This is a Plain English Papers summary of a research paper called Budget Insights: Predicting Market Impact with AI & the BASIR Budget Dataset. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Decoding Budget Impact: How Government Fiscal Policy Affects Financial Markets
Government fiscal policies, especially annual budgets, significantly influence financial markets in emerging economies. In India, the Union Budget's sector-specific allocations and tax reforms directly affect capital flows, with historical data showing volatility spikes in sectoral indices during budget weeks. While investors systematically analyze budgetary provisions to predict market trajectories, current analysis methods remain predominantly manual - a labor-intensive, time-consuming process prone to cognitive biases and speculation.
This research introduces a novel computational framework that combines transformer-based language models with sectoral performance ranking to address these limitations. The approach focuses on two main tasks: identifying sectors mentioned in budget speeches and predicting which sectors will perform best after budget announcements.
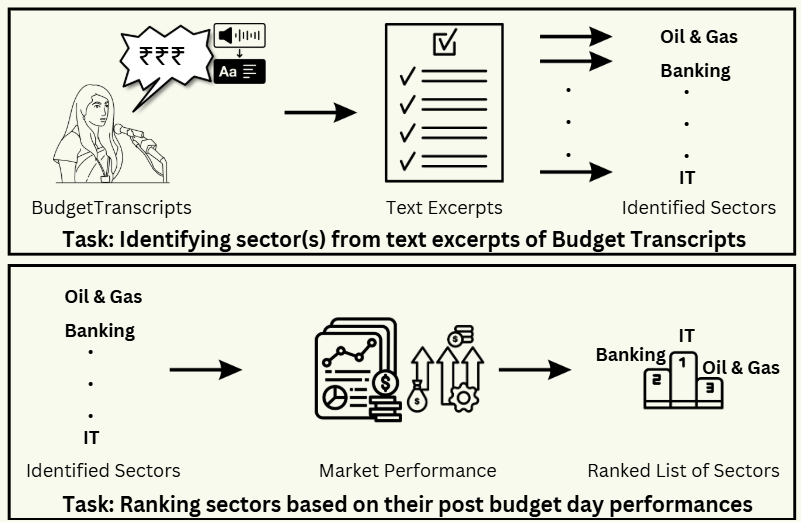
Figure 1: Framework for identifying sectors from budget transcripts and ranking them based on predicted performance
The key contributions include BASIR (Budget-Assisted Sectoral Impact Ranking) - the first annotated dataset spanning Indian Union Budgets from 1947 to 2025, featuring over 1,600 text excerpts from budget transcripts with corresponding sector labels. The research also presents a framework for identifying sectors from budget transcripts and ranking them based on predicted performance, along with an empirical assessment of advanced Large Language Models' capabilities in predicting sector performance based on budget excerpts.
The Intersection of Budgets and Markets: Research Context
The annual Indian Union Budget functions as a crucial instrument for economic policymaking, directly impacting sectoral growth trajectories and investor sentiment. Research using event study methodology has demonstrated that Cumulative Average Abnormal Returns (CAARs) are significant around budget announcements, indicating these events contain valuable information for market participants.
Several studies on financial sentiment analysis reveal pronounced sector-specific volatility patterns post-budget announcements, with healthcare, banking, and Information Technology sectors demonstrating heightened sensitivity to tax reforms and capital allocation decisions. NLP has emerged as a transformative tool in decoding fiscal policy impacts on stock markets, with sentiment analysis proving particularly useful in assessing market sentiment and generating trading signals.
Advanced NLP models like BERTopic and RoBERTa have been employed to analyze sentiment in monetary policy communications, revealing how different economic topics influence market reactions. However, most previous studies focused on post-hoc analyses using historical data, typically conducted after market hours. This work introduces a predictive approach, innovatively utilizing NLP to automatically detect sectors from budget announcements and rank them according to their predicted performances - providing valuable foresight for both investors and policymakers compared to traditional financial sentiment analysis approaches.
Twin Challenges: Sector Classification and Performance Prediction
This study addresses two sequential challenges in computational fiscal analysis:
Multi-Label Sector Classification: Given a budget transcript segment from India's Union Budget corpus (1947–2025), determine the probabilistic association for each sector, where the set represents 81 formal economic sectors. The task requires overcoming implicit sector references in policy language (e.g., "Credit access for handloom industries" → Banking, Textile sectors) and domain-specific lexical ambiguity (e.g., "digital infrastructure" mapping to both Technology & Utilities sectors).
Performance-Aware Sector Ranking: For identified sectors, develop a model that ranks sectors by expected next-day post-announcement returns using text excerpts related to the sector. This requires transforming qualitative budget language into quantitative performance predictions.
These twin challenges require sophisticated natural language processing techniques that can understand the nuanced relationships between budget language and market performance.
Building BASIR: A Comprehensive Dataset of Budget Impacts
The BASIR dataset was constructed through a comprehensive three-stage process:
Data Collection & Curation
- Sector-Company Mapping: Systematically collected a list of sectors and their constituent companies from Screener.in
- Budget Transcripts: Aggregated 97 Union Budget documents (1947–2025) from India's Ministry of Finance portal, comprising over 1,600 text excerpts including interim budgets
Annotation Pipeline
- Sector Tagging: For each budget transcript, DeepSeek was prompted to extract texts and corresponding sectors
- Validation: All outputs were manually validated for accuracy
Market Response Quantification
For each sector on budget day, performance metrics were calculated using opening price movements of constituent companies, with historical data sourced from Yahoo Finance. Sectors were then ranked in decreasing order of their performances.
| Metric | Budget Transcripts | Sector Identification | Sector Ranking |
|---|---|---|---|
| Total Entries | 97 | 1,671 | 429 |
| Temporal Span | 1947-2025 | 1947-2025 | 1997-2025 |
Table 1: Dataset Statistics showing the scale and temporal coverage of the BASIR dataset
The dataset was split chronologically, with data until 2019 used for training, 2020-2023 for validation, and 2024 reserved for testing. This chronological splitting ensures the models are evaluated on future data, mimicking real-world application scenarios. The efficient annotation methodology combining LLM suggestions with human validation represents a scalable approach for creating domain-specific datasets.
From Text to Predictions: Experimental Approach and Results
Finding Economic Signals in Budget Language
The task of identifying sectors from budget excerpts was approached as a multi-class classification problem with several methodologies tested:
- Semantic Similarity (STS) based on Nomic embeddings, both in base form and with fine-tuning to optimize vector space representation
- Fine-tuned Language Models including BERT and RoBERTa for classifying budget excerpts into appropriate sectors
The performance metrics reveal that the STS model with fine-tuned embeddings demonstrated superior performance in terms of both Macro (M) and Weighted (W) F1 scores. This suggests that the fine-tuned embedding approach effectively captures the nuanced relationships between budget language and sectoral classifications. The BERT model exhibited the highest Micro (m) F1 score, indicating its strength in correctly classifying the most frequent sector categories.
| F1 (M) | F1 (m) | F1 (w) | |
|---|---|---|---|
| STS (base) | 0.159 | 0.176 | 0.345 |
| STS (fine-tune) | 0.291 | 0.478 | 0.605 |
| BERT | 0.179 | 0.489 | 0.425 |
| RoBERTa | 0.075 | 0.274 | 0.192 |
Table 2: Results of Multi-Label Sector Classification showing F1 scores across different approaches
Predicting Winners and Losers: Ranking Sector Performance
To rank sectors based on their performance, the research evaluated four distinct architectural approaches:
- Encoder-based classification models (BERT, RoBERTa, DeBERTa) that transformed sector performance into a binary classification task
- Encoder-based regression models that directly predicted performance metrics
- Feature-based models using Nomic embeddings with various machine learning algorithms including logistic regression, random forest, and XGBoost
- Zero-shot prompting of large language models including Gemma-3 27B, DeepSeek V3, and Llama 3.3 70B
The models were evaluated using Normalized Discounted Cumulative Gain (NDCG), a measure of ranking quality. The BERT model trained for classification exhibited superior performance, suggesting that smaller models can be more effective when trained on limited instances. Notably, the performance of zero-shot large language models was comparable to that of dedicated trained models, demonstrating their potential for retrieval tasks even without domain-specific training.
| Model | Type | NDCG |
|---|---|---|
| BERT | Enc Clasifier | 0.997 |
| RoBERTa | Enc Clasifier | 0.994 |
| DeBERTa | Enc Clasifier | 0.996 |
| BERT | Enc Regressor | 0.995 |
| RoBERTa | Enc Regressor | 0.995 |
| DeBERTa | Enc Regressor | 0.995 |
| Logistic | Emd + Classifier | 0.996 |
| Random Forest | Emd + Classifier | 0.996 |
| XG-Boost | Emd + Classifier | 0.994 |
| Linear | Emd + Regressor | 0.995 |
| Random Forest | Emd + Regressor | 0.996 |
| XG-Boost | Emd + Regressor | 0.994 |
| XG-Boost | Learning to Rank | 0.994 |
| Gemma-3 27B | Zero Shot | 0.994 |
| DeepSeek V3 | Zero Shot | 0.993 |
| Llama 3.3 70B | Zero Shot | 0.994 |
Table 3: Sector Ranking Results showing NDCG scores across all evaluated models
Implications and Future Directions
The research presents a comprehensive framework for detecting and ranking sectors from Indian Union Budget transcripts. Fine-tuned Nomic-based embeddings provided superior performance in identifying sectors from textual excerpts, capturing the nuanced relationships between budget language and sectoral classifications. The BERT-based model fine-tuned for classification emerged as the most effective approach for ranking sectors based on predicted performance.
This framework offers valuable insights for investors and financial analysts seeking to understand immediate market implications of budget announcements. By automating sector identification and performance prediction, the approach enables more timely and informed decision-making compared to traditional manual analysis.
Future research directions include extending the framework to recommend specific stocks within identified sectors, potentially offering more granular investment guidance. Developing capabilities to capture real-time price movements following budget announcements would further enhance practical applicability. The BASIR dataset provides a valuable foundation for these future explorations in computational economics and finance.
Understanding the Limitations
Despite significant methodological contributions, several limitations warrant acknowledgment:
Annotation Approach: The focus on precision over recall in sector identification means the DeepSeek language model may have overlooked subtler budget-sector relationships, particularly when policy implications were implicit rather than explicit. This creates potential systematic blind spots in the dataset.
Temporal Coverage: Market performance data availability beginning only from 1997 excluded 50 years of budget documents (1947-1996) from complete analysis. Additionally, inconsistent market data across sectors forced the exclusion of certain sector-period combinations, introducing potential selection bias.
Confounding Variables: The performance metric isolates budget effects without controlling for other factors. Macroeconomic conditions, sector-specific events, and concurrent corporate announcements likely influence post-budget market movements, limiting causal interpretations of budget-performance relationships.
Future research should address these limitations through multi-source validation, synthetic data generation for pre-1997 periods, and development of counterfactual models that control for non-budgetary market influences.
