@5 | Pass@10 | Tokens |
|---|---|---|---|---|
| MATH500 | ||||
| Base | 0.47 | 0.78 | 0.81 | 3015 |
| Naïve | 0.52 | 0.78 | 0.82 | 1938 |
| ThoughtTerminator | 0.48 | 0.81 | 0.87 | 1590 |
| Zebra-logic | ||||
| Base | 0.03 | 0.095 | 0.135 | 3861 |
| Naïve | 0.22 | 0.575 | 0.755 | 1254 |
| ThoughtTerminator | 0.19 | 0.585 | 0.75 | 1368 |
| GPQA | ||||
| Base | 0.15 | 0.4096 | 0.5783 | 2815 |
| Naïve | 0.20 | 0.5783 | 0.7470 | 922 |
| ThoughtTerminator | 0.21 | 0.5542 | 0.7470 | 1279 |
| DUMB500 | ||||
| Base | 0.58 | 0.9646 | 0.9735 | 3570 |
| Naïve | 0.37 | 0.7385 | 0.8154 | 377 |
| ThoughtTerminator | 0.67 | 0.9610 | 0.9610 | 447 |
Table 3: Comparison of performance and token spend of R1-1.5B under the Base Setting, with Naïve, and with ThoughtTerminator.
The results show that ThoughtTerminator outperforms the naïve approach by 6% on MATH500 and 18% on dumb500-math in terms of accuracy, suggesting that the intermediate interrupt messages help the model adjust its thinking process more gracefully.
Key Takeaways and Future Directions
This research demonstrates that reasoning models suffer from considerable overthinking, especially on simple questions. By analyzing the relationship between question difficulty and optimal token spend, the researchers developed ThoughtTerminator, a simple but effective solution that:
- Reduces token usage by up to 98% while maintaining accuracy
- Works without requiring model retraining
- Uses difficulty-calibrated token budgeting to maximize efficiency
- Employs periodic reminders to guide models toward concise answers
The introduction of dumb500 also provides a valuable benchmark for evaluating AI systems on simple tasks, complementing existing benchmarks that focus on challenging problems.
This work opens possibilities for more efficient AI reasoning systems that can appropriately allocate computational resources based on task difficulty. Future research could explore more sophisticated difficulty estimation techniques and adaptive interrupt strategies to further improve calibration.
For more details on this approach, see the original research: ThoughtTerminator: Benchmarking, Calibrating, and Mitigating Overthinking in Reasoning Models.
