
บทความนี้เป็นการสร้างแบบจำลองเพื่อตรวจจับหาตุ๊กตาตัวละคร 4 ตัวที่มีลักษณะแตกต่างกัน โดยสร้าง AI ง่ายๆ สำหรับตรวจจับวัตถุด้วย YOLOv5
ผลลัพธ์ที่ได้จะเป็นแบบจำลองที่สามารถ detect หาตุ๊กตาทั้ง 4 แบบ ได้แก่ Chiaki, Shoko, Hwaryun และ Mizuki ตามวิดิโอด้านล่างเลยครับผม🧘

โดยจะมี 4 ขั้นตอนดังนี้
1.สร้างชุดข้อมูลบน Roboflow
นำรูปภาพสำหรับใช้ในการทำ Object Detection ใส่เข้าไปจากนั้นทำการ Annotate เพื่อระบุว่าวัตุแต่ละชิ้นอยู่ในกลุ่มใด
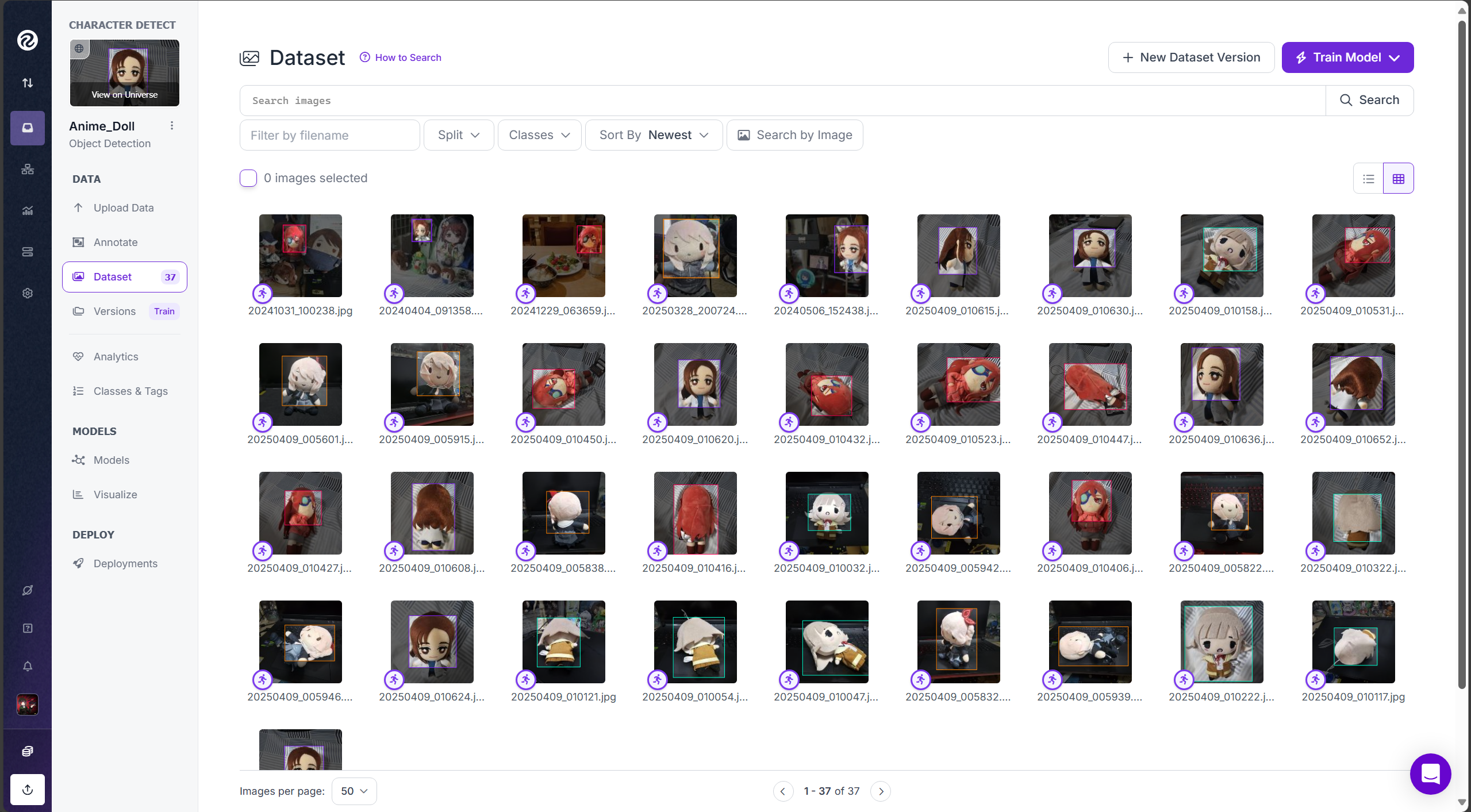
จากนั้นกด New Dataset Version เพื่อสร้างข้อมูล Dataset โดยจะมีการเพิ่มตัว Augmentation เข้าไปเพื่อสร้างภาพที่ถูกปรับแต่งจากตัวข้อมูลที่เรามีให้มีภาพมากขึ้นสำหรับการ Train AI โดยจะทำไว้ทั้งหมด 4 version เพื่อเพิ่มตัวข้อมูลรูปภาพที่เราจะนำมา train ตัว AI ของเรา
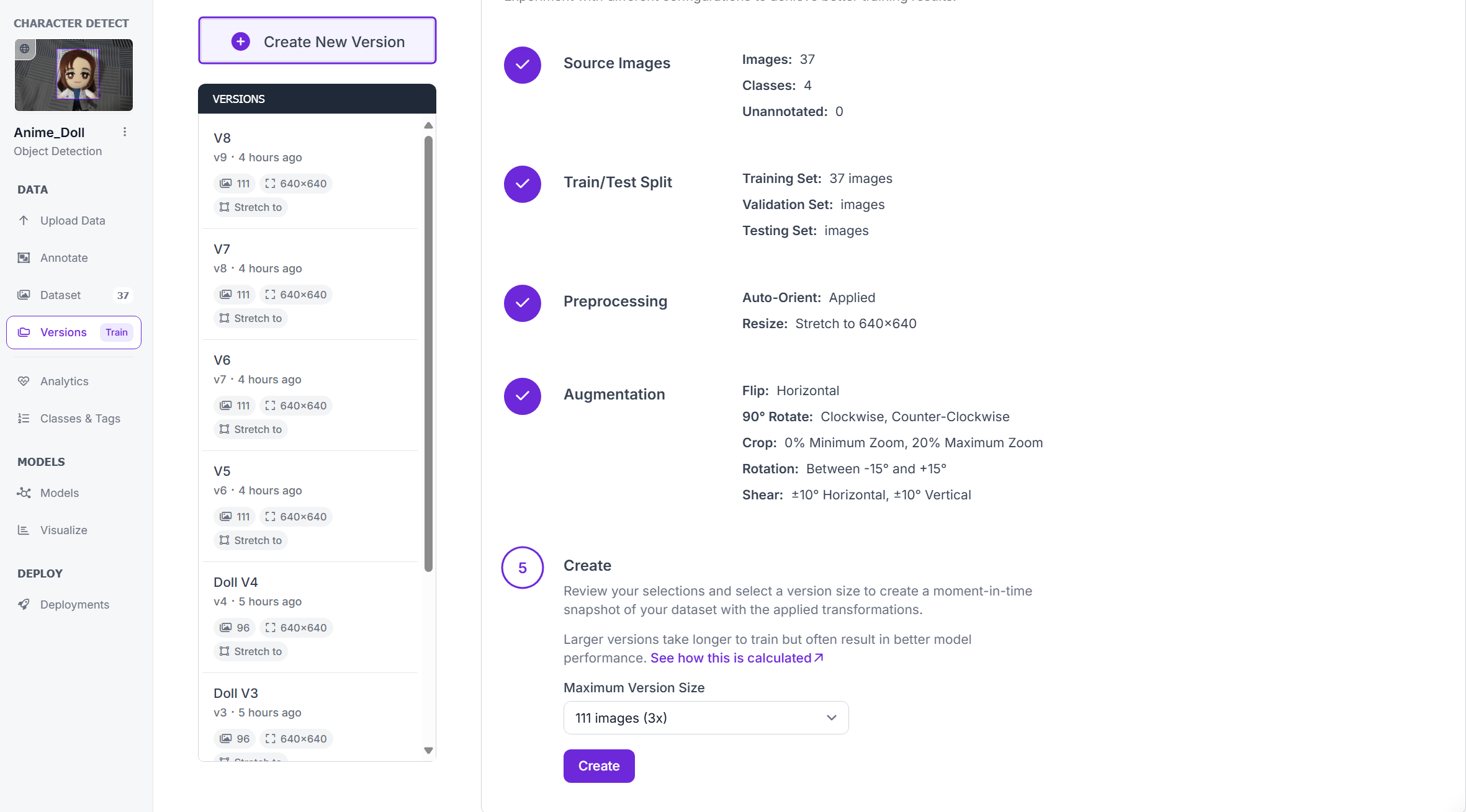
2.นำชุดข้อมูลขึ้น Google Drive
นำชุดข้อมูลที่มีการ label แล้วขึ้น Google Drive ดังภาพ โดยจะมีการ Mount folder ดังกล่าวใน Colab เพื่อดึงชุดข้อมูลไปใช้ในการพัฒนาแบบจำลอง
3.สร้างแบบจำลองบน Colab
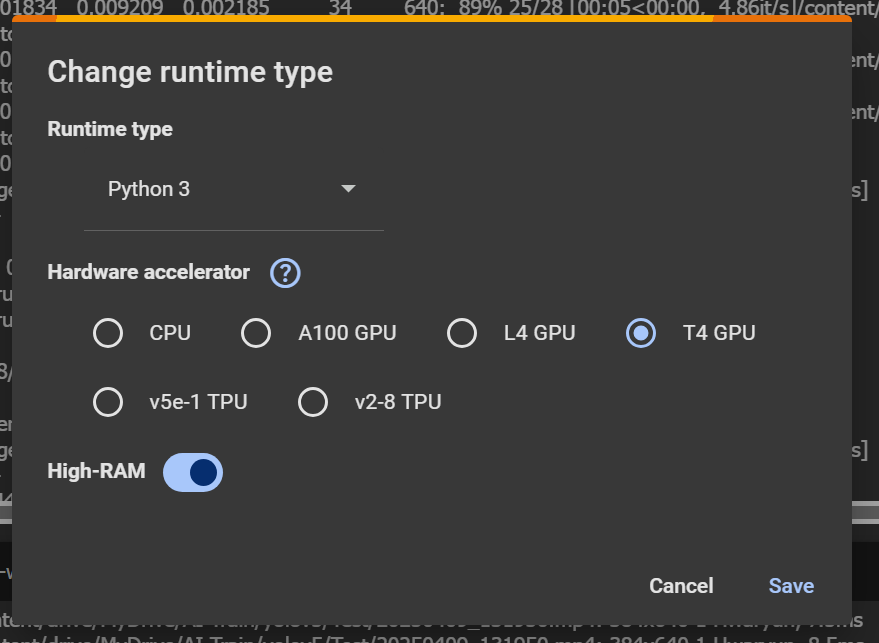
ทำการเลือก Change runtime type เป็น GPU ดังภาพด้านล่างเพื่อให้ สามารถประมวณผลข้อมูลได้เร็วขึ้น
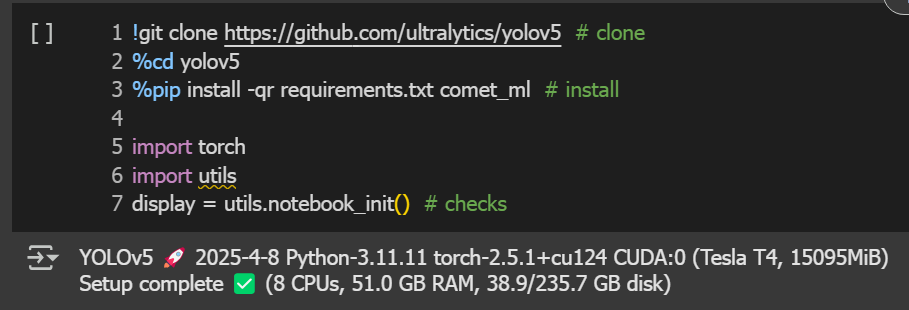
ทำการใส่คำสั่งด้านล่างลงไปใน Cell เพื่อทำการ clone source code yolov5 มาที่ Colab และติดตั้ง dependency ต่างๆ ของ yolov5 ด้วยคำสั่ง pip install จากนั้นกดปุ่ม Run ดังภาพ
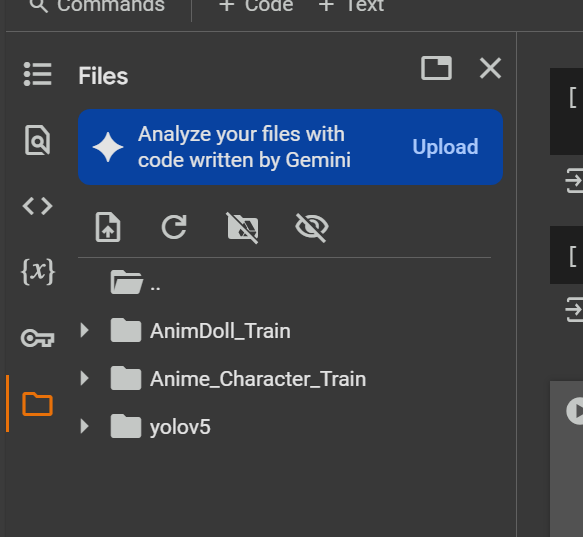
หลังจากนั้นกดไอคอน folder ที่แถบด้านข้าง จะเห็นได้ว่ามี folder yolov5 ขึ้นมาแสดงว่าการ clone source code yolov5 มาที่ Colab สำเร็จ
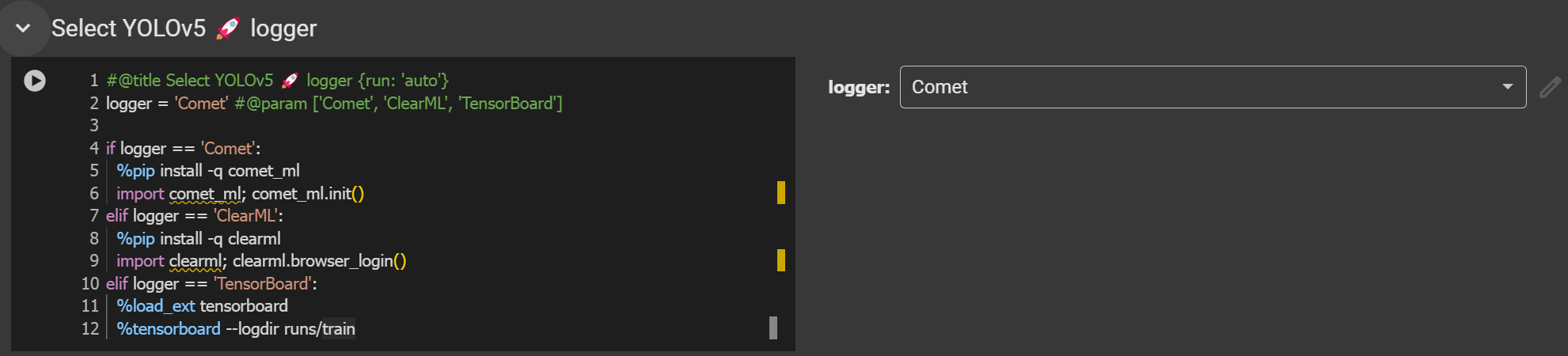
เพื่มฟังก์ชันสำหรับเลือกและตั้งค่า Logger สำหรับ YOLOv5 เพื่อใช้ติดตามและวิเคราะห์การฝึกโมเดล (training) ผ่านระบบล็อกต่าง ๆ ได้แก่
'Comet' – ใช้ Comet.ml สำหรับติดตาม experiment
'ClearML' – ใช้ ClearML เพื่อจัดการและติดตามโมเดล
'TensorBoard' – ใช้ TensorBoard สำหรับ visualization
จากนั้นเราจะสร้างไฟล์ AnimeDoll.yaml ภายใต้ folder yolov5/data
โดยในไฟล์ AnimeDoll.yaml ให้ระบุถึง path ของรูป จำนวน class และชื่อของ class ซึ่งประกอบไปด้วย 4 คลาสดังนี้
train: /content/drive/MyDrive/AI Train/Anime_Character_Train
val: /content/drive/MyDrive/AI Train/Anime_Character_Train
# Classes
names:
0: Chiaki
1: Hwaryun
2: Mizuki
3: Shoko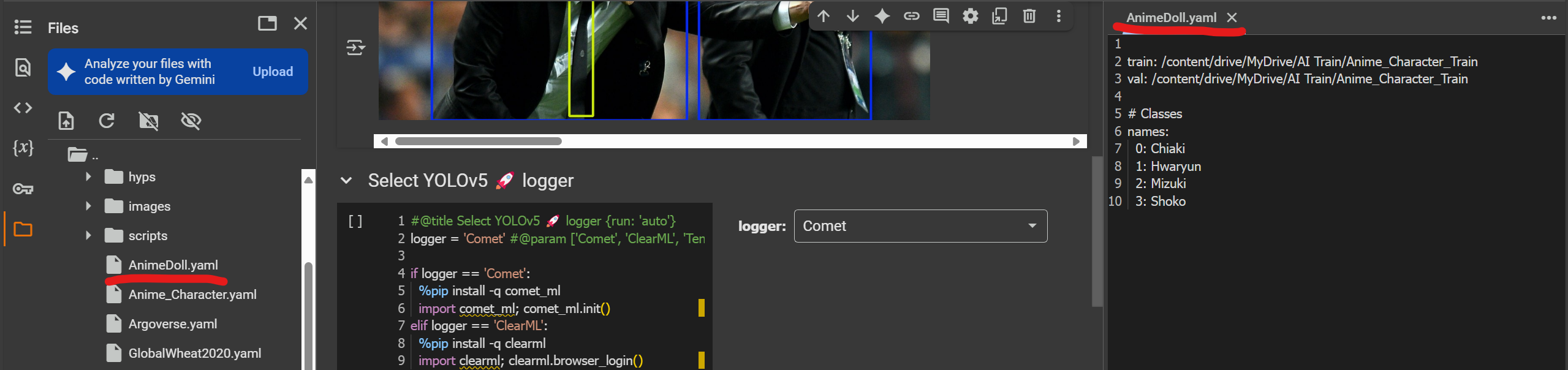
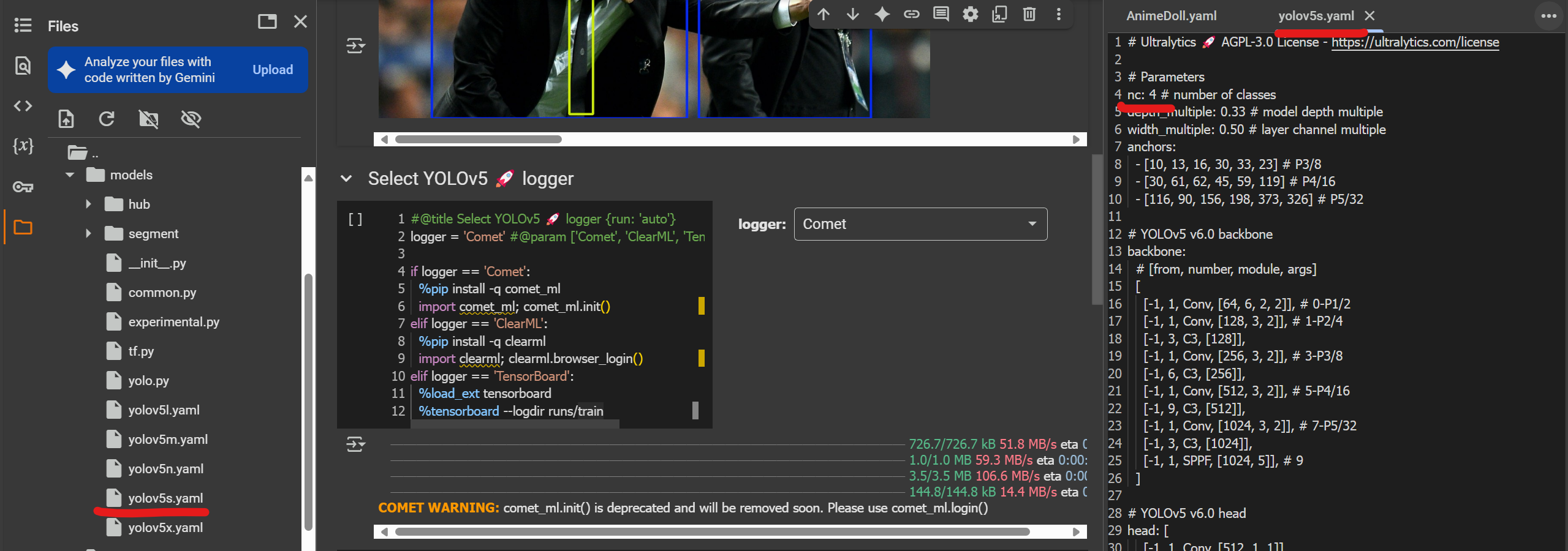
จากนั้นแก้ไขไฟล์ yolov5s.yaml ใน yolov5/models โดยใส่จำนวน class เป็น 4 ที่บรรทัดที่ 2 ตามจำนวน Class ทั้งหมดที่เรามี
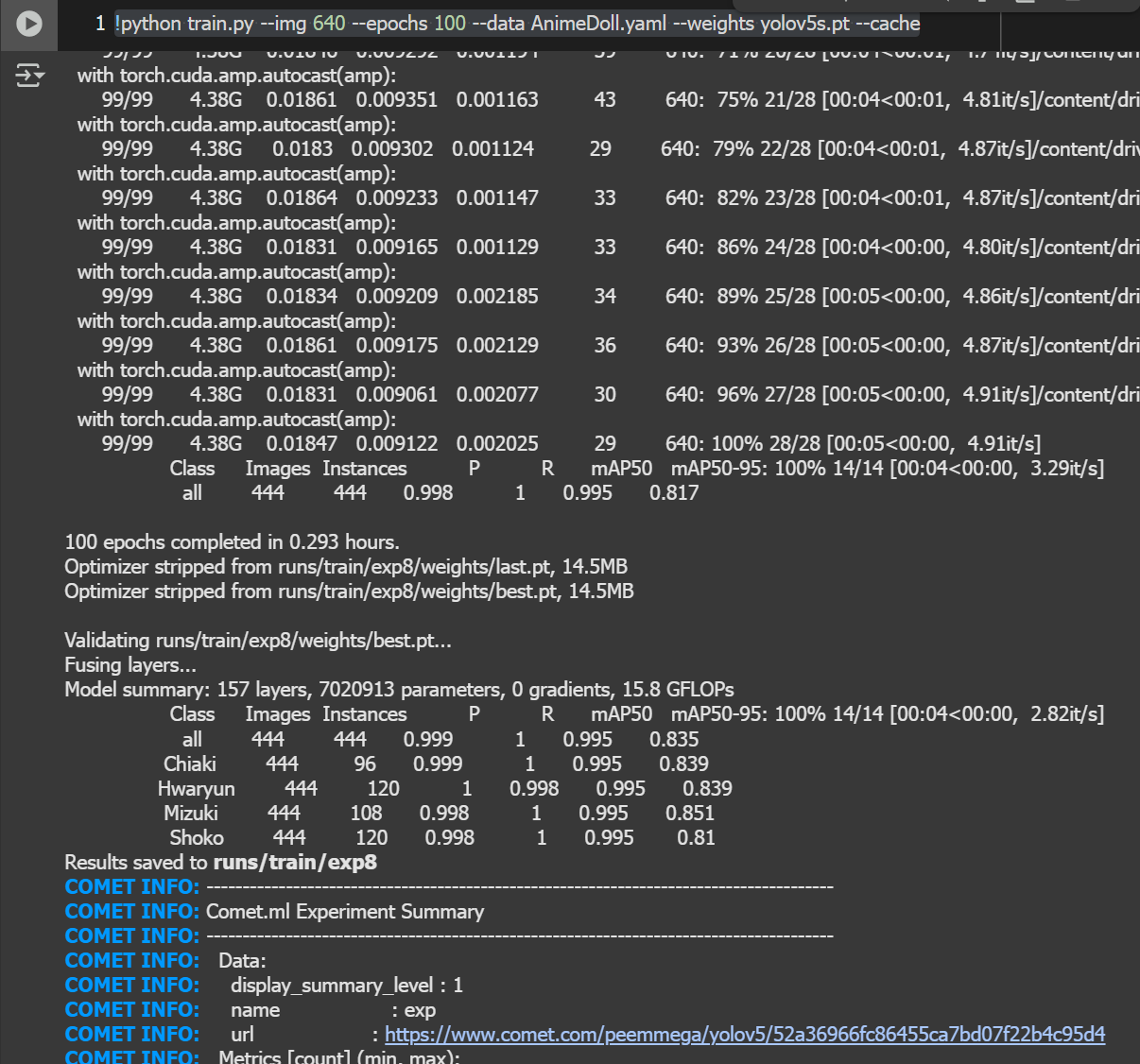
หลังจากนั้นเราจะทำการเรียกคำสั่งเพื่อ train แบบจำลอง โดยระบุขนาดของภาพในการตรวจจับเท่ากับขนาดของภาพที่จะ train คือ 640 และจำนวน Epoch เป็น 100 ครั้ง หรือก็คือเราจะทำการ train ทั้งหมด 100 ครั้งเพื่อให้ข้อมูลมีความแม่นยำมากที่สุด
!python train.py --img 640 --epochs 100 --data AnimeDoll.yaml --weights yolov5s.pt --cacheหลังจากที่เทรนจนครบ 100 Epoch สามารถดูผลลัพธ์สุดท้ายของการเทรนแบบจำลองผ่าน comet ตาม link ที่แสดงด้านล่าง โดยยิ่งค่า precision ข้อมูลก็จะยิ่งแม่นยำมากขึ้น
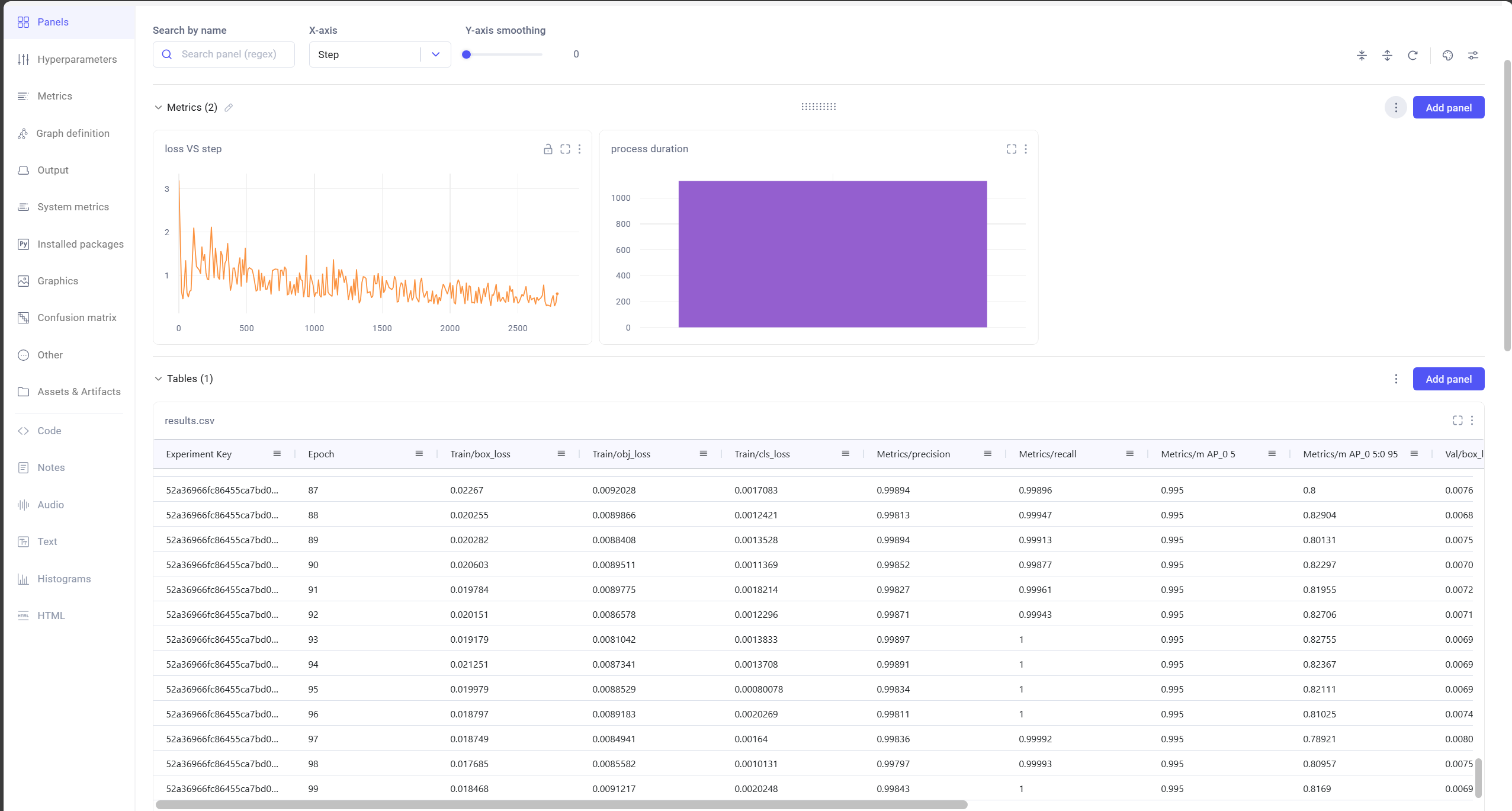
4.ทดลองใช้แบบจำลอง
ไฟล์แบบจำลองที่ดีที่สุดจะสร้างไว้ที่ yolov5/runs/train/exp/weights/best.pt (โดย folder exp จะเปลี่ยนแปลงตามจำนวนครั้งที่ทำการเทรน) โดยสามารถดาวน์โหลดมาใช้นอก Colab ได้ตามต้องการ โดยของผมจะเป็น exp8
จากนั้นเราจะมาลองเรียกคำสั่งด้านล่างเพื่อทดลองใช้แบบจำลองที่สร้างขึ้นเพื่อ detect หาตุ๊กตาในไฟล์ภาพที่เราเตรียมไว้ โดยผมจะใช้เป็น Folder Test สำหรับทดสอบหลาย ๆ ภาพ
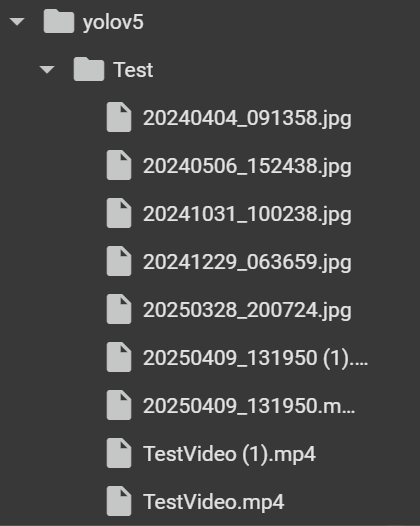
!python detect.py --weights runs/train/exp8/weights/best.pt --img 640 --conf 0.25 --source Test/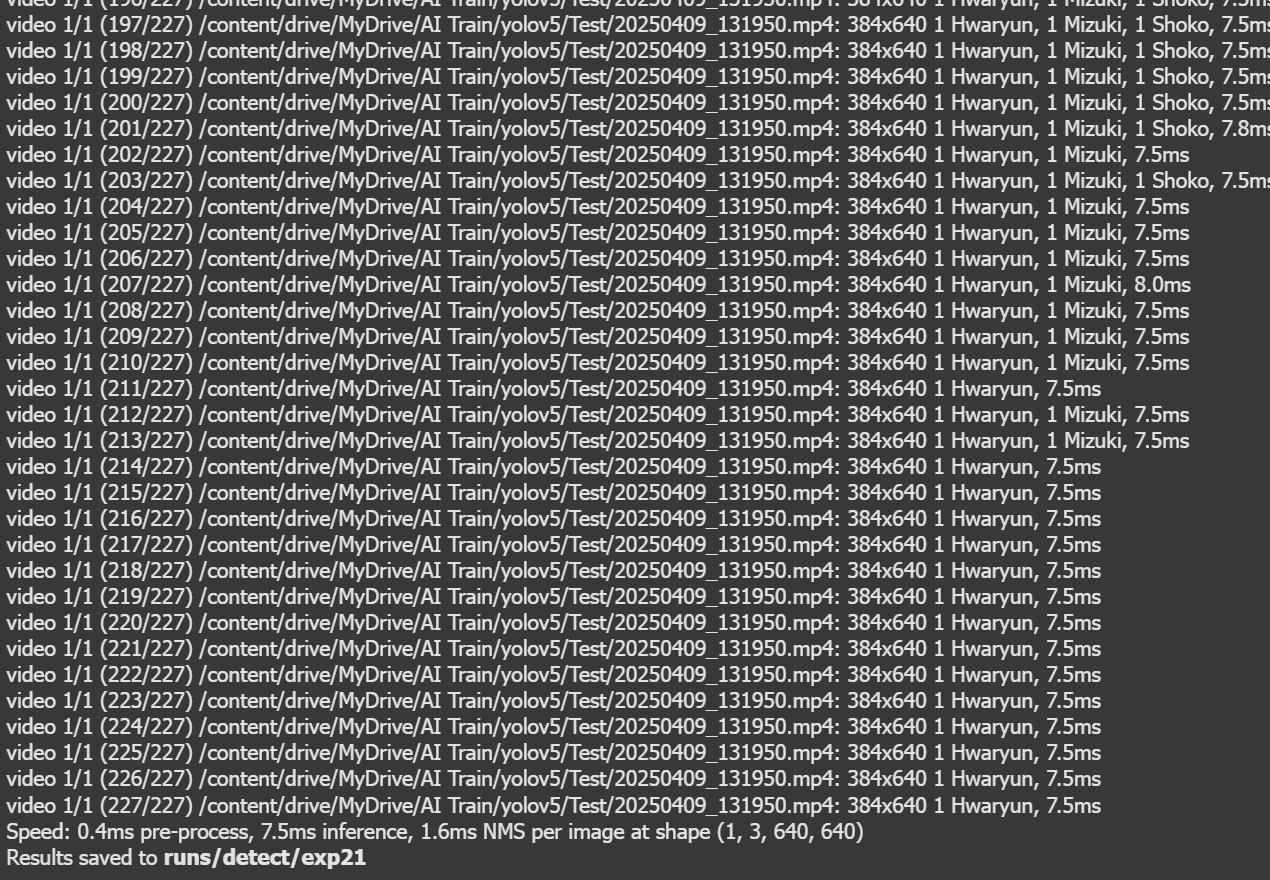
ไฟล์ภาพที่ได้จากการ Detect ด้วย yolov5 จะถูกเก็บไว้ใน yolov5/runs/detect/exp(ครั้งที่ใช้งาน)
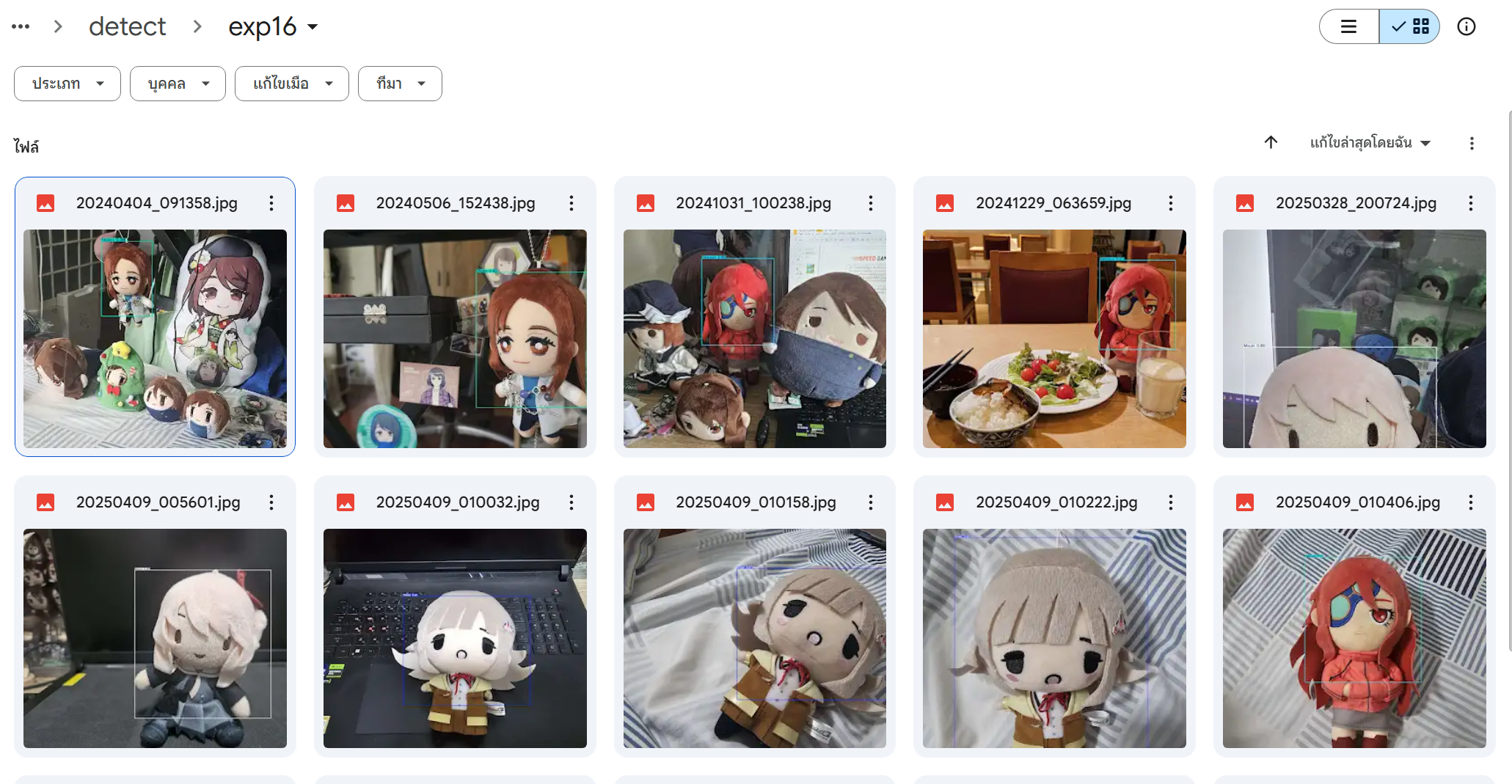





สรุปผล
สำหรับบทความนี้ เราได้แสดงตัวอย่างการทำ Object Detect อย่างง่าย ๆ ด้วย Yolov5 บน Colab ซึ่งเป็นการทำงานง่าย ๆ และสามารถนำไปใช้งานได้หลายรูปแบบโดยใช้ข้อมูลรูปภาพที่เราเตรียมไว้ในการ Train สำหรับใครที่อยากนำไปต่อยอดก็สามารถนำไปทำต่อได้ครับผม เช่น อาจเป็นการ Detech การส่วมแมส หรือ การส่วมหมวกนิรภัยก็ได้ แต่ผมเลือกทำตุ๊กตาเพราะเป็นของที่อยู่ใกล้ตัวและทดสอบได้ง่ายครับ
นายธีริทธิ์ ยอดเครือ รหัส 65120501050
ขอบคุณที่รับชมครับ 🙏
อ้างอิงบทความจาก [2022] สร้าง AI ง่ายๆ สำหรับตรวจจับวัตถุด้วย YOLOv5 (ตอนที่ 2 : สร้างแบบจำลองบน Colab)