Introduction
If you're looking to experiment with Amazon Bedrock or want a simple hands-on project to get started, this toy use case is a great way to explore how large language models can be integrated into real-world workflows.
Traditionally, when you submit an insurance claim—whether it’s for an auto accident or a medical procedure—it’s first reviewed by a human adjuster. The adjuster evaluates the details, validates supporting documents, and then determines whether the claim is genuine before approving or rejecting it.
In this blog post, we explore how Amazon Bedrock, specifically the Amazon Nova model, can be used to play the role of an adjuster. By leveraging Bedrock through a simple AWS Lambda function, we demonstrate how AI can assist in summarizing claims and assessing potential fraud risks.
For this initial prototype, we’re using AWS Lambda and Amazon Bedrock, but in the future, this project could be extended to include services like API Gateway, Step Functions, S3, and more.
Step 1: Get Model Access from Amazon Bedrock
Before you begin, make sure you have access to the Amazon Titan Nova Lite and Nova Pro models:
Go to Amazon Bedrock in the AWS Console.
Under Model Access, request access to the Nova models if not already enabled.

Step 2: Create the Lambda Function
In VS Code, create a new folder for your Lambda project.

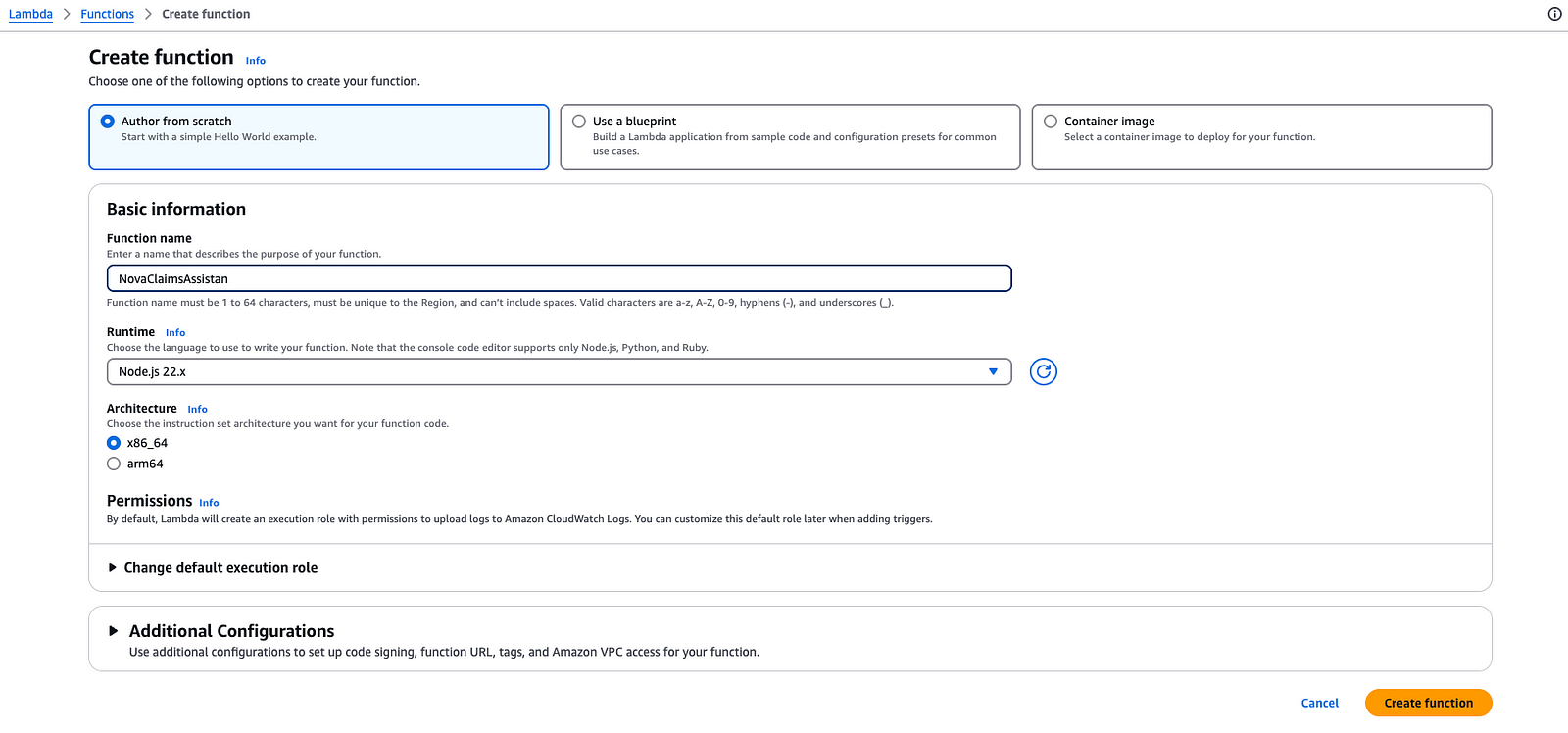
Write your Lambda function code (shared below).
In the AWS Console, create a new Lambda function.
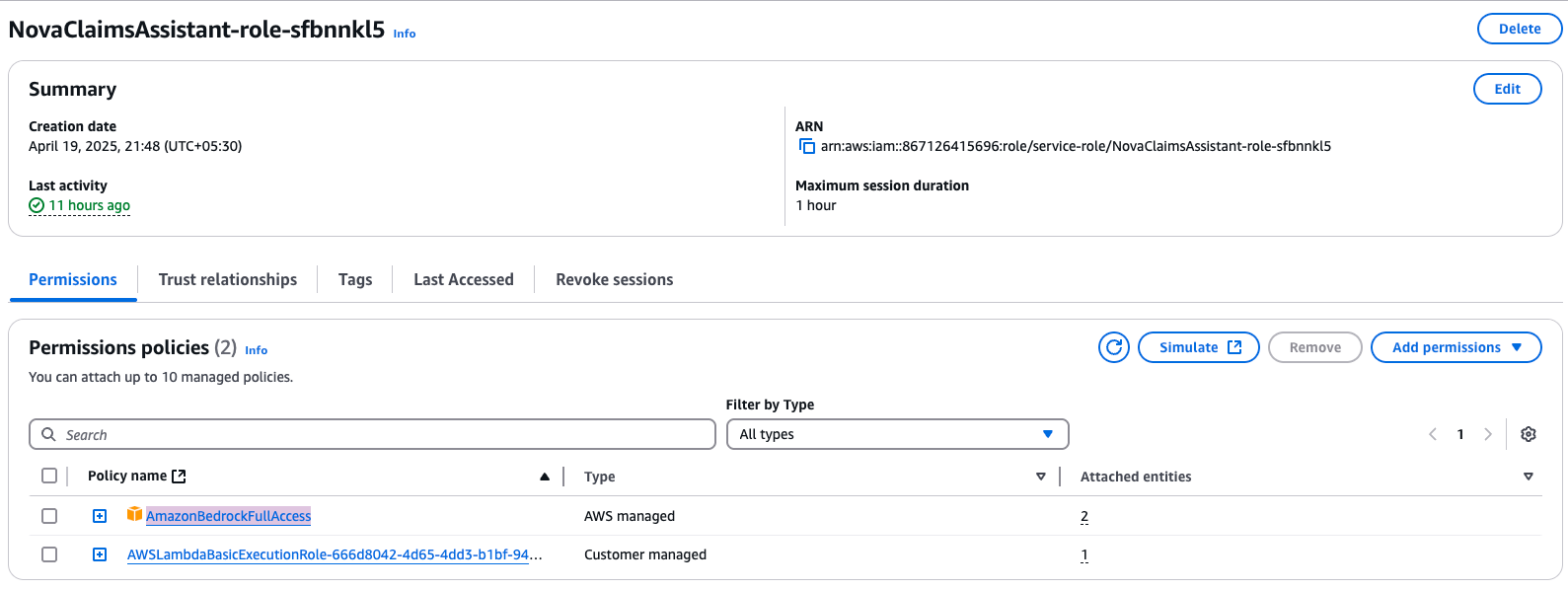
After creation, a default IAM role will be associated with the Lambda. Add a policy to this role to give it Amazon Bedrock full access.
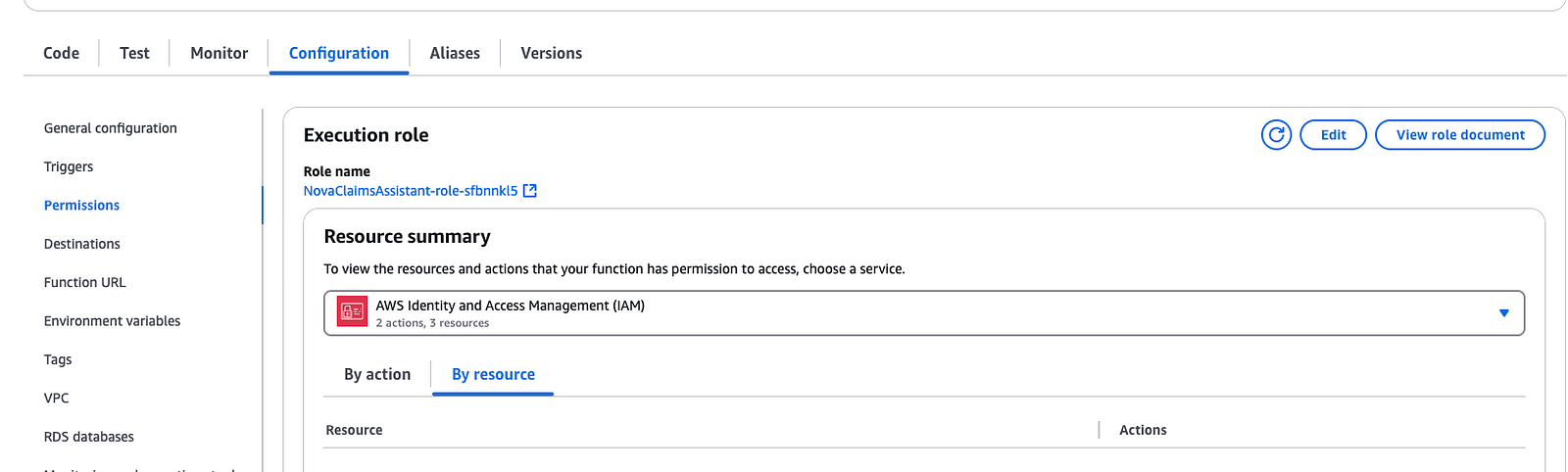
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": "*"
}Step 3: Lambda Function Code (lambda_function.py)
import boto3
import json
import os
bedrock = boto3.client("bedrock-runtime")
MODEL_ID = os.getenv("MODEL_ID", "amazon.nova-pro-v1:0")
def lambda_handler(event, context):
body = json.loads(event['body'])
note = body.get('note', '')
prompt = build_prompt(note)
response = bedrock.invoke_model(
modelId=MODEL_ID,
contentType="application/json",
accept="application/json",
body=json.dumps({
"messages": [
{
"role": "user",
"content": [
{"text": prompt}
]
}
]
})
)
model_output = json.loads(response['body'].read())
ai_reply = model_output.get('output', {}).get('message', {}).get('content', [{}])[0].get('text', '')
return {
"statusCode": 200,
"body": json.dumps({
"summary_and_score": ai_reply
})
}
def build_prompt(note):
return f"""
You are an AI assistant for insurance claims adjusters. Read the adjuster's note and:
1. Summarize the claim in 3–5 bullet points.
2. Highlight any fraud risk indicators (if any).
3. Provide a fraud risk score between 0 and 10.
Adjuster's Note:
\"\"\"{note}\"\"\"
Output Format:
Summary:
- ...
Fraud Risk:
- ...
Score: ...
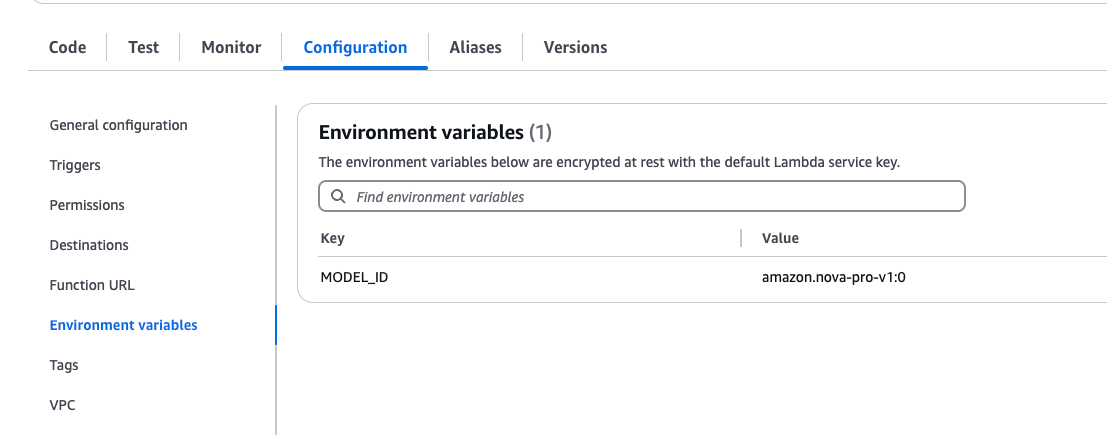
"""Don’t forget to add an environment variable in the Lambda settings:
MODEL_ID = amazon.nova-pro-v1:0
Step 4: Testing the Lambda
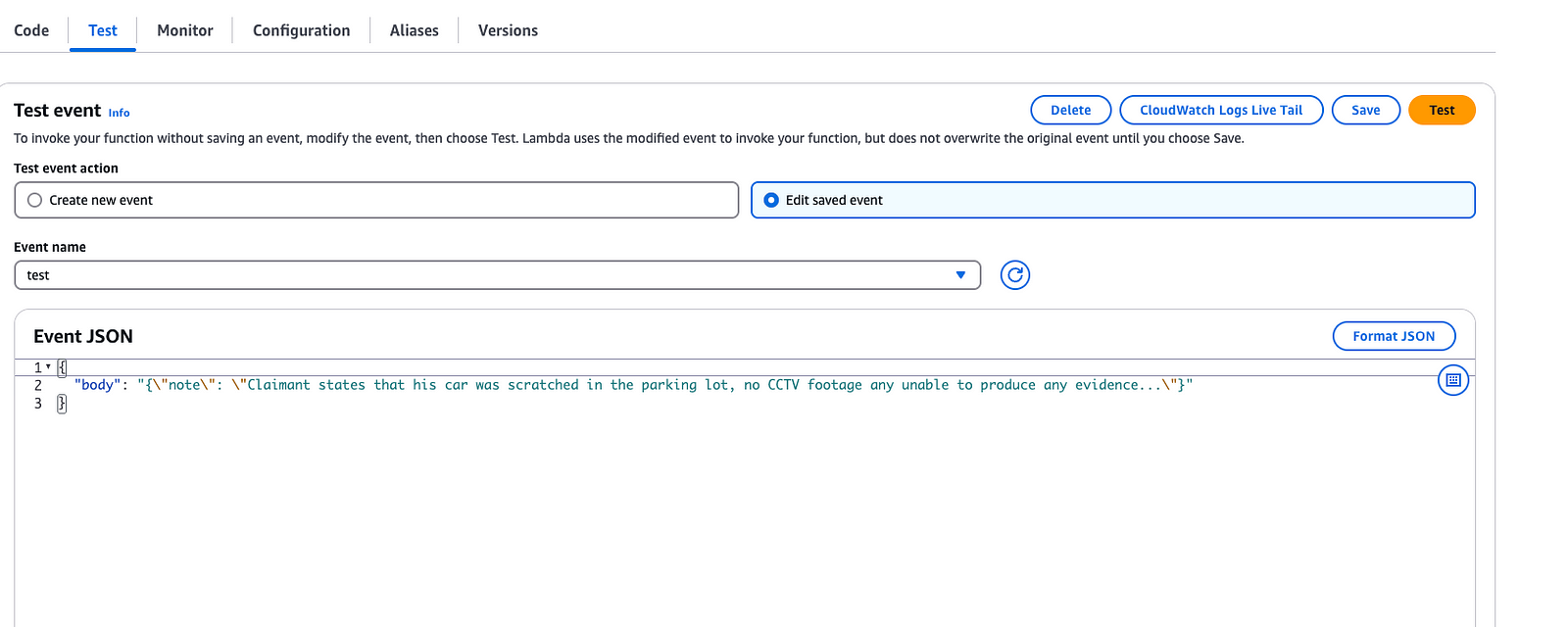
Use the Lambda test feature in the console to simulate a request. Here's a sample payload you can use:
{
"body": "{\"note\": \"Claimant reports a scratch on their car in a parking lot. No CCTV footage is available. No other witnesses. Wants to proceed with the claim.\"}"
}
Sample Output
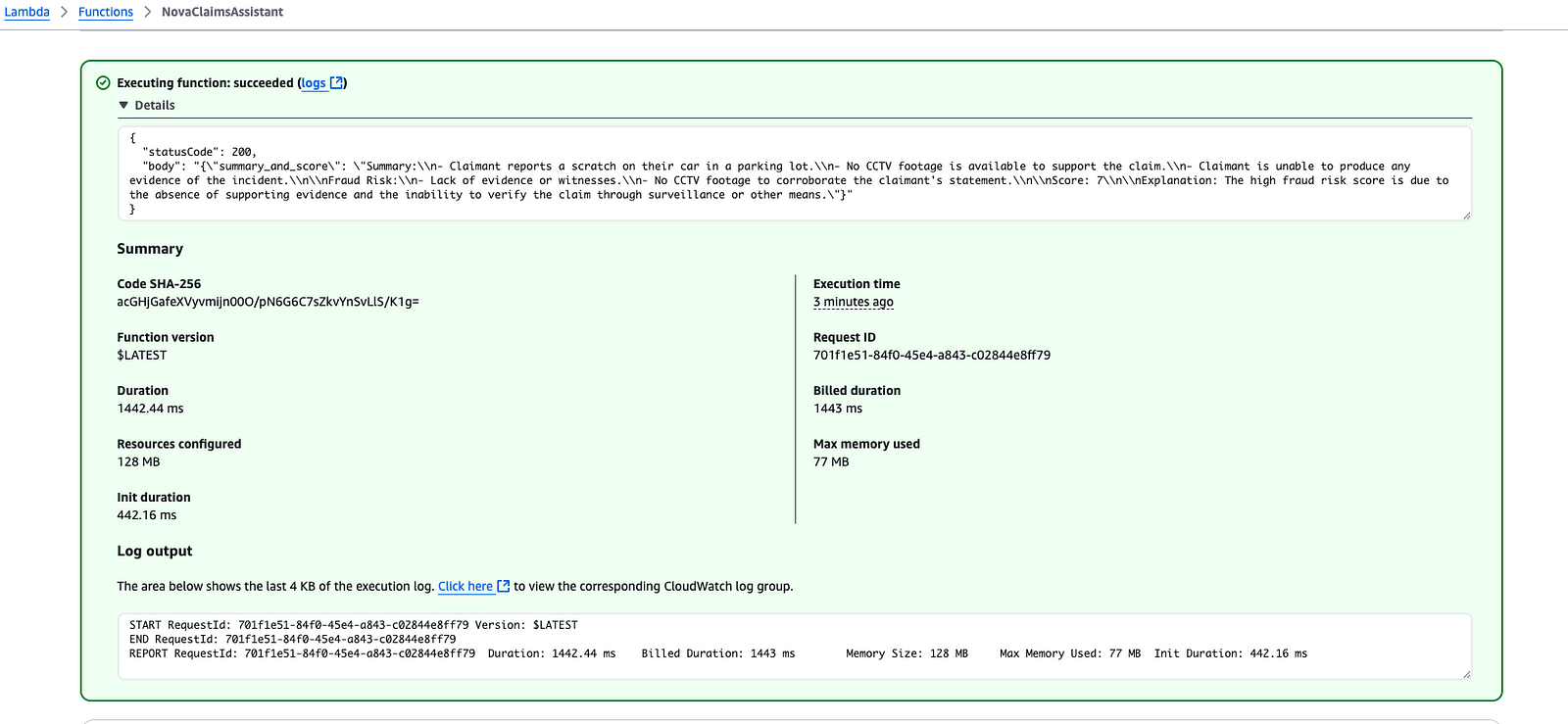
{
"statusCode": 200,
"body": "{\"summary_and_score\": \"Summary:\\n- Claimant reports a scratch on their car in a parking lot.\\n- No CCTV footage is available to support the claim.\\n- Claimant is unable to produce any evidence of the incident.\\n\\nFraud Risk:\\n- Lack of evidence or witnesses.\\n- No CCTV footage to corroborate the claimant's statement.\\n\\nScore: 7\\n\\nExplanation: The high fraud risk score is due to the absence of supporting evidence and the inability to verify the claim through surveillance or other means.\"}"
}How is the Fraud Risk Score Interpreted?
The fraud risk score is a value from 0 to 10, where:
Score Range Interpretation
0–3 Low fraud risk — the claim appears legitimate
4–6 Moderate risk — the claim may need further review
7–10 High fraud risk — the claim has red flags or lacks supporting evidence
As shown above, the Nova model provides:
- A clear summary of the claim
- Detected fraud indicators
- A risk score with reasoning
Conclusion
This toy project demonstrates how Amazon Bedrock and the Nova model can act as an intelligent assistant for insurance claims adjusters. By summarizing claim notes and providing fraud risk analysis, it can help organizations quickly triage and prioritize claims.
This is just a starting point. Future enhancements may include:
- Real-time REST APIs via API Gateway
- Workflow orchestration using Step Functions
- Secure data storage on S3
- Automated claim status notifications
By leveraging the Amazon Nova model through Amazon Bedrock, we're able to mimic the judgment of a seasoned claims adjuster—automating the summarization of adjuster notes, detecting possible red flags, and assigning a fraud risk score based on context.
This AI-powered workflow brings multiple benefits:
🧠 Smarter decisions: Nova evaluates claims contextually, helping to reduce oversight and human error.
⚖️ Consistent outcomes: The model applies the same logic across all claims, ensuring fairness and reducing bias.
🕒 Time savings: Automating the initial review process frees up human adjusters to focus on complex or high-value claims.
📈 Scalable operations: This approach can be applied to thousands of claims daily without additional headcount.
If you have any suggestions or scope of improvement, feel free to comment or you can reach me on LinkedIn - https://www.linkedin.com/in/hvmathan/
Thanks for reading!