Ever felt like you're drowning in data? You're not alone. In today's digital world, applications generate and consume information at an unprecedented rate. Choosing how and where to store that data in the cloud is one of the most fundamental – and often confusing – decisions architects and developers face. Pick the wrong type, and you could end up with slow performance, skyrocketing costs, or an architecture that just doesn't scale.
You look at the AWS console, and the options seem endless: S3, EBS, EFS, FSx... what's the difference, and when should you use each? It feels a bit like walking into a massive hardware store looking for a screw – you know you need something to hold things together, but the sheer variety of options is overwhelming.
(Intro/Hook: Relatable problem - data deluge and AWS option paralysis)
Why Getting Storage Right Matters More Than Ever
Choosing the right storage isn't just a technical detail; it's foundational to your application's success. Your storage choice directly impacts:
- Performance: How quickly can your application read and write data? Milliseconds matter for user experience and backend processes.
- Scalability: Can your storage grow seamlessly as your data volume or user load increases?
- Cost: Storage is a significant part of cloud spend. Optimizing it means saving real money.
- Durability & Availability: How safe is your data, and can your application access it when needed?
- Architecture: The type of storage often dictates how different parts of your application interact.
In short, understanding AWS storage types is crucial for building robust, efficient, and cost-effective cloud solutions. Let's break down the three fundamental categories: File, Block, and Object storage.
(Why It Matters: Connects topic to tangible business/technical impact)
The Digital Storage Analogy: Filing Cabinets, Building Blocks, and Valet Warehouses
Imagine you need to organize different kinds of information. How you store it depends heavily on what it is and how you need to access it. Let's use an analogy:
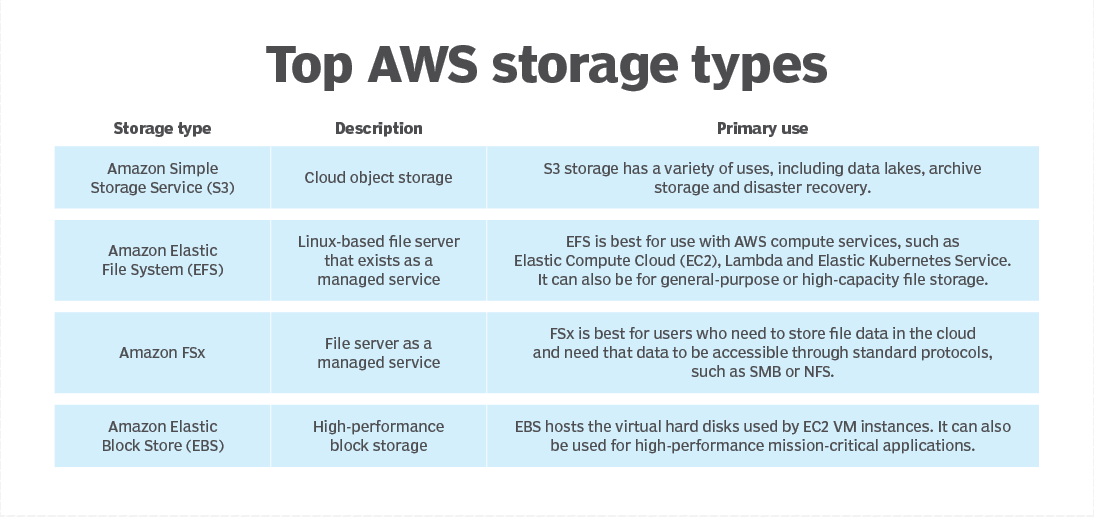
- File Storage (The Shared Filing Cabinet): Think of a traditional office filing cabinet. Folders are organized hierarchically (Cabinet -> Drawer -> Folder -> Document). Multiple people (or servers) can access the same cabinet simultaneously, see the same structure, and pull out entire files. It's familiar and intuitive. In AWS, this is primarily Amazon EFS (Elastic File System).
- Block Storage (The LEGO® Bricks): Imagine getting a box of LEGO® bricks. They are raw building blocks. You can assemble them however you want to build anything, but they don't have inherent structure on their own. You need instructions (an operating system) to make sense of them. They offer fine-grained control and high performance for specific constructions (like a database server). In AWS, this is primarily Amazon EBS (Elastic Block Store).

- Object Storage (The Giant Valet Warehouse): Picture a massive, modern warehouse where you drop off items (objects). Each item gets a unique ticket (an object ID). You don't care where in the warehouse it's stored, only that you can retrieve it instantly using your ticket. There's no complex folder structure visible to you; it's a flat space. This system is incredibly scalable and durable, perfect for storing vast amounts of unstructured data like photos, videos, or backups. In AWS, this is primarily Amazon S3 (Simple Storage Service).

(The Concept in Simple Terms: Core analogy introduced to provide mental model)
Deeper Dive: File, Block, and Object Storage Unpacked
Let's move beyond the analogy and look at the technical characteristics and primary AWS services for each type.
1. File Storage (e.g., Amazon EFS, Amazon FSx)
- What it is: Stores data as files within a hierarchical directory structure (folders and subfolders). Think
C:\Users\Youor/home/user. - Access Protocol: Uses file-level protocols like NFS (Network File System) for Linux or SMB (Server Message Block) for Windows.
- How it Works: Presents a shared filesystem that multiple clients (EC2 instances, containers, Lambda functions) can mount and access concurrently. The underlying service manages the file system structure.
- Key Characteristics:
- Shared access: Multiple clients see the same files simultaneously.
- Familiar structure: Uses standard directory paths.
- Consistency: Strong read-after-write consistency (changes are immediately visible).
- Managed service: AWS handles the underlying infrastructure, patching, etc. (for EFS/FSx).
- Primary AWS Service:
- Amazon EFS: Managed NFS file system for Linux-based workloads. Scales automatically, pay-as-you-go. Great for web serving, content management, home directories, container storage.
- Amazon FSx: Offers choices for Windows File Server (SMB) and high-performance file systems like Lustre. Used for Windows shares, HPC, machine learning data processing.
- Use Cases: Web content repositories, shared codebases, user home directories, lift-and-shift enterprise applications requiring shared file access, certain types of media workflows.
2. Block Storage (e.g., Amazon EBS)
- What it is: Stores data in fixed-size chunks called blocks. Doesn't inherently understand files or folders; it provides raw storage volumes.
- Access Protocol: Accessed by the operating system as mounted disk volumes (like a local hard drive) using protocols like iSCSI.
- How it Works: An operating system formats the block device with a filesystem (like ext4, NTFS, XFS) and then manages files and directories on top of it. Each volume is typically attached to a single instance at a time (though multi-attach EBS exists for specific clustered applications).
- Key Characteristics:
- Low latency: Designed for high performance, direct access.
- Instance-attached: Acts like a direct-attached disk drive for an EC2 instance.
- OS Managed Filesystem: Requires formatting and management by the instance's OS.
- Granular Control: Offers fine-tuned performance options (IOPS, throughput).
- Primary AWS Service:
- Amazon EBS: Provides persistent block storage volumes for use with EC2 instances. Offers various types optimized for different performance needs (gp3 for general purpose, io2 Block Express for highest performance, etc.).
- Use Cases: Boot volumes for EC2 instances, transactional databases (SQL, NoSQL), applications requiring high IOPS and low latency access to a dedicated volume.
3. Object Storage (e.g., Amazon S3)
- What it is: Stores data as objects, each consisting of the data itself, metadata (descriptive tags), and a unique identifier (key).
- Access Protocol: Accessed via APIs (REST, SDKs) or web interfaces, typically using HTTP/S requests (GET, PUT, DELETE).
- How it Works: Data is stored in a flat structure within containers called "buckets." There's no hierarchy in the storage system itself, though you can simulate folders using prefixes in object keys (e.g.,
images/cats/fluffy.jpg). - Key Characteristics:
- Massive Scalability: Virtually unlimited storage capacity.
- High Durability & Availability: Designed for 99.999999999% (11 nines) durability.
- Web Accessible: Easily accessed over the internet via HTTP/S.
- Rich Metadata: Can store extensive metadata alongside the object data.
- Cost-Effective: Generally the lowest cost storage option per GB.
- Eventual Consistency (for overwrite PUTS and DELETES in some scenarios, though S3 now provides strong read-after-write consistency for new objects).
- Primary AWS Service:
- Amazon S3: The workhorse of AWS object storage. Used for almost everything.
- Amazon S3 Glacier: Long-term, low-cost archival storage (often used via S3 lifecycle policies).
- Use Cases: Static website hosting, backups and disaster recovery, big data analytics & data lakes, media hosting (images, videos), application assets, log storage, software distribution.

(Deeper Dive: Breaks down each type with technical details, AWS services, and characteristics. Uses formatting for readability.)
Practical Use Case: Building a Photo Sharing App
Let's see how these storage types work together in a hypothetical photo-sharing application:
- User Uploads Photo: The web application server (running on EC2) receives the uploaded photo.
- Storing the Photo: The application uses the AWS SDK to
PUTthe photo directly into an Amazon S3 bucket (user-uploads-bucket/user123/photo.jpg). S3 is perfect because it's scalable, durable, cost-effective for potentially millions of photos, and easily accessible via URL for display later. Metadata like upload time, user ID, and maybe even auto-generated tags could be stored with the S3 object. - Storing User Profile & Metadata: User information (username, email, list of photo IDs) is stored in a database (e.g., RDS PostgreSQL or DynamoDB). This database runs on an EC2 instance.
- Database Storage: The database requires fast, low-latency storage for its data files and transaction logs. An Amazon EBS volume (likely a Provisioned IOPS type like io1/io2 or gp3) is attached to the database EC2 instance. EBS provides the necessary performance for database operations.
- (Optional) Shared Configuration/Cache: If multiple web servers need access to shared configuration files or a small, frequently accessed cache that needs filesystem semantics, they might mount a shared Amazon EFS volume. This allows updates to be instantly visible across all servers.
In this example, S3 handles the bulk object data, EBS provides high-performance block storage for the critical database, and EFS could potentially serve niche shared filesystem needs. Using the right tool for the job is key!
(Practical Example or Use Case: Concrete scenario showing how types are used together)
Common Mistakes and Misunderstandings
Newcomers (and even experienced folks!) sometimes stumble here:
- Using S3 for Database Files: Trying to store active database files directly on S3 is usually a bad idea. S3 is not a filesystem and lacks the low-latency random read/write performance databases need. Use EBS instead.
- Using EBS for Static Web Content: While you can store website assets (images, CSS, JS) on an EBS volume attached to your web server, S3 (often combined with CloudFront CDN) is far more scalable, durable, and cost-effective for this purpose.
- Treating EFS Like EBS (Performance): EFS is fantastic for shared access, but its baseline performance profile (especially in Bursting Throughput mode) might differ from a dedicated EBS volume. Understand EFS performance modes (Bursting vs. Provisioned Throughput) and monitor performance.
- Ignoring S3 Lifecycle Policies: Not setting up lifecycle policies to move older, less-frequently accessed data in S3 to cheaper tiers (like S3 Standard-IA or Glacier) can lead to unnecessarily high costs.
- Thinking EBS is Automatically Shared: Standard EBS volumes can only be attached to one EC2 instance at a time in a specific Availability Zone. Don't expect multiple instances to natively share a single EBS volume like they would an EFS filesystem (unless using EBS Multi-Attach for specific, cluster-aware applications like Oracle RAC or VMWare).
(Common Mistakes or Misunderstandings: Addresses frequent pitfalls)
Pro Tips & Hidden Gems
Level up your AWS storage game:
- EBS gp3 Volumes: Often provide better baseline performance and lower cost than the older gp2 standard. You can provision IOPS and throughput independently. Always consider gp3 first for general-purpose workloads.
- S3 Intelligent-Tiering: Let AWS automatically move your S3 data between frequent and infrequent access tiers based on usage patterns, optimizing costs without manual intervention. Great for unpredictable access patterns.
- EFS Infrequent Access (IA): Similar to S3 IA, EFS has lifecycle management to automatically move files not accessed for a period (e.g., 30 days) to a lower-cost IA storage class.
- EBS Snapshots: Use EBS snapshots for point-in-time backups. They are stored incrementally in S3, making them cost-effective. You can automate snapshot creation with Data Lifecycle Manager (DLM).
- S3 Transfer Acceleration: Use this feature for faster data uploads to S3 from geographically dispersed users by routing traffic through AWS edge locations.
-
CLI Power: Get comfortable with the AWS CLI for quick storage operations. For example, syncing a local directory to S3:
# Sync local 'my-app-assets' folder to an S3 bucket aws s3 sync ./my-app-assets/ s3://my-production-assets/app/
(Pro Tips & Hidden Features: Actionable advice and specific features/commands)
Final Thoughts: Choose Wisely!
File, Block, and Object storage each solve different problems exceptionally well. There's no single "best" type – the ideal choice depends entirely on your application's specific needs regarding performance, access patterns, scalability, and cost.
- Need shared, filesystem access for multiple servers? Think File (EFS/FSx).
- Need high-performance, low-latency disk for a single instance (like a database)? Think Block (EBS).
- Need to store vast amounts of unstructured data scalably, durably, and cost-effectively? Think Object (S3).
Understanding these core differences is your first step towards building well-architected, efficient, and cost-optimized applications on AWS. Now go forth and store wisely!
What are your favorite use cases for each storage type? Did any of the analogies click for you? Share your thoughts or questions in the comments below! 👇