🙏 Thank You!
After the first article, I received a lot of really nice and positive feedback. It was super pleasant for me — it gave me the feeling that this topic might actually be interesting and useful for many of you, and it gave me huge motivation to continue working on it. Thanks to all of you for such great support! And please keep sharing your feedback and ideas with me — it helps me improve my work and bring more value for you. 😉
📝 Preface
This is the second article in the “Building Your Own Web Server” series. You can find the first one here:
👉 Part 1 — Theory and Foundation
At the beginning, I thought the best way to move forward would be to start directly with building the actual server: open a socket, handle a connection, receive a message… and then gradually add more functionality, like parsing HTML or working with a config file and implementing other server's approaches. That approach worked well enough, and I was planning to stick with it — but while working on it, I ran into a problem. The development process quickly became chaotic, less structured, and full of constant rewriting and refactoring. Maybe that’s fine for a learning exercise, but definitely not for building something solid — or writing about it in a clean way.
So I stopped and rethought the structure.
In the first article, we identified two essential parts of a web server:
HTTP parsing and server configuration. These are core features we’ll need no matter what kind of server we build — and while experimenting with different server architectures (blocking, multithreaded, and single-threaded non-blocking), I realized something:
These two parts stay the same. They don’t need to change.
That gave me a much better idea: instead of starting with the server, I’ll start by implementing these two independent services first.
I really liked this decision. It gives us a strong foundation — and more importantly, we’ll have two modular, reusable components that we can use later in every version of the server we build. It also lets us dig deeper into interesting topics like the structure of HTTP messages and a new concept (at least for me): lexical tokenization, which is heavily used in compilers.
And one more thing: in this article, I’ll also include a quick roadmap — a kind of overview of what we’re planning to build in the upcoming parts. That way you’ll know where we’re going and how each piece fits in.
So that’s it for the preface — let’s jump into the implementation. I hope you enjoy the article and that it gives you something useful or at least interesting. 😊
🔗 Full source code is available here:
📋 Implementation Plan
Here’s what we’re going to build — both in this article and the next ones.
1. Implement basic services of the web server
This article focuses on building two independent and reusable components:
- The HTTP parser
- The configuration parser
2. Implement server v1 and v2: blocking and multithreaded
In the next article, we’ll try to reach the point where we can run the first version of our web server — a single-threaded, blocking version. We’ll test its performance, and I’ll show you what kind of problems appear with a blocking thread. Then we’ll fix those issues by switching to a multi-threaded approach and see how it affects performance in different cases.
3. Implement server v3: I/O multiplexing
In the last article, I want to try a different approach — where a single thread works in a non-blocking way. We’ll talk about I/O multiplexing, Python’s selectors module, and how NGINX architecture works.
At the end, we’ll build the final version of the server based on this approach — and check how it performs.
So… let’s go! 🚀
🌐 HTTP Parser
Obviously, if we want to build a web server, we need something that helps us transform raw HTTP message bytes received from a socket into a structured and readable format. Of course, there are tons of libraries and packages that already do this — like http.server in Python. But hey — why use a ready-made solution when we can build our own? 😉
Let’s first define what exactly our parser should be responsible for.
It sounds simple: the parser should be able to receive data and return HTTP data in a structured format. But how should it receive that data? Should it have access to the socket? Or the connection? Should the input be in bytes or in str format?
These are the kinds of questions that come up when we start writing the implementation. Let’s break them down one by one — it’ll help us better understand what we’re building and how.
But how should the parser receive the data? Should it have access to the socket or the connection?
We want to keep our HTTP parser as independent as possible — that way, it’s reusable and separated from the server’s architecture. The server will be responsible for handling sockets and connections, and this logic might be very different depending on whether we’re using blocking, non-blocking, or async I/O.
So we don’t want the parser to depend on that. What we do want is to make sure the server handles everything related to getting the data, and the parser focuses only on parsing that data.
That means we want the parser to have one clear responsibility:
Take raw input data and return a parsed HTTP message.
⚠️ Important note: because of persistent connections, we can’t guarantee that the data received from the socket will contain a full HTTP message. That’s why we need to handle this case in our parser. Basically, we shouldn’t trust the received data blindly — the parser should try to extract one valid HTTP message from the input.
Also, in addition to returning the message itself, the parser should return the number of bytes it consumed — so that the server can know how much of the buffer was handled and how much is left.
And this answers the last question too:
We’ll work with bytes instead of strings — this makes it easier to track how much data we’ve processed.
Bellow I will show the code of implementation and provide comments to every interesting step.
from typing import Dict, Optional, Tuple
# -----------------------------------------------------------------------------
# Custom exception classes for precise error handling in our HTTP parser.
# -----------------------------------------------------------------------------
class IncompleteMessageError(Exception):
"""
Raised when the parser determines that the data buffer does not yet
contain a full HTTP message. Signals to the server: “this input is
valid so far, but you need to read more bytes before retrying parse.”
"""
pass
class InvalidMessageError(Exception):
"""
Raised when the parser finds a structural or syntactic problem in the
data buffer that cannot be fixed by reading more bytes. Signals to the
server: “this request is malformed—respond with an error (e.g. 400 Bad Request).”
"""
pass
class HTTPMessage:
"""
Represents a complete HTTP message (request or response).
Attributes:
method: HTTP method (e.g. 'GET', 'POST') or response status code.
url: Request target (e.g. '/index.html') or response reason phrase.
version: HTTP version (e.g. 'HTTP/1.1').
headers: dict of header-name (lowercased) → header-value.
body: Raw bytes of the message body.
"""
def __init__(
self,
method: str,
url: str,
version: str,
headers: Dict[str, str],
body: bytes
):
self.method = method
self.url = url
self.version = version
self.headers = headers
self.body = body
def __repr__(self):
snippet = self.body[:100] # preview first 100 bytes of body
return (
f"HTTPMessage(method={self.method!r}, url={self.url!r}, "
f"version={self.version!r}, headers={self.headers!r}, "
f"body={snippet!r}...)"
)
class HTTPParser:
"""
A simple HTTP message parser that can extract one message at a time
from a byte buffer.
Exceptions:
- IncompleteMessageError: the buffer is valid so far but incomplete.
- InvalidMessageError: the buffer is malformed and cannot be parsed.
"""
@staticmethod
def parse_message(data: bytes) -> Tuple[Optional[HTTPMessage], int]:
"""
Parse exactly one HTTP message from the start of `data`.
:param data: Bytes that may contain zero, one, or multiple messages.
:return: A tuple (message, bytes_consumed). If data is empty, (None, 0).
:raises IncompleteMessageError: headers or body are incomplete.
:raises InvalidMessageError: data is syntactically invalid.
"""
# --- A) Empty buffer: nothing to parse yet.
if not data:
return None, 0
# --- B) Locate end of headers ("\r\n\r\n").
sep = b"\r\n\r\n"
idx = data.find(sep)
if idx == -1:
# Missing header terminator → need more data.
raise IncompleteMessageError(
"Incomplete headers: missing CRLF CRLF separator."
)
# Split header block from potential body.
header_text = data[:idx].decode("iso-8859-1", errors="replace")
rest = data[idx + len(sep):]
# --- C) Break headers into lines.
lines = header_text.split("\r\n")
start_line = lines[0]
header_lines = lines[1:]
# --- D) Parse start line into method, URL/status, version.
parts = start_line.split(" ", 2)
if len(parts) != 3:
# Syntax error cannot be fixed by more data → invalid.
raise InvalidMessageError(f"Malformed start line: {start_line!r}")
method, url, version = parts
# --- E) Parse headers into dict.
headers: Dict[str, str] = {}
for line in header_lines:
if not line:
continue # skip stray blank lines
if ":" not in line:
raise InvalidMessageError(f"Bad header line: {line!r}")
name, value = line.split(":", 1)
headers[name.strip().lower()] = value.strip()
# --- F) Determine body length via Content-Length, if present.
length_hdr = headers.get("content-length")
if length_hdr is not None:
try:
length = int(length_hdr)
except ValueError:
# Non-integer length cannot be corrected → invalid.
raise InvalidMessageError(
f"Invalid Content-Length value: {length_hdr!r}"
)
if len(rest) < length:
# Not enough data for full body → incomplete.
raise IncompleteMessageError(
f"Body incomplete: expected {length} bytes, got {len(rest)}."
)
body = rest[:length]
consumed = idx + len(sep) + length
else:
# No Content-Length — assume no body (e.g. for GET, HEAD).
body = b""
consumed = idx + len(sep)
message = HTTPMessage(method, url, version, headers, body)
return message, consumedThe final full code of the http parser can be found here: https://github.com/DmytroHuzz/build_own_webserver/blob/main/http_parser.py. Now let’s move to the second service: the configuration parser.
⚙️ Configuration parser
💬 Preface
At first glance, this part seemed simple — at least to me. But once I started diving into the world of compilers and interpreters, reading up on parsing techniques, I quickly realized it’s actually a deep and surprisingly complex topic. Things like lexical analysis and token streams were new to me.
I started reading docs and searching for guides, but there weren’t many good explanations of how config parsers work under the hood. So I turned to source code — specifically, the NGINX source: src/core/ngx_conf_file.c. That’s where I first came across the idea of lexical analysis, which became my starting point.
From there, with some help from ChatGPT to validate my findings, I pieced things together. What started as a “simple” part of the project turned into the most interesting and insightful one for me. Now I want to share what I learned with you — and I hope it will be just as fun for you to follow.
🧾 Requirements
The web server requires to have some part of functionality configurable. To this functionality relate: listening port, rules for routing included URI and resource locations and far more. To implement this requirements Nginx uses configuration file with strictly specific format. Here is possible to read in very details about that format of configuration file in Nginx: https://nginx.org/en/docs/beginners_guide.html#conf_structure.
From the same source we can take the basic description about format of the configuration file:
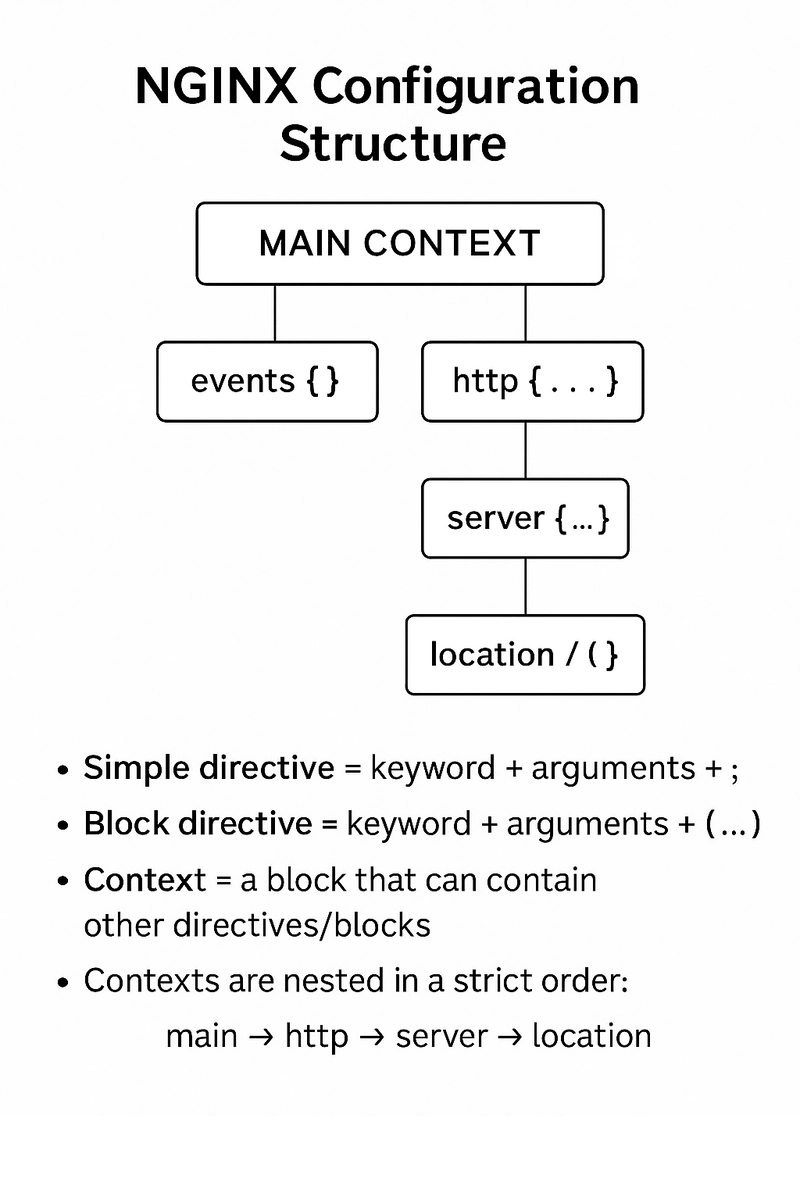
Configuration File’s Structure
nginx consists of modules which are controlled by directives specified in the configuration file. Directives are divided into simple directives and block directives. A simple directive consists of the name and parameters separated by spaces and ends with a semicolon (
;). A block directive has the same structure as a simple directive, but instead of the semicolon it ends with a set of additional instructions surrounded by braces ({and}). If a block directive can have other directives inside braces, it is called a context (examples: events, http, server, and location).Directives placed in the configuration file outside of any contexts are considered to be in the main context. The
eventsandhttpdirectives reside in themaincontext,serverinhttp, andlocationinserver.The rest of a line after the
#sign is considered a comment.
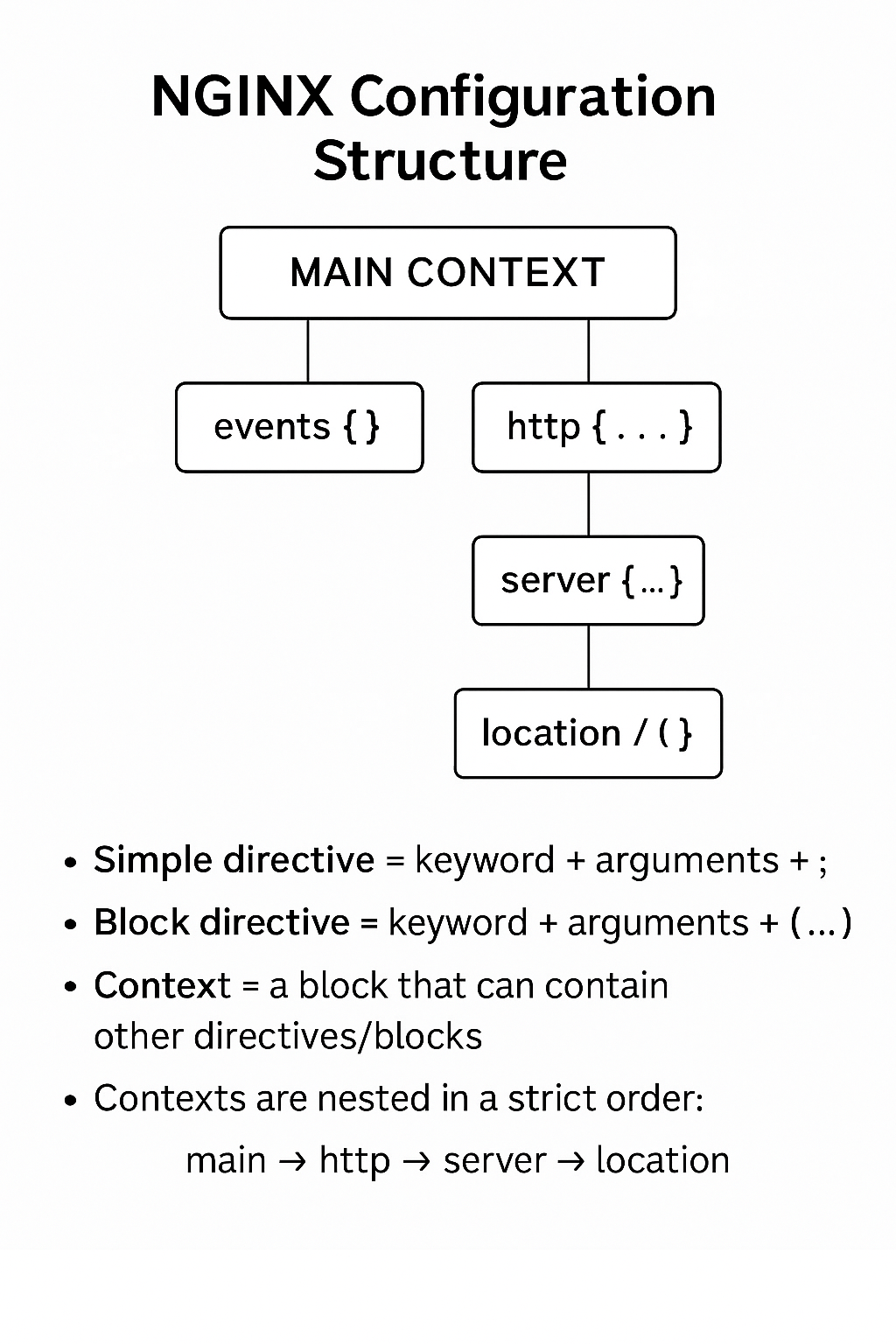
We will take this description as a specification and will implement the same format. As we agreed in our requirements, we will start simple and implement first serving static files only. At the beginning we will start only with a few basic directives and its configurations.
We will implement the server directive which is responsible for server’s settings. And define there next configurations: listen and location. So we can define the port which server should listen and routing rules.
http {
server {
listen 8080;
location / {
root /data/www;
}
}
}First of all, we will start with creating a parser for the defined format. And after that we can test the parser with our basic configuration file.
Configuration Parsing, Part 1: Lexer
In this part, we’re going to implement the first step of our configuration parsing system: the lexer. But before we dive into code, let’s clarify how the config parsing process works overall.
1. Overview: Configuration Parsing System
Our configuration parser consists of three main parts:
- Lexer – reads raw configuration text and breaks it into tokens (words, symbols, etc.).
- Parser – takes those tokens and builds a structured, nested configuration.
- ServerConfig – the resulting object that our server code will use to access config values.
This design may seem overkill for a small project, but it has clear benefits:
- Each part does one thing and is easy to test.
- Parsing becomes less error-prone and easier to understand.
- We follow the same approach real servers like NGINX use, which makes the system more realistic and extensible.
In next part, we’ll focus on implementing the lexer.
2. Lexer Implementation
What Is a Lexer?
The lexer (or tokenizer) is the first component that reads the raw config file line by line and splits it into tokens.
For example, this input:
server {
listen 8080;
location / {
root /data/www;
}
}Will be split into a sequence of tokens like:
WORD(server)
LBRACE({
WORD(listen)
WORD(8080)
SEMICOLON(;)
...Why Do We Need It?
While it’s possible to parse the config text directly, separating the lexer gives us better structure and separation of concerns. The lexer removes irrelevant details (like whitespace or comments) and leaves us with a clean, uniform stream of tokens to work with.
This makes the parser’s job significantly easier.
3. Python Implementation
Here’s a simple lexer class that extracts relevant tokens. I tried to add explicit comments to every block of the code, so that it should be clear how it works.
import re
from typing import List, Tuple
# Each token is represented as a tuple: (type, value)
Token = Tuple[str, str]
class SimpleConfigLexer:
"""
A basic lexer for NGINX-style config files.
It recognizes:
- comments (starting with #)
- symbols: { } ;
- quoted strings
- plain words: directives, numbers, paths
"""
TOKEN_PATTERNS = [
("COMMENT", r"#.*"),
("LBRACE", r"\{"),
("RBRACE", r"\}"),
("SEMICOLON", r";"),
("STRING", r'"[^"]*"'),
("WORD", r"[a-zA-Z0-9_./\-]+"),
("WHITESPACE", r"[ \t\r\n]+"),
]
def __init__(self, config_text: str):
self.config_text = config_text
self.tokens = self.tokenize()
def tokenize(self) -> List[Token]:
pattern = "|".join(f"(?P<{name}>{regex})" for name, regex in self.TOKEN_PATTERNS)
token_re = re.compile(pattern)
pos = 0
tokens: List[Token] = []
while pos < len(self.config_text):
match = token_re.match(self.config_text, pos)
if not match:
raise SyntaxError(f"Unexpected character at position {pos}: {self.config_text[pos]!r}")
kind = match.lastgroup
value = match.group()
if kind in ("WHITESPACE", "COMMENT"):
pass # skip it
elif kind == "STRING":
tokens.append((kind, value.strip('"'))) # remove quotes
else:
tokens.append((kind, value))
pos = match.end()
return tokens4. Testing the Lexer
Let’s run a quick test to see how it works.
config_text = '''
server {
listen 8080;
location / {
root /var/www;
}
}
'''
lexer = SimpleConfigLexer(config_text)
for token_type, value in lexer.tokens:
print(f"{token_type:<10} -> {value}")Output:
WORD -> server
LBRACE -> {
WORD -> listen
WORD -> 8080
SEMICOLON -> ;
WORD -> location
WORD -> /
LBRACE -> {
WORD -> root
WORD -> /var/www
SEMICOLON -> ;
RBRACE -> }
RBRACE -> }5. Optional: Visualizing the Token Stream
Here’s a simple helper function to visualize the nesting structure. It doesn’t parse the config yet, but it gives us a good idea of where blocks open and close.
def visualize_token_stream(tokens: List[Token]) -> None:
indent = 0
for token_type, value in tokens:
if token_type == "RBRACE":
indent -= 1
print(" " * indent + f"{token_type:10}: {value}")
if token_type == "LBRACE":
indent += 1Example output:
WORD : server
LBRACE : {
WORD : listen
WORD : 8080
SEMICOLON : ;
WORD : location
WORD : /
LBRACE : {
WORD : root
WORD : /var/www
SEMICOLON : ;
RBRACE : }
RBRACE : }This shows block structure in a readable way without needing a full parser yet.
🛠 Configuration Parsing, Part 2: Parser
We now have a working lexer, which takes a raw config file and splits it into a list of tokens. Now we’ll implement the parser — the part that takes that token stream and transforms it into a structured object the server can actually use.
1. What the Parser Does
The parser takes a flat list of tokens and builds a nested configuration tree based on blocks and directives.
Example config:
http {
server {
listen 8080;
location / {
root /data/www;
}
}
}The parser will convert this into something like:
{
"http": {
"server": {
"listen": "8080",
"location": {
"/": {
"root": "/data/www"
}
}
}
}
}This structure will later be used to create a ServerConfig object or whatever internal structure we want.
2. How the Parser Works (Conceptual Overview)
The parser uses a technique called recursive descent. It walks through the list of tokens one by one, and:
- When it sees a key followed by
{, it knows it's starting a block, and calls itself recursively to parse that block. - When it sees a key followed by one or more values and then
;, it stores them as a directive. - When it sees arguments before
{, it understands it's a block with arguments (e.g.,location / {).
Note on context validation: This parser is designed for educational clarity and intentionally does not. While real-world servers like NGINX enforce these rules, we chose to skip this complexity here to focus on the core parsing logic.
Here's a visual breakdown:
[WORD] → key
|
|-- [WORD] + [LBRACE] → block with arguments
| → assign key: { arg: { nested config } }
|
|-- [LBRACE] → block without arguments
| → assign key: { nested config }
|
|-- [WORD(s)] + SEMICOLON → directive
→ assign key: value or list of valuesNote: While our parser technically supports blocks with multiple arguments (like
WORD WORD WORD {), such constructs are not valid in real NGINX configurations. To stay faithful to NGINX-style syntax, we assume that a block can have at most one argument (e.g.,location / {). You can easily enforce this by validating the number of arguments if needed.
3. Parser Implementation (Step-by-Step)
Now we’re getting into the core part of the parser. I know — at first glance, the code might look long or even a bit intimidating. But don’t worry. I encourage you to take your time and walk through it slowly.
I’ve added detailed comments throughout the code to make each part as clear as possible. If something still feels confusing or unclear, feel free to ask questions in the comments — I’ll do my best to explain or improve it further.
And if you still feel a bit lost, that’s okay too. You can treat this parser as a black box for now — understanding the overall idea is enough to follow the rest of the article. The full implementation is here mostly for those who want to dig into the internals.
from typing import List, Tuple, Union
# A token is a pair: (type, value), e.g. ("WORD", "listen")
Token = Tuple[str, str]
# The parsed config will be a nested dictionary structure
ConfigDict = dict[str, Union[str, "ConfigDict", list]]
class SimpleConfigParser:
"""
Parses a list of tokens into a nested configuration dictionary.
This parser assumes a simplified NGINX-style format where:
- Each line is either a directive (ends with ';') or a block (enclosed in { ... }).
- Blocks can be nested.
- Blocks may take one argument (e.g. 'location / { ... }').
"""
def __init__(self, tokens: List[Token]):
self.tokens = tokens
self.pos = 0 # keeps track of which token we're currently parsing
def parse(self) -> ConfigDict:
"""
Entry point: parse the full list of tokens and return a nested dictionary.
This handles the top-level of the configuration (e.g., the main context).
"""
return self._parse_block()
def _parse_block(self) -> ConfigDict:
"""
Parses a block of configuration. This is a recursive function:
- Called when entering a new { ... } block.
- Returns a dictionary representing the contents of that block.
"""
config: ConfigDict = {}
while self.pos < len(self.tokens):
token_type, token_value = self.tokens[self.pos]
# If we reach a closing brace, it means the current block is finished.
if token_type == "RBRACE":
self.pos += 1 # consume the '}'
return config
# Each line must start with a directive or block name (a WORD).
if token_type != "WORD":
raise SyntaxError(f"Expected directive name (WORD), but got {token_type} '{token_value}'")
# Save the directive or block name.
key = token_value
self.pos += 1 # move to the next token
args = [] # used to collect parameters like '8080' or '/'
# Now we gather the rest of the tokens for this line,
# which will be either:
# - a list of arguments followed by a SEMICOLON (simple directive),
# - or a list of arguments followed by LBRACE (start of a nested block).
while self.pos < len(self.tokens):
t_type, t_value = self.tokens[self.pos]
if t_type == "LBRACE":
# We’ve found a new block. This is something like:
# location / { ... }
if len(args) > 1:
raise SyntaxError(f"Block '{key}' can only have one argument. Found: {args}")
self.pos += 1 # consume the '{'
block = self._parse_block() # recursively parse what's inside
if args:
# Example: location / { ... }
# We treat 'location' as the key and '/' as a subkey.
arg_key = args[0]
if key not in config:
config[key] = {}
if not isinstance(config[key], dict):
raise SyntaxError(f"Cannot nest block under non-dictionary directive '{key}'")
config[key][arg_key] = block
else:
# Example: server { ... }
# If there are multiple server blocks, store them as a list.
if key in config:
if isinstance(config[key], list):
config[key].append(block)
else:
config[key] = [config[key], block]
else:
config[key] = block
break # done processing this block directive
elif t_type == "SEMICOLON":
# We've reached the end of a simple directive like:
# listen 8080;
self.pos += 1 # consume the ';'
value = args[0] if len(args) == 1 else args
# If the same directive appears multiple times, store values in a list.
if key in config:
if isinstance(config[key], list):
config[key].append(value)
else:
config[key] = [config[key], value]
else:
config[key] = value
break # done processing this simple directive
elif t_type != "WORD":
# We only expect WORDs as arguments before we hit '{' or ';'
raise SyntaxError(f"Unexpected token in argument list: {t_type} '{t_value}'")
else:
# This is an argument — e.g., the '8080' in `listen 8080;`
args.append(t_value)
self.pos += 1
# If we exited the loop without encountering RBRACE (in a block) or SEMICOLON (in root), that's invalid.
else:
raise SyntaxError(f"Unexpected end of input after key '{key}' — expected ';' or '{{'.")
# If we reached the end of the token stream (top-level block), return what we've built so far.
return config4. Example Walkthrough
Let's walk through what happens when parsing this block:
http {
server {
listen 8080;
location / {
root /data/www;
}
location /static {
root /data/static;
}
}
server {
listen 8081;
location / {
root /data/api;
}
}
}Step-by-Step Parsing
- Parser sees http followed by { → enters a block.
- Inside http:
- Sees server + { → enters a new server block
- Parses listen 8080; → adds "listen": "8080"
- Parses location / { root /data/www; } → nested block under location with path /
- Parses location /static { root /data/static; } → second block under location with path /static
- Sees another server block → enters second server
- Parses listen 8081; → "listen": "8081"
- Parses location / { root /data/api; }
- Sees server + { → enters a new server block
Final structure:
{
"http": {
"server": [
{
"listen": "8080",
"location": {
"/": {
"root": "/data/www"
},
"/static": {
"root": "/data/static"
}
}
},
{
"listen": "8081",
"location": {
"/": {
"root": "/data/api"
}
}
}
]
}
}🛠 Configuration Parsing, Part 3: ServerConfig Object
Now that we’ve built the lexer and parser, which convert a raw config file into a structured nested dictionary, we’ll take the final step: wrapping that dictionary in a clean interface called ServerConfig.
1. Why Wrap the Dictionary?
The parser gives us a powerful structure like:
{
"http": {
"server": [
{
"listen": "8080",
"location": {
"/": {
"root": "/data/www"
}
}
},
{
"listen": "8081",
"location": {
"/": {
"root": "/data/alt"
}
}
}
]
}
}That’s great — but working directly with raw dictionaries is messy.
We’d rather write:
config.listen_ports
config.routesThan:
config["http"]["server"][0]["location"]["/"]["root"]2. What Will ServerConfig Do?
- Provide typed, user-friendly access to key values.
- Handle optional and default values gracefully.
- Expose common patterns (like mapping ports to route trees).
- Hide the nested structure from the rest of the server logic.
3. Full Implementation of ServerConfig
class ServerConfig:
"""
Wraps parsed configuration into a higher-level object with useful accessors.
This class makes it easier to access settings like ports and routes.
Expected format: output of SimpleConfigParser.parse()
"""
def __init__(self, config_dict: dict):
self.config = config_dict
def get_servers(self) -> list[dict]:
"""
Returns a list of server blocks inside the http block.
Handles:
- No 'http' block present
- One or more server blocks (as object or list)
"""
http_block = self.config.get("http", {})
servers = http_block.get("server", [])
if isinstance(servers, dict):
return [servers] # single server block
return servers # list of servers or empty
@property
def listen_ports(self) -> list[int]:
"""
Extracts all port numbers from server blocks.
Assumes port is defined via 'listen' directive.
"""
ports = []
for server in self.get_servers():
port = server.get("listen")
if port:
try:
ports.append(int(port))
except ValueError:
raise ValueError(f"Invalid port number: {port!r}")
return ports
@property
def routes(self) -> dict[int, dict[str, str]]:
"""
Builds a routing table for each server block.
Returns a mapping like:
{
8080: {"/": "/data/www"},
8081: {"/": "/data/alt"}
}
It pulls 'root' directive from 'location' blocks.
"""
mapping = {}
for server in self.get_servers():
port = int(server.get("listen", 80)) # default fallback
route_map = {}
location_block = server.get("location", {})
for path, inner in location_block.items():
if isinstance(inner, dict) and "root" in inner:
route_map[path] = inner["root"]
mapping[port] = route_map
return mapping4. Usage Example
Let’s see how you’d use ServerConfig in practice:
config = ServerConfig(parsed_dict)
print(config.listen_ports)
# → [8080, 8081]
print(config.routes)
# → {8080: {"/": "/data/www"}, 8081: {"/": "/data/alt"}}Much simpler than traversing a raw nested dictionary!
5. One-Liner Wrapper Function:
load_config()
Here’s a function that brings everything together:
def load_config(path: str) -> ServerConfig:
"""
Reads a config file, tokenizes and parses it, then wraps in ServerConfig.
"""
with open(path, "r", encoding="utf-8") as f:
config_text = f.read()
lexer = SimpleConfigLexer(config_text)
parser = SimpleConfigParser(lexer.tokens)
parsed_dict = parser.parse()
return ServerConfig(parsed_dict)Now in your server, you can do:
config = load_config("server.conf")…and get a full parsed, typed configuration object.
And the full implementation you can find here: https://github.com/DmytroHuzz/build_own_webserver/blob/main/config_parser.py
We’ve completed our configuration system! The full pipeline is:
- Lexer – splits raw config text into tokens
- Parser – builds nested dictionary from tokens
- ServerConfig – gives user-friendly access to config values
This modular approach mirrors how real servers like NGINX parse their config files — but with an implementation that’s small, clean, and easy to understand.
🧩 Wrapping Up
In this article, we built two critical components of our web server infrastructure: an HTTP parser and a configuration parser. These foundational tools will support every version of the server we build later — from simple blocking to advanced non-blocking architectures.
Here’s what we accomplished:
- Implemented a robust HTTP parser that can handle incomplete or malformed requests — a must-have for real-world networking.
- Built a config parser pipeline consisting of:
- A lexer to tokenize raw config text
- A parser that constructs a structured, nested dictionary
- A clean ServerConfig wrapper for easy access to ports and routing
By separating each component clearly, we’ve made our system modular, testable, and much easier to extend — just like in production-grade servers like NGINX.
In the next article, we’ll use these building blocks to implement our first working server: a single-threaded, blocking web server. We’ll measure its performance, understand its limitations, and prepare for more scalable designs.
Thanks again for reading — and feel free to share your thoughts, questions, or improvements!
