I'll show you different levels of parallelism you can achieve to improve the performance of complex Machine Learning workflows.
Parallelism in ML pipelines
Map is a functional programming paradigm that allows you to apply a function to each element of a collection (e.g., a list) and return the output in a collection of the same type.
This can be very useful in ML pipelines, where multiple transformation steps are applied iteratively to the input dataset. Say you need to preprocess a text dataset represented as a list:
raw_texts = [
"Hello! This is a SAMPLE text with UPPERCASE words.",
" Extra spaces AND 123 numbers... ",
"Another EXAMPLE with Punctuation!!!"
]You may want to define a preprocessing function:
def preprocess_text(text):
# Lowercase
text = text.lower()
# Remove special characters and numbers
text = re.sub(r'[^a-zA-Z\s]', '', text)
# Remove extra whitespace
text = re.sub(r'\s+', ' ', text).strip()
return textThen, you need to apply this function to the input text. Doing it sequentially would likely involve writing something like a for loop. While the output is the same, this can be time-consuming for large datasets, and processing it in parallel may be preferable.
Enter the map pattern.
# Apply preprocessing to all elements in the inputs list using map
preprocessed = list(map(preprocess_text, raw_texts))Using this approach, we can complete preprocessing in parallel, which can be beneficial in ML pipelines where this step may happen multiple times.
But, how to do it more efficiently? How to distribute the load among multiple compute nodes? Enter Flyte Map Tasks.
Flyte MapTask
Flyte is a distributed computation framework that uses a Kubernetes Pod as the fundamental execution environment for each task in a pipeline. When you use MapTasks, Flyte automatically distributes the load among multiple Pods that run in parallel and limits each Pod to downloading and processing only a specific index from the inputs list, preventing inefficient duplicate data movement.
But how many Pods are created?
Let’s see.
In this simple example:
from flytekit import map_task, task, workflow
threshold = 11
@task
def detect_anomalies(data_point: int) -> bool:
return data_point > threshold
@workflow
def map_workflow(data: list[int] = [10, 12, 11, 10, 13, 12, 100, 11, 12, 10]) -> list[bool]:
# Use the map task to apply the anomaly detection function to each data point
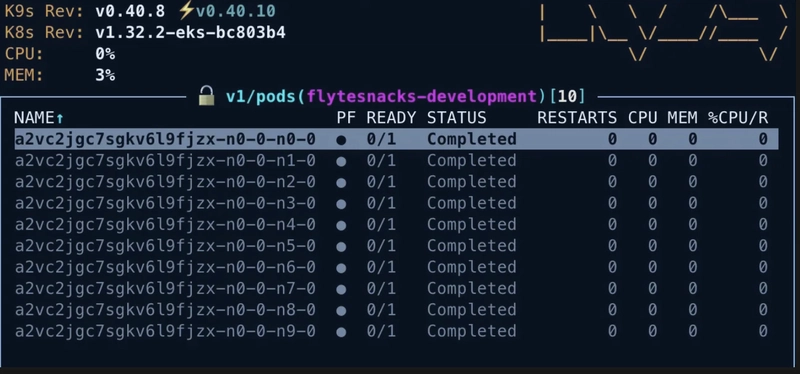
return map_task(detect_anomalies)(data_point=data)We can see it creates one Pod per element in the inputs list:
We said it’s an iterative process, so next time you have to do this, MapTasks again spin up 10 Pods. What if there are thousands or millions of inputs (like in many LLM input datasets)? What is the impact of booting up one container per element in the inputs list?
With the example above, this is the time it takes to complete the execution:
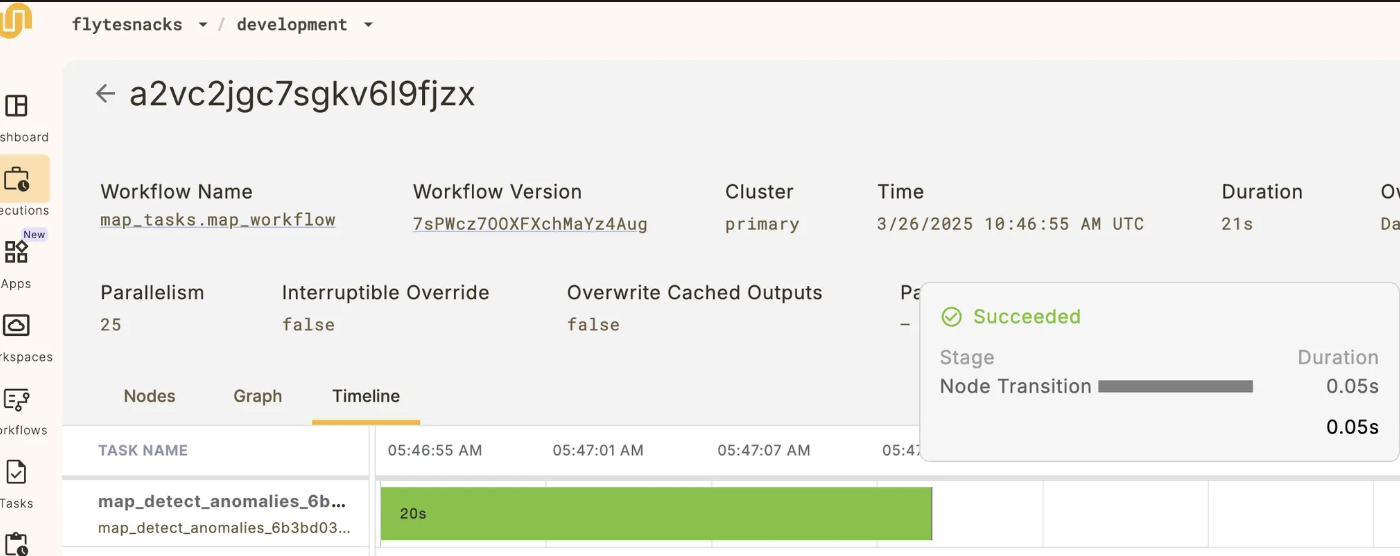
20 seconds.
If we duplicate the list size, time starts piling up:
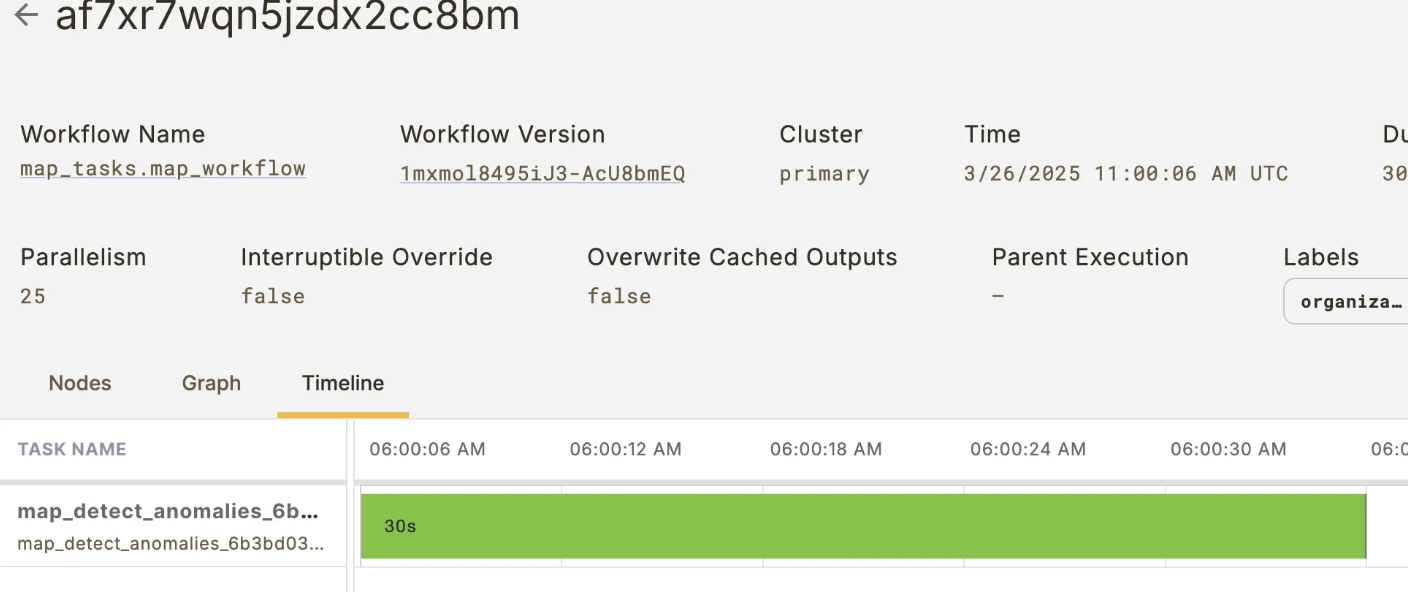
This is, for a 100% increase in the input dataset size, there was a 50% increase in total execution time.
What if you could reuse a specific number of Pods to mitigate this penalty?
Union Actors
This feature allows you to declare an execution environment and then reuse it through multiple executions to mitigate the impact of container boot-up times.
We define a slightly modified version of the previous example to run it in the Union platform using an input dataset with 100 items.
As you may imagine at this point, it would create 100 Pods.
To mitigate this workflow becoming a "noisy neighbour" in your cluster, you can specify the number of concurrent executions and, hence, the number of Pods that are created simultaneously at any point in time. In this example, we limit this number to 10:
from flytekit import map_task
import union
import random
threshold = 31
#Declare a container image
image = union.ImageSpec(
packages=["union==0.1.168"],
builder= "union",
)
@union.task(container_image=image)
def detect_anomalies(data_point: int) -> bool:
return data_point > threshold
@union.workflow
def map_workflow(data: list[int] = random.sample(range(1,101), k=100)) -> list[bool]:
# Use the map task to apply the anomaly detection function to each data point
return map_task(detect_anomalies, concurrency=10)(data_point=data)Execution takes 1 minute:

Now, if we define an Actors environment with 10 replicas, or 10 "reusable" Pods:
from flytekit import map_task
import union
import random
threshold = 101
image = union.ImageSpec(
#registry="ghcr.io/davidmirror-ops/images",
packages=["union==0.1.168"],
builder= "union",
)
#Here we define the Actors settings
actor = union.ActorEnvironment(
name="my-actor",
replica_count=10,
ttl_seconds=30,
requests=union.Resources(
cpu="125m",
mem="256Mi",
),
container_image=image,
)
@actor.task
def detect_anomalies(data_point: int) -> bool:
return data_point > threshold
@union.workflow
def map_workflow(data: list[int] = random.sample(range(1,101), k=100)) -> list[bool]:
# Use the map task to apply the anomaly detection function to each data point
return map_task(detect_anomalies)(data_point=data)Execution time is 22 seconds:
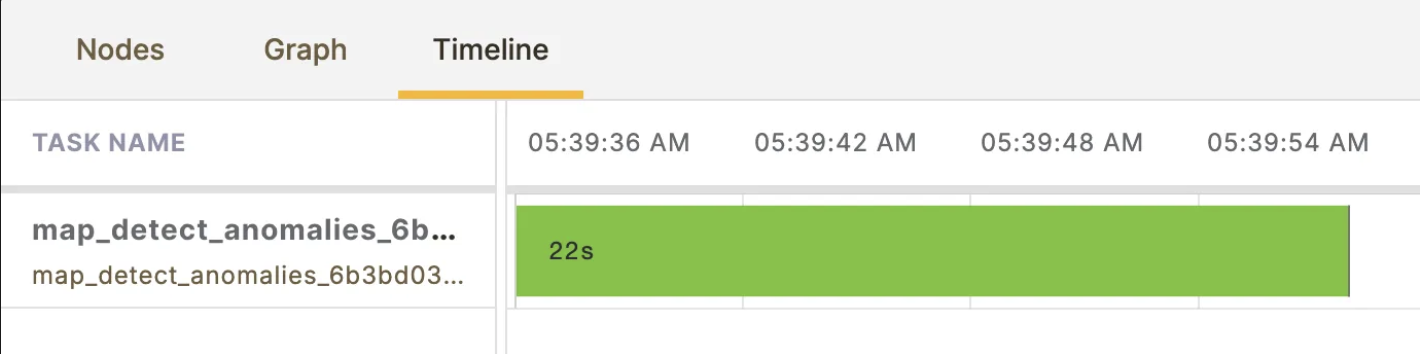
That's a 63% decrease in execution time, enabling much higher iteration velocity and more efficient resource consumption.
Conclusion
Modern ML workloads are typically designed to process in parallel big datasets. That carries a performance penalty due to the latency of booting up a container. Flyte let's you achieve efficient parallel processing but Union Actors take it to the next level by also removing the limitation of one Pod per input item, allowing faster and more efficient executions.
Signup for Union's free tier
Check out the repo
Questions? Join us on Slack!