

Olá a todos! Hoje gostaria de abordar um tema que interessa a muitos: a conexão de um modelo de linguagem grande como DeepSeek ou ChatGPT com sua própria base de conhecimento.
Neste artigo, vou explicar detalhadamente os princípios dos bancos de dados vetoriais e por que eles podem ser usados como parte da conexão da sua base de conhecimento com redes neurais “grandes” já prontas.
Como exemplo, vamos considerar a busca na documentação da Amverum Cloud. Amverum Cloud é uma alternativa ao Heroku mais barata e fácil de implantar, com domínios gratuitos, armazenamento persistente incluído e a possibilidade de atualizar projetos via git push amverum master.
Atualmente estamos desenvolvendo ativamente um agente de IA que ajudará os usuários a implantar projetos na nuvem, eliminar erros no código e na configuração, e também simplificará o trabalho com a documentação. E a busca na documentação é um excelente caso para usar um banco de dados vetorial, como o Chroma.
Vamos analisar imediatamente um bloco limitante
Redes neurais já prontas, como DeepSeek, ChatGPT ou Claude, são projetadas inicialmente para receber certos dados de texto com um contexto definido (prompt) como entrada e, com base em seus parâmetros e treinamento, processam sua solicitação, realizando a tarefa necessária.
Ou seja, como trabalharemos com modelos de linguagem já prontos, não poderemos nos desviar do processo de preparar prompts com um contexto definido e enviar solicitações para as redes neurais já prontas.
Isso leva a uma tarefa lógica: como conectar nosso banco de dados ao processo de comunicação com a rede neural? Imagine que sejam milhares de páginas de literatura profissional. É duvidoso que formemos centenas de megabytes de dados em um único prompt gigante e, ao mesmo tempo, esperemos que a rede neural aceite trabalhar com isso. No mínimo, receberemos um erro de que o contexto transmitido foi excedido.
É lógico que a solução sugere-se por si só: formar sua solicitação, complementando-a apenas com o contexto necessário para essa solicitação específica, mas como fazer isso? A opção mais simples é organizar algum tipo de motor de busca SEO. Enviamos, por exemplo, “treinamento de redes neurais” e é feita uma busca em nossos gigabytes de dados, mas aqui surge um problema lógico. Mesmo que encontremos informação, digamos, mil ocorrências da frase “treinamento de redes neurais”, como destacamos esse contexto? Como decidimos o que é importante transmitir à rede neural para a comunicação e o que não é necessário? Claro, você pode complicar muito esse motor de busca, mas, como entende, essa abordagem não é ótima, e isso significa que é preciso buscar outra solução mais flexível e bem-sucedida, sobre a qual falaremos hoje em detalhes.
Bancos de dados vetoriais
Provavelmente você nunca ouviu falar desses bancos de dados, ou só conhece superficialmente. Por isso, a seguir vou explicar detalhadamente e de forma simples o que são esses bancos de dados e, o mais importante, entenderemos como eles nos ajudarão em nossa tarefa.
Resumindo e de forma simples, um banco de dados vetorial é uma representação de dados: texto ou bytes em uma representação numérica ou, mais corretamente, em forma de vetores.
Por exemplo, a palavra “olá” em representação vetorial será assim: [-0.012, 0.124, -0.056, 0.203, …, 0.078] (removi números desnecessários para maior clareza).
No contexto atual, não importa muito como esses números são obtidos matematicamente. Agora só é importante uma compreensão geral da representação digital dos dados.
Benefício prático
Neste ponto, você pode dizer com razão: “Tudo isso é divertido, mas qual o uso prático de tudo isso e como se obtêm esses números estranhos?” Vamos descobrir.
A primeira coisa a entender é que as redes neurais não podem ler seus textos nem ver suas fotos no sentido humano. Por exemplo, quando você envia uma solicitação ao ChatGPT, acontece o seguinte:
- A rede neural recebe o texto.
- Transforma esse texto em vetores ou, mais corretamente, em embeddings.
- Usa esses embeddings para gerar uma resposta baseada nos parâmetros treinados do modelo.
- Realiza os cálculos.
- Recebe uma resposta em forma de embedding.
- Transforma o embedding em texto humano (Linguagem Natural).
- Envia a você o texto humano.
Ou seja, já nesta etapa fica claro que na comunicação com redes neurais aparece algo como uma representação numérica da informação recebida (representação em forma de embeddings), e agora vamos descobrir por que isso é necessário.
Embeddings e para que servem
Os embeddings são “impressões digitais do significado” de um texto. Vamos ver este conceito com um exemplo real.
Imagine que você tem uma pilha enorme de documentos: livros, artigos, anotações. E quer encontrar informações neles não por palavras exatas, mas por significado.
Como implementar isso:
- A rede neural aceita todas as palavras que você preparou e as converte em sequências de números (embeddings).
Exemplo:
- “Gato” → [0.2, -0.5, 0.7, …]
- “Gatinho” → 0.19, -0.48, 0.69, …
Um banco de dados vetorial, como o Chroma, armazena esses números e pode:
- Buscar vetores que estejam próximos em significado (mesmo que as palavras sejam diferentes).
- Responder a perguntas como: “Encontre algo sobre animais de estimação com bigodes” → vai retornar documentos sobre gatos, gatinhos.
Analogia simples
- Busca normal (como Ctrl+F): busca por coincidências exatas de palavras.
- A consulta “carro” não encontrará “automóvel”.
- Busca por embeddings: busca por significados semelhantes.
- “Carro”, “automóvel”, “transporte” - estarão próximos nos números e o banco de dados os relacionará.
Por que isso é necessário?
Os chatbots (como o ChatGPT) usam embeddings para entender consultas por significado, não por coincidências exatas.
Você pode perguntar a um documento com suas próprias palavras, e o sistema entenderá, mesmo que não haja coincidências exatas.
Resultado: Os embeddings são um “tradutor” de texto para números, para que você possa buscar por significado, não por letras. Os bancos de dados vetoriais são seu “armazenamento”, onde a busca funciona como um ímã para ideias semelhantes.
Existem redes neurais especiais que podem transformar seus dados de texto em uma representação vetorial (numérica). Para tais tarefas, não é necessário recorrer a gigantes como ChatGPT ou DeepSeek, basta usar redes neurais especializadas. Mais adiante, na parte prática, mostrarei a criação de embeddings e a implementação de busca inteligente usando como exemplo a rede neural paraphrase-multilingual-MiniLM-L12-v2.
Essa rede neural pesa apenas 500 MB e roda localmente até mesmo em computadores medianos, por isso é ideal para nossas tarefas.
Bancos de dados vetoriais (continuação)
Agora, você já deve ter entendido que, ao trabalhar com dados em representação numérica, aplica-se a seguinte conexão:
- Os dados de texto são transformados em uma representação vetorial (numérica) por meio de uma rede neural especial.
- Para que a busca inteligente funcione, precisamos:
- Obter o embedding do seu conjunto de dados em representação vetorial.
- Escrever uma consulta de texto como “encontre tudo o que se carrega na mão”.
- Transformar a consulta em representação vetorial.
- Comparar o vetor da consulta com os vetores do grande embedding.
- Transformar o resultado encontrado de volta para linguagem humana.
- Fornecer o resultado.
Agora surge uma pergunta lógica sobre o armazenamento desses dados numéricos. É claro que podemos pegar o texto, transformá-lo em vetores usando alguma, por enquanto desconhecida, paraphrase-multilingual-MiniLM-L12-v2, mas onde armazenar isso?
Isso pode ser armazenado em um banco de dados especializado, como o Chroma, com o qual trabalharemos hoje, ou na RAM.
Princípio do armazenamento em RAM
Preparar os dados de texto. Transformá-los em embeddings.
Enviar uma solicitação de embedding.
Depois que o script termina de ser executado, a memória é limpa e, ao iniciar novamente, é necessário gerar os embeddings novamente.
Princípio do armazenamento em um banco de dados especializado
Preparar os dados de texto.
Transformá-los em embeddings.
Salvar o embedding no formato do banco de dados.
Ao trabalhar, conectar-se ao banco de dados e usar o embedding já pronto.
Os bancos de dados vetoriais podem ser tanto locais (self-hosted) quanto em nuvem.
O banco de dados local mais simples é o ChromaDB, com o qual trabalharemos hoje. Escolhi por sua simplicidade e ótima integração com a linguagem Python.
Outros bancos de dados vetoriais locais: Qdrant, Weaviate, Milvus e outros.
Aqui alguns exemplos de bancos de dados em nuvem: Pinecone, RedisVL, Qdrant Cloud e outros.
O que vamos fazer hoje?
Mais adiante haverá ainda mais teoria, mas tenho certeza de que você está esperando a parte prática. Então, vamos descobrir o que faremos na prática, além de absorver a informação teórica.
A seguir, mostrarei com um exemplo prático como transformar dados de texto em um banco de dados vetorial ChromaDB. Primeiro, criaremos um banco de dados usando um exemplo simples e trabalharemos com a busca nele, e depois trabalharemos com um exemplo mais complexo, sobre o qual construiremos nosso assistente inteligente no futuro.
Depois de entender completamente como funciona a geração de embeddings e a busca inteligente dentro deles, conectaremos as grandes redes neurais DeepSeek e GPT ao contexto geral, implementando a seguinte lógica:
- O usuário envia uma solicitação específica.
- Usando a busca inteligente, extraímos conteúdo adicional do nosso banco de dados vetorial.
- Reenviamos a solicitação do usuário junto com nossos “resultados da busca inteligente” para DeepSeek / GPT e recebemos uma resposta da rede neural baseada no nosso contexto pessoal.
Vai ser interessante!
Banco de dados vetorial simples
Agora, para consolidar o bloco teórico geral descrito acima, prepararemos um banco de dados ChromaDB simples baseado na descrição de produtos de uma loja online fictícia (para o exemplo mais simples, é um exemplo visual).
Imagine que temos um conjunto de produtos deste tipo:
SHOP_DATA = [
{
"text": 'Portátil Lenovo IdeaPad 5: 16 Gb RAM, SSD 512 Gb, LED 15.6", precio 550 $.',
"metadata": {
"id": "1",
"type": "product",
"category": "laptops",
"price": 55000,
"stock": 3,
},
},
{
"text": 'Smartphone Xiaomi Redmi Note 12: 128 Gb RAM, SSD 512 Gb, LED 15.6", precio 1550 $.',
"metadata": {
"id": "2",
"type": "product",
"category": "phones",
"price": 18000,
"stock": 10,
},
},
# ...
]Como pode ver, a informação é apresentada como uma lista de dicionários, cada um contendo duas chaves principais: texto e metadados.
Documentos e metadados em bancos de dados vetoriais
Este é um ponto importante que vale a pena analisar com mais detalhe. Deve compreender que na base de dados ChromaDB, toda a nossa pesquisa “inteligente” funcionará “prontamente” apenas no valor da chave de texto (o nome pode ser qualquer coisa).
No contexto dos bancos de dados vetoriais, distinguem-se conceitos como documentos (no nosso caso, é o texto que descreve um produto específico) e metadados.
Restrições de comprimento de documento
Na etapa de preparação dos dados de texto para carregá-los em um banco de dados vetorial, é extremamente importante levar em conta as restrições de comprimento de texto estabelecidas pelo modelo que irá convertê-los para uma representação vetorial. Essas restrições dependem da rede neural específica e geralmente variam de 256 a 512 tokens.
Portanto, se, por exemplo, você planeja adicionar um livro inteiro de 200 páginas ao banco de dados, primeiro ele deve ser dividido em trechos menores, cada um não maior que 256–512 tokens. Isso garantirá que o modelo processe corretamente o texto e preserve a integridade semântica no espaço vetorial.
O modelo paraphrase-multilingual-MiniLM-L12-v2 com o qual trabalharemos hoje tem um limite de 512 tokens por documento. Isso equivale a aproximadamente 250–350 palavras ou 1500–2200 caracteres. No entanto, como usaremos nossos dados com as poderosas redes neurais DeepSeek e ChatGPT, faremos o tamanho do documento ainda menor para evitar sobrecarregar o contexto.
O papel dos metadados
Os metadados são nosso assistente, tornando a busca mais precisa e localizada. Aqui está um exemplo simples:
Imagine que sua loja online vende notebooks, smartphones e outros equipamentos. Você pode limitar a busca inteligente pela categoria dos metadados. Independentemente de você usar os metadados para a busca explicitamente, é importante entender que os documentos encontrados (resultados da busca) sempre conterão essas tags meta, o que permitirá processamento adicional.
Exemplo com livros:
Imagine que você decidiu carregar toda a série de livros de Harry Potter em um banco de dados vetorial. Você dividiu todo o texto em trechos de 512 tokens e especificou as seguintes tags meta: título do livro, número da página, número do capítulo e outras informações.
Depois, você faz uma consulta como “Quando Harry Potter soube sobre as Horcruxes”. Sua busca inteligente retorna certos resultados: documentos com tags meta que permitem entender de qual livro vem e em que página está a informação.
Outro exemplo de trabalho com tags meta é limitar a busca a um livro específico, série de livros ou autor ao formar uma consulta.
Lembre-se de que a busca inteligente não está relacionada aos metadados de forma alguma, a menos que você especifique explicitamente a lógica para processá-los na consulta.
Uso prático dos metadados
No contexto dos metadados para nossos produtos:
{
"id": "1",
"type": "product",
"category": "laptops",
"price": 55000,
"stock": 3,
}Transmitimos o ID do produto, tipo, categoria, preço e estoque. Por exemplo, uma busca inteligente de produtos poderia ser implementada no site e apenas os produtos com o ID encontrado seriam exibidos ao usuário na página de resultados.
Assim, um banco de dados vetorial é uma excelente ferramenta não apenas para integração com redes neurais, mas também para resolver tarefas práticas, como um motor de busca inteligente em um site ou em sua API.
Criando um Banco de Dados Vetorial em Python
Agora vamos escrever algum código. O código será simples, uma vez que não precisamos de dividir documentos (descrições de produtos) em fragmentos ou executar lógica adicional para analisar e processar produtos.
Preparar o projeto
A primeira coisa que fazemos é criar um novo projeto Python com um ambiente virtual dedicado. Adicione um ficheiro requirements.txt ao projeto com o seguinte conteúdo:
langchain-huggingface==0.1.2
torch==2.6.0
loguru==0.7.3
chromadb==0.6.3
sentence-transformers==3.4.1
langchain-chroma==0.2.2
pydantic-settings==2.8.1
langchain-text-splitters==0.3.7
langchain-deepseek==0.1.3
langchain-openai==0.3.11O que é o langchain?
Já deve ter reparado que encontrei a palavra langchain nas dependências até 5 vezes, o que não é acidental.
Langchain é uma poderosa ferramenta Python que lhe permite integrar um grande número de redes neuronais e outras ferramentas úteis ao seu projeto, prontas a utilizar. Este framework merece ser mencionado em mais do que um artigo, pelo que recomendo vivamente que leia a documentação do projeto (mais de 105 mil estrelas no GitHub devem indicar que o projeto merece atenção).
No projeto de hoje, iremos utilizar as seguintes ferramentas deste framework:
langchain-text-splitters==0.3.7
Uma ferramenta para dividir textos grandes em fragmentos mais pequenos (pedaços). Contém várias estratégias de segmentação: por símbolos, frases, tokens, blocos semânticos. É necessário para processar documentos grandes quando estes excedem a janela de contexto dos modelos de linguagem (256–512 tokens no nosso caso).
langchain-deepseek==0.1.3
Integração com os modelos de IA da DeepSeek. Permite utilizar modelos de linguagem DeepSeek poderosos para análise e geração de texto (hoje a demonstração será baseada no modelo deepseek-chat).
langchain-openai==0.3.11
Adaptador para trabalhar com a API OpenAI. Fornece acesso à família de modelos de linguagem GPT e às suas funções. Inclui suporte para modelos de chat, modelos de incorporação e funções para trabalhar com imagens via DALL-E (vamos considerar um exemplo com o modelo gpt-3.5-turbo).
langchain-chroma==0.2.2
Conector para a base de dados vetorial ChromaDB. Permite armazenar e recuperar eficientemente representações vetoriais de textos para implementar funções de pesquisa semântica e construir bases de conhecimento com a capacidade de pesquisar por similaridade.
langchain-huggingface==0.1.2
A integração com o ecossistema Hugging Face dá acesso a milhares de modelos abertos desenvolvidos pela comunidade. Isto inclui modelos de linguagem, modelos para incorporações, classificação e outras tarefas de PNL. Esta ferramenta é especialmente útil quando precisa de executar modelos localmente ou utilizar modelos especializados. No nosso caso, poderemos utilizar a rede neural local paraphrase-multilingual-MiniLM-L12-v2.
Outros pacotes
torch: Uma biblioteca de aprendizagem automática que alimenta muitos modelos de linguagem
loguru: Um registador prático para acompanhar o progresso do nosso código
chromadb: A base de dados vetorial real que usaremos
sentence-transformers: Uma biblioteca para converter texto em vetores (embeddings)
Instalando dependências
Agora vamos instalar:
pip install -r requirements.txtA instalação pode demorar muito tempo devido ao peso total dos pacotes que estão a ser instalados (no meu caso, o processo de instalação demorou cerca de 20 minutos).
Criando um banco de dados
Vamos agora criar um ficheiro chamado create_chromadb.py (pode dar-lhe qualquer nome).
Realizar importações:
import time
from langchain_huggingface import HuggingFaceEmbeddings
import torch
from loguru import logger
from langchain_chroma import ChromaVamos definir as principais variáveis:
CHROMA_PATH = "./shop_chroma_db"
COLLECTION_NAME = "shop_data"As coleções em bases de dados vetoriais podem ser comparadas a tabelas em bases de dados clássicas. Se não especificar um nome de coleção, o ChromaDB fornece um valor predefinido.
Vamos agora adicionar uma variedade de produtos (quanto mais, melhor):
SHOP_DATA = [
{
"text": 'Lenovo IdeaPad 5: 16 RAM, SSD 512, 15.6", prise 55000 $.',
"metadata": {
"id": "1",
"type": "product",
"category": "laptops",
"price": 55000,
"stock": 3,
},
},
# add other products
]E por fim, vamos escrever uma função para criar a base de dados:
def generate_chroma_db():
try:
start_time = time.time()
logger.info("Carregando o modelo de incorporação...")
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
model_kwargs={"device": "cuda" if torch.cuda.is_available() else "cpu"},
encode_kwargs={"normalize_embeddings": True},
)
logger.info(f"Modelo carregado em {time.time() - start_time:.2f} seg")
logger.info("Criação do Chroma DB...")
chroma_db = Chroma.from_texts(
texts=[item["text"] for item in SHOP_DATA],
embedding=embeddings,
ids=[str(item["metadata"]["id"]) for item in SHOP_DATA],
metadatas=[item["metadata"] for item in SHOP_DATA],
persist_directory=CHROMA_PATH,
collection_name=COLLECTION_NAME,
)
logger.info(f"Chroma DB criado em {time.time() - start_time:.2f} seg")
return chroma_db
except Exception as e:
logger.error(f"Erro: {e}")
raiseNeste código nós:
- Crie um modelo para converter texto em vetores (embeddings)
- Inicialize a base de dados Chroma com os nossos produtos
- Transferir textos, IDs, metadados e definições do espaço de pesquisa
- Registar criação bem-sucedida de base de dados ou erros
É importante referir que utilizámos o modelo multilingue paraphrase-multilingual-MiniLM-L12-v2, que funciona bem com a língua portuguesa. Isto permitir-nos-á criar corretamente representações vetoriais para os nossos produtos em russo. O modelo em si será carregado automaticamente a partir do repositório Hugging Face na primeira execução. Não haverá necessidade de o carregar em execuções repetidas se o modelo já estiver na sua máquina.
A particularidade do modelo escolhido é que é equilibrado em tamanho e qualidade — oferece bons resultados de vetorização de texto mesmo no CPU, mas com uma placa gráfica compatível com CUDA funciona muito mais rapidamente. Além disso, graças ao parâmetro normalize_embeddings=True, todos os embeddings criados serão normalizados, o que aumentará a precisão da pesquisa de produtos semelhantes.
Execute o código:
if __name__ == "__main__":
generate_chroma_db()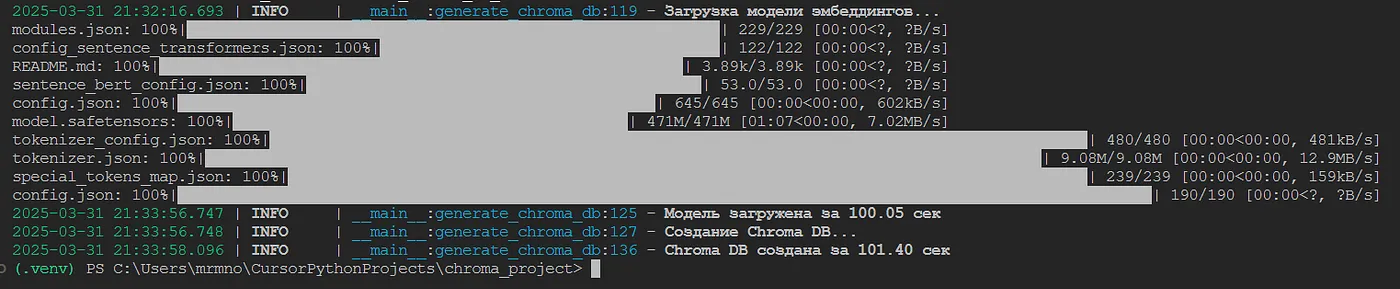
Feito! Temos agora uma base para criar uma base de dados vetorial com uma descrição de documentos. Na raiz do projeto após o lançamento, deverá aparecer uma pasta chamada “shop_chroma_db”, na qual estarão localizados os ficheiros da base de dados. No futuro, poderemos utilizar esta base de dados para a pesquisa semântica de produtos por solicitação do utilizador — a pesquisa encontrará não só correspondências exatas, mas também produtos semanticamente próximos.
Escrevendo um mecanismo de busca para o banco de dados
Agora que a base de dados está pronta, podemos descrever um sistema de pesquisa simples dentro da mesma. O princípio aqui será o seguinte:
- Ligar a uma base de dados existente, recebendo embeddings
- Receba uma consulta de pesquisa do utilizador
- Transforme a consulta de pesquisa numa representação vetorial
- Comparar o vetor de consulta recebido com os dados da base de dados
- Devolver ao utilizador o número de documentos que este solicitou
Quanto à emissão de documentos ao utilizador. Há aqui uma característica: indicamos sempre o número de documentos que queremos receber. Digamos que podem ser 5 peças. Se não ligar estritamente os metadados através de filtros, receberá sempre como resposta da base de dados exatamente o número de documentos especificado.
Ou seja, mesmo que a saída não corresponda de todo ao seu pedido, continuará a receber os seus 5 documentos como resposta. Isto é importante considerar ao desenvolver uma interface de utilizador.
A resposta em si consiste em: um documento, metadados ligados a este e um índice de classificação (quanto mais baixo for o índice, mais semelhante em significado será o documento que irá receber). A emissão em si baseia-se no princípio: quanto mais baixo for o índice, maior será a posição na emissão.
Agora vamos voltar ao código.
Importações:
from langchain_huggingface import HuggingFaceEmbeddings
import torch
from loguru import logger
from langchain_chroma import ChromaVariáveis:
CHROMA_PATH = "./shop_chroma_db"
COLLECTION_NAME = "shop_data"Vamos agora descrever a função para ligar a uma base de dados existente:
def connect_to_chroma():
"""Ligue-se ao Chroma."""
try:
logger.info("Incorporação de download...")
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
model_kwargs={"device": "cuda" if torch.cuda.is_available() else "cpu"},
encode_kwargs={"normalize_embeddings": True},
)
chroma_db = Chroma(
persist_directory=CHROMA_PATH,
embedding_function=embeddings,
collection_name=COLLECTION_NAME,
)
logger.success("Sucesso na ligação com o Chroma")
return chroma_db
except Exception as e:
logger.error(f"Erro ao ligar o Chroma: {e}")
raiseEsta função irá retornar um objeto de base de dados pronto a usar, dentro do qual a pesquisa vetorial será realizada.
Vamos agora descrever uma função que permitirá a pesquisa tanto por documento (páginas de documentação) como por metadados:
def search_products(query: str, metadata_filter: dict = None, k: int = 4):
"""
Pesquisa de página
"""
try:
chroma_db = connect_to_chroma()
results = chroma_db.similarity_search_with_score(
query, k=k, filter=metadata_filter
)
logger.info(f"Encontrado {len(resultados)} resultado da consulta: {query}")
formatted_results = []
for doc, score in results:
formatted_results.append(
{
"text": doc.page_content,
"metadata": doc.metadata,
"similarity_score": score,
}
)
return formatted_results
except Exception as e:
logger.error(f"Erro: {e}")
raiseE agora vamos chamar-lhe:
for i in search_products(query="como implantar uma aplicação no Amverum, com git push?"):
print(i)O parâmetro metadata_filter permite-nos especificar condições de filtragem de metadados. O exemplo de pesquisa de produtos de loja online é mais adequado aqui do que a nossa documentação. Por exemplo, se quisermos encontrar apenas portáteis com um preço abaixo dos 600 dólares, podemos usar um filtro como este:
filter_condition = {
"category": "laptops",
"price": {"$lt": 600}
}Aqui quero salientar que este exemplo é educativo. Num sistema de produção, é normalmente criada uma classe para gerir uma sessão com uma base de dados, para que se possa ligar uma vez e manter a ligação. Na implementação atual, cada chamada à função irá reiniciar a ligação e carregar o modelo de incorporação, o que consome muitos recursos. No próximo artigo, se perceber que está interessado neste tema, vou mostrar-lhe como implementar esta classe e como pode criar uma aplicação web completa baseada numa base de dados vetorial.
A propósito, o código-fonte do projeto de hoje, bem como a classe já escrita para gerir a ligação à base de dados vetorial, podem ser encontrados no meu canal de Telegram “Easy Way to Python”. O código-fonte completo do projeto está lá há cerca de uma semana.
Ligue para a pesquisa e veja os resultados.

Tenha em atenção o valor da pontuação de similaridade. Quanto mais baixo for este valor, mais próximo estamos do significado da consulta.
Nada mau, certo? Embora não tenhamos especificado explicitamente um modelo específico de aspirador ou as suas características na consulta, a pesquisa vetorial foi capaz de compreender a semântica da consulta e devolver os resultados mais relevantes da nossa base de dados. Isto demonstra o poder das bases de dados vetoriais combinadas com modelos de linguagem modernos.
Vamos praticar
Agora que já tem uma compreensão básica dos princípios de trabalho com bases de dados vetoriais, podemos começar a criar uma lógica mais complexa.
Falaremos do serviço Amverum Cloud, que já referi nos meus artigos anteriores sobre o Habr. Em suma, é uma plataforma para a fácil implementação (lançamento remoto) de projetos em quase qualquer linguagem de programação.
Uma das vantagens do Amverum Cloud é a capacidade de implementar rapidamente um projeto em diversas tecnologias utilizando o git push (ou arrastando ficheiros na interface), bem como obter um nome de domínio gratuito para o mesmo. Além disso, o serviço oferece proxy integrado gratuito para as APIs OpenAI, Antropic, Cloude e Grok, o que é conveniente para interagir com o LLM. Graças a estas capacidades técnicas, o serviço conta com uma documentação muito extensa e detalhada — para todas as ocasiões: desde guias básicos, como a migração do Heroku, a tópicos mais específicos — por exemplo, lançamento de projetos em FastAPI ou Django, ou resolução de problemas de faturação.
Esta documentação (e são cerca de 70 documentos diferentes) é perfeita para uma demonstração prática: podemos pegar numa série de textos, transformá-la numa base de dados vectorial e mostrar como integrar eficazmente esta base de dados com modelos de redes neuronais para obter respostas significativas e úteis.
Dados de entrada
Já tinha em mãos cerca de 70 documentos em Markdown da Amverum neste formato:
# Suporte de sondas Kubernetes
## Como configurar?
O formulário requer o preenchimento das configurações em formato yaml, nativo do formato utilizado
pelo próprio k8s (ver [aqui](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/)).
O ficheiro de configuração é substituído na sua implementação, que é carregada com ele no cluster.
**Isto significa que se carregou uma configuração que não funciona ou no formato errado, o seu projeto irá falhar na fase de compilação.** …
Estes documentos foram-me fornecidos como um projeto contendo ficheiros md e outros ficheiros técnicos. Mas muito provavelmente, no seu caso, não haverá esse presente.
Por conseguinte, é importante lembrar que para recolher informações para a base de dados, pode utilizar qualquer ferramenta conveniente para si: análise de sites, carregamento de dados das suas próprias bases de dados SQL, leitura de documentos nos formatos Excel, Word, PDF e assim por diante. O principal é que no final a informação seja convertida num formato suportado por bases de dados vectoriais e que tenha uma estrutura clara.
A primeira coisa que implementei no formato de uma tarefa com preparação foi transformar todos estes ficheiros com uma estrutura aninhada num formato JSON deste tipo:
{
"text": "some text",
"metadata": {
"section_count": 2,
"section_1": "backups",
"section_2": "backups /data"
}
}Ou seja, são informações de texto integral na legenda do texto, sem sinais de pontuação, caracteres especiais e letras maiúsculas, e informações técnicas colocadas nos metadados, como o número de secções, nomes, etc.
É importante compreender que os metadados são os nossos assistentes, mas nada impede que carregue apenas textos. No entanto, com os metadados, obtemos oportunidades adicionais para filtrar e analisar os resultados de pesquisa.
Vamos descrever a lógica para criar uma pasta com ficheiros JSON:
import json
import os
import re
import string
import sys
from typing import Any, Dict, List
from config import settings
from loguru import loggerAqui usei as bibliotecas internas do Python, com exceção do loguru — para um registo conveniente dos resultados. A extração em si será orientada para expressões regulares.
Vamos gerar as constantes:
HEADER_PATTERN = re.compile(r"^(#+)\s(.+)")
PUNCTUATION_PATTERN = re.compile(f"[{re.escape(string.punctuation)}]")
WHITESPACE_PATTERN = re.compile(r"\s+")Vamos descrever a lógica para normalizar textos:
def normalize_text(text: str) -> str:
"""Normalização de texto: remoção de pontuação e caracteres especiais."""
if not isinstance(text, str):
raise ValueError("O texto de entrada deve ser uma string")
# Removendo pontuação
text = PUNCTUATION_PATTERN.sub(" ", text)
# Removendo quebras de linha e espaços extra
text = WHITESPACE_PATTERN.sub(" ", text)
# Convertendo para minúsculas
return text.lower().strip()Vamos escrever a lógica para analisar um documento no formato md:
def parse_markdown(md_path: str) -> Dict[str, Any]:
"""Análise de dados"""
if not os.path.exists(md_path):
raise FileNotFoundError(f"Ficheiro {md_path} não encontrado")
try:
with open(md_path, "r", encoding="utf-8") as file:
content = file.read()
except Exception as e:
logger.error(f"Erro de leitura {md_path}: {e}")
raise
sections: List[str] = []
section_titles: List[str] = []
current_section: str | None = None
current_content: List[str] = []
for line in content.splitlines():
section_match = HEADER_PATTERN.match(line)
if section_match:
if current_section:
sections.append("\n".join(current_content).strip())
section_titles.append(current_section)
current_content = []
current_section = section_match.group(2)
current_content.append(current_section)
else:
current_content.append(line)
if current_section:
sections.append("\n".join(current_content).strip())
section_titles.append(current_section)
# Normalização de texto
normalized_sections = [normalize_text(section) for section in sections]
full_text = " ".join(normalized_sections)
# Estrutura de metadados
metadata = {
"file_name": os.path.basename(md_path),
"section_count": len(section_titles),
}
# Adicionar cabeçalho
for i, title in enumerate(section_titles):
metadata[f"section_{i+1}"] = title
return {"text": full_text, "metadata": metadata}E descreveremos a função para analisar todos os documentos:
def process_all_markdown(input_folder: str, output_folder: str) -> None:
"""processamento de markdown"""
if not os.path.exists(input_folder):
raise FileNotFoundError(f"{input_folder} não encontrado")
try:
os.makedirs(output_folder, exist_ok=True)
except Exception as e:
logger.error(f"erro de criação do diretório de saída: {e}")
raise
for root, _, files in os.walk(input_folder):
for file_name in files:
if file_name.endswith(".md"):
try:
md_path = os.path.join(root, file_name)
output_path = os.path.join(
output_folder, file_name.replace(".md", ".json")
)
parsed_data = parse_markdown(md_path)
with open(output_path, "w", encoding="utf-8") as file:
json.dump(parsed_data, file, ensure_ascii=False, indent=4)
logger.info(f"Resultar em poupança{output_path}")
except Exception as e:
logger.error(f"Erro de processamento de ficheiros {file_name}: {e}")A função recebe como entrada a pasta na qual se encontram todos os documentos e a pasta na qual serão gravados os ficheiros JSON recebidos.
A lógica de deteção de ficheiros md funciona de forma a pesquisar em todas as pastas aninhadas por diretórios com documentos. Isto é especialmente útil se a sua documentação tiver uma estrutura complexa de ficheiros e diretórios.
Agora chamamos:
if __name__ == "__main__":
try:
process_all_markdown(
input_folder="caminho para a pasta com documentos",
output_folder="caminho para a pasta para guardar JSON",
)
except Exception as e:
logger.error(f"Erro crítico: {e}")
sys.exit(1)Vamos lançar.
Recebeu 63 documentos (um exemplo de todos os ficheiros está no código fonte do projeto)
Os ficheiros estão prontos! Agora só precisamos de ler todos os ficheiros e criar uma base de dados vetorial baseada neles.
Note que o nosso analisador extrai não só o texto do Markdown, mas também a estrutura do documento. Nos metadados, guardamos o nome do ficheiro e os títulos de todas as secções. Isto permite-nos não só pesquisar por conteúdo, mas também indicar com precisão de que secção da documentação foi retirado um fragmento específico, o que é muito útil para criar respostas significativas do assistente.
Criar uma base de dados
O processo de criação de uma base de dados para o Amverum não é muito diferente da abordagem anteriormente descrita, com a diferença de que iremos obter dados de ficheiros JSON existentes.
Antes de continuar, para um código mais estruturado, vamos criar um ficheiro . env na raiz do projeto e colocar nele as seguintes variáveis:
DEEPSEEK_API_KEY=sk-1234
OPENAI_API_KEY=sk-proj-1234Ambas as chaves API devem estar aqui. Se não existirem chaves, não precisa de criar o ficheiro.
De seguida, crie o ficheiro config.py e preencha-o da seguinte forma:
import os
from pydantic import SecretStr
from pydantic_settings import BaseSettings, SettingsConfigDict
class Config(BaseSettings):
DEEPSEEK_API_KEY: SecretStr
BASE_DIR: str = os.path.abspath(os.path.join(os.path.dirname(__file__)))
DOCS_AMVERA_PATH: str = os.path.join(BASE_DIR, "amverum_data", "docs_amvera")
PARSED_JSON_PATH: str = os.path.join(BASE_DIR, "amverum_data", "parsed_json")
AMVERA_CHROMA_PATH: str = os.path.join(BASE_DIR, "amverum_data", "chroma_db")
AMVERA_COLLECTION_NAME: str = "amvera_docs"
MAX_CHUNK_SIZE: int = 512
CHUNK_OVERLAP: int = 50
LM_MODEL_NAME: str = "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
DEEPSEEK_MODEL_NAME: str = "deepseek-chat"
OPENAI_MODEL_NAME: str = "gpt-3.5-turbo"
OPENAI_API_KEY: SecretStr
model_config = SettingsConfigDict(env_file=f"{BASE_DIR}/.env")
settings = Config() # type: ignoreNesta aula recolhemos todas as variáveis necessárias para o funcionamento do projeto. Como pode ver, os caminhos para as pastas importantes são aqui indicados (a sua estrutura pode ser diferente), os nomes das coleções, o tamanho máximo dos blocos e os nomes dos modelos de redes neuronais.
Preste especial atenção à declaração das chaves API:
OPENAI_API_KEY: SecretStr
DEEPSEEK_API_KEY: SecretStrÉ importante descrevê-las não como strings normais, mas via SecretStr. Este é um requisito da biblioteca LangChain para o manuseamento seguro de dados confidenciais.
Agora podemos importar a variável de definições para qualquer lugar no código e aceder às definições necessárias através de um ponto.
Criação de uma base de dados
Vamos voltar à criação de uma base de dados. Comecemos pelas importações:
import json
import os
import sys
from typing import Any, Dict, List, Optional
import torch
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from loguru import logger
from config import settingsAqui, entre outras coisas, vê a importação de RecursiveCharacterTextSplitter. Este componente permitir-nos-á dividir documentos de grandes dimensões em blocos semânticos (fragmentos de texto relacionados entre si por significado).
Vamos escrever uma função para carregar todos os ficheiros JSON existentes no formato de lista de dicionário:
def load_json_files(directory: str) -> List[Dict[str, Any]]:
"""Download JSON"""
documents = []
try:
if not os.path.exists(directory):
logger.error(f"O diretório {directory} não existe")
return documents
for filename in os.listdir(directory):
if filename.endswith(".json"):
file_path = os.path.join(directory, filename)
try:
with open(file_path, "r", encoding="utf-8") as file:
data = json.load(file)
documents.append(
{"text": data["text"], "metadata": data["metadata"]}
)
logger.info(f"Ficheiro carregado: {filename}")
except Exception as e:
logger.error(f"Erro ao ler o ficheiro {nome do ficheiro}: {e}")
logger.success(f"Ficheiros JSON {len(documents)} carregados")
return documents
except Exception as e:
logger.error(f"Erro ao carregar ficheiros JSON: {e}")
return documentsApós a execução desta função, receberemos todos os dados dos ficheiros JSON como dicionários colocados na RAM. As informações destes dicionários podem ser utilizadas para criar um banco de dados vetorial.
Vamos agora descrever a lógica para dividir documentos grandes em fragmentos significativos:
def split_text_into_chunks(text: str, metadata: Dict[str, Any]) -> List[Any]:
"""Dividir o texto em pedaços, preservando os metadados."""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=settings.MAX_CHUNK_SIZE,
chunk_overlap=settings.CHUNK_OVERLAP,
length_function=len,
is_separator_regex=False,
)
chunks = text_splitter.create_documents(texts=[text], metadatas=[metadata])
return chunksComo resultado desta função, temos ainda uma lista de dicionários, mas agora os textos grandes estão divididos em fragmentos semânticos. Ao mesmo tempo, cada um dos fragmentos contém os metadados necessários. Isto é importante para manter o contexto geral, mesmo quando se divide um texto grande em muitas partes.
Por fim, descreveremos a lógica para a criação de uma base de dados vetorial:
def generate_chroma_db() -> Optional[Chroma]:
"""Inicialização do ChromaDB com dados de ficheiros JSON."""
try:
# Crie um diretório para armazenar a base de dados se não existir
os.makedirs(settings.AMVERA_CHROMA_PATH, exist_ok=True)
# Carregando ficheiros JSON
documents = load_json_files(settings.PARSED_JSON_PATH)
if not documents:
logger.warning("Não há documentos para adicionar à base de dados.")
return None
# Inicializar o modelo de incorporação
embeddings = HuggingFaceEmbeddings(
model_name=settings.LM_MODEL_NAME,
model_kwargs={"device": "cuda" if torch.cuda.is_available() else "cpu"},
encode_kwargs={"normalize_embeddings": True},
)
# Preparação de dados para o Chroma
all_chunks = []
for i, doc in enumerate(documents):
chunks = split_text_into_chunks(doc["text"], doc["metadata"])
all_chunks.extend(chunks)
logger.info(
f"Document {i+1}/{len(documents)} is divided into {len(chunks)} chunks"
)
# Criar um armazenamento vetorial
texts = [chunk.page_content for chunk in all_chunks]
metadatas = [chunk.metadata for chunk in all_chunks]
ids = [f"doc_{i}" for i in range(len(all_chunks))]
chroma_db = Chroma.from_texts(
texts=texts,
embedding=embeddings,
ids=ids,
metadatas=metadatas,
persist_directory=settings.AMVERA_CHROMA_PATH,
collection_name=settings.AMVERA_COLLECTION_NAME,
collection_metadata={
"hnsw:space": "cosine",
},
)
logger.success(
f"Baza Chroma inicializado, adicionado {len(all_chunks)} pedaços de {len(documents)} documentos"
)
return chroma_db
except Exception as e:
logger.error(f"Erro de arranque Chroma: {e}")
raiseA lógica de criação de uma base de dados não é muito diferente dos exemplos que vimos anteriormente. A principal diferença é dividir os textos grandes em fragmentos significativos (pedaços).
No meu modesto computador, o processo de criação de uma base de dados demorou menos de 10 minutos. Em dispositivos com GPU, este processo demorará apenas alguns minutos graças à computação paralela.
Otimização de desempenho
De notar que ao trabalhar com grandes volumes de dados, pode otimizar ainda mais o processo:
- Utilize lotes ao criar embeddings (processamento de documentos em grupos)
- Configure os parâmetros MAX_CHUNK_SIZE e CHUNK_OVERLAP consoante a estrutura dos seus dados
- Escolha um modelo de incorporação adequado, equilibrando a qualidade e a velocidade
O ChromaDB tem um bom desempenho para a maioria das tarefas RAG, mas para volumes de dados muito grandes (milhões de documentos), vale a pena considerar outras soluções, como o FAISS ou o Pinecone.
Integração de um motor de busca com redes neuronais
Anteriormente, vimos como descrever um motor de busca sem utilizar grandes redes neuronais. Para consolidar este material, sugiro que crie você mesmo um motor de busca com base na sua base de dados.
Passarei à parte mais interessante: explicarei como combinar a saída de uma base de dados vetorial com redes neuronais para criar um agente de IA inteligente. Para tal, vamos utilizar dados da documentação do Amverum Cloud, que já transformei numa base de dados vetorial.
Configuração inicial do projeto
Vamos começar por criar um ficheiro chamado chat_with_ai.py.
Vamos fazer as importações necessárias:
from typing import Any, Dict, List, Literal, Optional
import torch
from config import settings
from langchain_chroma import Chroma
from langchain_deepseek import ChatDeepSeek
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from loguru import loggerAqui incluímos as novas ferramentas langchain_deepseek e langchain_openai, que nos permitirão integrar facilmente os modelos DeepSeek e ChatGPT (bem como outros modelos OpenAI) no nosso projeto.
Estrutura da classe principal
Para um código mais estruturado, decidi formatá-lo como uma classe. Vamos declarar a nossa classe e descrever a lógica de inicialização:
class ChatWithAI:
def __init__(self, provider: Literal["deepseek", "openai"] = "deepseek"):
self.provider = provider
self.embeddings = HuggingFaceEmbeddings(
model_name=settings.LM_MODEL_NAME,
model_kwargs={"device": "cuda" if torch.cuda.is_available() else "cpu"},
encode_kwargs={"normalize_embeddings": True},
)
if provider == "deepseek":
self.llm = ChatDeepSeek(
api_key=settings.DEEPSEEK_API_KEY,
model=settings.DEEPSEEK_MODEL_NAME,
temperature=0.7,
)
elif provider == "openai":
self.llm = ChatOpenAI(
api_key=settings.OPENAI_API_KEY,
model=settings.OPENAI_MODEL_NAME,
temperature=0.7,
)
else:
raise ValueError(f"Unsupported provider: {provider}")
self.chroma_db = Chroma(
persist_directory=settings.AMVERA_CHROMA_PATH,
embedding_function=self.embeddings,
collection_name=settings.AMVERA_COLLECTION_NAME,
)Ao criar um objeto de classe, passamos o parâmetro provider com o valor “deepseek” ou “openai” para indicar a rede neural com que iremos trabalhar no projeto.
Observe a construção:
ChatDeepSeek(
api_key=settings.DEEPSEEK_API_KEY,
model=settings.DEEPSEEK_MODEL_NAME,
temperature=0.7,
)Desta forma simples, podemos declarar a rede neural com a qual iremos interagir. Aqui, basta passar o token da API e o nome do modelo (estes são parâmetros obrigatórios). Também pode passar parâmetros adicionais para um ajuste mais fino, por exemplo, a temperatura para controlar a criatividade das respostas.
Obtenção do contexto relevante
Vamos descrever o método para obter uma resposta da base de dados:
def get_relevant_context(self, query: str, k: int = 3) -> List[Dict[str, Any]]:
"""Obtenção de contexto relevante do banco de dados."""
try:
results = self.chroma_db.similarity_search(query, k=k)
return [
{
"text": doc.page_content,
"metadata": doc.metadata,
}
for doc in results
]
except Exception as e:
logger.error(f"Erro ao obter contexto: {e}")
return []O método recebe como entrada o pedido do utilizador e o número de documentos que esperamos receber (por defeito, 3 documentos).
Para a pesquisa, utilizei o método similarity_search. Deixe-me lembrar-lhe que a essência deste método é que transformamos o pedido de pesquisa numa representação vetorial e, com base nesse vetor, pesquisamos na nossa base de dados.
Formatação do contexto
Vamos agora descrever o método que transformará o resultado obtido num formato conveniente para redes neuronais:
def format_context(self, context: List[Dict[str, Any]]) -> str:
"""Formatação do contexto para um prompt."""
formatted_context = []
for item in context:
metadata_str = "\n".join(f"{k}: {v}" for k, v in item["metadata"].items())
formatted_context.append(
f"Texto: {item['text']}\nMetadata:\n{metadata_str}\n"
)
return "\n---\n".join(formatted_context)This method transforms the document + metadata bundle from all received documents into one structured message, which we then pass to the neural network.
Generating a response
Now we will describe the method that will link our context with the request to the neural network:
def generate_response(self, query: str) -> Optional[str]:
"""Gere uma resposta com base num pedido e contexto."""
try:
context = self.get_relevant_context(query)
if not context:
return "Gere uma resposta com base num pedido e contexto."
formatted_context = self.format_context(context)
messages = [
{
"role": "system",
"content": """Você é o gestor interno da empresa. Amverum Cloud (https://amverum.com/). Responde direto ao ponto, sem introduções desnecessárias.
Regras:
1.º Vá direto ao assunto, sem frases como "Com base no contexto"
2.º Use apenas factos. Se não existirem dados exatos, responda com frases gerais sobre a Nuvem Amverum, mas não dê detalhes específicos.
3.º Utilize texto simples sem formatação
4. Inclua os links apenas se estiverem em contexto
5.º Fale na primeira pessoa do plural: “Nós fornecemos”, “Nós temos”.
6.º Ao mencionar ficheiros, faça-o naturalmente, por exemplo: "Anexarei instruções onde os passos são descritos detalhadamente".
7.º Responda às saudações com gentileza e à negatividade com um pouco de humor.
8.Ao responder, pode utilizar informações gerais de fontes abertas sobre o Amverum Cloud, mas confie no contexto
9.Se o utilizador perguntar sobre preços, planos ou especificações técnicas - dê respostas específicas do contexto
10.º Para questões técnicas, ofereça soluções práticas
Personalize as respostas mencionando o nome do cliente, se estiver no contexto. Seja breve, informativo e útil.""",
},
{
"role": "user",
"content": f"Question: {query}\nContext: {formatted_context}",
},
]
response = self.llm.invoke(messages)
if hasattr(response, "content"):
return str(response.content)
return str(response).strip()
except Exception as e:
logger.error(f"Erro ao gerar resposta:{e}")
return "Ocorreu um erro ao gerar a resposta."Note-se que é aqui utilizado um prompt de texto, que atua como um invólucro sobre o nosso contexto. O próprio prompt (query) pode ser qualquer coisa, e eu dei apenas um dos exemplos possíveis.
Vale a pena experimentar o conteúdo do prompt dependendo dos requisitos específicos do seu projeto. As instruções podem ser mais ou menos directivas, podem orientar o modelo para diferentes estilos de resposta ou diferentes formatos de apresentação de informação.
O método aceita uma consulta de pesquisa do utilizador como entrada. Esta consulta é primeiramente processada por uma base de dados vetorial e, com base nela, obtemos o texto estruturado dos documentos relevantes. De seguida, este texto é combinado com o prompt que preparámos e, chamando self.llm.invoke(messages), obtemos uma resposta da rede neural.
De seguida, transformamos a resposta e devolvemos ao utilizador.
Lançamento e testes
Agora só falta inicializar correctamente a classe e chamar os seus métodos:
if __name__ == "__main__":
chat = ChatWithAI(provider="deepseek")
print("\n=== Bate-papo com IA===\n")
while True:
query = input("Tu:")
if query.lower() == "output":
print("\nVeja o seu atraso!")
break
print("\nEstá a imprimir...", end="\r")
response = chat.generate_response(query)
print(" " * 20, end="\r") # Limpando "Impressões de IA"..."
print(f"AI: {response}\n")Note que estamos aqui a executar um loop que só sairá se o utilizador digitar “exit”. Isto demonstra como podemos manter uma ligação com a base de dados de vetores do Chroma sem ter de voltar a ligar a cada pedido.
Ligamo-nos à base de dados uma vez e só nos desconectamos quando o nosso loop infinito estiver completo. Esta abordagem poupa o tempo de inicialização da ligação para cada pedido do utilizador.
Conclusão
Nesta fase, temos apenas um protótipo de um motor de busca para documentação do Amverum Cloud — é difícil chamar-lhe um serviço completo com um assistente de IA.
Se este material encontrar uma resposta em si sob a forma de visualizações, gostos e comentários, no próximo artigo direi em detalhe quais os blocos do código atual que podem ser melhorados. Com base na versão modificada, criaremos um serviço web pronto a usar, semelhante ao site chat.openai.com, onde implementaremos um chat completo e prático com o nosso assistente de IA.
Espero ter conseguido transmitir-vos como funcionam as bases de dados vetoriais, como recolher e estruturar informação para as mesmas e como organizar a geração e a pesquisa nestas bases de dados.
Devido aos recursos limitados, não consegui abordar o tema de forma profunda e abrangente. Assim, recomendo vivamente estudar a representação vetorial de dados com mais detalhe. Isto é importante pelo menos porque gigantes como o ChatGPT, Claude, DeepSeek e outras redes neuronais modernas trabalham com a representação vetorial da informação.
Além disso, recomendo que se preste atenção a uma ferramenta tão poderosa como o LangChain. O que discutimos neste artigo é apenas uma pequena parte das suas capacidades.
Isso é tudo. Vemo-nos no próximo artigo!
Alex Yacovenko
O Amverum Cloud é uma alternativa mais barata e fácil de implementar ao Heroku com domínios gratuitos, armazenamento persistente incluído e a possibilidade de atualizar projetos através de “git push amverum master”.
