When dealing with massive datasets of URLs—especially in industries like sports analytics, finance, or research—it’s not uncommon to encounter a frustrating pattern: a web page loads, appears valid to the server, but contains a polite “Sorry, we couldn’t find what you’re looking for” message. These kinds of false positives are time-consuming to verify manually, especially when the dataset spans tens of thousands of links.
To solve this problem, I built a headless URL checker that scans web pages for meaningful content, distinguishing between truly valuable pages and placeholder or “no data” pages. This post outlines how the tool works, the features that make it cloud-ready and scalable, and how it handles the challenges of bot detection.
The Problem: Valid URLs, Useless Content
The URLs I worked with pointed to profile pages—some of which loaded correctly but returned a message like:
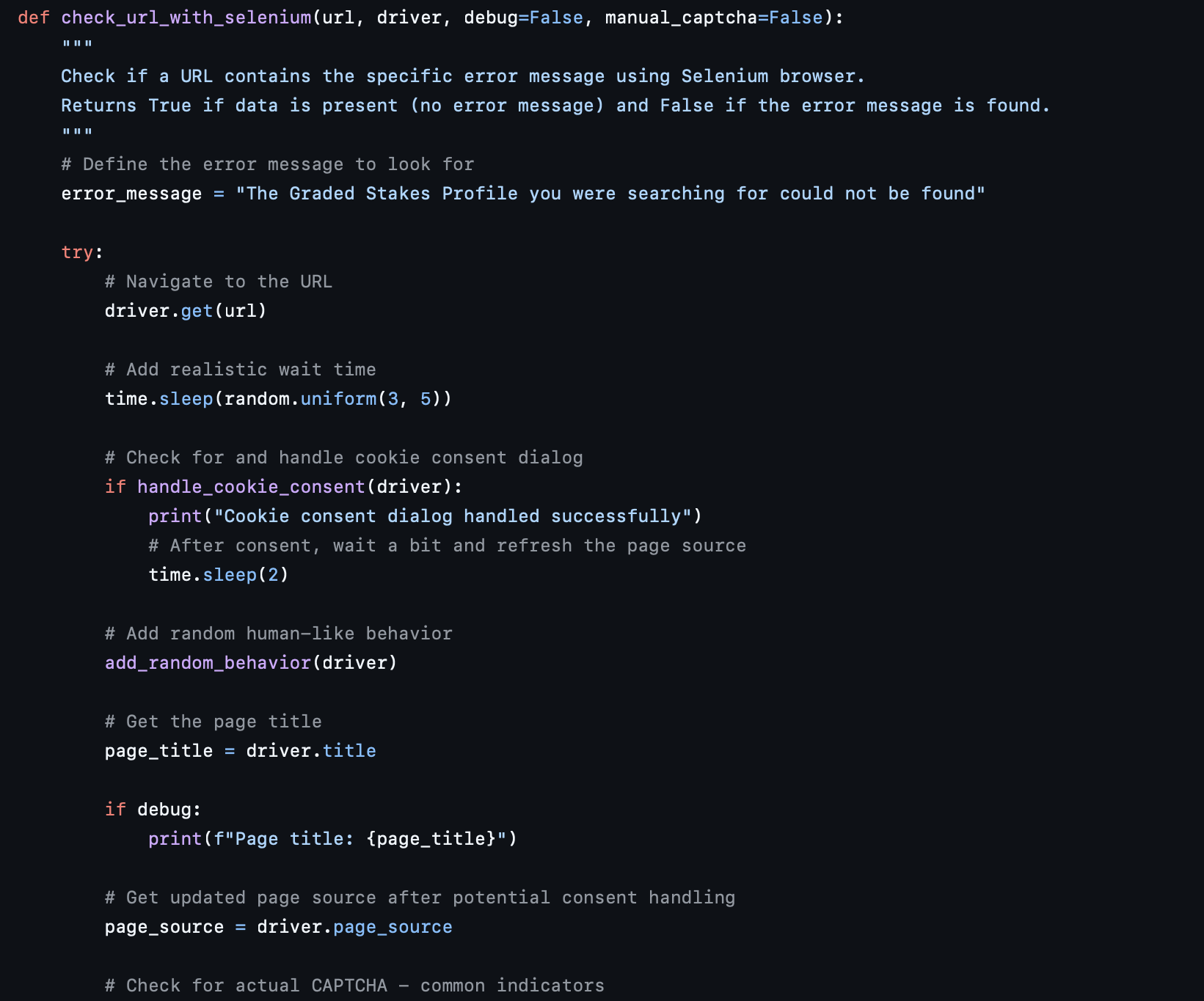
"The Graded Stakes Profile you were searching for could not be found"
These pages technically loaded (i.e., status code 200), but they didn’t actually contain the content I needed. I needed a way to automate the process of identifying these cases so I could focus only on URLs with actual data.
The Solution: Headless URL Checker
The solution is a Python-based script (url_checker_HEADLESS.py) that uses Selenium with headless Chrome to programmatically load and inspect pages.
Main Capabilities:
Reads from a CSV: Input is a master file (Equibase_URLS.csv) containing ~30,000 URLs.
Searches page content: Scans the page for a specific error message indicating no relevant data.
Saves results: Records either "yes" (content found) or "no" (error message detected) in an output CSV.
Here’s the logic in a nutshell:
If the page contains the "could not be found" message → record "no".
If the message is absent → record "yes", indicating this URL contains data we are interested in.
Sample code:
Built for the Cloud (and for Stealth)
Scraping at scale comes with risks: IP blocking, captchas, and bot protection mechanisms. This checker includes several countermeasures:
- Headless Chrome Browsing: Lightweight and fast for cloud-based execution.
- Randomised User Agents: Prevents fingerprinting.
- Session Cookie Injection: Uses a cookies.pkl file generated from a real browser session via generate_cookies.py.
- Random Delays: Introduces human-like delays between URL batches.
- Manual Captcha Mode: Supports fallback if a captcha appears during execution.
- Batch Processing: Splits the workload across smaller CSV chunks to avoid memory or session issues.
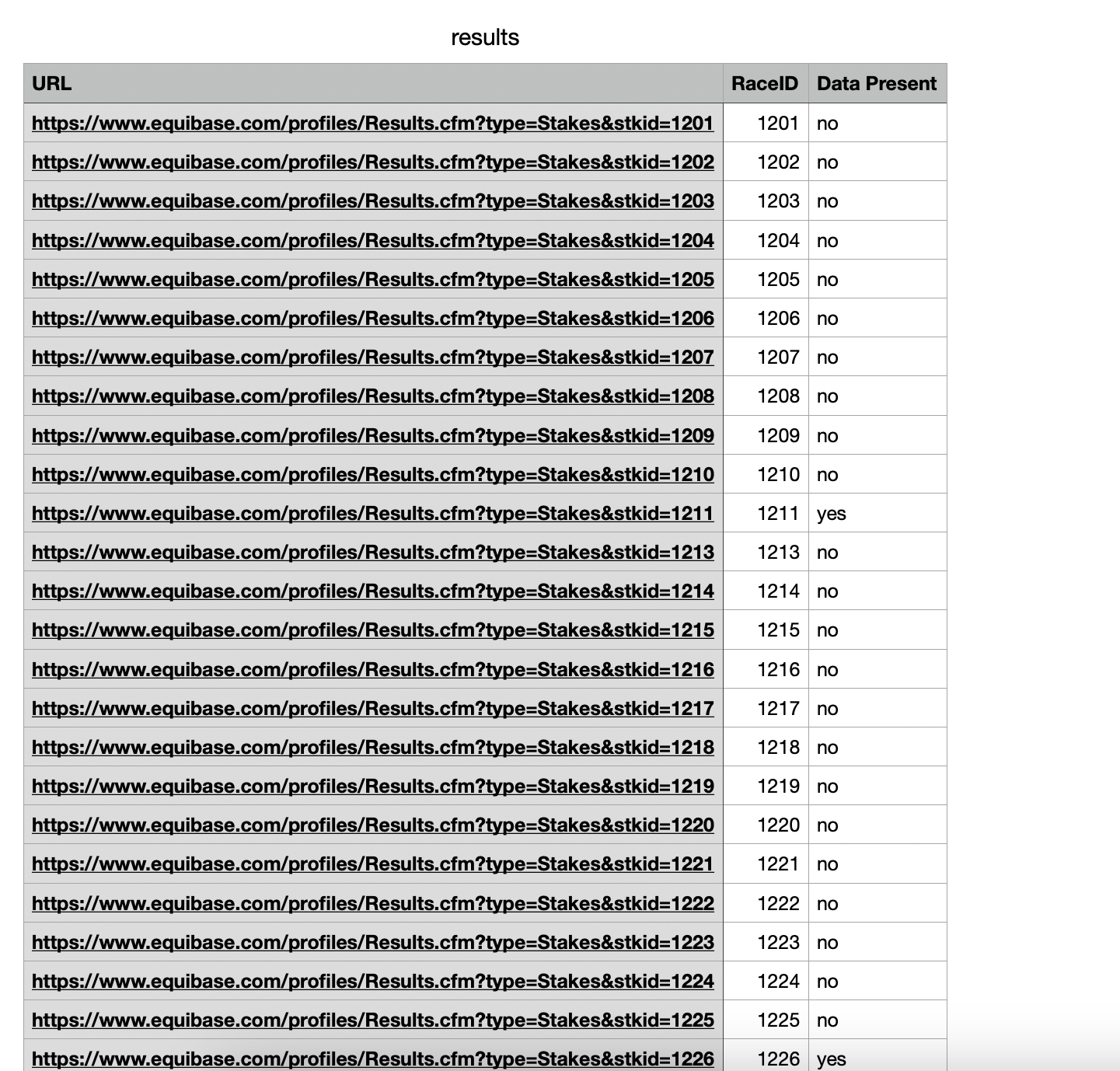
Output: Simple, Clear, and Actionable
Each row in the output CSV includes:
The original URL.
A "yes" or "no" label indicating whether the page is worth further inspection. i.e.,:
Final Thoughts
This tool has already saved me hours of manual inspection and allowed me to filter out tens of thousands of dead-end URLs with high precision. Whether you’re dealing with scraped web data or any large volume of dynamic content, having a smart, headless filter like this in your toolkit can make your workflow significantly more efficient—and a lot less painful.
Full repo can be found here: https://github.com/TheOxfordDeveloper/URL-checker.git