This is a Plain English Papers summary of a research paper called AI's Creative Block: Why Next-Token Prediction Fails "Leap-of-Thought" Tasks. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Introduction: The Creative Limits of Next-Token Prediction
Creativity in AI goes beyond correctness - it requires generating diverse, original responses that make fresh connections and satisfy constraints in novel ways. These capabilities grow more crucial as we deploy language models for scientific discovery, generating training data, and complex reasoning tasks.
In this research, the team designs minimal algorithmic tasks that abstract real-world creative challenges, allowing them to rigorously quantify the creative limits of current language models. Their work reveals how next-token prediction fundamentally struggles with tasks requiring a "leap of thought" - an implicit search-and-plan process that orchestrates multiple random decisions before generating output.
The researchers challenge two aspects of current language modeling paradigms: (1) next-token learning itself and (2) how models elicit randomness. Their findings suggest that multi-token approaches like teacherless training and diffusion models excel at producing diverse and original output compared to standard next-token prediction, which tends toward myopic learning and excessive memorization.
Rather than evaluating subjective real-world creativity, which invites debate, they create controllable algorithmic tasks to provide more definitive conclusions about what limits creative generation in language models, building on insights from the pitfalls of next-token prediction.
Open-Ended Algorithmic Tasks & Two Types of Creativity
The researchers distinguish between simple open-ended tasks (like generating random names) and those requiring a creative leap of thought. In the latter, coherence requires satisfying "global" constraints rather than just local next-token patterns.
Understanding the Creative Process
Inspired by cognitive science literature (Boden, 2003), they identify two fundamental types of creativity:
Combinational creativity: Making unexpected connections between familiar ideas. This includes wordplay like "What musical genre do balloons enjoy? Pop music," where the punchline connects two previously unrelated concepts. Scientific research and drawing analogies also rely on this form of creativity.
Exploratory creativity: Constructing novel patterns that satisfy non-trivial constraints. This includes designing logical puzzles or mysteries that must be resolvable according to certain rules. This form involves searching through possible sequences rather than knowledge.
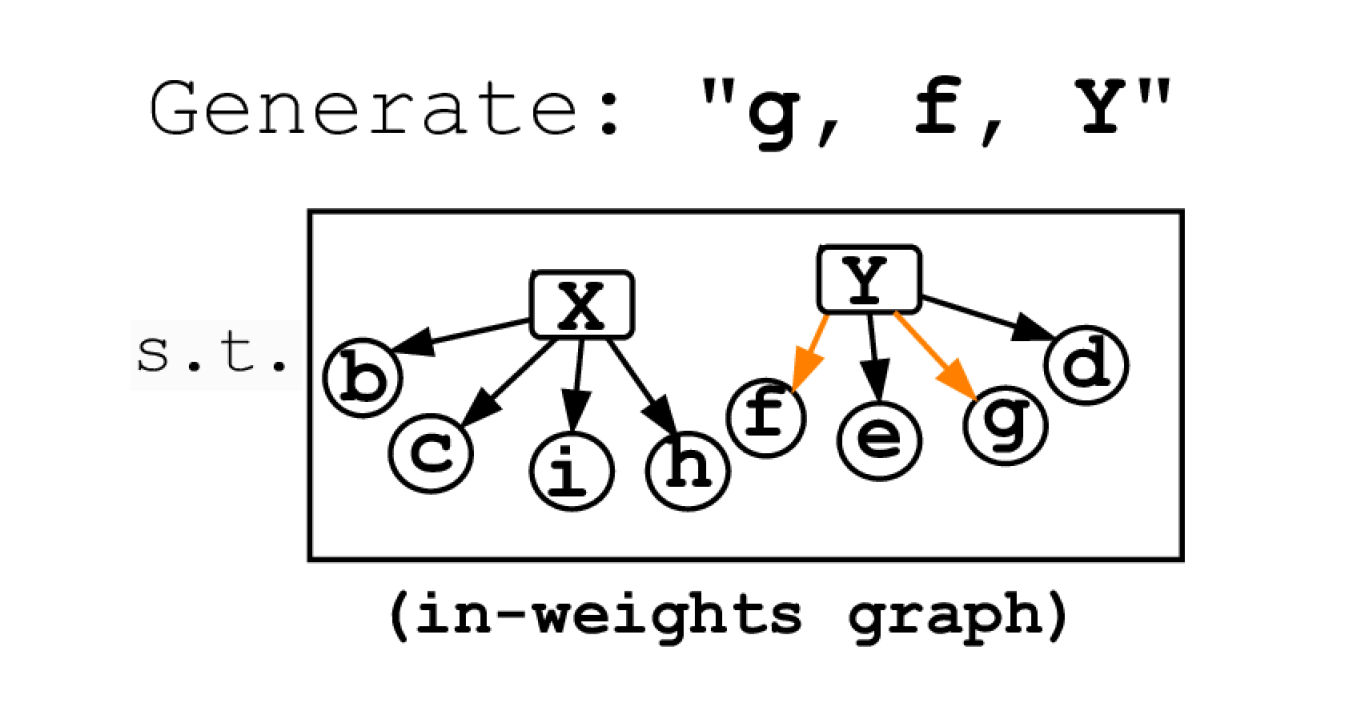
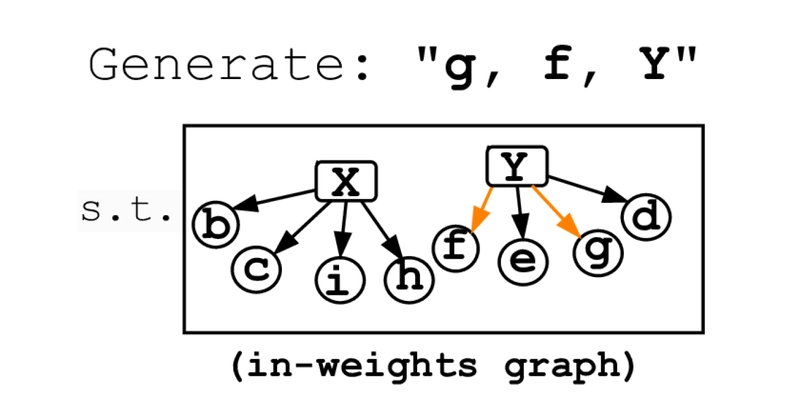
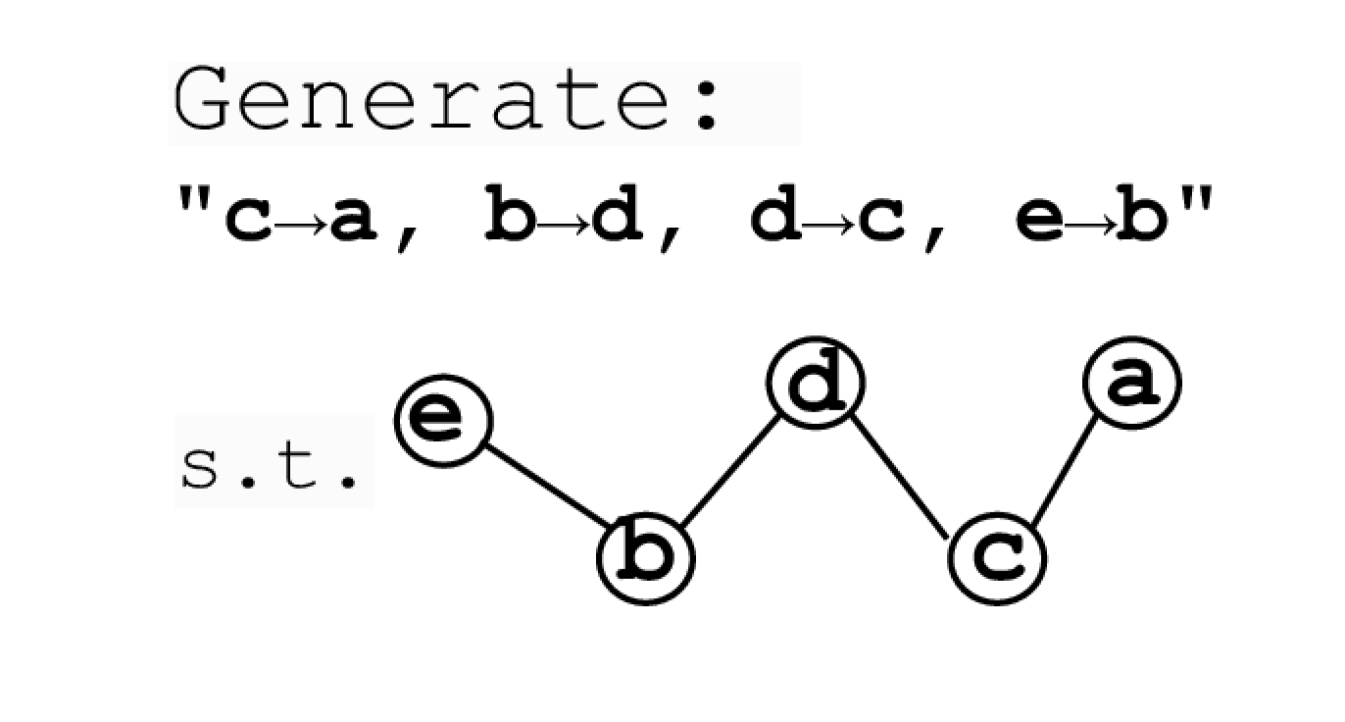
The in-weights graph represents the underlying knowledge graph used to generate the training data. Generated samples that are incoherent, memorized, or duplicated don't count as valid samples.
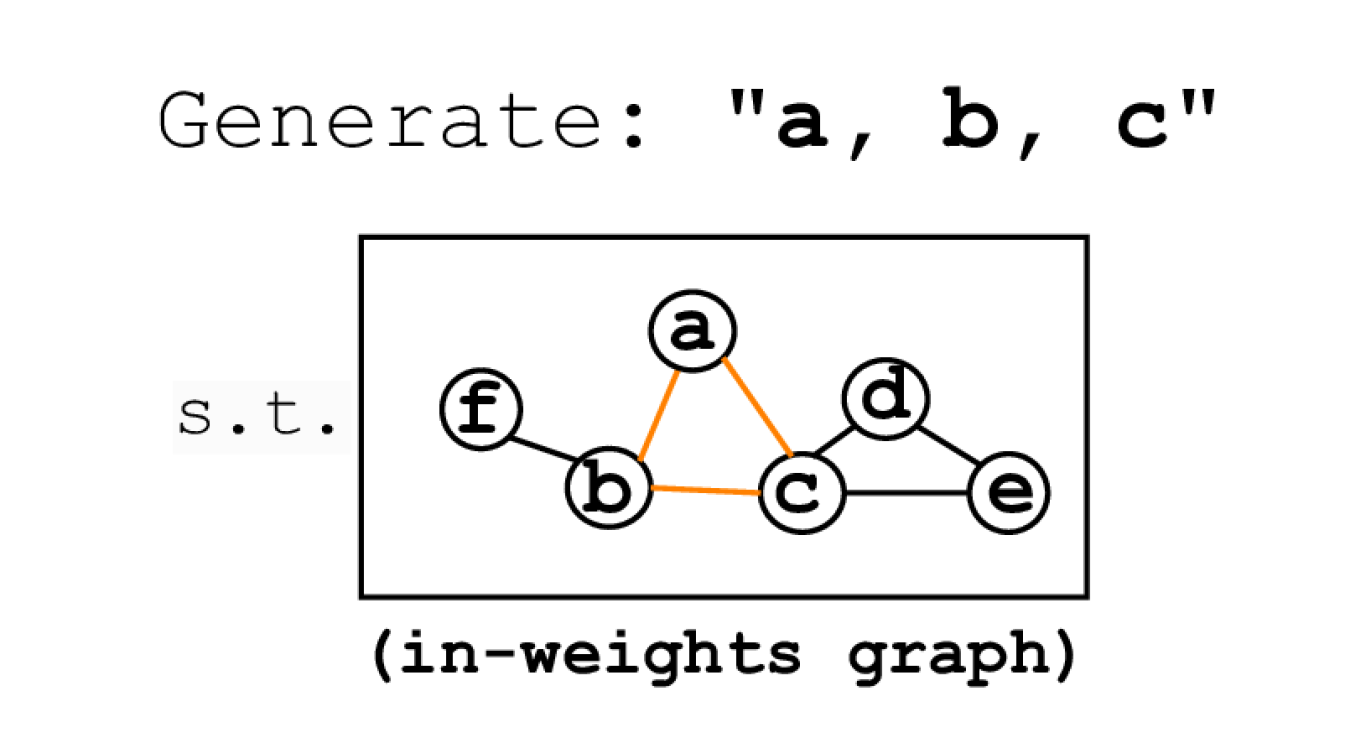
Triangle Discovery task requires finding three-node cycles in a graph, representing a higher-order planning process in combinational creativity.
The Four Algorithmic Tasks
The researchers create four specific tasks that capture different aspects of creative thinking:
- Sibling Discovery: Finding connected nodes in a bipartite graph where siblings must share a parent node.
- Triangle Discovery: Finding three-node cycles in a graph, requiring higher-order planning.
- Circle Construction: Creating circle graphs through edge rearrangement.
- Line Construction: Creating line graphs through edge rearrangement.
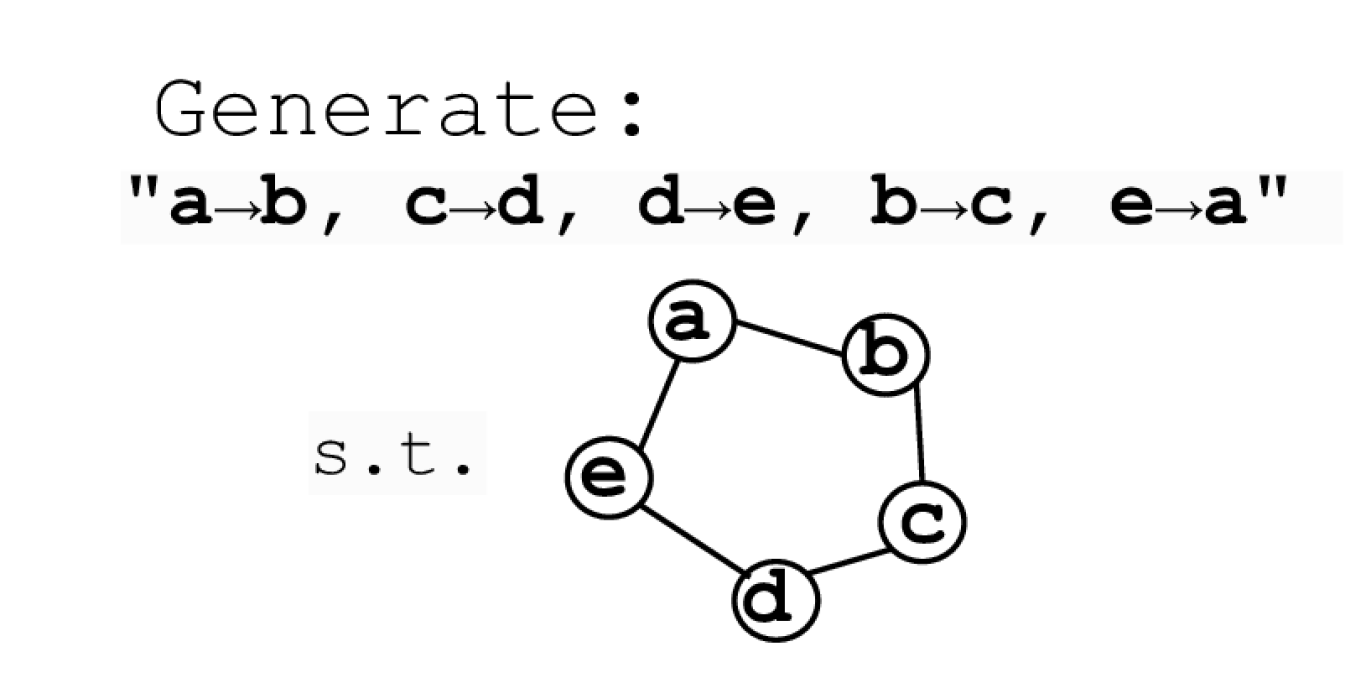
The constructed graph visualizes the graph induced by the training or generated sample. Edge indices represent the order of edge appearing in the string.
The key novelty is that these tasks are permutation-invariant—no token is more privileged than another, requiring all tokens to be "simultaneously learned" to infer the underlying process. This mimics real-world creative tasks where the creative process is highly implicit.
Why Next-Token Learning Struggles
The researchers argue that next-token prediction (NTP) is fundamentally misaligned with creative leap-of-thought tasks. While the most natural way to generate creative outputs is to plan latent choices in advance, NTP is myopic:
- Instead of learning a latent plan, NTP exploits "Clever Hans cheats" where the model uses partial information to predict the next token.
- This causes the model to memorize patterns from training data rather than learning how to generate novel combinations.
- For example, in Sibling Discovery, rather than planning which parent connects two siblings, the model learns to predict the parent based on already seeing the siblings.
This mechanism makes NTP far more data-hungry than approaches that learn to plan, similar to the challenges demonstrated in algorithmic capabilities research.
Training and Inference Methods
The researchers compare three main approaches:
Standard Transformer with next-token prediction (NTP): Using the teacher-forcing objective where the model predicts each token given the previous ground truth tokens.
Transformer with teacherless multi-token training: The model is trained to predict all tokens simultaneously given only a prompt (with dummy tokens replacing what would be inputs).
Discrete diffusion models: Rather than predicting tokens sequentially, these models iteratively add and remove noise from all tokens, allowing them to capture global dependencies.
Hash-Conditioning: A Novel Approach
For prompt-free generation tasks, standard approaches use temperature sampling to increase diversity. However, the researchers introduce "hash-conditioning" as an alternative:
- Instead of using fixed pause tokens or null prefixes, they prepend a random hash string unique to each training example
- During test time, they prompt with novel hash strings to extract fresh data
- This approach helps the model coordinate random decisions in advance rather than on-the-fly
- It also appears to help the model focus on one thought path per sample
This approach provides a way to look beyond next-token prediction by injecting randomness at the input rather than the output layer.
Experimental Results
The experiments use Gemma v1 (2B), a 90M parameter SEDD diffusion model, and an 86M parameter GPT-2 model to ensure fair comparisons.
Key Findings on Algorithmic Creativity
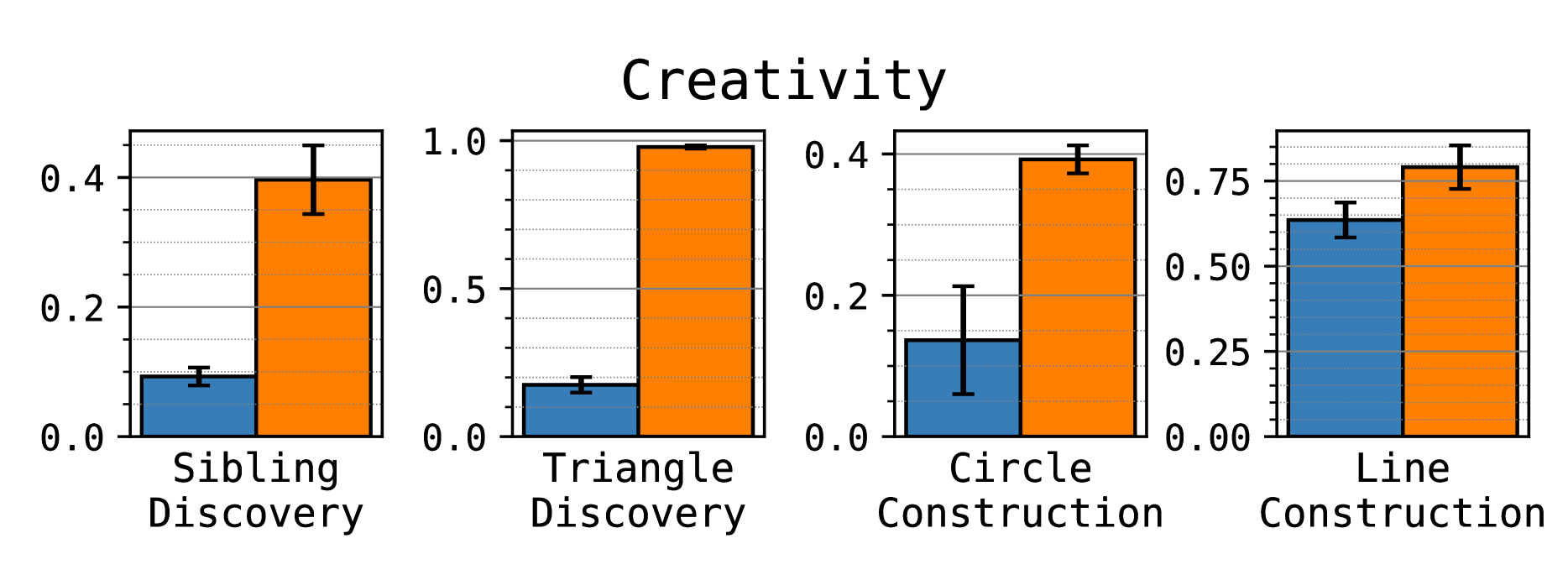
The results show that multi-token prediction significantly improves algorithmic creativity:
Multi-token diffusion training improves algorithmic creativity (top) on the four open-ended algorithmic tasks, achieving up to 5x higher scores than next-token training. It also reduces memorization on discovery tasks but not construction tasks (bottom).
Key observations include:
Multi-token prediction boosts creativity: The Gemma v1 (2B) model shows nearly a 5x increase in algorithmic creativity under multi-token prediction, especially for discovery datasets.
Dramatic reduction in memorization: Next-token prediction tends to memorize training data, while multi-token methods exhibit much stronger resistance to memorization.
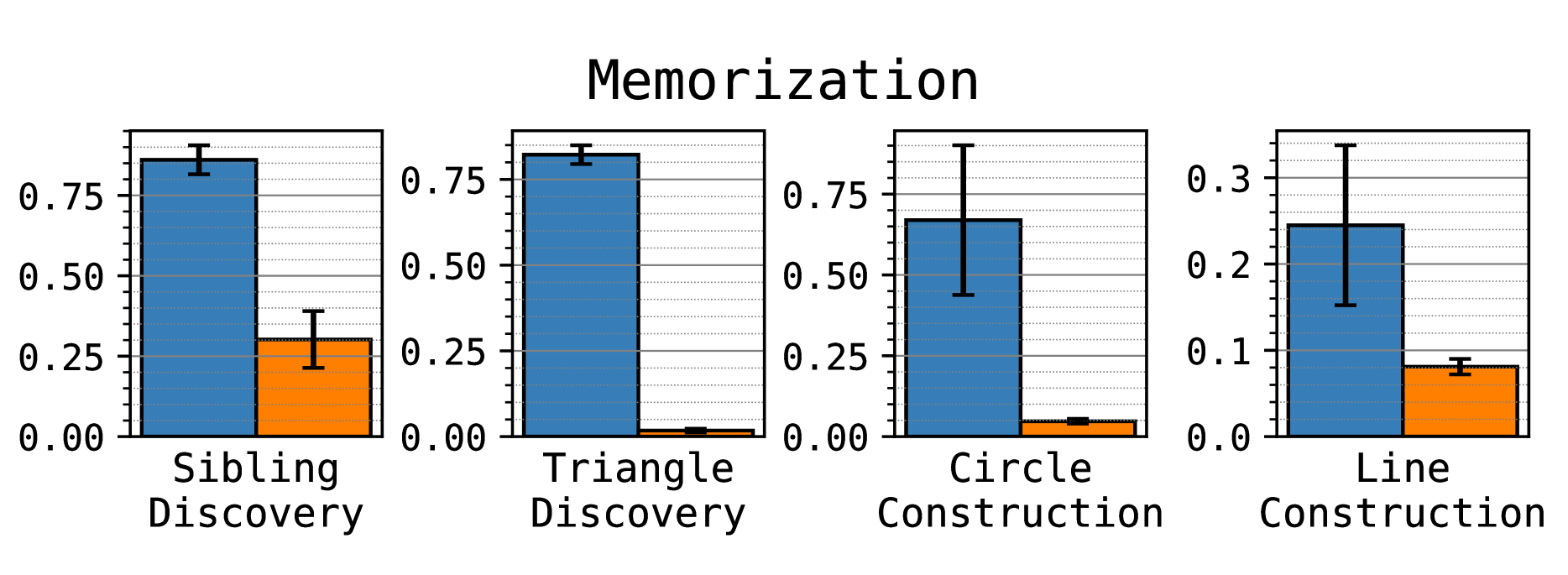
Hash-conditioning improves creativity: This technique significantly enhances creativity for both small and large models.
Hash-conditioning improves algorithmic creativity of the GPT-2 (86M) model (but not the diffusion model). The X-axis labels show the training and decoding procedure, while the legend indicates the prefix type used.
Remarkably, with hash-conditioning:
- Greedy decoding generates diverse outputs as good or better than temperature sampling
- Increasing hash string length consistently boosts creativity
- The benefits apply to both next-token and multi-token approaches
Hash-conditioning essentially provides a distinct knob for diversity with more potency than temperature scaling.

Even as multi-token prediction reduces memorization on unseen hash strings, it can still perfectly reproduce training data on seen hash strings, demonstrating it has enough capacity for memorization when appropriate.
Real-World Applications: Summarization Tasks
The researchers conducted preliminary experiments with GPT models on summarization tasks (XSUM, CNN/DailyMail) to test if their findings extend to more realistic scenarios:
Multi-token training improves diversity scores for XSUM summarization for large GPT-2 models. The plot shows diversity and quality measured over multiple checkpoints during finetuning, revealing differences in diversity for a fixed quality level.
They measured diversity by generating multiple completions for each prompt and computing Self-Bleu metrics. The results show that:
- For a given model quality (Rouge score), larger multi-token models achieve slightly higher diversity
- This improvement doesn't hold for smaller models
- Teacherless training consistently improves summarization quality
Discussion and Implications
The Power of Hash-Conditioning
Why does hash-conditioning work so well? The researchers offer two speculative explanations:
Representational benefits: Fixing a random seed upfront may help the model develop a single coherent thought per sample, rather than maintaining multiple competing thoughts.
Planning benefits: For next-token prediction on open-ended tasks, a fixed seed may help coordinate multiple interlocking random decisions in advance rather than deciding them sequentially.
Hash-conditioning resembles varying prompt wording or using soft prompts, which are known to induce diversity. However, it's unclear whether this approach would be useful beyond these minimal tasks.
Limitations of Current Reasoning Methods
The researchers note that while techniques like reinforcement learning and chain-of-thought prompting enhance the quality of individual examples, they aren't designed to maximize originality or diversity across multiple responses.
A profound question remains: is spelling out a model's thought process in token space an efficient way to search for diverse outputs? This approach might require enumerating all possible candidates, which becomes impossible in large search spaces.
Limitations
Experimental Scope and Applications
The researchers acknowledge several limitations to their experimental approach:
- Success on minimal tasks doesn't guarantee success on more complex ones
- Some tasks may exist where next-token prediction outperforms multi-token approaches
- Teacherless multi-token training is harder to optimize than next-token prediction, especially for smaller models
- Even when multi-token approaches outperform next-token prediction, all algorithms remain far from delivering sufficient diversity in some tasks
- Models struggle with highly complex tasks and are sensitive to how data is formatted
| Hyperparameter | Sibling Discovery |
Triangle Discovery |
Circle Construction |
Line Construction |
|---|---|---|---|---|
| Max. Learning Rate | $5 \times 10^{-4}$ | $5 \times 10^{-4}$ | $5 \times 10^{-4}$ | $5 \times 10^{-5}$ |
| Model Seq. Len. | 32 | 32 | 2048 | 2048 |
| Training steps | 7500 | $10 k$ | $15 k$ | $15 k$ |
| Training size | $50 k$ | $15 k$ | $10 k$ | $10 k$ |
| Weight given to multi-token obj. |
0.5 | 0.5 | 0.75 | 0.75 |
Table 1. Hyperparameter details for Gemma v1 (2B) model.
Broader Limitations on Creativity
The researchers also highlight broader conceptual limitations:
- The skills captured represent only computational skills necessary for creativity, not sufficient ones
- Their algorithmic tasks represent only a subset of creative tasks in Boden's taxonomy
- Real-world creative tasks require much larger context lengths and knowledge bases
- Their approach doesn't capture subjective, social, cultural, and personal values integral to creativity
- Their proxy measure for creativity is computationally efficient but not comprehensive
| Hyperparameter | XSUM | CNN/DailyMail |
|---|---|---|
| Batch Size | 32 | 32 |
| Max. Learning Rate | $5 \times 10^{-5}$ | $3 \times 10^{-6}$ |
| Warmup Steps | 338 | 124 |
| Training Steps | 7778 | 2486 |
| Training Size | 248906 | 79552 |
Table 2. Hyperparameter details for summarization experiments.
Conclusion and Future Directions
This work provides a principled test-bed for analyzing open-ended creative skills in language models. While these tasks are simplified abstractions of real-world creativity, they enable rigorous quantification of originality and diversity.
The research offers compelling evidence that going beyond next-token prediction through multi-token approaches and hash-conditioning can significantly improve creative generation. Multi-token learning helps models capture global dependencies and plan coherent outputs, while hash-conditioning provides a powerful mechanism for inducing diversity without sacrificing coherence.
Several questions remain open for future work:
- Why does hash-conditioning work so well, and would its benefits extend to more complex tasks?
- Can reasoning-enhancement methods like RL and chain-of-thought be adapted to maximize diversity?
- How can we design more efficient ways to search through possible outputs in creative tasks?
This research opens important discussions about the fundamental limitations of next-token prediction and points toward promising alternatives for more creative, diverse language models.
