
Automated extraction of information from the web (web scraping) has become a fundamental process for development, analytics, and automation professionals. This approach enables the harvesting of vast amounts of data from websites – from monitoring competitors’ prices to gathering social media content. To address these tasks, a wide array of tools has been created – ranging from open-source libraries and frameworks to full-fledged cloud API services that provide programmatic access to web data. Some solutions are ideal for rapid parsing of static pages, others can handle complex JavaScript navigation, and yet others specialize in retrieving data via APIs.
In this review, I will analyze the best parsing tools – both open source and commercial – and compare them according to the following criteria:
Speed and Performance:
How many pages or data points are processed per second and how efficiently are resources used? For instance, asynchronous frameworks operate much faster due to parallel processing compared to solutions that emulate a full browser, where page rendering significantly slows down the process.
Scalability:
The ability to work with a large number of threads or nodes, which is critical for industrial-scale volumes of data. Some open source projects, such as Scrapy, are designed from the outset to handle high loads, while SaaS platforms allow scaling the process in the cloud.
Bypassing Anti-Bot Protections and Handling JavaScript:
This is an important function for complex sites where dynamic content rendering is required, along with simulating user actions (clicks, scrolling) and masking automated traffic. Browser-based solutions (e.g., Selenium, Puppeteer, Playwright) are capable of mimicking human behavior, though without special settings they can be detected.
Proxy Support and CAPTCHA Solving:
The tool must allow easy configuration and rotation of proxy servers to distribute requests across different IP addresses, and also provide capabilities for bypassing CAPTCHAs. In open source solutions, manual configuration is often required, whereas commercial services usually handle this automatically.
Documentation and Community:
Detailed documentation, numerous examples, and an active community are crucial for quickly mastering the tool.
APIs and Integration:
The availability of a user-friendly API to manage scraping tasks or retrieve results facilitates project integration. Open source libraries typically provide language-specific interfaces (and sometimes even allow job launching via an API), while most SaaS tools offer a REST API – simply send an HTTP request and receive JSON data in return.
Implementation Language and License:
The choice of tool should align with your team’s tech stack (most commonly Python or Node.js), and the license for open source solutions (BSD, MIT, Apache 2.0, etc.) must permit free use in commercial projects.

Web scraping – What truly matters in this process
Open Source Libraries and Frameworks for Web Parsing
In my opinion, open source parsing tools are best suited for those who want complete control over the process and do not wish to depend on third-party services. Although they require programming skills, their flexibility allows you to precisely configure the data collection logic and deploy the parser in your own environment (on a server, in a container, etc.) without additional costs. Let’s consider the most popular solutions:
Scrapy (Python):
One of the most renowned frameworks, Scrapy is developed in Python. Thanks to its modular architecture and the asynchronous Twisted engine, Scrapy can handle thousands of requests simultaneously. It covers the entire parsing cycle – from forming the request queue and downloading pages to extracting data using selectors (XPath/CSS) and saving results in the desired format (JSON, CSV, etc.). The support for multithreading, automatic request delays, and retries of failed requests make it indispensable for “industrial” tasks. Zyte (formerly Scrapinghub) processes over 3 billion pages per month based on Scrapy. Mastering Scrapy requires understanding its architecture (spiders, pipelines, middleware), but comprehensive documentation and an active community help overcome this learning curve. The BSD license allows its use in commercial projects.
Selenium (Multilingual):
If your task requires emulating a full browser, Selenium is an excellent choice. Initially created for testing web applications, it is widely used for parsing and supports scripts in Python, Java, C#, JavaScript, and other languages. Selenium controls real browsers (Chrome, Firefox, Safari, Edge) and allows the parser to “see” the page as a user does: executing JavaScript, clicking buttons, scrolling, and filling forms. This approach is indispensable for dynamic sites; however, launching a full browser makes it slow and resource-intensive, limiting the number of parallel threads. Tools such as undetected-chromedriver are often used to hide the fact of automation. Selenium is distributed under the Apache 2.0 license, ensuring freedom of use.
Headless Browsers: Puppeteer and Playwright (Node.js, Python):
In recent years, headless solutions have gained tremendous popularity.
Puppeteer is a Node.js library from Google that controls Chrome/Chromium via the DevTools protocol.
Playwright, developed by Microsoft, offers similar functionality but also supports Firefox and WebKit, with client libraries available for Python and other languages.
Both tools allow scripts to launch a browser in headless mode, load pages, wait for JavaScript execution, and capture the final HTML, as well as create screenshots and PDFs. By interacting directly with the browser engine, they are often faster and more stable than Selenium. For example, Playwright can launch multiple browser contexts concurrently for efficient resource allocation. Despite high system requirements, they excel in tasks where JavaScript rendering is indispensable, and plugin support (e.g., for masking headless mode) helps bypass anti-bot protections. Both are available under the Apache 2.0 license.
Beautiful Soup and HTML Parsers (Python):
If the goal is to quickly process HTML or XML, BeautifulSoup4 is a time-tested tool for parsing markup and searching for elements by tags or attributes. Its simplicity and resilience to “broken” HTML have made it a favorite among beginners. It is usually used in conjunction with the requests module for downloading pages. Note that performance depends on the chosen parsing engine: the built-in html.parser is slower, while lxml significantly speeds up processing, increasing performance by roughly 25%. Although specialized parsers such as selectolax (using the lexbor engine) can deliver even better results, BeautifulSoup remains a versatile solution for handling static HTML. It is licensed under MIT.
Cheerio (Node.js):
For Node.js users, Cheerio serves as an analogue to BeautifulSoup by providing a jQuery-like API (using methods like cheerio.load(html) and $('selector')) for fast HTML parsing. It does not render pages or load external resources, which allows for high-speed operation. Typically, Cheerio is used alongside HTTP clients (such as axios or node-fetch) to obtain the HTML string, and then for processing it. However, because Cheerio does not execute JavaScript, its use is limited to static or pre-rendered content. It is licensed under MIT.
Apify SDK (Crawlee, Node.js):
Crawlee (formerly known as Apify SDK) is a powerful crawling framework designed for Node.js, developed by Apify. It combines high-level crawling features – such as URL queuing, automatic retries, and proxy rotation – with the ability to integrate with browser-based parsers. Crawlee allows you to create hybrid solutions: quickly processing static HTML via Cheerio or switching to headless mode (using Puppeteer or Playwright) for dynamic sites. It supports various output formats (JSON, CSV, XML) and seamless integration with data storage, making it indispensable for large-scale projects. It is licensed under Apache 2.0.
Other Languages:
Besides Python and Node.js, there is a multitude of tools available for other languages. For instance, Java’s Jsoup is a popular lightweight parser with a jQuery-like API. In .NET, you have Html Agility Pack and AngleSharp, while in Go, libraries such as Colly (crawler) and GoQuery (a jQuery-like parser) are widely used. However, for the purposes of this review, Python and Node.js solutions are the most in demand.
Below is a summary table of the main features of popular open source parsers:
Also note the accompanying illustration comparing the HTML parsing speed of various Python libraries: requests-html (built on BS4) was the slowest, BeautifulSoup4 with lxml took about 0.05 seconds, pure lxml about 0.01 seconds, and the leader, selectolax, parsed in 0.002 seconds. Such a difference is critical, and the choice of tool depends on performance requirements.
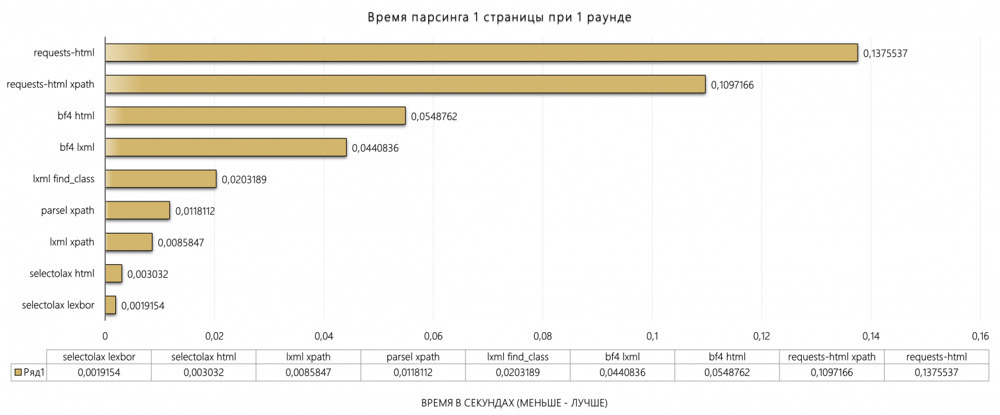
Processing time for one page (Python libraries): Selectolax (lexbor) is the fastest, while requests-html is the slowest.
Comparison of Open Source Parsers
Tool - Language - Performance & Scalability - Bypassing Blocks (JavaScript/Anti-Bot) - Proxy & CAPTCHA - License
Scrapy - Python - Extremely high – the asynchronous Twisted engine handles thousands of parallel requests; scales to clusters - Processes only static HTML; for dynamic sites, integrates with headless solutions (e.g., Splash, Selenium) and can adjust headers and delays to mask requests - Proxy support via middleware/settings; automatic delays aid in bypassing blocks; CAPTCHA is handled through manual integration with external services - BSD (open source)
Beautiful Soup - Python - Low – synchronous parsing; using lxml increases speed by roughly 25% - Handles only static HTML; dynamic sites require pre-rendering with external tools - Does not perform network requests – proxies and cookies are managed at the HTTP client level (e.g., requests) - MIT (open source)
Selenium - Multilingual - Low – running a full browser takes several seconds per page; resource-intensive and typically limited to a few dozen parallel threads - Emulates browser behavior by executing JavaScript, clicks, and inputs; can bypass most anti-bot protections, although headless mode requires special settings - Proxies are set via web driver options; CAPTCHA handling can be integrated using external services (e.g., Rucaptcha) via custom scripts - Apache 2.0 (open source)
Playwright - Node.js, Python, C# - Moderate – faster than Selenium thanks to headless operation and optimizations; supports multiple concurrent contexts - A full headless browser (Chromium/WebKit/Firefox) renders the entire page; less detectable than Selenium; supports network interceptors for dynamic user-agent changes - Proxy configuration is available via browser.newContext; CAPTCHA resolution requires external services or manual input - Apache 2.0 (open source)
Puppeteer - Node.js - Moderate – operates in headless Chromium; requires significant resources but scales well if sufficient power is available - Headless Chromium executes JavaScript and processes SPAs; easily detected without stealth plugins (e.g., navigator.webdriver flag); stealth plugins mitigate this risk - Proxies are configured via launch arguments or Page.authenticate (for HTTP proxies with credentials); CAPTCHA handling is similar to Playwright’s approach - Apache 2.0 (open source)
Cheerio - Node.js - Very high – speed is determined solely by the htmlparser2 engine, without overhead from rendering - Works only with HTML and does not execute JavaScript; unsuitable for SPAs without prior rendering; anti-bot evasion is achieved indirectly via proper HTTP headers - Does not perform HTTP requests on its own – proxy, retry, and CAPTCHA functions must be implemented externally; Cheerio focuses solely on HTML extraction - MIT (open source)
Apify Crawlee - Node.js - Very high – an asynchronous crawler with auto-throttling, capable of handling hundreds of thousands of requests and scaling horizontally - Combines fast static HTML parsing with the ability to switch to headless scraping (using Puppeteer/Playwright) for complex sites; includes built-in stealth configurations - Offers built-in proxy support (via Proxy URL or Apify Proxy rotation); does not directly solve CAPTCHAs, but external integrations can be added - Apache 2.0 (open source)
Grab - Python - Extremely high – based on pycurl/libcurl, it can handle thousands of parallel requests without being hindered by Python’s GIL thanks to asynchronous C-level processing - Processes static HTML; mimics browser behavior by adjusting headers and cookies; anti-bot measures are overcome by fine-tuning delays and request sequencing - Provides native proxy support (HTTP(S), SOCKS) with built-in authentication; does not include built-in CAPTCHA automation and requires external solutions - MIT (open source)
Cloud Platforms and Visual Scrapers (SaaS)
Commercial scraping solutions are aimed at those who want to avoid infrastructure complexities and obtain a ready-made service. Typically, these are cloud platforms and APIs that provide advanced features (extensive proxy pools, automatic bypassing of blocks, visual builders) in exchange for a subscription fee or pay-per-volume pricing. Let’s review the main categories:
API Services for Web Scraping and Proxies
These services allow you to send an HTTP request with a URL and receive HTML or structured data in response. They handle the distribution of requests across thousands of IP addresses, enforce delays, and solve CAPTCHAs—making it convenient for developers to integrate the API call directly into their code without worrying about blocks.
Scraper API:
A service with the slogan “get the HTML of any website via an API call.” Automatic IP rotation, retrying failed requests, and CAPTCHA solving virtually guarantee that you won’t get blocked. Scraper API substitutes the necessary proxies and user-agents, can bypass protections like Cloudflare, and supports JavaScript rendering options. Its simple GET-request interface (for example, a call like http://api.scraperapi.com?api_key=APIKEY&url=http://example.com) and available SDKs for Python, Node.js, and others have made it very popular. It offers a free plan of up to 1,000 requests per month, with paid plans starting at $29/month.
Zyte (Scrapinghub):
A comprehensive cloud solution from the creators of Scrapy. It includes the Smart Proxy Manager (formerly Crawlera) for intelligent proxy management, Splash for page rendering, AutoExtract – an ML-based API for structured data extraction, and Scrapy Cloud for hosting crawlers. This hybrid approach allows you to write a scraper in Scrapy and run it seamlessly in the cloud using integrated proxy and data extraction tools. Although the documentation and tutorials are excellent, the cost is significantly higher: proxies start at $99/month for 200k requests, and a full package for large projects can reach thousands of dollars.
Bright Data (Luminati):
The largest proxy provider also offers a comprehensive Web Scraping API. Their product, Web Unlocker, is an all-in-one solution that automatically configures headers, follows redirects, manages cookies, and even solves complex CAPTCHAs if needed. With access to millions of residential and mobile IPs with automatic rotation, you receive structured data without the usual headaches. The downside is the high cost, aimed at the corporate segment (enterprise plans typically start at around $500/month).
SerpAPI:
A specialized API for obtaining search engine results (from Google, Bing, Baidu, etc.). Scraping search result pages is challenging due to frequent HTML changes and strict limits, so SerpAPI provides ready-made endpoints. A query with parameters (for example, q=USD RUB exchange rate) returns structured JSON with headlines, links, snippets, and even additional data (maps, widgets). The service can simulate geolocation, device type, and search language for maximum accuracy. A free plan offers 100 requests per month, with paid plans starting at $50/month.
Cloud-Based Platforms & Visual Scrapers
This group of solutions is aimed not only at developers but also at users who prefer a visual, code-free experience. They typically feature cloud-based interfaces or desktop applications where you can set up scraping with simple point-and-click actions, and the service does the rest.
Octoparse:
One of the most popular cloud scrapers with a point-and-click interface. The user enters a URL, selects the elements to extract by clicking, and the system automatically builds a workflow: first gathering links from category pages, then following them and extracting fields (such as title, price, etc.). Octoparse can simulate scrolling, clicking the “load more” button, logging into a site, and other actions required to bypass protections. The service uses automatic IP rotation to help avoid bans. Its free plan supports up to 10k data points per month, while paid plans start at $89/month.
ParseHub:
A desktop application with a web dashboard that allows you to visually configure a scraper. Marketed as “an advanced scraper that extracts data as if you were clicking on it,” ParseHub emphasizes structured output – immediately exporting results to JSON, CSV, or Google Sheets via its API. It supports pagination, infinite scroll, and dropdown interactions to handle even complex sites. The free version is limited to 200 pages per project, with paid plans starting at roughly $149/month.
WebScraper.io:
A popular Chrome extension, also available as a cloud service, that lets you select elements for extraction directly in the browser, forming a sort of site map for crawling. It supports dynamic AJAX sites, proxy usage, and multithreading. While the extension is free, advanced features such as data storage and exports (to Dropbox or Google Sheets) are available through paid Cloud Scraper plans starting at $50/month.
Apify:
In addition to its open source SDK, the Apify platform offers a ready-made cloud infrastructure complete with a catalog of ready-to-run scripts (Actors) for popular websites – from Amazon product scrapers to Instagram post collectors. You can run pre-built Actors without writing code or create your own using Crawlee, all within their cloud environment. This hybrid approach – combining a visual builder with the option for custom coding – makes Apify a versatile solution. It offers a free tier (up to $10 in credits per month), with further usage billed on a pay-as-you-go basis.
Specialized & Unique Scraping Solutions
There are also commercial tools designed for niche or advanced scraping tasks.
Diffbot:
A powerful AI-powered parser that, instead of manual selector definitions, uses computer vision and machine learning to automatically recognize the structure of a page. Simply provide a URL, and Diffbot returns the headline, text, author, date, images – everything you need – by automatically identifying data blocks. It is excellent for scaling scraping across up to 10,000 domains, building a unified Knowledge Graph. Pricing starts at $299/month, making it a choice for large companies.
A-Parser:
A popular desktop application for SEO scraping in the CIS, available for Windows and Linux. It is distributed under a lifetime license (starting at $119) and combines over 70 built-in scrapers for various tasks – from search engine results to bulk link availability checks. Its flexible configuration allows you to use pre-built modules or create custom templates using RegExp, XPath, and JavaScript. API support for integration with other services and an active community make it indispensable for SEO specialists.
PhantomBuster:
A service well-known in SMM automation that provides pre-built “phantoms” (scripts) for extracting data from social networks and other platforms where standard methods do not work. For example, you can extract the contacts of users who liked an Instagram post or compile a list of LinkedIn event participants. PhantomBuster emulates real user actions in a browser, often requiring you to supply your own cookies or access tokens. For developers, this is a convenient outsourcing solution that avoids the need to build a custom bot. Pricing starts at $30/month.

Comparison of Commercial Scraping Solutions
Service/API - Type - Anti-Block Capabilities - Proxy/CAPTCHA - API/Documentation - Price (from)
ScraperAPI - HTTP Request API - Automatically rotates IPs on each request, retries errors, and handles CAPTCHAs seamlessly - Includes an extensive proxy pool; CAPTCHAs are resolved on the server side - Excellent documentation, client libraries for popular languages; simple REST GET interface - Free for 1,000 requests/month; from $29/month
Zyte (Scrapinghub) - Platform (Proxies + Cloud) - Features Smart Proxy Manager with sophisticated anti-block algorithms; uses Splash for JS rendering; AutoExtract for ML-based parsing - Boasts its own proxy pool of thousands; can bypass Cloudflare; CAPTCHAs managed via Splash or external recognition services - Rich REST API with Scrapy integration; web interface and extensive tutorials - Demo for 10k requests; commercial plans from $99/month (proxies), with additional costs for AutoExtract
Bright Data (Luminati) - API + Control Panel - Employs aggressive evasion tactics: full browser emulation, dynamic header/cookie management, and reCAPTCHA solving - Provides millions of residential IPs worldwide with automatic rotation; CAPTCHAs, even complex ones, are solved as an extra service - Detailed API with a user-friendly web panel featuring logs; enterprise-grade support - Custom pricing; for serious projects, from approximately $500/month
Octoparse - Cloud Service + Desktop UI - Utilizes automatic IP rotation and simulates user actions (clicks, scrolls) to overcome basic blocks - Offers a built-in proxy pool (transparent to the user); if a CAPTCHA appears, it pauses the scraper for manual input (partial automation) - Visual interface combined with an HTTP API for result downloads; comprehensive help center - Free (up to 10k records/month); paid plans start at $89/month
ParseHub - Cloud Service + Desktop UI - Executes JavaScript/AJAX on pages to bypass most standard blocks; can operate via your VPN/proxy if necessary - Does not include built-in proxies, but supports connecting your own; CAPTCHA issues require manual intervention - Features a visual UI and an API for exporting data (JSON, CSV) and project management; excellent user guide - Free (200 pages per project); approximately $149/month for advanced plans
Apify - Cloud Platform + Marketplace - Runs scripts on Puppeteer/Playwright to bypass protections like Cloudflare; offers ready-made Actors with anti-detection methods - Apify Proxy (a paid add-on) supplies thousands of global IPs; allows integration of your own proxies; CAPTCHAs are managed via integrated script services - Full-featured HTTP API for launching, monitoring, and retrieving results; superb documentation; extensive Actor library - Free tier (up to $20 in credits); then pay-as-you-go (e.g., ~$49/month for ~220k pages)
Diffbot - API with AI Processing - Utilizes AI algorithms to “see” and parse pages like a human, independent of HTML structure, ensuring resilience to changes - Uses proprietary crawlers—no proxy setup required; minimal CAPTCHAs due to low-frequency requests and natural browser appearance - REST API with SDKs for various languages; technical documentation with detailed data structure descriptions (Knowledge Graph) - From $299/month and up (enterprise-oriented, with trial limitations)
A-Parser - Desktop Software (CLI/Desktop) - Mimics human browsing through configurable delays and randomized parameters; for search engines, leverages official APIs to reduce bans - Supports proxy lists (with dynamic weights and automatic updates); intelligently distributes load and switches IPs when blocked; integrates third-party CAPTCHA solvers (e.g., 2captcha, RuCaptcha) - Offers an HTTP API for programmatic control; configuration via files and UI; detailed documentation in Russian and English; active community forum - €119 one-time for the basic (Lifetime) version; €279 for the extended version; demo is functionally limited
In addition to the solutions listed above, many other SaaS scrapers exist on the market – such as ScrapingBee, ScrapingAnt, browser extensions like Data Miner or Instant Data Scraper, specialized price monitoring tools (e.g., NetPeak Spider, Screaming Frog for SEO), and social media scraping services like PhantomBuster for LinkedIn/Instagram. The choice depends on the specifics of your task.
Conclusion
There is no single “best” tool in the world of web scraping – the optimal choice depends entirely on your project’s specific requirements. If speed, flexibility, and full control are paramount, open source solutions like Scrapy or Crawlee are ideal – they allow you to work with vast amounts of data, process dynamic content using Playwright/Puppeteer, or quickly parse static HTML with BeautifulSoup or Cheerio. Of course, all these tools require coding, but they offer maximum freedom without additional costs. On the other hand, cloud services and APIs save time by automatically bypassing blocks, providing out-of-the-box scalability, and often allowing you to configure scraping without writing a single line of code. Their drawbacks are cost and reliance on a third-party platform, but for regular extraction of gigabytes of data or rapid prototyping, this compromise can be optimal. Sometimes, a hybrid approach proves most effective: performing the main scraping with an open source tool while minimizing the risk of blocks with a commercial proxy API.
Happy scraping, and may the power of proxies always be with you!