
This is a Plain English Papers summary of a research paper called Complex Image Editing Gets Real: New Benchmark Tests Limits, Uses GPT-4o. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Challenge of Complex Image Editing Instructions
Current image editing models are trained and evaluated mainly on simple instructions like "remove the car" or "change the sky to blue." But real-world editing tasks often demand more complex instructions such as "replace the car with a blue bus featuring an iPhone advertisement on its side." This gap between simple test benchmarks and complex real-world needs limits our ability to properly assess editing models.
To address this challenge, researchers have introduced Complex-Edit, a comprehensive benchmark designed to systematically evaluate instruction-based image editing models across varying levels of complexity. This benchmark leverages GPT-4o to automatically generate diverse editing instructions at different complexity levels.

An overview of the Complex-Edit data collection pipeline with three distinct stages: generating atomic instructions, simplifying them, and combining them into complex instructions.
The researchers' key contributions include:
- A novel data generation pipeline that creates complexity-controllable editing instructions
- A comprehensive evaluation framework with metrics for instruction following, identity preservation, and perceptual quality
- Insights about how models perform when facing increasingly complex instructions
Creating Complex-Edit: A Three-Stage Pipeline for Complex Instruction Generation
The Complex-Edit dataset creation follows a structured three-stage pipeline designed to generate editing instructions of controllable complexity.
Starting with Atomic Operations: Sequence Generation Stage
In the first stage, 24 distinct atomic operations are defined, representing the basic actions of image editing. These operations fall into 9 categories that capture different aspects of image editing:
- Object Manipulation and Transformation (add, remove, replace objects)
- Color and Tone Adjustments
- Texture and Material Adjustments
- Background and Environment
- Lighting and Shadows
- Text and Symbols
- Composition and Cropping
- Pose and Expression
- Special Effects

The distribution of atomic instructions among 9 operation categories. Arc thickness between categories indicates the frequency of adjacent instructions from these categories.
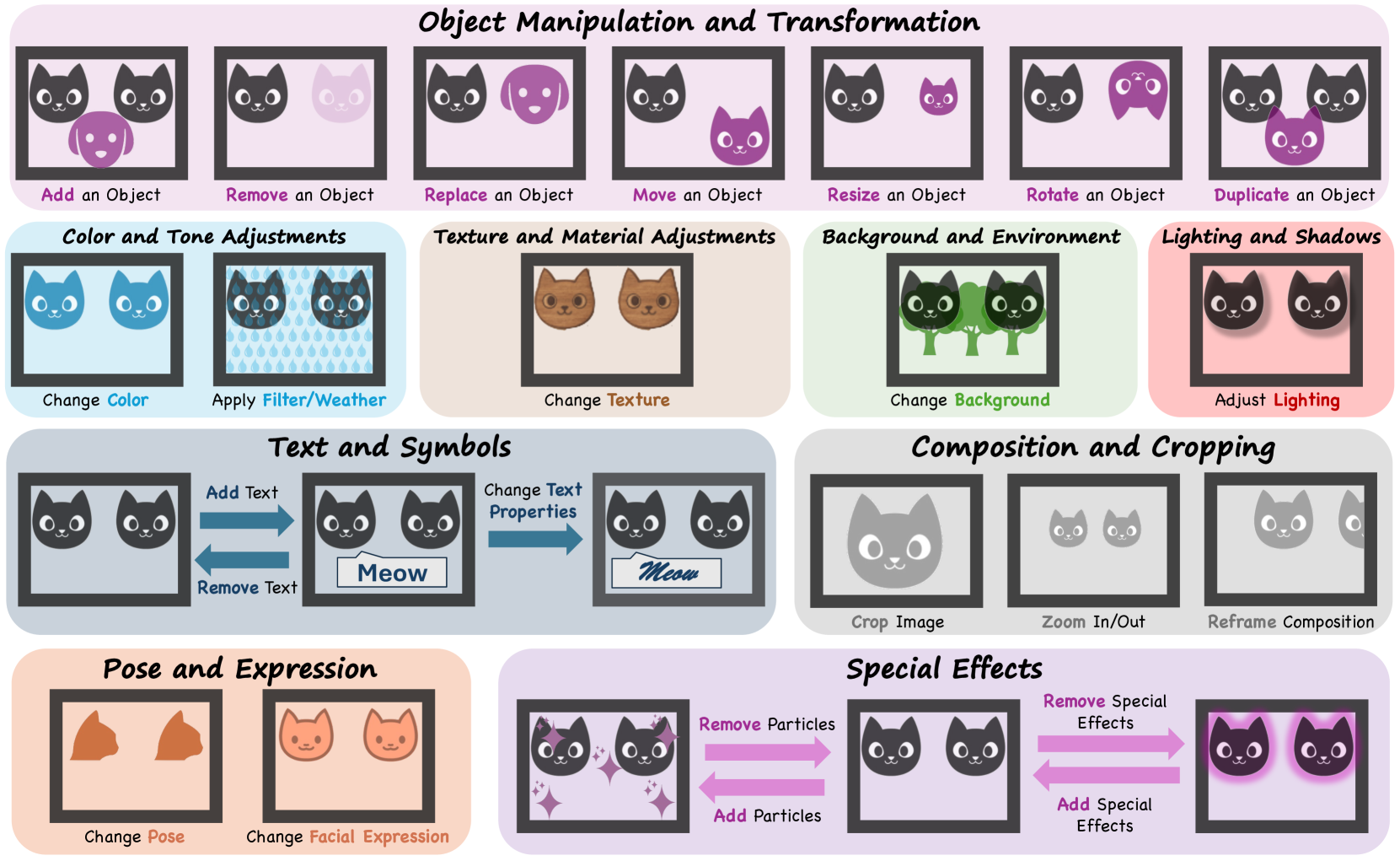
An illustration of the 24 types of atomic editing operations organized into 9 categories.
For each input image, GPT-4o generates a sequence of atomic instructions based on these predefined operation types. Each instruction corresponds to one atomic operation and adheres to a predetermined length.
Refining Instructions: The Simplification Stage
The GPT-generated atomic instructions sometimes contain unnecessary details or commentary about the editing operations. For instance, an instruction might read: "To enhance the photo's playfulness, add a ball of yarn for the cat to play with."
Since the benchmark aims to evaluate performance on clear and concise instructions, a dedicated simplification stage eliminates superfluous content. GPT-4o examines each instruction and outputs a simplified version that preserves only the essential editing directive, such as "Add a ball of yarn."
Building Complexity: The Instruction Compounding Stage
In the final stage, simplified atomic instructions are combined to form compound instructions of varying complexity. Given a sequence of N atomic instructions, N compound instructions are generated, each corresponding to a different complexity level:
- Complexity level C₁: The first atomic instruction alone (simplest)
- Complexity level C₂: The first two atomic instructions combined
- ...and so on until...
- Complexity level C_N: All N atomic instructions integrated (most complex)
Rather than simply concatenating instructions, GPT-4o seamlessly integrates them into coherent complex instructions. For example, instead of "add a ball of yarn" followed by "change the color of the yarn to red," the compound instruction becomes "add a red ball of yarn."
Technical Implementation: Making the Pipeline Work
To ensure GPT-4o fully understands the objectives at each stage, the researchers:
- Constructed multiple few-shot examples for each stage
- Enabled Chain-of-Thought reasoning for the Sequence Generation and Instruction Compounding stages
- Increased the sampling temperature from 1.0 to 1.15 during Sequence Generation to improve diversity
- Implemented rule-based filtration to detect and regenerate flawed outputs
Evaluating Image Editing Quality: A Comprehensive Framework
Building on prior work in instruction-following image editing, the researchers developed a comprehensive evaluation framework that employs Vision Language Model (VLM)-based autograders for large-scale assessment.
Measuring What Matters: Designing Effective Metrics
The evaluation framework focuses on two primary dimensions:
- Alignment: whether the output image reflects the changes specified by the editing instruction
- Perceptual quality: whether the output image looks aesthetically pleasing and free of visual artifacts
Balancing Instructions and Identity: The Alignment Metrics
Unlike previous frameworks that measure alignment as a single metric, Complex-Edit decomposes it into two complementary criteria:
- Instruction Following (IF): Measures whether the specified modifications appear in the output image
- Identity Preservation (IP): Assesses whether elements that should remain unchanged are preserved

Examples of evaluation results for Instruction Following and Identity Preservation, showing how different models perform on these metrics.
These criteria correspond roughly to the directional CLIP similarity and image-wise CLIP similarity metrics used in earlier studies. For evaluation, the VLM receives a triplet containing the input image, output image, and editing instruction.
Beyond Accuracy: Assessing Perceptual Quality
The Perceptual Quality (PQ) metric examines factors such as:
- Consistency in lighting and shadows
- Style coherence
- Seamless integration of elements
Interestingly, the researchers discovered that providing editing instructions to VLMs when evaluating perceptual quality actually reduces the correlation between VLM and human evaluations. Therefore, for PQ evaluation, only the edited image is supplied to the VLM autograder.

Examples of evaluation results for Perceptual Quality, illustrating how this metric captures the overall visual harmony of edited images.
Pulling It All Together: Computing the Overall Score
The overall score (O) is calculated as the arithmetic mean of the three metrics:
O = (IF + IP + PQ) / 3
Robust Metric Calculation Methods
The researchers explored different approaches to calculate metrics reliably.
Comparing Scoring Approaches: Numeric vs. Token Probability
Two methods for computing metrics were compared:
- Numeric scoring: The VLM assigns a score between 0 and 10 for each metric
- Token probability: The evaluation is reformulated as a binary classification task with a yes-or-no question, calculating the score as the normalized token probability for the affirmative response
| Deterministic | Correlation | ||
|---|---|---|---|
| IF | IP | PQ | |
| 0.468 | 0.530 | 0.234 | |
| ✓ | 0.461 | 0.507 | 0.215 |
Table 1: Random sampling vs Discriminative sampling, showing correlation values for different metrics.
Guiding Evaluation: The Importance of Detailed Rubrics
The researchers designed comprehensive rubrics for each metric to guide evaluation and improve result interpretability. Each rubric provides detailed descriptions for scores from 0 to 10, often with textual examples to reduce ambiguity.
| Scoring Method | CoT | Rubric | Correlation | ||
|---|---|---|---|---|---|
| IF | IP | PQ | |||
| Token Prob | 0.411 | 0.366 | 0.136 | ||
| Token Prob | ✓ | 0.447 | 0.460 | 0.158 | |
| Numeric | 0.434 | 0.450 | 0.207 | ||
| Numeric | ✓ | 0.446 | 0.451 | 0.234 | |
| Numeric | ✓ | ✓ | 0.468 | 0.530 | 0.208 |
| CLIP_dir | CLIP_img | ||||
| 0.182 | 0.523 |
Table 2: Results from different scoring methods, showing that numeric scoring with rubrics and Chain-of-Thought (CoT) works best for IF and IP, while numeric scoring with rubrics but without CoT works best for PQ.
Ensuring Consistency: Addressing Per-sample Variance
Advanced proprietary VLMs like GPT-4o can produce score variations for individual samples across different runs. While averaging over many samples mitigates discrepancies at the dataset level, per-sample stability is crucial for test-time scaling.
To enhance stability, the researchers adopted an approach that averages scores from multiple independent evaluations. Their analysis showed that 20 measurements per sample provides optimal stability.
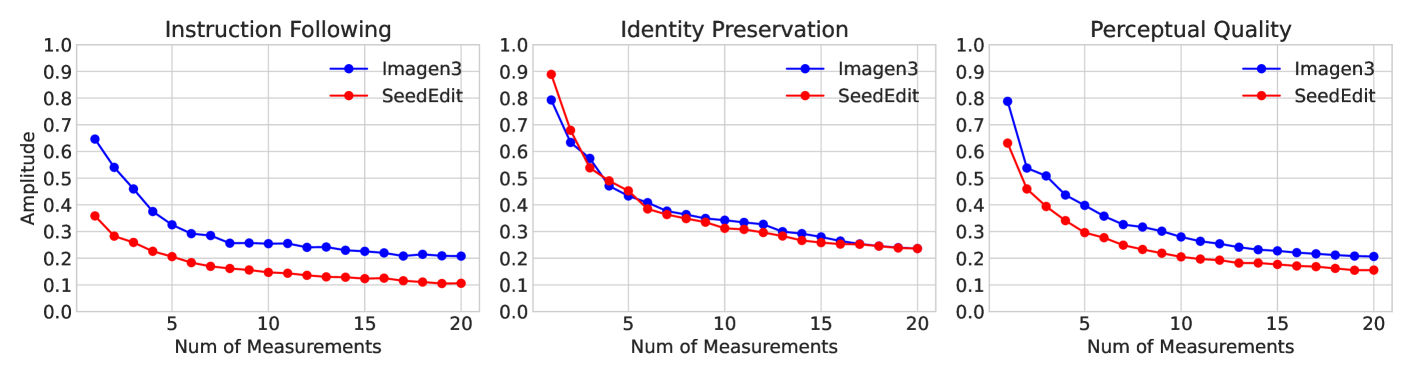
Relationship between per-sample variance and the number of measurements, showing convergence at around 20 measurements.
Validating the Evaluation Framework: Meta-Evaluation
To ensure the reliability of their evaluation framework, the researchers conducted a meta-evaluation to assess how well their metrics aligned with human judgments.
Aligning with Human Judgment: Correlation Analysis
Rather than asking human raters to assign consistent numeric scores across diverse samples, the researchers presented pairs of output images for each input image and editing instruction, asking raters to compare them with respect to each metric. They then computed the correlation between human comparisons and the differences in corresponding metric scores.
For this meta-evaluation, they sampled 100 output images for each complexity level from C₁ to C₈ using both Imagen3 and SeedEdit, resulting in 800 image pairs. Each pair was annotated by at least two human raters.
Key findings from the meta-evaluation:
- Numeric scoring yields higher correlation with human evaluation than token probability methods
- Supplementing numeric scoring with detailed rubrics consistently improves correlation
- Chain-of-Thought (CoT) reasoning doesn't consistently enhance metric correlation, and negatively affects correlation for Perceptual Quality
- Including editing instructions when evaluating Perceptual Quality dramatically reduces correlation with human evaluations
- The arithmetic mean for combining metrics produces a higher correlation with human judgments than the geometric mean
- The proposed metrics exhibit higher correlations with human evaluations compared to established CLIP-based metrics
Results and Insights: What We Learned from Complex-Edit
The Complex-Edit benchmark provides several important insights into how image editing models handle complex instructions.
The Experiment: Models, Data, and Setup
The Complex-Edit dataset comprises both realistic and synthetic images:
- 531 deduplicated images from the EMU-Edit test set serve as realistic images
- An equivalent set of 531 synthetic images generated by FLUX.1 based on captions from EMU-Edit
Each image has editing instructions with complexity levels ranging from C₁ (simplest) to C₈ (most complex).
Five instruction-based image editing models were evaluated:
- Three open-source models: UltraEdit, OmniGen, and AnyEdit
- Two proprietary models: Imagen3 and SeedEdit
- Additionally, GPT-4o was evaluated on a subset of realistic images at complexity level C₈
| Model | Prop. of Real Images | Realistic Style | IF | IP | PQ | O |
|---|---|---|---|---|---|---|
| UltraEdit | ✓ | ★ | 6.56 | 5.93 | 7.29 | 6.59 |
| OmniGen | ✓✓✓ | ★★★★★ | 6.25 | 6.42 | 7.54 | 6.74 |
| AnyEdit | ✓✓✓ | ★★★★ | 1.60 | 8.15 | 7.25 | 5.67 |
| SeedEdit | ✓ | ★★ | 8.49 | 6.91 | 8.74 | 8.04 |
| Imagen3 | ? | ★ | 7.56 | 6.55 | 7.67 | 7.26 |
| GPT4o | ? | ★★ | 9.29 | 7.51 | 9.47 | 8.76 |
Table 3: Evaluation results with direct editing on real images with instruction complexity at C₈, showing GPT-4o outperforming other models overall.
Complexity Challenges: How Increasing Instruction Complexity Affects Performance
One of the key findings from Complex-Edit is that as instruction complexity increases, model performance generally decreases, with open-source models showing a wider performance gap compared to proprietary models.
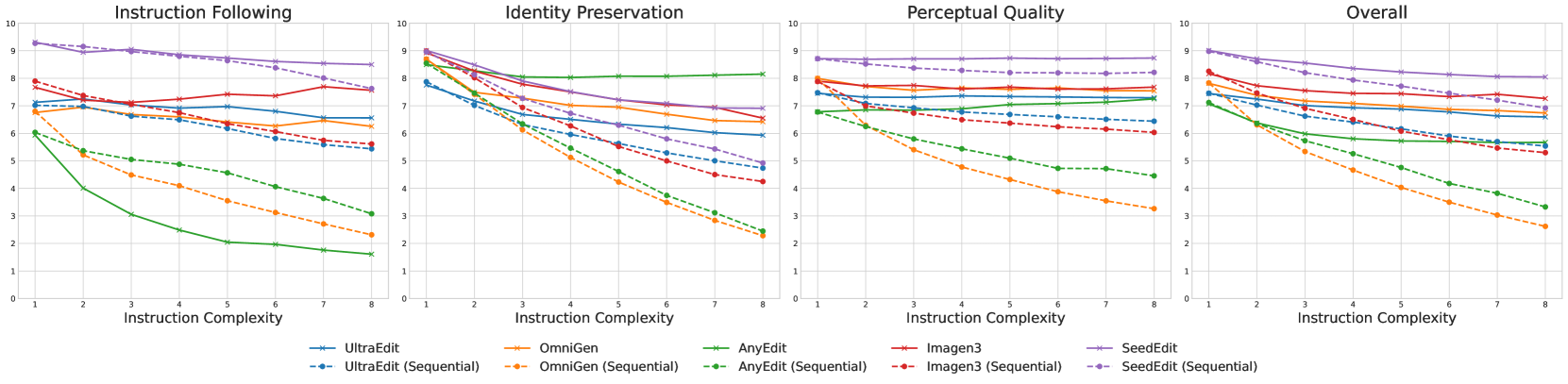
Results for direct and sequential editing on real-life input images across complexity levels from C₁ to C₈. Note how performance metrics decline as complexity increases.
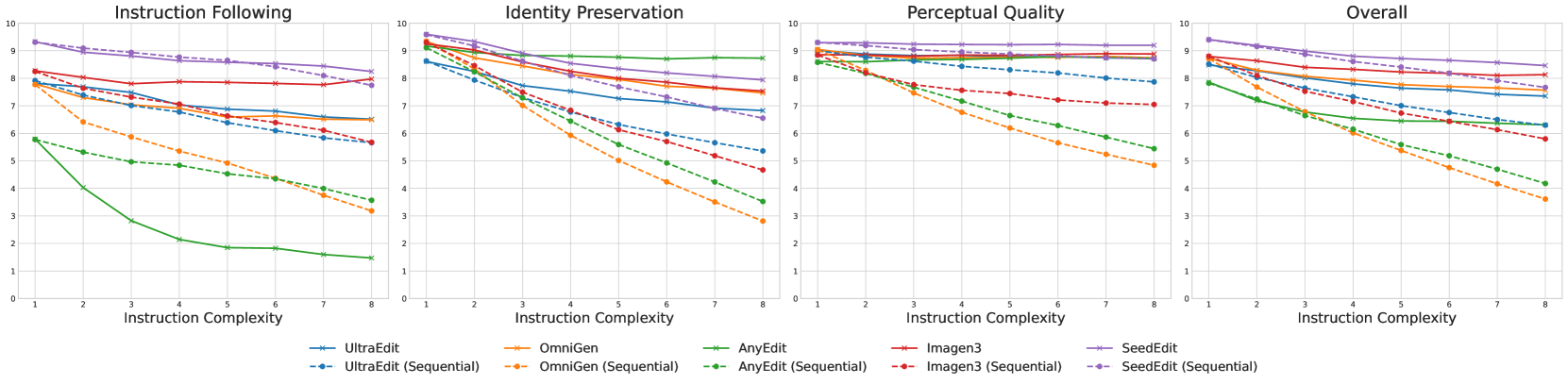
Results for direct and sequential editing on synthetic input images across complexity levels from C₁ to C₈, showing similar trends as with real images.
The results show that:
- Open-source models significantly underperform compared to proprietary models
- The performance gap widens as instruction complexity increases
- Increased instruction complexity mainly affects Identity Preservation (IP) and Perceptual Quality (PQ)
- The impact on Instruction Following (IF) varies across models
| Model | C₁ | C₈ | C₈-C₁ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IF | IP | PQ | O | IF | IP | PQ | O | Δ_IF | Δ_IP | Δ_PQ | Δ_O | |
| UltraEdit | 7.13 | 7.76 | 7.45 | 7.45 | 6.56 | 5.93 | 7.29 | 6.59 | -0.57 | -1.82 | -0.16 | -0.85 |
| OmniGen | 6.76 | 8.69 | 7.99 | 7.82 | 6.25 | 6.42 | 7.55 | 6.74 | -0.50 | -2.27 | -0.45 | -1.07 |
| AnyEdit | 5.94 | 8.50 | 6.78 | 7.07 | 1.61 | 8.15 | 7.25 | 5.67 | -4.33 | -0.34 | +0.47 | -1.40 |
| Imagen3 | 7.67 | 8.93 | 7.90 | 8.17 | 7.56 | 6.55 | 7.68 | 7.27 | -0.11 | -2.38 | -0.22 | -0.90 |
| SeedEdit | 9.31 | 9.01 | 8.71 | 9.01 | 8.50 | 6.91 | 8.74 | 8.05 | -0.81 | -2.10 | +0.02 | -0.96 |
Table 4: Performance comparison between C₁ and C₈ on real images. All models consistently underperform as instruction complexity increases.
Similar patterns were observed with synthetic images:
| Model | C₁ | C₈ | C₈-C₁ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IF | IP | PQ | O | IF | IP | PQ | O | Δ_IF | Δ_IP | Δ_PQ | Δ_O | |
| UltraEdit | 7.82 | 8.61 | 9.02 | 8.48 | 6.51 | 6.83 | 8.72 | 7.35 | -1.30 | -1.78 | -0.30 | -1.13 |
| OmniGen | 7.80 | 9.34 | 9.05 | 8.73 | 6.49 | 7.47 | 8.74 | 7.57 | -1.31 | -1.87 | -0.31 | -1.16 |
| AnyEdit | 5.79 | 9.17 | 8.61 | 7.86 | 1.47 | 8.73 | 8.72 | 6.31 | -4.32 | -0.44 | +0.11 | -1.55 |
| Imagen3 | 8.27 | 9.25 | 8.86 | 8.79 | 7.97 | 7.54 | 8.88 | 8.13 | -0.30 | -1.72 | +0.03 | -0.66 |
| SeedEdit | 9.33 | 9.60 | 9.29 | 9.41 | 8.25 | 7.94 | 9.20 | 8.46 | -1.08 | -1.66 | -0.10 | -0.95 |
Table 5: Performance comparison between C₁ and C₈ on synthetic images, showing similar trends to real images.
The Synthetic Style Problem: The "Curse of Synthetic Data"
An intriguing discovery from the research is the "curse of synthetic data" phenomenon. When applying extremely complex editing instructions (C₈) to real input images, the resulting outputs frequently lose their realistic appearance and adopt a distinctly synthetic aesthetic.

A real image edited with a C₈ instruction, showing how outputs from certain models lose realistic style completely.
This effect is particularly pronounced in UltraEdit, which contains a significantly higher proportion of synthetic images in its training data compared to OmniGen and AnyEdit. The phenomenon extends to highly capable proprietary models as well, including SeedEdit, Imagen3, and even GPT-4o.

A real image edited with a C₈ instruction by GPT-4o, showing complete loss of realistic style.
This observation suggests that, although the training sources for proprietary models are undisclosed, they likely incorporate synthetic data, contributing to both their impressive performance and the emergence of a distinctly synthetic aesthetic in complex editing scenarios.
Improvement Strategies: Test-Time Scaling Approaches
Building on insights from complex instruction following research, the researchers explored strategies to improve editing performance.
Breaking Down Complex Tasks: CoT-like Sequential Editing
Since the data pipeline composes complex instructions by combining sequences of atomic editing operations, it was reasonable to expect that sequentially applying these atomic steps would be equivalent to executing the complex instruction directly. This approach of decomposing complex tasks has proven effective in both language generation and text-to-image generation.
However, the results revealed that sequential editing leads to a steady decline in performance across all three metrics, with accumulating visual artifacts and distortions—even for strong proprietary models like Imagen3 and SeedEdit. AnyEdit demonstrated improved Instruction Following with sequential editing, but this came at the cost of reduced Identity Preservation.
Selecting the Best Option: The Benefits of Best-of-N
The researchers also experimented with Best-of-N, a simple test-time scaling method commonly used for text-to-image generation. For direct editing, they generated N candidate outputs for each input image and selected the one with the highest overall score. For sequential editing, they generated N candidates at each step and chose the candidate with the highest score to proceed to the next editing operation.
Results showed that:
- Increasing N gradually improves direct editing performance across all metrics
- For sequential editing, even a Best-of-N strategy with N=2 produces significant gains in Identity Preservation and Perceptual Quality
- The improvement in performance plateaus at around N=4 for both direct and sequential editing
Context and Connection: Related Research on Image Editing
The work on Complex-Edit builds upon significant prior research in text-based image editing.
InstructPix2Pix established the paradigm of instruction-based image editing, enabling users to modify images through textual instructions. Subsequent research has sought to address limitations through various innovations:
- MagicBrush proposed manually curated annotations
- HQ-Edit employed sophisticated black-box large language models with text-to-image generation systems
- MGIE and SmartEdit implemented multilevel language learning models for more precise editing operations
- UltraEdit introduced advanced masking techniques for fine-grained manipulation
- OmniGen expanded both model architecture and data corpus
- UIP2P introduced cyclic editing methodology for unsupervised instruction-driven editing
Recent efforts have also focused on enhancing image generation results through Test-Time Scaling methodologies. However, maintaining image identity remains a more significant challenge in image editing contexts compared to less-constrained image generation tasks.
Unlike previous work that proposed new editing models, Complex-Edit introduces a challenging benchmark designed to systematically assess how existing models perform under complex instructions.
Looking Forward: Implications and Future Directions
The Complex-Edit benchmark reveals several key insights about instruction-based image editing models:
- Open-source models significantly underperform compared to proprietary models, with the gap widening as instruction complexity increases
- Increased instructional complexity primarily impairs models' ability to retain key elements and preserve overall aesthetic quality
- Sequential editing (decomposing complex instructions into atomic steps) degrades performance across multiple metrics
- Best-of-N selection improves results for both direct and sequential editing
- Models trained with synthetic data produce increasingly synthetic-looking outputs as instruction complexity rises
These insights highlight the significant challenges in developing models that can handle complex editing instructions while maintaining image fidelity and quality. They also suggest promising directions for future research, particularly in test-time scaling approaches that could enhance model performance without requiring retraining.
The Complex-Edit benchmark provides a systematic way to evaluate progress in this important field, driving advancements in more powerful instruction-based image editing models that can better serve real-world editing needs.
