In previous posts, I discussed the limitations of MongoDB emulations on databases like Oracle and PostgreSQL. AWS offers Amazon DocumentDB, which provides compatibility with MongoDB 5.0 and may run on top of Aurora PostgreSQL, a guess due to some similarities, never confirmed officially, but the storage capabilities are those of Aurora.
MongoDB's strength is not just in document storage like a key-value store, but also in its efficient indexing for queries with equality, sorting, and range filtering on flexible schemas with embedded arrays and sub-documents.
None of the compatible options I've tested can execute a simple .find().sort().limit() effectively without excessive document scanning, because of the underlying inverted indexes limitations. Is Amazon DocumentDB better?
I create a single-node instance with the highest version available, which compatible with MongoDB 5.0, an old version (I'm testing this in May 2025):
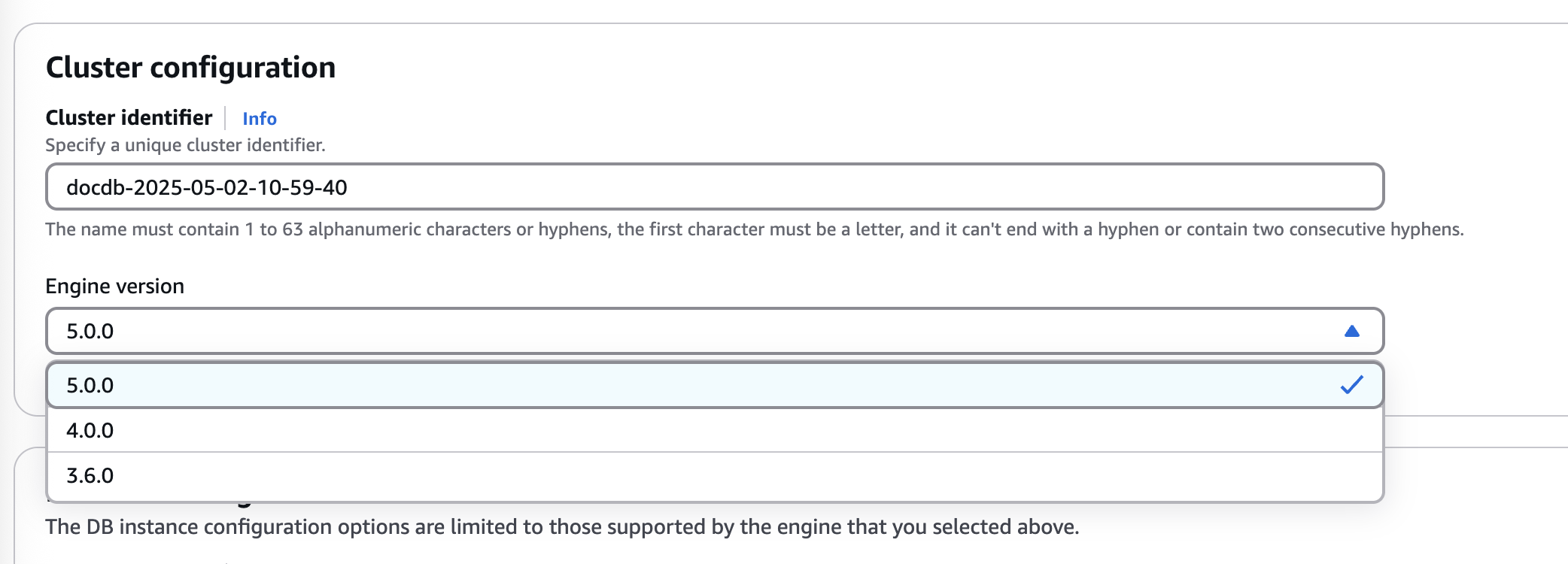
I created the same collection as in the previous post:
for (let i = 0; i < 10000; i++) {
db.demo.insertOne( {
a: 1 ,
b: Math.random(),
ts: new Date()
} )
}
db.demo.createIndex({ "a": 1 , ts: -1 }) ;
db.demo.countDocuments( { a: 1 } );
db.demo.find( { a: 1 } ).explain("executionStats")The index I have created is not used, the whole collection is read (COLLSCAN returning 10000 documents):
rs0 [direct: primary] test> db.demo.countDocuments( { a: 1 } )
10000
rs0 [direct: primary] test> db.demo.find( { a: 1 }
).explain("executionStats")
{
queryPlanner: {
plannerVersion: 1,
namespace: 'test.demo',
winningPlan: { stage: 'COLLSCAN' }
},
executionStats: {
executionSuccess: true,
executionTimeMillis: '10.268',
planningTimeMillis: '0.124',
executionStages: {
stage: 'COLLSCAN',
nReturned: '10000',
executionTimeMillisEstimate: '9.803'
}
},
serverInfo: { host: 'docdb-2025-05-02-12-45-45', port: 27017, version: '5.0.0' },
ok: 1,
operationTime: Timestamp({ t: 1746190938, i: 1 })
}All rows match my filter so maybe Amazon DocumentDB has a different query planner and a full scan is valid here.
To validate that the index can be used, I can add a hint:
rs0 [direct: primary] test> db.demo.find( { a: 1 }
).hint({a:1,ts:-1}).explain("executionStats")
{
queryPlanner: {
plannerVersion: 1,
namespace: 'test.demo',
winningPlan: {
stage: 'SUBSCAN',
inputStage: { stage: 'IXSCAN', indexName: 'a_1_ts_-1', direction: 'forward' }
}
},
executionStats: {
executionSuccess: true,
executionTimeMillis: '73.495',
planningTimeMillis: '16.987',
executionStages: {
stage: 'SUBSCAN',
nReturned: '10000',
executionTimeMillisEstimate: '55.689',
inputStage: {
stage: 'IXSCAN',
nReturned: '10000',
executionTimeMillisEstimate: '42.151',
indexName: 'a_1_ts_-1',
direction: 'forward'
}
}
},
serverInfo: { host: 'docdb-2025-05-02-12-45-45', port: 27017, version: '5.0.0' },
ok: 1,
operationTime: Timestamp({ t: 1746190980, i: 1 })
}The execution plan is not as verbose as MongoDB, so this doesn't give lots of information about the seek and index keys, but at least I know that my index can be used. Note that SUBSCAN is not a MongoDB execution plan stage, and there's no information telling me if { a: 1 } was filtered efficiently by the index. The next test will tell more.
Time to test what failed on CosmosDB - a simple compound index used for equality and sort:
rs0 [direct: primary] test> db.demo.find( { a: 1 }
).sort({ts:-1}).limit(10).explain("executionStats")
{
queryPlanner: {
plannerVersion: 1,
namespace: 'test.demo',
winningPlan: {
stage: 'SUBSCAN',
inputStage: {
stage: 'LIMIT_SKIP',
inputStage: {
stage: 'IXSCAN',
indexName: 'a_1_ts_-1',
direction: 'forward'
}
}
}
},
executionStats: {
executionSuccess: true,
executionTimeMillis: '0.398',
planningTimeMillis: '0.161',
executionStages: {
stage: 'SUBSCAN',
nReturned: '10',
executionTimeMillisEstimate: '0.200',
inputStage: {
stage: 'LIMIT_SKIP',
nReturned: '10',
executionTimeMillisEstimate: '0.195',
inputStage: {
stage: 'IXSCAN',
nReturned: '10',
executionTimeMillisEstimate: '0.193',
indexName: 'a_1_ts_-1',
direction: 'forward'
}
}
}
},
serverInfo: { host: 'docdb-2025-05-02-12-45-45', port: 27017, version: '5.0.0' },
ok: 1,
operationTime: Timestamp({ t: 1746191080, i: 1 })
}
rs0 [direct: primary] test> ;This looks good. Finally, is there a MongoDB-compatible API that can use an index to optimize pagination queries?
This was simple, as the index values are all scalar. However, the flexible schema of MongoDB allows arrays when one document has a One to Many relationship instead of a One to One.
In my opinion, this is the main advantage of a document database: not having to change the complete data model, which carries risks to the existing data not concerned by the change, when a business rule evolves. I explained an example of this, a multi-city airport, in a previous article.
I added similar documents but with an array of values in "a":
for (let i = 0; i < 10000; i++) {
db.demo.insertOne( {
a: [0,1,2] ,
b: Math.random(),
ts: new Date()
} )
}In parallel, I did the same on a MongoDB Atlas database, running the genuine document database, version 8.0, to illustrate the expected outcomes. The index is utilized efficiently, reading just 10 index keys and fetching 10 documents without subsequent filtering or sorting:
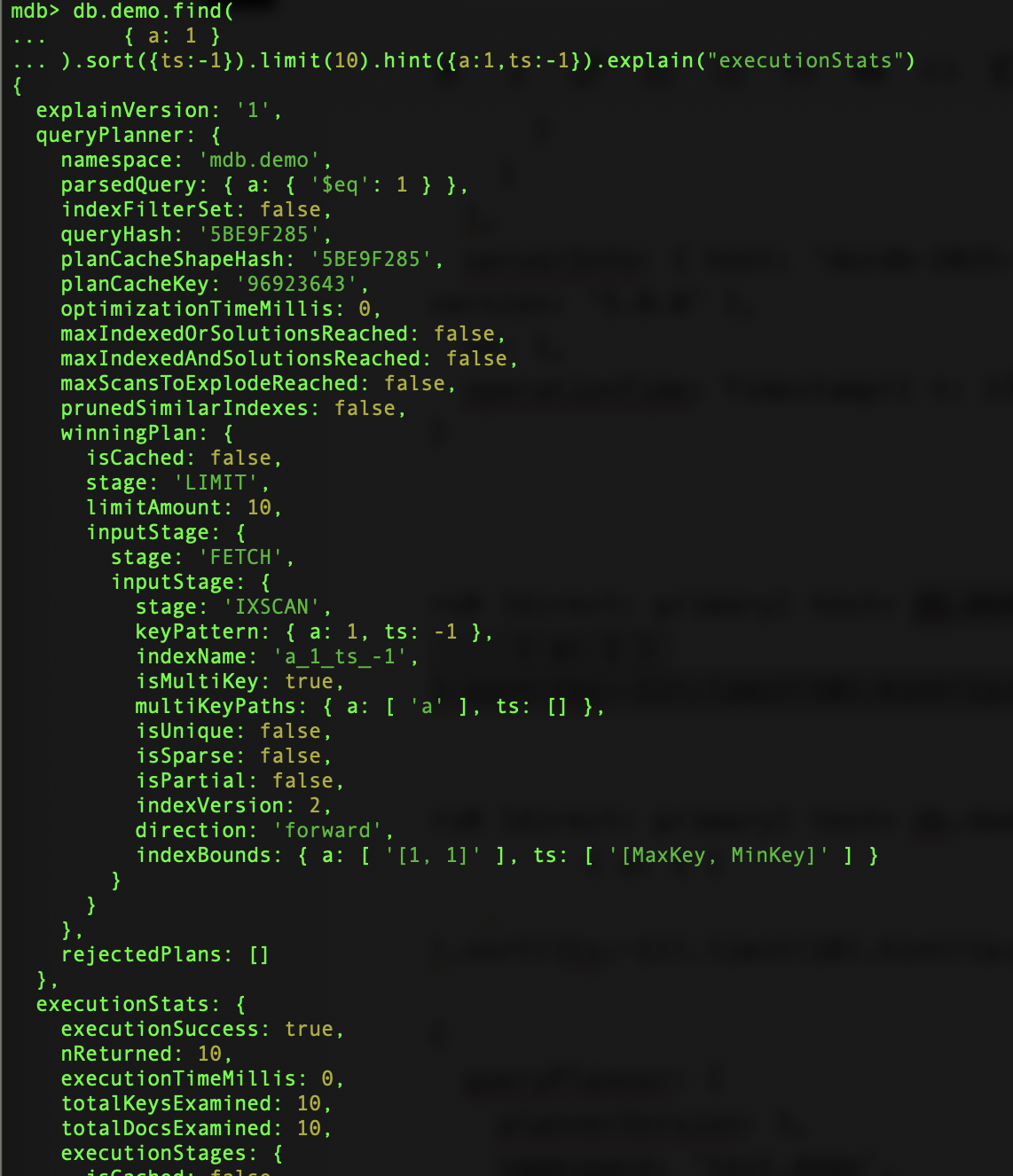
But it is not the same on Amazon DocumentDB where the full collection is scanned, and sorted, before picking the 10 documents of the result:
rs0 [direct: primary] test> db.demo.find( { a: 1 }
).sort({ts:-1}).limit(10).explain("executionStats")
{
queryPlanner: {
plannerVersion: 1,
namespace: 'test.demo',
winningPlan: {
stage: 'SUBSCAN',
inputStage: {
stage: 'LIMIT_SKIP',
inputStage: {
stage: 'SORT',
sortPattern: { ts: -1 },
inputStage: { stage: 'COLLSCAN' }
}
}
}
},
executionStats: {
executionSuccess: true,
executionTimeMillis: '53.092',
planningTimeMillis: '0.479',
executionStages: {
stage: 'SUBSCAN',
nReturned: '10',
executionTimeMillisEstimate: '52.572',
inputStage: {
stage: 'LIMIT_SKIP',
nReturned: '10',
executionTimeMillisEstimate: '52.564',
inputStage: {
stage: 'SORT',
nReturned: '10',
executionTimeMillisEstimate: '52.561',
sortPattern: { ts: -1 },
inputStage: {
stage: 'COLLSCAN',
nReturned: '20000',
executionTimeMillisEstimate: '37.111'
}
}
}
}
},
serverInfo: { host: 'docdb-2025-05-02-12-45-45', port: 27017, version: '5.0.0' },
ok: 1,
operationTime: Timestamp({ t: 1746193272, i: 1 })
}Although I can force the index with a hint, the process results in a full scan of all index entries. This method fails to apply the equality filter on the key and does not utilize the ordering of entries effectively:
rs0 [direct: primary] test> db.demo.find( { a: 1 }
).sort({ts:-1}).limit(10).hint({a:1,ts:-1}).explain("executionStats")
{
queryPlanner: {
plannerVersion: 1,
namespace: 'test.demo',
winningPlan: {
stage: 'SUBSCAN',
inputStage: {
stage: 'LIMIT_SKIP',
inputStage: {
stage: 'SORT',
sortPattern: { ts: -1 },
inputStage: {
stage: 'FETCH',
inputStage: { stage: 'IXSCAN', indexName: 'a_1_ts_-1' }
}
}
}
}
},
executionStats: {
executionSuccess: true,
executionTimeMillis: '27.382',
planningTimeMillis: '0.241',
executionStages: {
stage: 'SUBSCAN',
nReturned: '10',
executionTimeMillisEstimate: '27.102',
inputStage: {
stage: 'LIMIT_SKIP',
nReturned: '10',
executionTimeMillisEstimate: '27.094',
inputStage: {
stage: 'SORT',
nReturned: '10',
executionTimeMillisEstimate: '27.091',
sortPattern: { ts: -1 },
inputStage: {
stage: 'FETCH',
nReturned: '20000',
executionTimeMillisEstimate: '15.592',
inputStage: {
stage: 'IXSCAN',
nReturned: '20000',
executionTimeMillisEstimate: '4.338',
indexName: 'a_1_ts_-1'
}
}
}
}
}
},
serverInfo: { host: 'docdb-2025-05-02-12-45-45', port: 27017, version: '5.0.0' },
ok: 1,
operationTime: Timestamp({ t: 1746193437, i: 1 })
}Surprisingly, the result appears to be ordered when I use an index hint. I verified this on my result, although it may be a side effect of the implementation:
db.demo.find({ a: 1 }).hint({ a: 1, ts: -1 }).toArray().forEach((doc, index, docsArray) => {
if (index > 0) {
const previousDoc = docsArray[index - 1];
if (doc.ts > previousDoc.ts) {
console.log("The results are not ordered by 'ts' in descending order.");
}
}
});But wait, I inserted a batch of scalars and then a batch of arrays. It is possible that each has a different partial index in the underlying PostgreSQL. I started with only scalar values, so one index, and was able to use its full filtering and ordering capabilities. In a second batch, with all arrays, a second index may have been created for them. It can use both indexes, as I've seen when forcing it with a hint, but with two branches in the execution plan, one for each index. With a concatenation, similar to a UNION ALL, PostgreSQL can preserve the order with a merge sort. However, if a bitmap scan is used, the ordering is lost. As my sort() in on the insertion timestamp, it is possible that, by chance, the indexes were scanned in the right order even of the ordering is not guaranteed.
To validate the ordering can be lost, reason why the query planner adds a sort stage, I inserted one more document with a scalar and ran my ordering test again:
rs0 [direct: primary] test> db.demo.insertOne( { a: 1 , b: Math.random(), ts: new Date() } )
{
acknowledged: true,
insertedId: ObjectId('68151d8420044b5ec3d9aea2')
}
rs0 [direct: primary] test> db.demo.find({ a: 1 }).hint({ a: 1, ts: -1 }).toArray().forEach((doc, index, docsArray) => {
... if (index > 0) {
... const previousDoc = docsArray[index - 1];
... if (doc.ts > previousDoc.ts) {
... console.log("The results are not ordered by 'ts' in descending order.");
... }
... }
... });
The results are not ordered by 'ts' in descending order.Now that scalar values and arrays are interleaved, reading from two distinct indexes does not preserve the order. That would explain why the query planner cannot optimize the query.
The document model's primary advantage lies in having a single index over a flexible schema, as opposed to two indexes on separate tables in a normalized relational database. If my hypothesis holds true, the existence of multiple indexes due to the flexible schema negates this key benefit of a document database.
I tried multiple combinations of index creation and insertions. If I delete all rows (db.demo.deleteMany({})) it still behaves like a multi-key where the index cannot be used for equality and sort.
Dropping and re-creating the index resets this state. However, if I insert rows with scalar and arrays before creating the index, I got a case where I cannot force the index with a hint:
rs0 [direct: primary] test> db.demo.dropIndex({ "a": 1 , ts: -1 }) ;
{
nIndexesWas: 2,
ok: 1,
operationTime: Timestamp({ t: 1746215608, i: 1 })
}
rs0 [direct: primary] test> db.demo.insertOne( { a: 1 , b: Math.random(), ts: new Date() } )
{
acknowledged: true,
insertedId: ObjectId('681522ba20044b5ec3d9fcc8')
}
rs0 [direct: primary] test> db.demo.insertOne( { a: [ 1,2,3 ] , b: Math.random(), ts: new Date() } )
{
acknowledged: true,
insertedId: ObjectId('681522bb20044b5ec3d9fcc9')
}
rs0 [direct: primary] test> db.demo.createIndex({ "a": 1 , ts: -1 }) ;
a_1_ts_-1
rs0 [direct: primary] test> db.demo.find( { a: 1 }
).hint({a:1,ts:-1}).explain("executionStats")
MongoServerError: Cannot use Hint for this Query.
Index is multi key index , partial index or sparse index and query is not optimized to use this index.The available statistics and logs are insufficient to identify the type of index in use. It is neither a MongoDB index, as it doesn't have the same capabilities, nor does it behave like one single PostgreSQL index.
In PostgreSQL, an inverted index, such as GIN, utilizes bitmaps for scanning and does not maintain order, even with scalar values. While an expression index can facilitate equality, sorting, and range queries, it cannot be established on a flexible schema with arrays in the key.
I suspect that multiple partial expression indexes are created, and full features can only be utilized before a multi-key is detected. Maybe the SUBSCAN is the operation that combines results from multiple partial indexes, to emulate MongoDB flexible schema, but loosing the optimization of pagination queries.
To effectively compare databases with a compatible API, focus on indexing options and execution plans for OLTP query patterns. Benchmarks must run over extended periods with increasing data, testing critical query patterns like find().sort().limit(). Always examine execution plans first to avoid wasting cloud resources in long tests. You can compare plans scanning MongoDB compound indexes.
Note that Amazon DocumentDB may have other advantages, like the integration with some Amazon services, and Aurora-like separation of compute and storage, but when it comes to take the full advantages of a document database, MongoDB is more advanced, and is available on AWS, like other clouds, with Atlas.