Introduction
In the process of building a data warehouse,data synchronizationis a critical step.
Apache SeaTunnel, as a high-performance*distributed data integration tool*, is widely used for synchronizing MySQL data to OLAP databases like Doris.
However, optimizing this synchronization process to*improve efficiency and reduce resource consumption*is a challenge that every data engineer faces.
In this article, we will explore optimization strategies for*syncing MySQL to Doris with Apache SeaTunnel*, using real configuration files as examples.
Environment Optimization
Parallelism Settings
Parallelism is a key factor affecting synchronization performance.
In our real-time data lake project, we tested different parallelism settings:
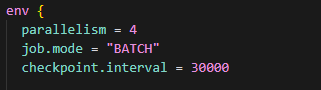
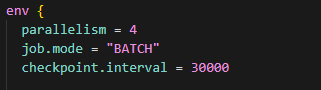
env {
parallelism = 4 \# Full load configuration
}
env {
parallelism = 8 \# CDC mode configuration
}Optimization Recommendations:
- Full Load Mode:Adjust parallelism based on table size and server resources. Larger tables may require higher parallelism.
- CDC Mode:Consider the load on the source database to prevent excessive parallelism from causing stress.
- Different tables can have different parallelism settings— for example, an orders table can use higher parallelism, while a configuration table may use a lower setting.
JVM Parameter Optimization
Proper*JVM parameters*can enhance the stability and performance of SeaTunnel:
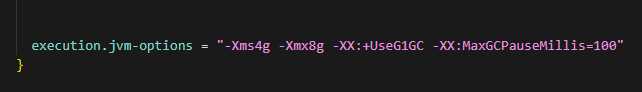
execution.jvm-options = "-Xms4g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=100"Optimization Recommendations:
- Adjust heap size based on*available memory;ensure max heap memory does not exceed 70% of physical memory*.
- Use the*G1 garbage collectorforbetter large memory management*.
- Set a reasonable*GC pause time*to balance throughput and latency.
Checkpoint Configuration
Checkpoint settings affect task*fault tolerance and recovery*capabilities:
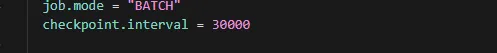
checkpoint.interval = 10000 \# CDC mode
checkpoint.interval = 30000 \# Full load modeOptimization Recommendations:
- CDC Mode:Use shorter checkpoint intervals (e.g.,10 seconds) to ensure real-time data and quick recovery.
- Full Load Mode:Longer checkpoint intervals*reduce checkpoint overhead*.
- Configure a*local checkpoint storage pathforfaster recovery*:
execution.checkpoint.data-uri = "file:///opt/seatunnel/checkpoints"Source-side Optimization
Read Rate Limiting
To prevent excessive load on the*source MySQL database*, rate limiting should be applied:
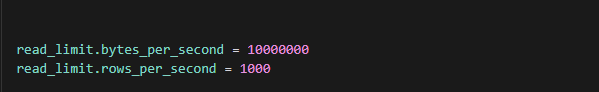
read\_limit.bytes\_per_second = 10000000 \# Limit read rate to ~10MB/s
read\_limit.rows\_per_second = 1000 \# Limit read rate to 1000 rows/secOptimization Recommendations:
- Adjust rate limits based on*source database load capacity*.
- Loosen restrictions*during off-peak hours, tighten themduring peak periods*.
- Apply*stricter limits*for critical business tables.
Partitioned Parallel Reads
Using an*effective partition strategyimproves efficiency duringfull synchronization*:

query = "select id, ... from gmall.order_info"
partition_column = "id"
partition_num = 4Optimization Recommendations:
- Choose*evenly distributed columns(e.g., auto-increment
id) aspartition keys*. - Set the number of partitions*based on table size and parallelism, usuallyequal to or slightly higher than parallelism*.
- For*large tables, usecustom partition SQLto ensurebalanced data distribution*across partitions.
Connection Pool Optimization
Optimizing connection pool settings can enhance*data source reading efficiency*.
Optimization Recommendations:
- Set
max_sizeto*1.5-2 times the parallelism level*. - Maintain appropriate
min_idleconnections to*reduce creation overhead*. - Adjust
max_idle_msbased on workload to*prevent frequent connection creation and destruction*.
CDC-Specific Configurations
For*CDC mode*, additional optimization parameters are needed:
snapshot.mode = "initial"
snapshot.fetch.size = 10000
chunk.size.rows = 8096Optimization Recommendations:
- Use
**initial**mode for the first sync, and**latest**mode for incremental sync. - Adjust
**snapshot.fetch.size**to balance*memory usageandnetwork overhead*. - Increase
**chunk.size.rows**for*large tables*to enhance parallel efficiency.
Transformation Optimization
SQL Transformation Optimization
Efficient SQL transformations can*reduce processing overhead*:

transform {
Sql {
query = """
select
id,
date(create_time) as k1, # Ensure k1 is DATE type
...other fields...
from mysql_seatunnel
"""
}
}Optimization Recommendations:
- Select*only necessary fieldstoreduce data transmission*.
- Perform*data type conversions at the sourcetolighten the load on Doris*.
- Use appropriate functions for*date-time fields*to ensure compatibility with the target table.
- For*complex transformations, considermultiple transformation steps*for better maintainability.
Destination-side Optimization
Write Mode Configuration
A well-configured*write modecan improveDoris ingestion performance*:

sink.properties {
format = "json"
read\_json\_by_line = "true"
max\_filter\_ratio = "1.0"
merge_type = "MERGE"
delete_enable = "true"
}Optimization Recommendations:
- Use
**JSON**formatfor*simpler processing*. - Adjust
**max_filter_ratio**based on*data quality needs*. - Enable
**MERGE**mode and**delete_enable**for CDC scenarios.
Conclusion
Optimizing*MySQL to Doris synchronization with Apache SeaTunnelrequires acomprehensive approachinvolvingparallelism settings, JVM tuning, checkpoint optimization, read/write rate limits, and transformation strategies*.
By applying the best practices outlined in this article, you can*enhance synchronization performance, reduce resource consumption, and ensure data reliabilityin yourdata warehouse*. 🚀