
I don't know about you, but each time I await something in Python, I get a tiny itch in the back of my brain.
Not because I don’t know what it does or how to use it, that part’s fine. I write my async defs, slap some await in there, and it just works™️. No, what's bothering me is: why does it work?
If we’re not blocking the main process... who’s doing the actual work I’m awaiting? And more importantly, how does the result get back into my Python function?
Take a typical FastAPI route. Maybe we’re calling an external API:
import httpx
from fastapi import APIRouter
router = APIRouter()
@router.get("/user/{id}")
async def get_user(id: str):
async with httpx.AsyncClient() as client:
response = await client.get(f"https://api.example.com/users/{id}")
return response.json()The request comes in, the interpreter hits await client.get(...), and somehow... the server keeps handling other requests while the HTTP call is doing its thing.
Doing its thing where, exactly?
And once it's done, who taps the interpreter on the shoulder to say: "Hey, here’s your response. You can resume now." ?
It all feels a bit too magical, and I hate magic. That's why I always end up playing a sneaky archer in Skyrim.
This post is about removing the magic and understanding how it all works under the hood. We'll build our own version of asyncio step by step , from a simple generator all the way to running a fully working echo server using only our custom event loop.
Here is what the end result will look like :
from socket import SO_REUSEADDR, SOL_SOCKET, socket
from scheduler.future import AcceptSocket, ReadSocket, Sleep
from scheduler.scheduler import Scheduler
async def read(conn):
return await ReadSocket(conn)
async def accept(sock):
return await AcceptSocket(sock)
async def echo(sock):
while True:
data = await read(sock)
if not data:
sock.close()
print(f"received {data}")
# assume non-blocking
sock.send(data)
async def echo_server(scheduler: Scheduler, port: int):
print("creating socket...")
sock = socket()
sock.bind(("localhost", port))
sock.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
sock.listen(100)
sock.setblocking(False)
print("socket created waiting for connection")
while True:
conn = await accept(sock)
# Schedule new concurrent connection
scheduler.create_task(echo(conn))
if __name__ == "__main__":
scheduler = Scheduler()
scheduler.create_task(echo_server(scheduler, 1235))
scheduler.run_forever()To do that, we’ll need three things:
A way to pause a function and resume where we left off.
A way to switch between those paused/resumable functions.
A way to start the work somewhere else, and get notified when it’s done.
Sound familiar? That first point should ring a bell: generators! Generators let us pause in the middle of a function and resume it later. And fun fact: that’s very close to how asyncio actually works under the hood.
(Want to skip ahead? Check out the full repo here with all the code we'll write in this post.)
Primer on Generators and Coroutines
First a small primer on generators, and their twin coroutines.
In python, generators are created (among other ways) using yield. A yield statement pauses the callee and returns something to the caller. This allows to do cool stuff like maintaining state across multiple function executions.
Here's an example generator that when iterated over return the Fibonacci sequence:
from time import sleep
def fibonnaci_generator():
n_1 = 0
n_2 = 1
while True:
n = n_1 + n_2
yield n
n_2 = n_1
n_1 = n
if __name__ == "__main__":
generator = fibonnaci_generator()
for x in generator:
print(x)
sleep(1)
Calling fibonacci_generator() gives us a generator object. Iterating over it calls yield repeatedly, pausing and resuming the function between each number.
But yield has a hidden superpower: it doesn’t just let a generator produce values, it also allows it to receive values using my_generator.send(value). This turns the generator into a data consumer, not just a producer.
A generator that can receive data like this is often referred to as a coroutine. Why coroutine? Because unlike regular subroutines (which run top-to-bottom and return once) they can pause, yield control, and be resumed later with external data, possibly by some external scheduler. That makes them perfect for cooperative multitasking, where functions can run concurrently by explicitly handing control back and forth, and sending values to each other, rather than stacking up on the call stack like traditional functions.
⚠️ Quick note on terminology:
In this post, I’m using the term coroutine in its broader, general sense. In Python, this includes generator functions that use
yieldand.send()to cooperate with a scheduler.These generator-based coroutines were the first way to write asynchronous code in Python. Since version 3.5, Python introduced native coroutines using the
async defandawaitkeywords. Native coroutines are more ergonomic, but conceptually, they do the same thing: pause, wait for something, then resume.We’ll explore those native coroutines, and how our library supports them, later in the post.
send will come in handy when we want to send the result of an asynchronous operation back into the paused coroutine.
Let’s see this in action. We’ll write a coroutine that filters even numbers from the Fibonacci sequence (yes, it’s very useful):
from time import sleep
def fibonnaci_generator():
n_1 = 0
n_2 = 1
while True:
n = n_1 + n_2
yield n
sleep(1)
n_2 = n_1
n_1 = n
def filter_even():
while True:
x = yield
if x > 200:
return x
if x % 2 == 0:
print(x)
if __name__ == "__main__":
filter = filter_even()
generator = fibonnaci_generator()
filter.send(None)
for x in generator:
filter.send(x)
Notice how filter_even consumes values generated by fibonnaci_generator ? That's the difference between generator and coroutines. Of course, a generator can do both, but that gets messy quickly, and I won’t get into why here. (You can find a good explanation p.16 of A Curious Course on Coroutines and Concurrency)
That's enough theory on coroutines for now. But look, we've already completed step 1: we now have a way to pause and resume execution. Next up: running coroutines concurrently with a scheduler.
Building a Scheduler
We'll build a Scheduler that well be responsible for, that's right, scheduling our coroutines. First, let's write a Task wrapper to encapsulate all the coroutine stuff:
from typing import Generator
import uuid
class Task:
def __init__(self, coro: Generator):
self.id = uuid.uuid4()
self._coro = coro
self.val = None
def run(self):
self._coro.send(self.val)the val attribute represents the next value we want to send to the coroutine. We’ll use it to give back some result to the wrapped coroutine later on. After initialization, it’s None. Sending None to a coroutine is equivalent to calling next on it, and will advance to the next yield statement.
Next, we write a simple scheduler to manage the tasks queue:
from collections import deque
from typing import Generator
from scheduler.task import Task
class Scheduler:
def __init__(self):
self._queue = deque([])
def create_task(self, coro: Generator):
task = Task(coro)
self._queue.append(task)
def run_forever(self):
while self._queue:
task = self._queue.pop()
try:
task.run()
self._queue.appendleft(task)
except StopIteration as err:
print(err.value)This is as simple while loop that take the next task in the queue and run it once. Then either:
We reschedule the task at the back of the queue
StopIteration is raised, meaning the coroutine is over, and the task isn't rescheduled
💡
StopIterationis raised when a generator (or generator-style coroutine) finishes execution.
This happens either:
When it reaches the end of the function, or
When it hits a
returnstatement (in which case thereturnvalue is stored in the exception’s.valueattribute)
Let's see this in action. We'll build two simple coroutines, ping and pong, that print their own name and yield. We can use your brand new Scheduler to run them.
import time
from scheduler.scheduler import Scheduler
def ping():
while True:
print("ping")
time.sleep(1)
(yield)
def pong():
while True:
print("pong")
time.sleep(1)
(yield)
if __name__ == "__main__":
scheduler = Scheduler()
scheduler.create_task(ping())
scheduler.create_task(pong())
scheduler.run_forever()
Great! As you can see, our scheduler alternates between the ping and pong tasks. That’s step 2 done.
However, for now, we still can’t really “await” anything. If we modify ping to use a blocking sleep(30), it will pause for 30 seconds before the scheduler can switch to pong.
Right now, our scheduler behaves similarly to running both tasks in separate threads, except we are the ones deciding when the switch happens. This model is called cooperative multitasking, but we are still missing our third ingredient: something to delegate the work and be notify when it's done.
This is where the Future class comes into play
Adding a Future
A Future is similar to a Promise in TypeScript. It represents a value that’s not available yet, but will be eventually. That’s exactly what we need: we want our coroutine to yield a Future, and then have our scheduler “pause” it until that future is resolved.
Here’s a base Future class we can work with:
class Future(TaskProtocol, metaclass=ABCMeta):
def __init__(self):
self._done_callbacks = []
self.is_done = False
self._result = None
self._coro = self._run()
def add_done_callback(self, callback: Callable[[Any], None]):
self._done_callbacks.append(callback)
def run(self):
self._coro.send(None)
def _run(self):
while True:
result = self._check_result()
if result:
self._done(result)
return result
yield
def _done(self, result: Any):
self.is_done = True
self._result = result
for callback in self._done_callbacks:
callback(self._result)
@abstractmethod
def _check_result(self) -> Any:
passA few things to notice here:
The Future has a run method, just like our Task. This is because the Future will replace the task in the queue, having a task-like interface allows us to treat it like a normal task.
💡 The
TaskProtocolis define elsewhere, it simply enforces this shared interface betweenFutureandTask
The Future wraps a coroutine in _run, which polls for the result. When it’s ready, we mark the future as done and trigger any callbacks waiting on it.
When a Task yields a Future, that future replaces the task in the queue, and holds a reference to the task. That’s how we “pause” the coroutine. Once the future is complete, it will call its registered callback to reschedule the waiting task with the result, resuming it. In our case, the scheduler will be responsible for setting this callback.
from collections import deque
from typing import Generator
from scheduler.future import Future
from scheduler.task import Task
from scheduler.task_protocol import TaskProtocol
class Scheduler:
def __init__(self):
self._queue = deque([])
def create_task(self, coro: Generator):
task = Task(coro)
self._schedule(task)
def _schedule(self, task: TaskProtocol):
self._queue.appendleft(task)
def _continue(self, task):
def callback(result):
task.val = result
self._schedule(task)
return callback
def run_forever(self):
while self._queue:
task = self._queue.pop()
try:
future = task.run()
if isinstance(future, Future):
future.add_done_callback(self._continue(task))
self._schedule(future)
else:
self._schedule(task)
except StopIteration:
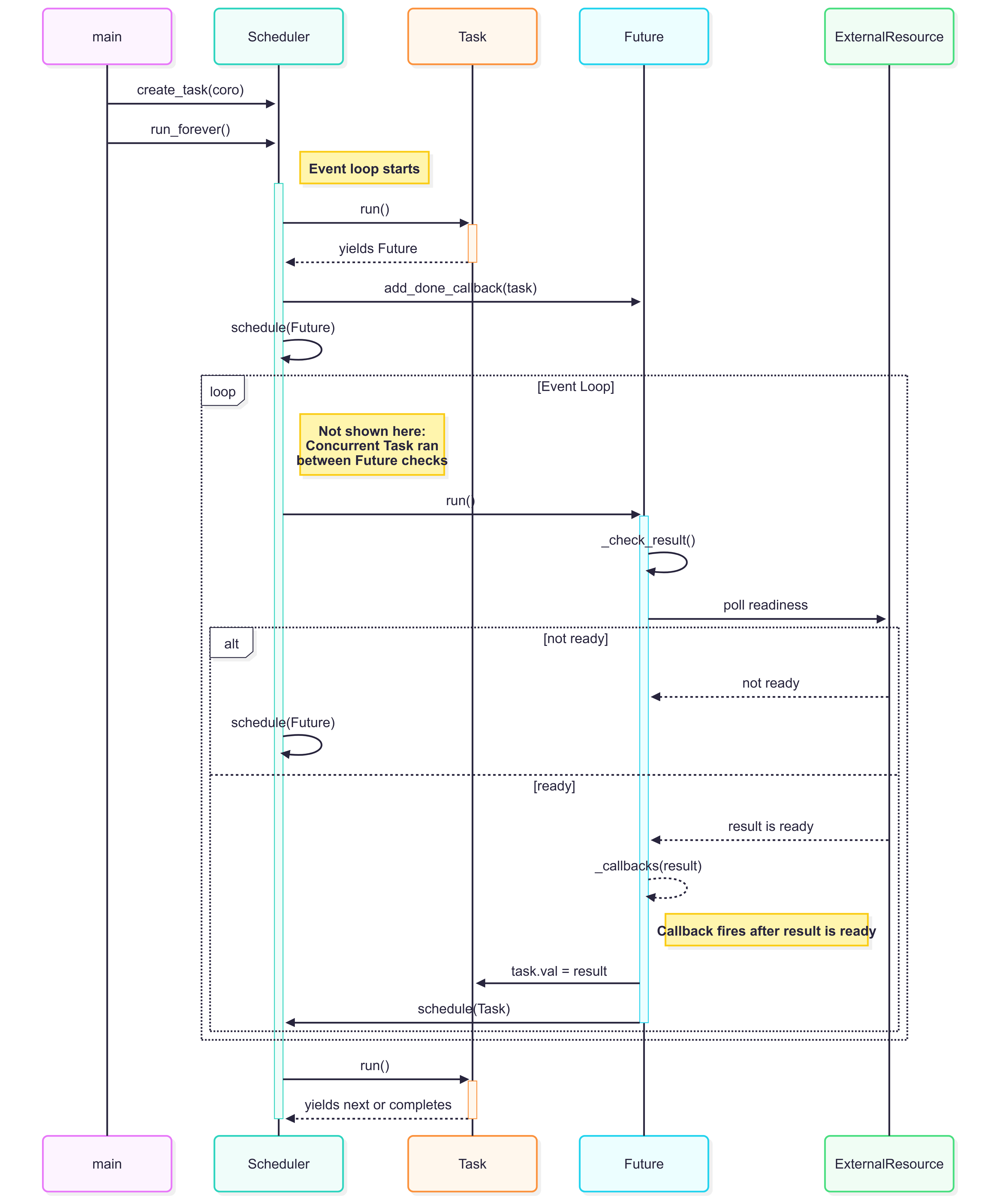
passNow when a task yields a Future, the scheduler sets a callback that:
Assigns the result back to the task (task.val)
Reschedules the task so it can resume execution
This is not very easy to visualize, so here is a sequence diagram showing what happens:
Let’s put this to the test. Here’s an implementation of a non-blocking sleep using this future logic:
class Sleep(Future):
def __init__(self, wait_for: int, *args, **kwargs):
super().__init__(*args, **kwargs)
self._wait_for = timedelta(seconds=wait_for)
self._ready_at = datetime.now(tz=timezone.utc) + self._wait_for
def _check_result(self):
if datetime.now(tz=timezone.utc) >= self._ready_at:
return TrueAnd now let's do some non-blocking awaiting:
import time
from scheduler.future import Sleep
from scheduler.scheduler import Scheduler
def sleep(n: int):
return (yield Sleep(n))
def ping():
print("waiting for result before ping...")
result = yield from sleep(5)
print(f"result: {result}")
while True:
print("ping")
time.sleep(1)
yield from sleep(0)
def pong():
while True:
print("pong")
time.sleep(1)
yield from sleep(0)
if __name__ == "__main__":
scheduler = Scheduler()
scheduler.create_task(ping())
scheduler.create_task(pong())
scheduler.run_forever()
We did it! ping pauses for 5 seconds, and during that time, pong can continue doing its thing. Just like with the real asyncio.sleep.
Also, note the use of yield from when nesting coroutines.If we had just done yield Sleep(n), we’d yield a generator instead of the result we wanted. If this seems too magical, check out the branch step/nested-coroutines in the linked repo. In that branch, I use stack in the Task class to handle nested co-routine manually.
Now we could stop here for our scheduler and skip to doing some I/O. But the real asyncio lib works with the async/await keywords. Wouldn’t it be nice if we could do that as well ?
Adhering to async/await
The keywords async and await don't introduce new features to Python's execution model. They simply organize and improve what we've been doing with yield from and generators.
There's no magic involved. await works like yield from, and async alters our function type from Generator to Coroutine. This helps keep asynchronous generators/coroutines separate from regular generators.
To convert our generator-based coroutines into true coroutines, we just need to add async before them. Then we can use await with them (which is a drop-in replacement for yield from).
To integrate our custom Future with Python's await system, we need to make it awaitable. This means implementing the __await__ method, which Python uses under the hood when you write await my_future.
class Future(TaskProtocol, metaclass=ABCMeta):
def __init__(self):
self._done_callbacks = []
self.is_done = False
self._result = None
self._coro = self._run()
def __await__(self):
return (yield self)
# ... rest of the classAnd that's it, now we can change sleep like so
async def sleep(n: int):
return await Sleep(n)which is functionally the same as calling Sleep(n).__await__().
Let me say that again because it is important: async and await do no magic whatsoever. They are just part of a protocol, much like the Iterator protocol. Their purpose is to keep us from mixing up regular generators with coroutines that are meant to be managed by a scheduler or an event loop.
And now that our futures are awaitable, we can use async and await everywhere. In fact, we must use them, because once a function is declared with async def, the interpreter expects await inside, not yield.
from scheduler.future import Sleep
import time
from scheduler.scheduler import Scheduler
async def sleep(n: int):
return await Sleep(n)
async def ping():
print("waiting for result before ping...")
result = await sleep(5)
print(f"result: {result}")
while True:
print("ping")
time.sleep(1)
# yield control to the event loop. We cannot use (yield in a "true" coroutine)
await sleep(0)
async def pong():
while True:
time.sleep(1)
await sleep(0)
print("pong")
if __name__ == "__main__":
scheduler = Scheduler()
scheduler.create_task(ping())
scheduler.create_task(pong())
scheduler.run_forever()You can still use
yieldinside an async function in the context of Asynchronous Generators. But this is outside the scope of this post.
Look at that ! Pretty much exactly what this would look like using the regular asyncio, except it comes from our own library. Pretty neat, uh ?
Adding Real I/O to Our Async Framework
So far so good, but we still haven't handled any real I/O. What we have, though, is a framework that lets us build custom Future subclasses. Each of them can poll for a result and resume a task once that result is available.
At the beginning of the post, in the final code example, you may have noticed these two lines:
async def read(conn):
return await ReadSocket(conn)
async def accept(sock):
return await AcceptSocket(sock)Well guess what? Both ReadSocket and AcceptSocket are subclasses of our Future class.
AcceptSocket allows us to suspend execution while waiting for new incoming connections on a socket. ReadSocket does the same for receiving data from a connection. Now that all the async plumbing is in place, their implementation is surprisingly simple:
import selectors
from socket import socket
class AcceptSocket(Future):
def __init__(self, sock: socket, *args, **kwargs):
super().__init__(*args, **kwargs)
self._select = selectors.DefaultSelector()
self._sock = sock
self._select.register(sock, selectors.EVENT_READ)
def _check_result(self):
events = self._select.select(0)
if events:
conn, addr = self._sock.accept()
print("accepted", conn, "from", addr)
conn.setblocking(False)
return conn
class ReadSocket(Future):
def __init__(self, sock: socket, *args, **kwargs):
super().__init__(*args, **kwargs)
self._select = selectors.DefaultSelector()
self._sock = sock
self._select.register(sock, selectors.EVENT_READ)
def _check_result(self):
events = self._select.select(0)
if events:
return self._sock.recv(1000)I won't go into the details of how sockets work in Python. If you need a refresher (I did!), the socket module docs are a great place to start.
The key thing here is the selectors module. It lets us monitor socket readiness without blocking the main thread. And that, finally, answers the question I posed at the beginning of this article:
"Who's doing the work while we await?"
The answer is simple. The operating system is. When we call register(), we ask the OS to monitor the socket for readiness. Each time we call select(0), we check for any ready events without blocking. This makes implementing the _check_result overrides a piece of cake. We simply check if something is ready in the socket, and if so we return it. If not, we’ll check again during the next loop iteration. Our scheduler handles resuming the appropriate task.
Now that everything is in place, we can finally build a working echo server:
from socket import SO_REUSEADDR, SOL_SOCKET, socket
from scheduler.future import AcceptSocket, ReadSocket, Sleep
from scheduler.scheduler import Scheduler
async def sleep(n: int):
return await Sleep(n)
async def read(conn):
return await ReadSocket(conn)
async def accept(sock):
return await AcceptSocket(sock)
async def echo(sock):
while True:
data = await read(sock)
if not data:
sock.close()
print(f"received {data}")
# assume non-blocking
sock.send(data)
async def echo_server(scheduler: Scheduler, port: int):
print("creating socket...")
sock = socket()
sock.bind(("localhost", port))
sock.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
sock.listen(100)
sock.setblocking(False)
print("socket created waiting for connection")
while True:
conn = await accept(sock)
# Schedule new concurrent connection
scheduler.create_task(echo(conn))
if __name__ == "__main__":
scheduler = Scheduler()
scheduler.create_task(echo_server(scheduler, 1235))
scheduler.run_forever()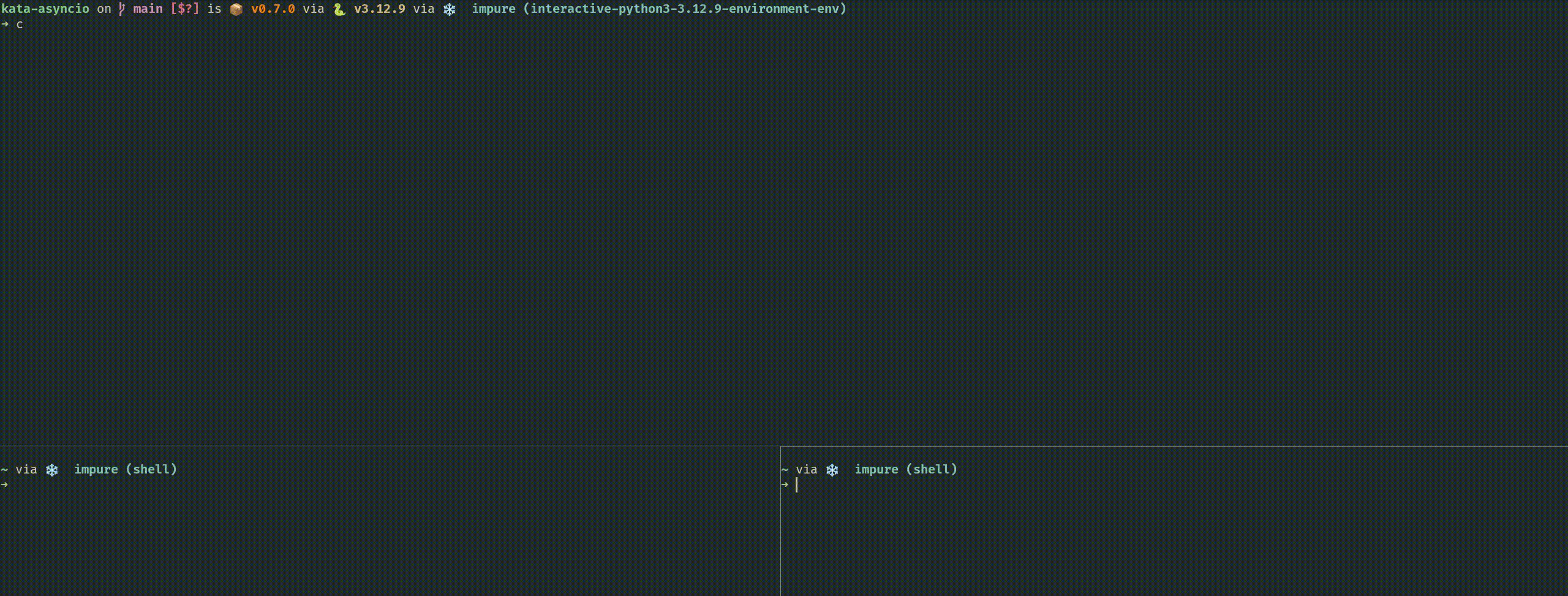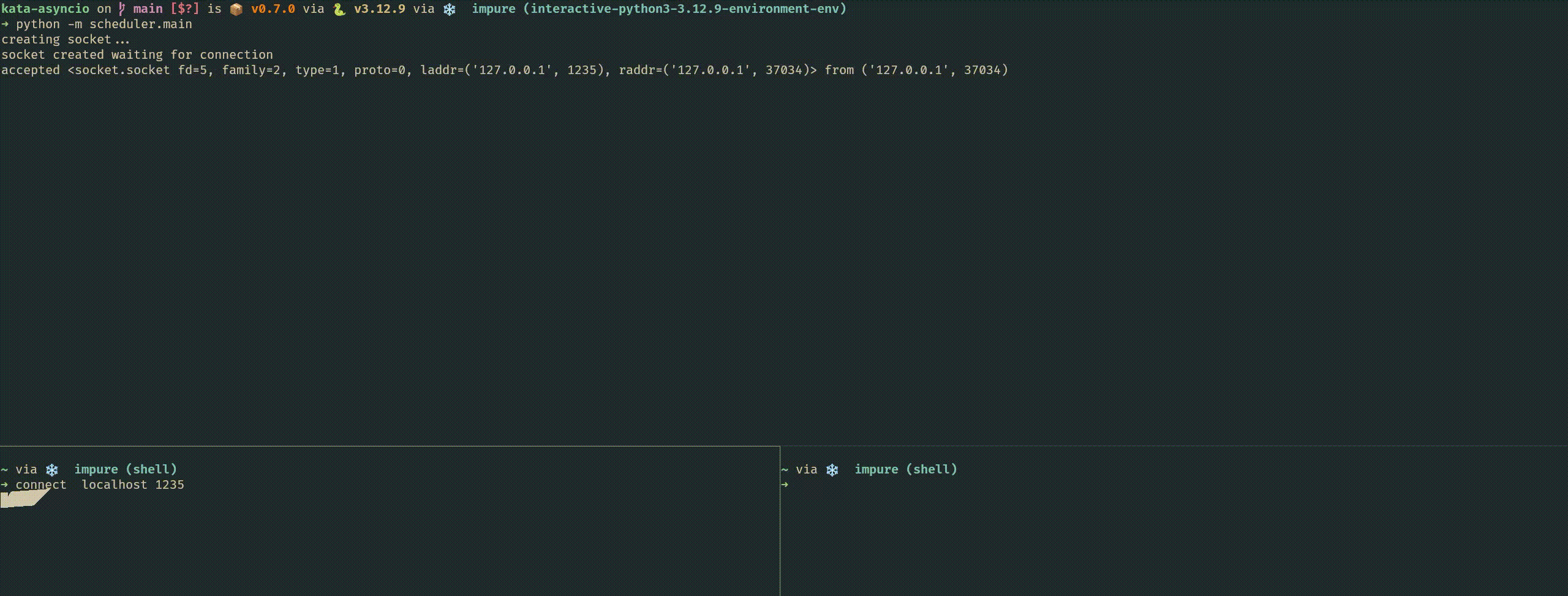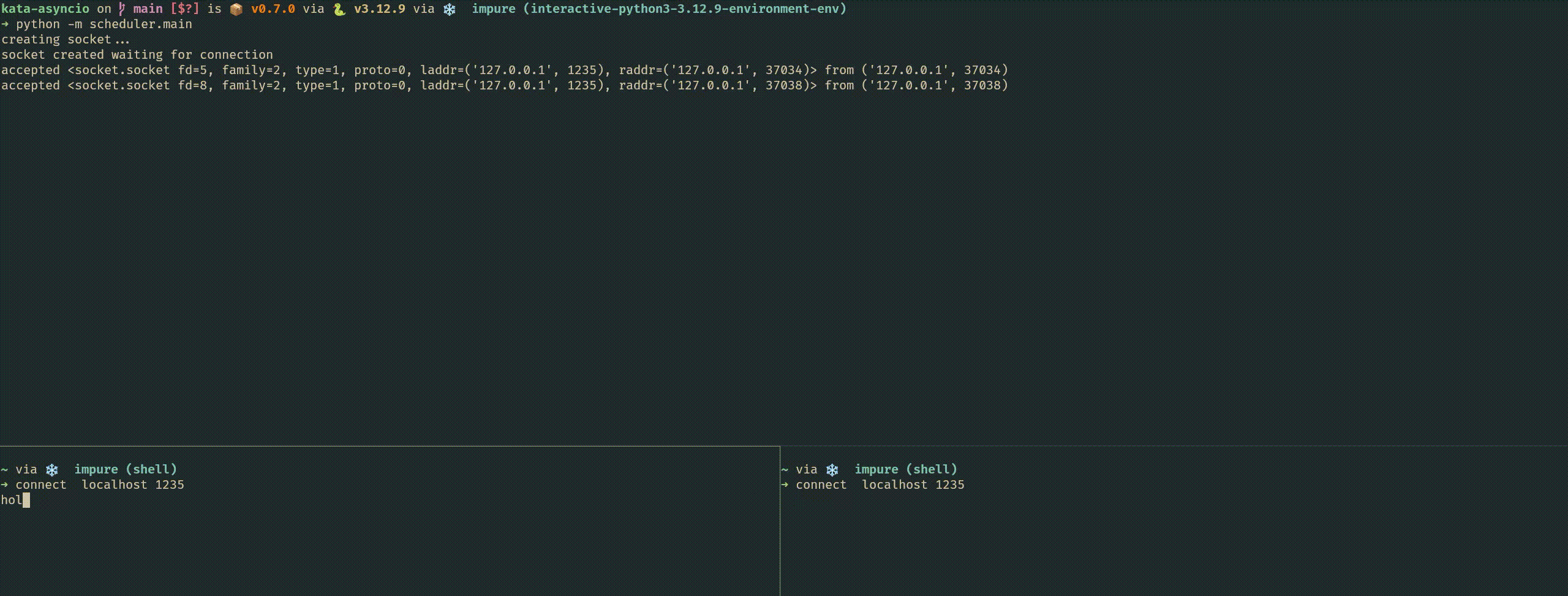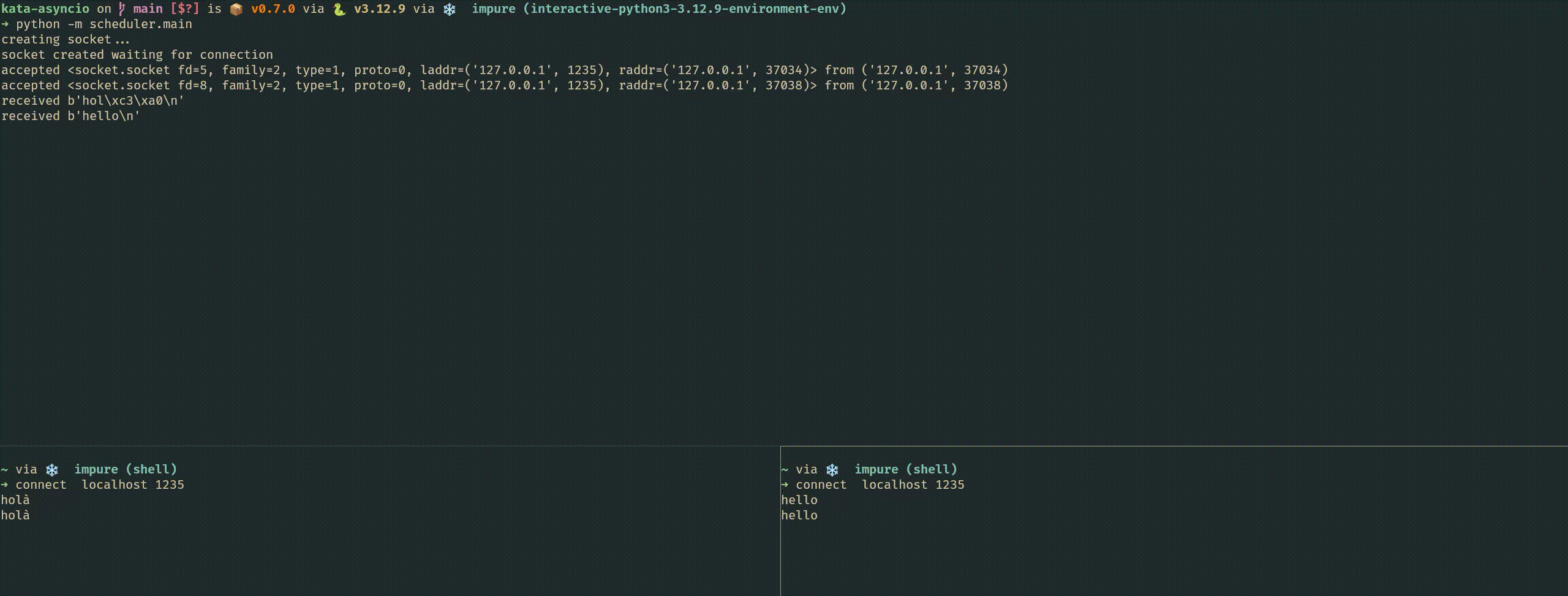
The echo coroutine handles a single client connection. The echo_server coroutine waits for new clients and launches a new concurrent instance of echo for each one. You can run the script and connect multiple clients to port 1235 to see it in action. The echo_server is avaible in the scheduler package of the repository
🎉 Conclusion
If you've made it this far, congratulations! Our implementation is pretty close to the real thing, and asyncio should feel way less mysterious.
Of course, it gets more complex when you want to support timeouts, cancellation, priorities, etc., but the foundation remains the same. If you want to dig deeper, check out the asyncio source in the CPtyon repository, it should look pretty familiar now.
Turns out, the real magic isn’t the await. It's the yield we wrote along the way.
