and Why Indexes Alone Won’t Save You
Executive Summary
Modern databases handle vast amounts of data — often spanning tens of terabytes or even petabytes — and relying solely on indexing is insufficient for optimal performance. Misunderstanding this can lead to degraded performance, increased operational costs, and poor user experience. This article highlights why indexing alone isn’t the solution and provides practical alternatives and strategies for scalable, efficient data management.
Why Indexes Alone Are Insufficient
Indexes improve read performance but introduce overhead during writes, slowing transactional operations. Businesses frequently face performance degradation due to excessive indexing, resulting in increased operational costs and diminished customer satisfaction.
Technical Basics
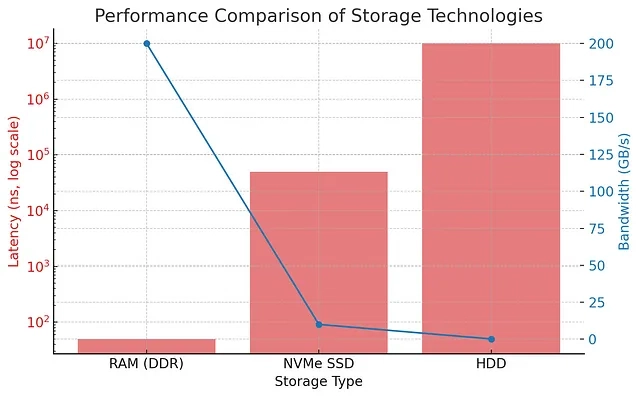
Data resides in three main storage systems, each with distinct performance characteristics:
RAM (volatile memory): Extremely fast, ideal for real-time data processing.
NVMe Drives/SSDs: Faster, persistent storage with moderate costs.
Rotating hard drives: Cost-effective but significantly slower.
The efficiency of your software solution (SQL, NoSQL, or caching systems) significantly depends on your choice of storage and how effectively the software manages data contention.
When Indexing Hurts More Than It Helps
High-write Workloads: Frequent data updates make indexing costly and inefficient.
Analytics Queries: Full-table scans on specialized storage can be more efficient than indexed lookups.
Complex Joins and Aggregations: Excessive indexing increases complexity and resource use, potentially harming performance.
Strategic Alternatives to Optimize Performance
1️⃣ Separate Analytics from OLTP Systems
Operational (OLTP) and analytical workloads should never compete for resources within the same database. Operational queries demand instant responses, while analytics queries, analyzing large historical data sets, consume extensive resources.
Actionable Step: Evaluate your database architecture to segregate operational databases from analytical workloads.

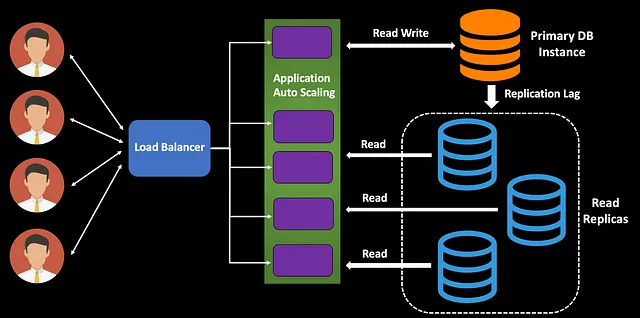
2️⃣ Separate Read and Write Operations
Using database read replicas improves scalability and resource efficiency by minimizing bottlenecks. However, it can introduce slight latency or data staleness.
Actionable Step: Consider implementing read replicas to reduce load on your primary database, but assess potential data staleness impacts.
Possible Challenge! Creating replicas introduces latencies to allow writes to replicate. Or some staleness in the data. Which can be ok in most (not all) scenarios. Choose wisely!
3️⃣ Implement Caching with Redis, Valkey, or Memurai
Caching frequently accessed data significantly enhances application responsiveness by reducing database queries. This results in lower latency, reduced database loads, and improved scalability. The first cache that found tremendous popularity was Redis (for Linux). Then its unwise licensing choices lead the recent groth of Valkey, a fully open-source alternative to Redis. For Windows, there’s Memurai: a fully supported and enterprise-ready partner of Redis.

Actionable Step: Consider adding code (for Reads) that access cache first, and only on a cache-miss access the DB.
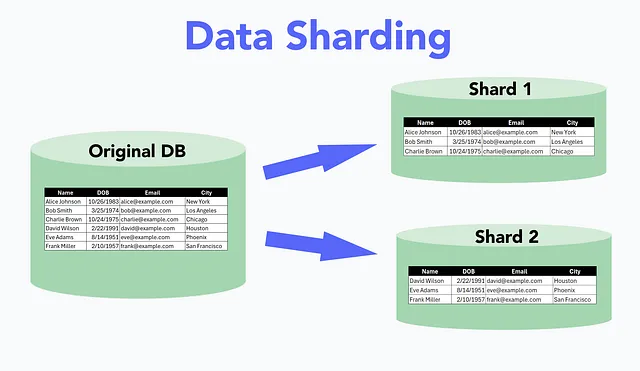
4️⃣ Shard Data to Distribute Load
Sharding partitions data across multiple databases, distributing load and preventing bottlenecks. While traditional databases (RDBMS) require manual sharding efforts, solutions like Valkey offer built-in sharding capabilities, simplifying scaling.
Actionable Step: Consider sharding if your current database struggles with heavy loads or data volumes exceeding manageable thresholds.
6️⃣ Leverage Data Lakes for Historical Data
Storing historical data in data lakes optimizes analytics, lowers storage costs, and maintains regulatory compliance without taxing operational databases.
Actionable Step: Implement clear data-retention policies and regularly move older, less frequently accessed data to data lakes to enhance database performance.
7️⃣ Summary
Providing generic advice is inherently challenging. Please consider the recommendations in this table as guidelines rather than absolute rules.
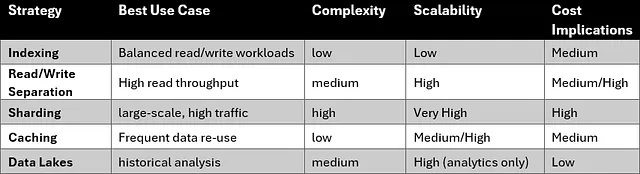
Conclusion
Indexes alone cannot support modern database demands at large scale. Strategic decisions regarding database infrastructure directly influence your organization’s agility, costs, customer satisfaction, and competitive positioning. Making informed choices now prevents costly performance degradation later.
Are you dealing with SQL scalability headaches?
If your data is growing and you’re unsure how to scale without breaking the bank, let’s talk. I help teams with architecture and modernization strategies — reach out if you need a second opinion.
PS: Check out my informal podcast “PROIEX — Tech Experiences”!
