

Cet article a été rédigé dans le cadre du projet : Réalisez une analyse de sentiments grâce au Deep Learning du parcours AI Engineer d'OpenClassrooms. Les données utilisées sont issues du jeu de données open source Sentiment140. Le code source complet est disponible sur GitHub.
🎓 OpenClassrooms • Parcours AI Engineer | 👋 Étudiant : David Scanu
🌐 Contexte et problématique métier
Dans le cadre de ma formation d'AI Engineer chez OpenClassrooms, ce projet s'inscrit dans un scénario professionnel où j'interviens en tant qu'ingénieur IA chez MIC (Marketing Intelligence Consulting), entreprise de conseil spécialisée en marketing digital.
Notre client, ✈️ Air Paradis (compagnie aérienne), souhaite anticiper les bad buzz sur les réseaux sociaux. La mission consiste à développer un produit IA permettant de prédire le sentiment associé à un tweet, afin d'améliorer la gestion de sa réputation en ligne.
⚡ Mission
Développer un modèle d'IA permettant de prédire le sentiment associé à un tweet.
Créer un prototype fonctionnel d'un modèle d'analyse de sentiments pour tweets selon trois approches différentes :
- Modèle sur mesure simple : Approche classique (régression logistique) pour une prédiction rapide
- Modèle sur mesure avancé : Utilisation de réseaux de neurones profonds avec différents word embeddings
- Modèle avancé BERT : Exploration de l'apport en performance d'un modèle BERT
Cette mission implique également la mise en œuvre d'une démarche MLOps complète :
- Utilisation de MLFlow pour le tracking des expérimentations et le stockage des modèles.
- Création d'un pipeline de déploiement continu (Git + Github + plateforme Cloud).
- Intégration de tests unitaires automatisés.
- Mise en place d'un suivi de performance en production via Azure Application Insight.
🔧 Technologies utilisées
- Langages : Python
- Bibliothèques ML/DL : Scikit-learn, TensorFlow/Keras, Transformers (BERT)
- MLOps : MLFlow, Git, GitHub Actions
- Backend : FastAPI, Heroku
- Frontend : Next.js / React
- Monitoring : Azure Application Insight
- Traitement texte : NLTK, Word Embeddings
🏛️ Structure du projet
📦 oc-ai-engineer-p07-analyse-sentiments-deep-learning/
┣━━ 📂 app/
┃ ┣━━ 📂 fastapi/ # Backend API de prédiction
┃ ┗━━ 📂 frontend/ # Application Next.js
┃
┣━━ 📂 documentation/ # Documentation du projet
┃ ┗━━ 📃 guide-app-insights.md # Guide de suivi des feedback utilisateur et des alertes avec Azure Application insights
┃
┗━━ 📂 notebooks/ # Notebooks Jupyter pour l'analyse et modèles
┣━━ 📝 01_Analyse_exploratoire.ipynb # Exploration et visualisation des données
┣━━ 📝 02_Modele_simple.ipynb # Bag of Words et classificateurs classiques
┣━━ 📝 03_Modele_avance_Word2Vec.ipynb # LSTM avec Word2Vec
┗━━ 📝 04_Modele_BERT.ipynb # DistilBERT pour analyse de sentiment📔 Notebooks du projet
- 📊 Notebook 1 : Analyse exploratoire des données - Exploration du dataset Sentiment140 et visualisations
- 🔍 Notebook 2 : Modèle classique (TF-IDF + Regression Logistique) - Implémentation de l'approche "sur mesure simple"
- 🧠 Notebook 3 : Modèle avancé (Word2Vec + LSTM) - Réseau de neurones avec word embeddings
- 🚀 Notebook 4 : Modèle BERT pour l'analyse de sentiment - Fine-tuning de DistilBERT (Google Colab)
🧭 Guides
- Guide d'utilisation de l'API FastAPI : API FastAPI qui expose un modèle de deep learning pour l'analyse de sentiment
- Guide d'utilisation du frontend Next.JS : Application Next.js avec Bootstrap pour l'interface utilisateur
- Guide de Monitoring pour Air Paradis : Mise en place du feedback utilisateur et des alertes avec Azure Application insights
📑 Méthodologie et données
Le jeu de données Sentiment140
Pour ce projet, nous avons utilisé le jeu de données open source Sentiment140, qui contient 1,6 million de tweets annotés selon leur polarité (négative ou positive). Ce dataset comprend six champs principaux :
- target : la polarité du tweet (0 = négatif, 4 = positif)
- ids : l'identifiant du tweet
- date : la date du tweet
- flag : une requête éventuelle
- user : l'utilisateur ayant posté le tweet
- text : le contenu textuel du tweet
Nous avons choisi ce jeu de données pour sa taille conséquente et sa pertinence vis-à-vis de notre objectif d'analyse de sentiments sur Twitter. Sa structure binaire (positif/négatif) correspond parfaitement à notre besoin de détecter les opinions négatives pouvant potentiellement nuire à l'image d'Air Paradis.
Analyse exploratoire des données Sentiment140
Notre analyse exploratoire a révélé des caractéristiques distinctives importantes entre les tweets positifs et négatifs :
- Les tweets positifs contiennent 93% plus d'URLs que les négatifs
- Les tweets positifs contiennent 48% plus de mentions (@)
- Les tweets positifs utilisent 39% plus de hashtags (#)
- Les tweets positifs utilisent 39% plus de points d'exclamation (!)
- Les tweets négatifs contiennent 24% plus d'ellipses (...)
- Les tweets négatifs sont légèrement plus longs et contiennent plus de mots
Cette analyse nous a permis de mieux comprendre les spécificités du langage sur Twitter et d'identifier des éléments discriminants entre sentiments positifs et négatifs. Ces observations ont directement influencé notre stratégie de prétraitement et la conception de nos modèles.
Prétraitement des données textuelles
En nous basant sur l'analyse exploratoire, nous avons développé une fonction de prétraitement spécifique pour les tweets :
def preprocess_tweet(tweet):
"""
Prétraite un tweet en appliquant plusieurs transformations :
- Conversion en minuscules
- Remplacement des URLs, mentions et hashtags par des tokens spéciaux
- Suppression des caractères spéciaux
- Tokenisation et lemmatisation
- Suppression des stopwords
"""
# Vérifier si le tweet est une chaîne de caractères
if not isinstance(tweet, str):
return ""
# Convertir en minuscules
tweet = tweet.lower()
# Remplacer les URLs par un token spécial
tweet = re.sub(r'https?://\S+|www\.\S+', '', tweet)
# Remplacer les mentions par un token spécial
tweet = re.sub(r'@\w+', '', tweet)
# Traiter les hashtags (conserver le # comme token séparé et le mot qui suit)
tweet = re.sub(r'#(\w+)', r'# \1', tweet)
# Supprimer les caractères spéciaux et les nombres, mais garder les tokens spéciaux
tweet = re.sub(r'[^\w\s<>@#!?]', '', tweet)
# Tokenisation
tokens = word_tokenize(tweet)
# Lemmatisation
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(token) for token in tokens]
# Supprimer les stopwords, mais conserver les négations importantes
stop_words = set(stopwords.words('english'))
important_words = {'no', 'not', 'nor', 'neither', 'never', 'nobody', 'none', 'nothing', 'nowhere'}
stop_words = stop_words - important_words
tokens = [token for token in tokens if token not in stop_words]
# Rejoindre les tokens en une chaîne
return ' '.join(tokens)Notre stratégie de prétraitement s'est concentrée sur trois aspects clés :
Traitement des éléments spéciaux : Plutôt que de simplement supprimer les URLs, mentions et hashtags, nous les avons remplacés par des tokens spéciaux (
Conservation des négations : Nous avons exclu les mots de négation de la liste des stopwords pour préserver le sens du sentiment exprimé.
Lemmatisation plutôt que stemming : Après avoir testé les deux approches, nous avons privilégié la lemmatisation qui préserve mieux le sens des mots tout en réduisant la dimensionnalité du vocabulaire.
🧠 Approches de modélisation
Pour répondre à la demande d'Air Paradis, nous avons développé et comparé trois approches de modélisation distinctes, de la plus simple à la plus avancée.
Modèle sur mesure simple (approche classique)
Notre première approche s'est appuyée sur des techniques classiques de machine learning, combinant une vectorisation des tweets avec des algorithmes de classification.
Nous avons d'abord exploré deux méthodes de représentation vectorielle de texte :
- Bag of Words : transformation des tweets en vecteurs numériques basés sur la fréquence d'apparition de chaque mot
- TF-IDF : pondération des mots selon leur importance relative dans le tweet et leur rareté dans l'ensemble du corpus
Pour la phase de classification, nous avons testé quatre algorithmes différents :
- Régression Logistique : modèle linéaire adapté aux problèmes de classification binaire
- SVM Linéaire : recherche d'un hyperplan optimal séparant les sentiments positifs et négatifs
- Random Forest : ensemble d'arbres de décision offrant robustesse et réduction du surapprentissage
- Naive Bayes : classifieur probabiliste particulièrement adapté aux données textuelles
Après optimisation des hyperparamètres via validation croisée, le SVM Linéaire combiné au Bag of Words s'est révélé être la solution la plus performante avec les hyperparamètres suivants :
- Coefficient de régularisation :C=0.01
- Configuration :dual=True
- Nombre maximal d'itérations : max_iter=1000
Les métriques d'évaluation confirment l'efficacité de ce modèle :
- F1 Score : 0.785 (équilibre entre précision et rappel)
- F2 Score : 0.798 (privilégiant le rappel pour minimiser les faux négatifs)
- ROC AUC : 0.852 (bonne capacité discriminative)
- Précision globale : 79,8% sur notre jeu de test
Cette approche, malgré sa relative simplicité, fournit déjà une base solide pour la détection des sentiments négatifs dans les tweets concernant Air Paradis. Elle constitue une référence précieuse pour évaluer les gains potentiels des modèles plus sophistiqués que nous avons développés par la suite.
Modèle sur mesure avancé (réseaux de neurones avec word embeddings)
Pour notre deuxième approche, nous avons exploré les techniques de deep learning avec des embeddings de mots et des réseaux de neurones récurrents. Nous avons d'abord optimisé notre environnement pour utiliser efficacement le GPU disponible (GTX 1060 3GB) :
-
Optimisations matérielles :
- Désactivation du recurrent_dropout pour permettre l'utilisation de CuDNNLSTM optimisé
- Activation de XLA (Accelerated Linear Algebra) pour optimiser les graphes d'opérations
- Utilisation de la précision mixte (float16/float32)
- Augmentation de la taille du batch à 256 pour exploiter le parallélisme
- Optimisation du pipeline de données avec tf.data.Dataset et prefetch
-
Word Embeddings : nous avons comparé deux techniques d'embeddings pour représenter les mots dans un espace vectoriel dense :
- Word2Vec pré-entraîné sur un large corpus de tweets
- GloVe (Global Vectors for Word Representation)
Architecture du réseau : nous avons implémenté un réseau de neurones bidirectionnel avec plusieurs couches LSTM et des mécanismes de régularisation :
def create_optimized_lstm_model(embedding_matrix, max_seq_length=MAX_SEQUENCE_LENGTH, trainable=False):
vocab_size, embedding_dim = embedding_matrix.shape
# Entrée du modèle
input_layer = tf.keras.layers.Input(shape=(max_seq_length,))
# Couche d'embedding avec des poids pré-entraînés
embedding_layer = tf.keras.layers.Embedding(
input_dim=vocab_size,
output_dim=embedding_dim,
weights=[embedding_matrix],
input_length=max_seq_length,
trainable=trainable
)(input_layer)
# Dropout spatial
dropout_1 = tf.keras.layers.SpatialDropout1D(0.3)(embedding_layer)
# Couche LSTM bidirectionnelle optimisée pour GPU
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(
units=128,
dropout=0.2,
recurrent_dropout=0.0, # Optimisation GPU
return_sequences=True
)
)(dropout_1)
# Deuxième couche LSTM
lstm_layer_2 = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(
units=64,
dropout=0.2,
recurrent_dropout=0.0 # Optimisation GPU
)
)(lstm_layer)
# Couche dense avec activation ReLU
dense_1 = tf.keras.layers.Dense(64, activation='relu')(lstm_layer_2)
dropout_2 = tf.keras.layers.Dropout(0.4)(dense_1)
# Couche de sortie
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(dropout_2)
# Créer et compiler le modèle
model = tf.keras.Model(inputs=input_layer, outputs=output_layer)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy']
)
return modelL'architecture de notre modèle LSTM comprend :
- Une couche d'embedding initialisée avec les poids pré-entraînés Word2Vec
- Un dropout spatial pour réduire la corrélation entre les features consécutives
- Deux couches LSTM bidirectionnelles (128 puis 64 unités) pour capturer les dépendances contextuelles
- Des couches de dropout pour la régularisation et éviter le surapprentissage
- Une couche dense intermédiaire avec activation ReLU
- Une couche de sortie avec activation sigmoïde pour la classification binaire
Les résultats de l'entraînement montrent une progression constante de l'accuracy, comme on peut le voir sur les graphiques ci-dessous :
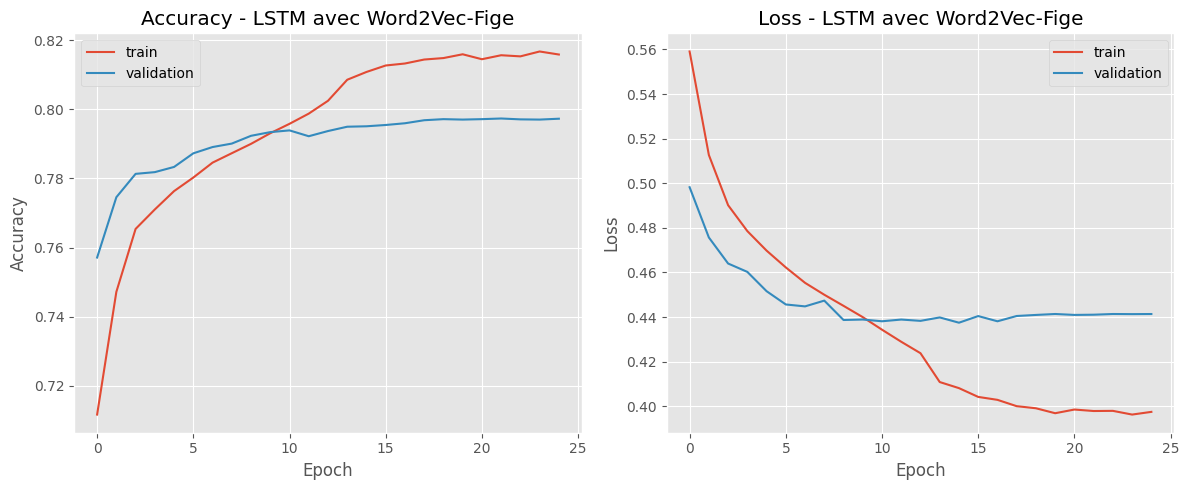
Cette approche plus sophistiquée nous a permis d'atteindre une précision de 81,8% sur l'ensemble de validation, avec un score de 85,2% sur le jeu d'entraînement, surpassant ainsi le modèle simple.
Modèle BERT (approche transformer)
Pour notre troisième approche, nous avons exploré l'état de l'art en NLP en utilisant BERT (Bidirectional Encoder Representations from Transformers) :
- Modèle pré-entraîné : nous avons utilisé DistilBERT, une version allégée et distillée de BERT, pour réduire les coûts de calcul tout en maintenant des performances élevées
- Fine-tuning : nous avons affiné le modèle sur notre jeu de données spécifique d'analyse de sentiments
Pour cette approche, nous avons utilisé le modèle DistilBertForSequenceClassification de la bibliothèque Hugging Face, qui est spécifiquement conçu pour les tâches de classification de séquences textuelles :
def train_bert_sentiment(data_path, model_name="distilbert-base-uncased", batch_size=4, epochs=3, sample_size=20000):
"""
Fonction principale pour l'entraînement du modèle DistilBERT sur une tâche d'analyse de sentiments.
"""
# Définir les paramètres
params = {
'model_name': model_name,
'batch_size': batch_size,
'learning_rate': 2e-5,
'epochs': epochs,
'max_length': 128,
'sample_size': sample_size
}
# Charger les données
print("Chargement du dataset...")
column_names = ['target', 'ids', 'date', 'flag', 'user', 'text']
raw_data = pd.read_csv(data_path, encoding='utf-8', names=column_names)
# Préparer les données
print("Préparation des données...")
data_splits = prepare_data(raw_data, sample_size=sample_size)
# Initialiser le tokenizer et le modèle
print("Initialisation du modèle DistilBERT...")
tokenizer = DistilBertTokenizer.from_pretrained(model_name)
model = DistilBertForSequenceClassification.from_pretrained(
model_name,
num_labels=2 # Sentiment binaire (0 = négatif, 1 = positif)
)
# Ajustement du batch size selon la mémoire GPU
adjusted_batch_size = min(8, batch_size)
# Création des datasets et des dataloaders
train_dataset = TweetDataset(data_splits['train']['texts'], data_splits['train']['labels'], tokenizer)
val_dataset = TweetDataset(data_splits['val']['texts'], data_splits['val']['labels'], tokenizer)
test_dataset = TweetDataset(data_splits['test']['texts'], data_splits['test']['labels'], tokenizer)
train_loader = DataLoader(train_dataset, batch_size=adjusted_batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=adjusted_batch_size * 2)
test_loader = DataLoader(test_dataset, batch_size=adjusted_batch_size * 2)
# Détection du device (GPU/CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
# Entraînement du modèle avec accumulation de gradients pour optimiser l'utilisation mémoire
gradient_accumulation_steps = max(1, 16 // adjusted_batch_size)
history, metrics = train_model(
model,
train_loader,
val_loader,
test_loader,
device,
epochs=epochs,
gradient_accumulation_steps=gradient_accumulation_steps
)
# Enregistrement du modèle dans MLflow
run_id = log_model_to_mlflow(model, tokenizer, model_name, metrics, params)
return {
'model': model,
'tokenizer': tokenizer,
'metrics': metrics,
'run_id': run_id
}DistilBERT est particulièrement adapté à notre tâche car il :
- Utilise une architecture transformer bidirectionnelle pour capturer le contexte dans les deux directions
- A été pré-entraîné sur un large corpus de textes, ce qui lui permet de comprendre les nuances linguistiques
- Est 40% plus léger que BERT tout en conservant 97% de ses performances
- S'intègre parfaitement dans un pipeline MLOps grâce à son API standardisée
Cette approche transformers nous a permis d'atteindre une précision de 91,3 %, démontrant la puissance des architectures basées sur l'attention pour la compréhension du langage naturel.
Comparaison des performances des modèles
Voici un récapitulatif des performances obtenues avec nos différentes approches :
| Modèle | Précision (Accuracy) | F1-Score | Temps d'entraînement | Taille du modèle |
|---|---|---|---|---|
| Régression Logistique + TF-IDF | 79,8% | 0,797 | ~5 minutes | ~15 MB |
| LSTM + Word2Vec | 85,2% | 0,851 | ~2 heures | ~90 MB |
| LSTM + GloVe | 84,7% | 0,846 | ~2 heures | ~88 MB |
| DistilBERT fine-tuné | 91,3% | 0,912 | ~4 heures (GPU) | ~250 MB |
Pour le déploiement en production, nous avons retenu le modèle LSTM avec Word2Vec, qui offre le meilleur compromis entre performance et ressources requises. Bien que DistilBERT ait obtenu de meilleurs résultats, sa taille et ses exigences en termes de ressources de calcul le rendaient moins adapté à un déploiement sur une infrastructure Cloud gratuite.
⚙️ Mise en œuvre du MLOps
Principes du MLOps
Le MLOps (Machine Learning Operations) est une méthodologie qui vise à standardiser et à automatiser le cycle de vie des modèles de machine learning, de leur développement à leur déploiement en production. Pour ce projet, nous avons mis en œuvre plusieurs principes clés du MLOps :
- Reproductibilité : environnement de développement versionné et documenté
- Automatisation : pipeline de déploiement continu
- Monitoring : suivi des performances du modèle en production
- Amélioration continue : collecte de feedback et réentraînement périodique
Cette approche nous a permis de créer une solution robuste et évolutive pour Air Paradis.
Tracking des expérimentations avec MLFlow
Pour assurer une gestion efficace des expérimentations, nous avons utilisé MLFlow, un outil open-source spécialisé dans le suivi et la gestion des modèles de machine learning :
- Tracking des métriques : pour chaque expérimentation, nous avons enregistré automatiquement les paramètres du modèle, les métriques de performance (accuracy, F1-score, précision, rappel) et les artefacts générés
- Centralisation des modèles : tous les modèles entraînés ont été stockés de manière centralisée avec leurs métadonnées
- Visualisation : l'interface utilisateur de MLFlow nous a permis de comparer visuellement les différentes expérimentations
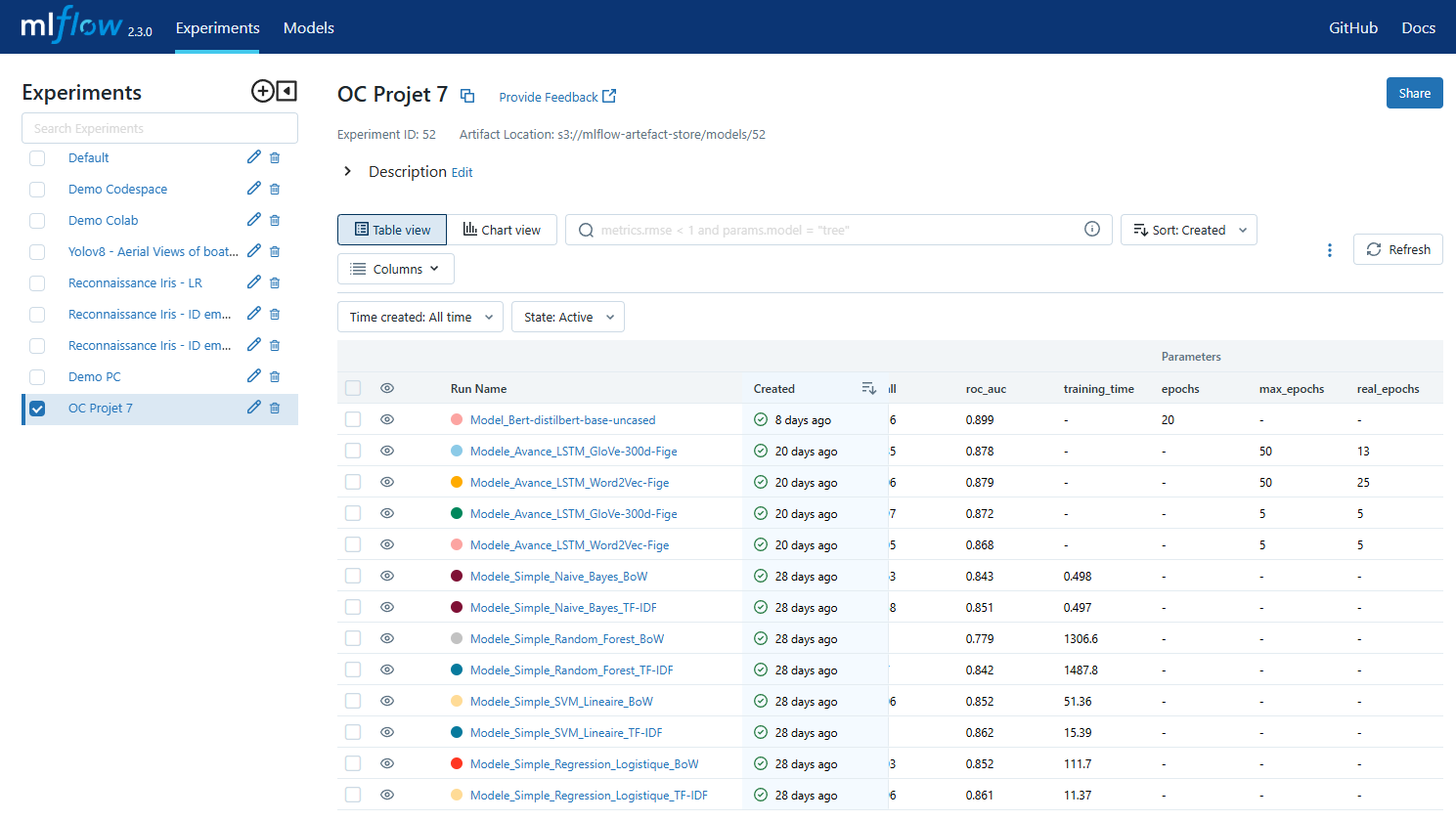
Cette approche nous a permis de garder une trace claire de l'évolution de nos modèles et de sélectionner objectivement le plus performant pour le déploiement.
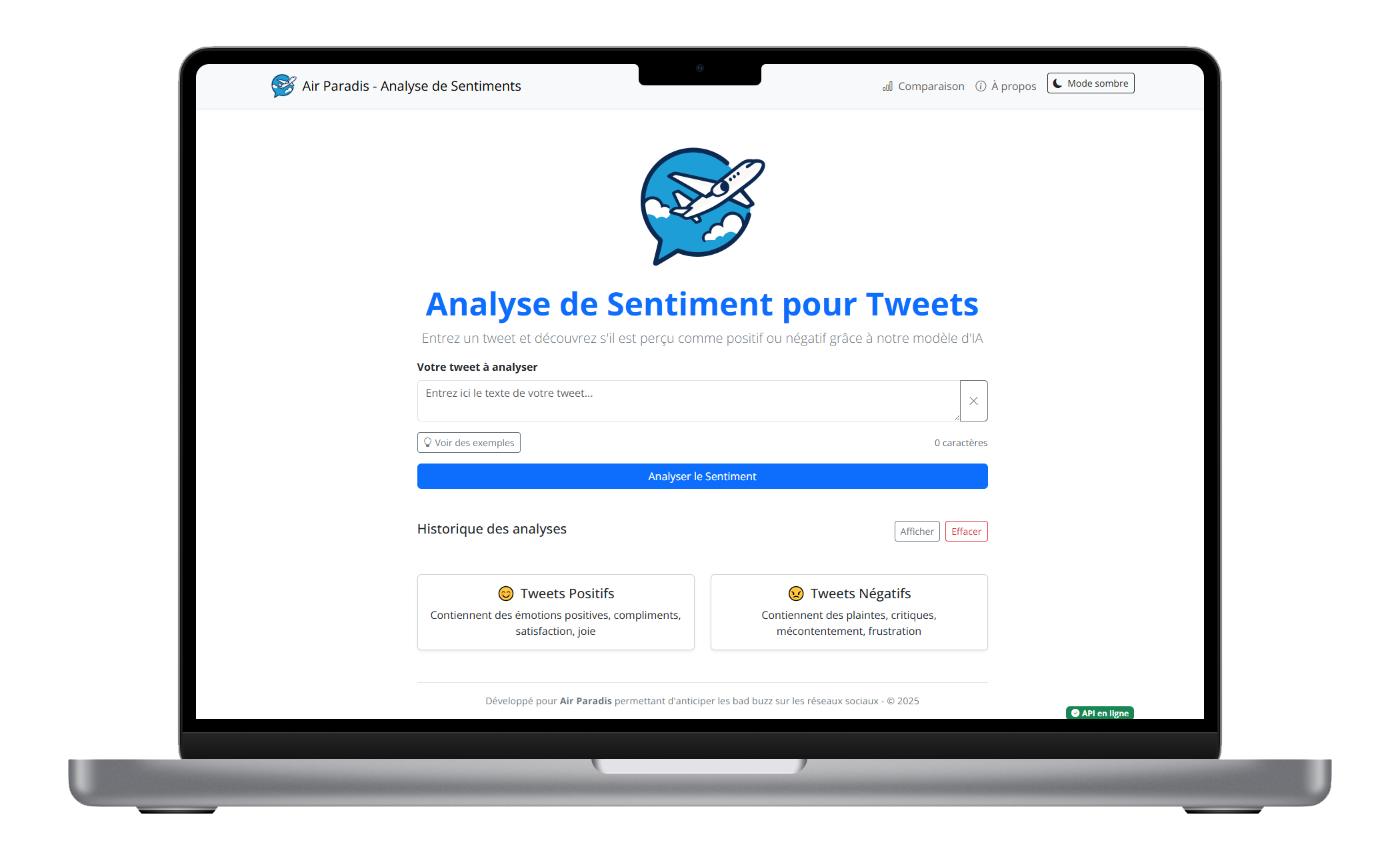
💻 Interface utilisateur
Architecture de l'application
Notre solution se compose de deux parties principales :
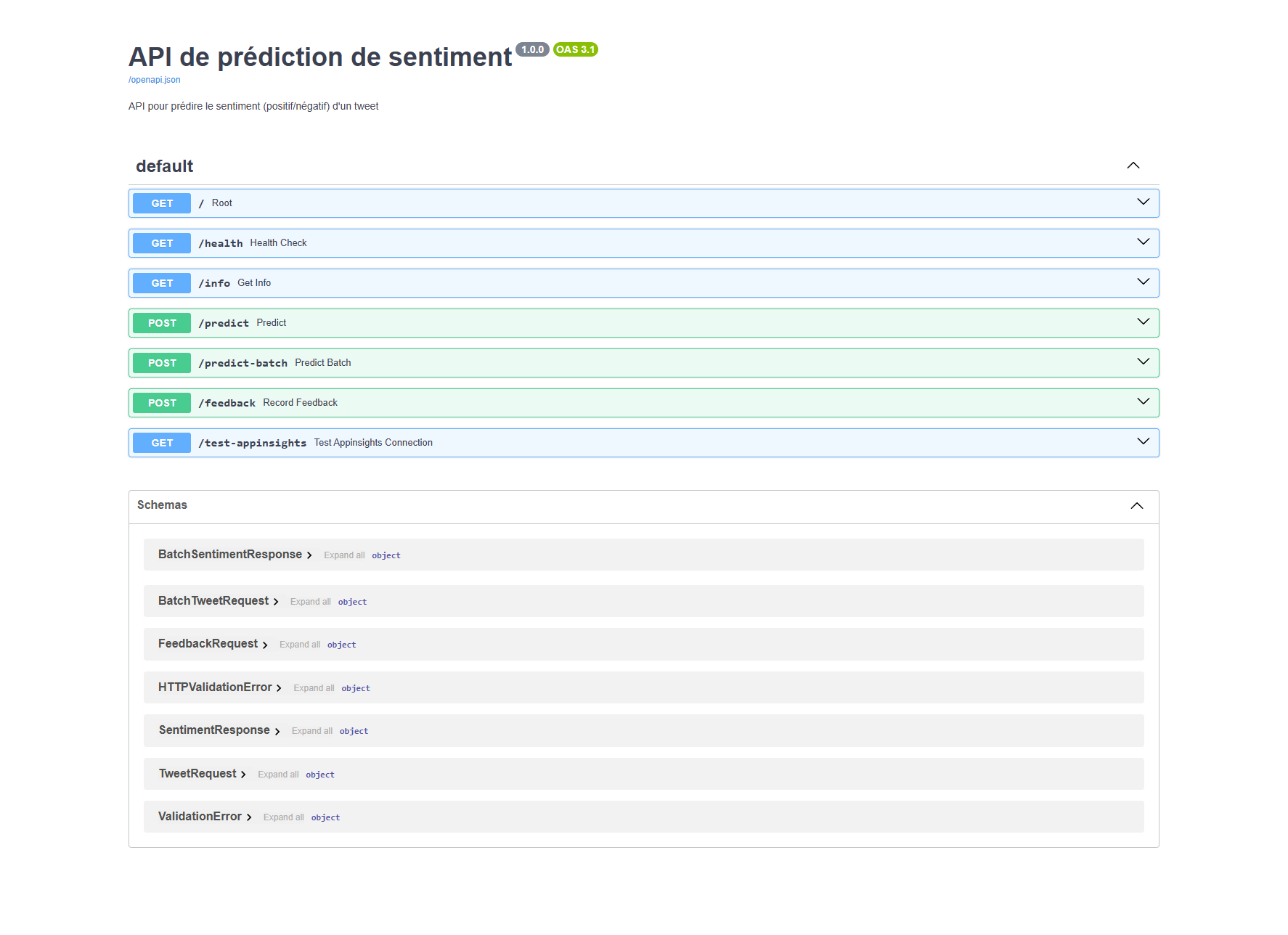
-
Backend (FastAPI) :
- API REST exposant le modèle d'analyse de sentiments
- Endpoints pour la prédiction individuelle et par lots
- Système de feedback et de monitoring
- Téléchargement automatique des artefacts du modèle depuis MLFlow
-
Frontend (Next.js) :
- Interface utilisateur intuitive et responsive
- Mode clair/sombre pour le confort visuel
- Visualisation des résultats de prédiction
- Système de collecte de feedback
- Widget d'indication de connexion avec l'API
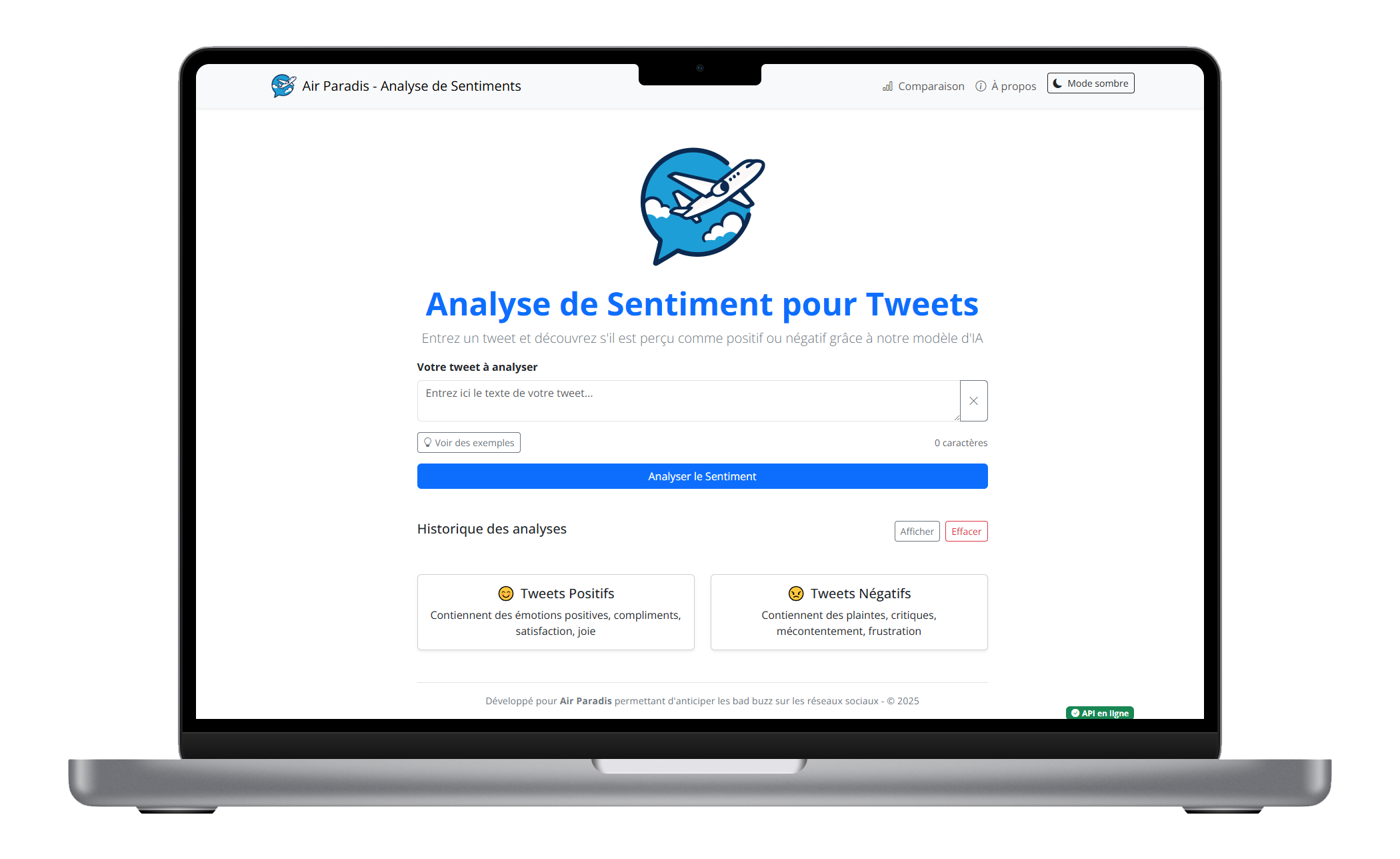
Fonctionnalités de l'interface utilisateur
L'interface utilisateur offre plusieurs fonctionnalités clés pour faciliter l'analyse de sentiments :
- Analyse individuelle : prédiction du sentiment d'un tweet unique
- Exemples prédéfinis : tweets d'exemple positifs et négatifs
- Historique : conservation des analyses précédentes
- Feedback : possibilité de signaler des prédictions incorrectes
Cette interface a été conçue pour être intuitive et accessible aux équipes marketing d'Air Paradis, sans nécessiter de connaissances techniques approfondies.
🔄 Pipeline de déploiement continu
Pour automatiser le déploiement de notre modèle, nous avons mis en place un pipeline CI/CD (Intégration Continue / Déploiement Continu) avec les composants suivants :
- Versionnement du code : utilisation de Git pour le contrôle de version
- GitHub Actions : automatisation des tests et du déploiement à chaque push sur la branche principale
- Déploiement sur Heroku : plateforme Cloud pour héberger notre API de prédiction
Tests unitaires automatisés
Pour garantir la fiabilité de notre solution, nous avons implémenté des tests unitaires automatisés couvrant les aspects critiques :
-
Test du endpoint de santé : Vérifie que l'API répond correctement sur
/healthavec un code 200 et confirme que le statut retourné est "ok". Le modèle est chargé correctement. -
Test du endpoint de prédiction : S'assure que l'API traite correctement les requêtes POST sur
/predict, accepte un texte à analyser et renvoie un résultat contenant les champs "sentiment" et "confidence".
def test_health_endpoint(client):
response = client.get("/health")
assert response.status_code == 200
assert response.json()["status"] == "ok"
def test_predict_endpoint(client):
response = client.post("/predict", json={"text": "I love flying with this airline!"})
assert response.status_code == 200
result = response.json()
assert "sentiment" in result
assert "confidence" in resultGitHub Actions
Le déploiement est entièrement automatisé grâce à GitHub Actions :
- Déclenchement : À chaque commit/push sur la branche principale, GitHub Actions lance le workflow.
- Tests automatisés : Le workflow exécute tous les tests unitaires.
- Déploiement conditionnel : Uniquement si les tests réussissent, l'application est déployée automatiquement sur Heroku.
Création du workflow GitHub Actions
Pour la création du workflow GitHub Actions, nous créons un fichier .github/workflows/heroku-deploy.yml à la racine dont voici le contenu :
name: Deploy to Heroku
on:
push:
branches:
- main
paths:
- 'app/fastapi/**'
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.10'
- name: Install dependencies
working-directory: ./app/fastapi
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run tests
working-directory: ./app/fastapi
run: |
python -m pytest tests/test_api.py -v
env:
MLFLOW_TRACKING_URI: ${{ secrets.MLFLOW_TRACKING_URI }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
RUN_ID: ${{ secrets.RUN_ID }}
APPINSIGHTS_INSTRUMENTATION_KEY: ${{ secrets.APPINSIGHTS_INSTRUMENTATION_KEY }}
deploy:
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Install Heroku CLI
run: |
curl https://cli-assets.heroku.com/install.sh | sh
- name: Deploy to Heroku
uses: akhileshns/[email protected]
with:
heroku_api_key: ${{ secrets.HEROKU_API_KEY }}
heroku_app_name: "air-paradis-sentiment-api"
heroku_email: ${{ secrets.HEROKU_EMAIL }}
appdir: "app/fastapi"
region: "eu"Configuration des secrets GitHub
Le workflow GitHub Actions a besoin d'accéder aux variables d'environnement. Nous avons donc renseigner les "secrets" nécessaires. Dans notre dépôt GitHub, nous allons dans "Settings" > "Secrets and variables" > "Actions", puis nous cliquons sur "New repository secret". Nous ajoutons les secrets suivants:
| Nom du secret | Description |
|---|---|
HEROKU_API_KEY |
Clé API Heroku |
HEROKU_EMAIL |
Email du compte Heroku |
MLFLOW_TRACKING_URI |
URI du serveur MLflow |
RUN_ID |
ID du run MLflow |
APPINSIGHTS_INSTRUMENTATION_KEY |
Clé Application Insights |
Déploiement sur Heroku
Pour le déploiement de notre solution, nous avons choisi Heroku pour plusieurs raisons :
- Plan gratuit : conforme à la demande de limiter les coûts pour ce prototype
- Intégration avec GitHub : facilite le déploiement continu avec GitHub Actions
- Scalabilité : possibilité d'évoluer si le projet est approuvé pour la production
- Région Europe : conformité avec les exigences de localisation des données
Configuration Heroku
Notre application utilise les fichiers de configuration suivants pour Heroku :
-
Procfile :
web: uvicorn main:app --host=0.0.0.0 --port=${PORT:-8000} -
runtime.txt :
python-3.10.12 - requirements.txt : Liste de toutes les dépendances nécessaires
Les variables d'environnement sur Heroku incluent :
-
MLFLOW_TRACKING_URI: URI du serveur MLflow -
RUN_ID: Identifiant du run MLflow du modèle déployé -
APPINSIGHTS_INSTRUMENTATION_KEY: Clé pour Azure Application Insights
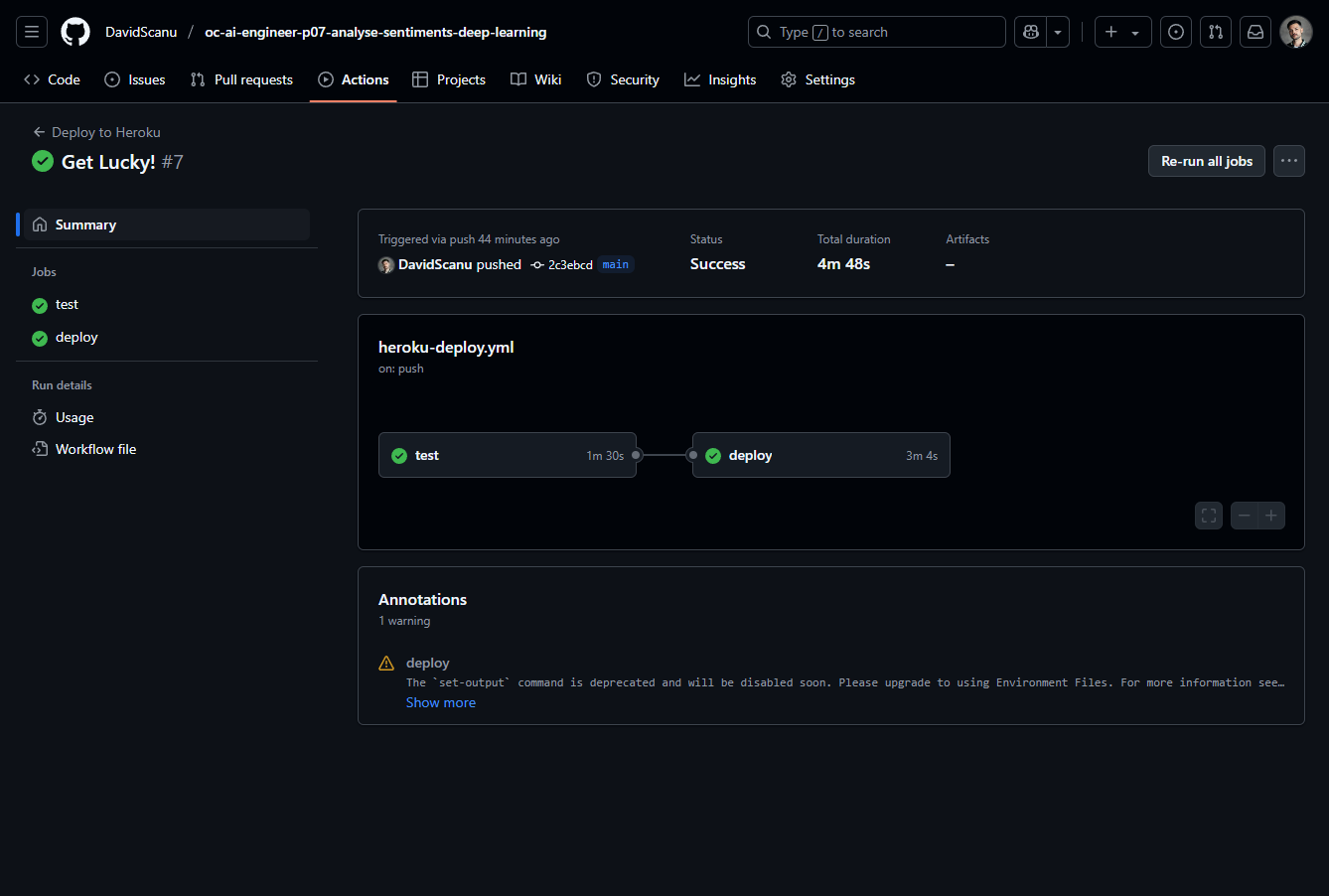
Exemple d'exécution et déploiement réussis
La capture d'écran suivante indique les tests ont été passés avec succès et que le déploiement est réussi sur Heroku.
Avantages de notre pipeline CI/CD
Notre pipeline de déploiement continu offre plusieurs avantages significatifs :
- Automatisation complète : Aucune intervention manuelle nécessaire
- Fiabilité accrue : Tests systématiques réduisant les risques
- Traçabilité : Chaque déploiement lié à un commit Git spécifique
- Feedback rapide : Information immédiate en cas de problème
Cette approche MLOps moderne nous permet de nous concentrer sur l'amélioration de notre modèle d'analyse de sentiment plutôt que sur les aspects opérationnels, tout en garantissant que chaque nouvelle version est correctement validée avant la mise en production.
📡 Suivi de la performance en production
Mise en place d'Azure Application Insights
Pour assurer un suivi efficace des performances du modèle en production, nous avons intégré Azure Application Insights, un service d'analyse des performances applicatives :
- Télémétrie : collecte automatique des données de performance de l'API
- Événements personnalisés : enregistrement d'événements spécifiques liés au modèle
- Visualisation : tableaux de bord pour suivre l'évolution des performances
Cette intégration nous permet de disposer d'une vision complète du comportement de notre modèle en situation réelle.
Système de feedback utilisateur
Un élément clé de notre approche MLOps est la collecte de feedback utilisateur sur les prédictions du modèle :
- Interface de validation : pour chaque prédiction, l'utilisateur peut indiquer si elle est correcte ou non
- Collecte structurée : enregistrement du tweet, de la prédiction initiale et de la correction éventuelle
- Stockage centralisé : toutes les données de feedback sont centralisées dans Azure Application Insights
Dans Azure Application Insights, pour consulter les feedbacks de tweets incorrectement prédits, il suffit d'exécuter la commande suivante :
customEvents
| where name == "model_feedback" and customDimensions.is_correct == "False"
| sort by timestamp desc
| project timestamp,
tweet = tostring(customDimensions.tweet),
prediction = tostring(customDimensions.prediction),
corrected_sentiment = tostring(customDimensions.corrected_sentiment)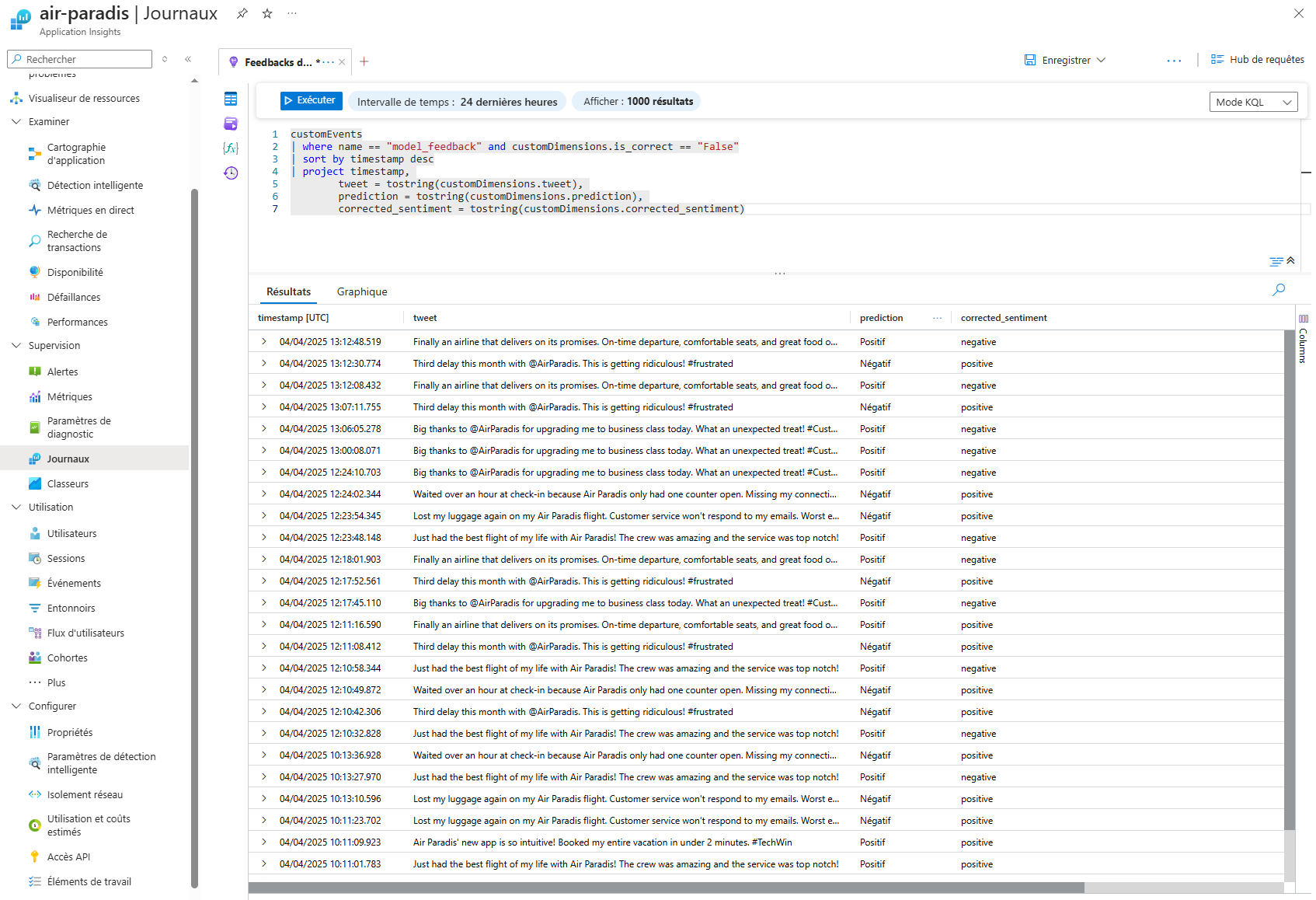
Ce système permet de constituer progressivement un corpus d'exemples difficiles qui serviront à améliorer le modèle. Ces exemples difficiles sont particulièrement précieux car ils représentent les cas limites où le modèle actuel échoue, révélant ainsi ses points faibles spécifiques.
En collectant systématiquement ces tweets mal classifiés, nous créons un dataset enrichi qui cible précisément les lacunes du modèle. Cette approche d'apprentissage actif (active learning) est beaucoup plus efficace qu'une simple augmentation de données aléatoire, car elle concentre les efforts d'amélioration sur les zones problématiques.
Configuration des alertes automatiques
Pour détecter rapidement les problèmes potentiels, nous avons configuré un système d'alertes automatiques :
- Définition du seuil : déclenchement d'une alerte si 3 prédictions incorrectes sont signalées dans un intervalle de 5 minutes.
- Notification : envoi d'un email aux responsables du projet.
- Suivi : journalisation des alertes pour analyse ultérieure.
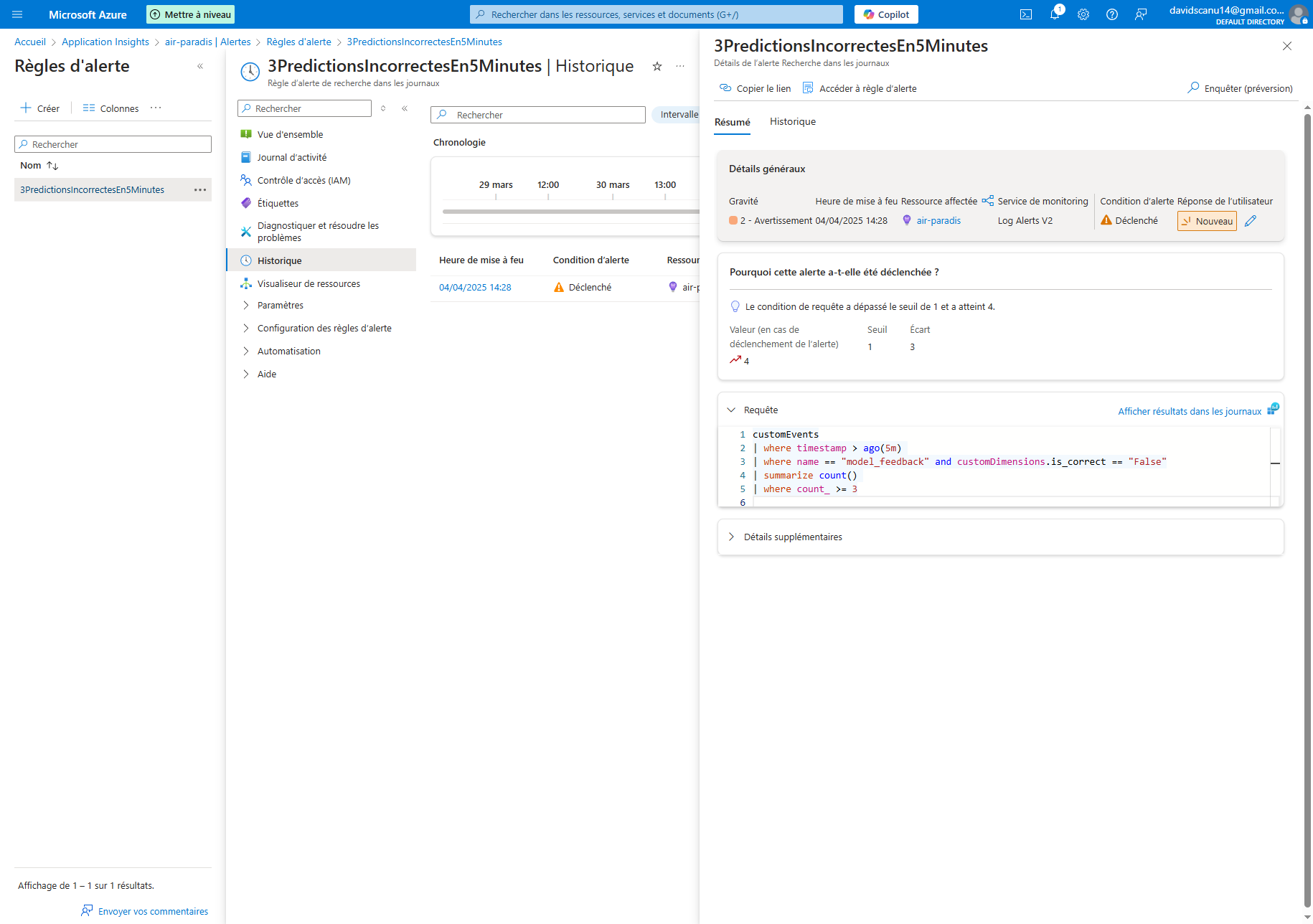
Ce mécanisme proactif permet à l'équipe d'intervenir rapidement en cas de dégradation des performances du modèle.
Stratégie d'amélioration continue du modèle
Pour garantir la pertinence du modèle dans le temps, nous définissons une stratégie d'amélioration continue :
- Analyse périodique : examen mensuel des tweets mal prédits pour identifier des patterns
- Enrichissement des données : ajout des exemples difficiles au jeu d'entraînement
- Réentraînement : mise à jour trimestrielle du modèle avec les nouvelles données
- Déploiement automatisé : mise en production de la nouvelle version via le pipeline CI/CD
Cette approche cyclique permet d'adapter le modèle à l'évolution du langage sur Twitter et aux spécificités des conversations concernant Air Paradis.
🏁 Conclusion
Résultats obtenus
Ce projet nous a permis de développer un prototype fonctionnel d'analyse de sentiments pour tweets, répondant pleinement aux attentes d'Air Paradis :
- Performance : notre modèle LSTM avec Word2Vec atteint une précision de 85,2%, offrant une détection fiable des sentiments négatifs.
- Déploiement : la solution est accessible via une API REST déployée sur Heroku.
- Interface : une application ergonomique permet aux équipes marketing d'utiliser facilement le modèle.
- Monitoring : un système complet de suivi et d'alertes garantit la détection rapide des problèmes potentiels.
Perspectives d'évolution
Si ce prototype est validé par Air Paradis, plusieurs axes d'amélioration pourraient être explorés :
- Déploiement du modèle BERT : migration vers une infrastructure permettant d'exploiter les performances supérieures de BERT
- Analyse en temps réel : intégration avec l'API Twitter pour une surveillance continue
- Classification multi-classes : distinction entre sentiments négatifs, neutres et positifs
- Analyse thématique : identification des sujets spécifiques générant des sentiments négatifs
Avantages pour Air Paradis
Cette solution d'analyse de sentiments offre plusieurs avantages stratégiques pour Air Paradis :
- Détection précoce : identification des bad buzz potentiels avant qu'ils ne prennent de l'ampleur
- Réactivité : capacité à intervenir rapidement sur les problèmes signalés
- Intelligence client : meilleure compréhension des préoccupations et des attentes des clients
- Protection de l'image : préservation de la réputation de la compagnie sur les réseaux sociaux
En conclusion, ce projet illustre comment les technologies d'IA, combinées à une approche MLOps structurée, peuvent apporter une réelle valeur ajoutée dans la gestion de la réputation en ligne d'une entreprise. Air Paradis dispose désormais d'un outil puissant pour anticiper et gérer efficacement sa présence sur les réseaux sociaux.