
🇻🇪🇨🇱 Dev.to Linkedin GitHub Twitter Instagram Youtube
Linktr

Enlace al repo https://github.com/build-on-aws/langchain-embeddings/blob/main/notebooks/05_create_audio_video_embeddings.ipynb
Crear embeddings para imágenes y texto es una práctica común en aplicaciones basadas en Generación Aumentada por Recuperación (RAG). Sin embargo, manejar contenido de video presenta desafíos únicos porque los videos combinan miles de cuadros con flujos de audio que pueden convertirse en texto. Esta publicación te muestra cómo transformar este contenido complejo en representaciones vectoriales buscables.
Utilizando Amazon Bedrock para invocar los Modelos de Fundación Amazon Titan para generar embeddings multimodales, Amazon Transcribe para convertir el habla en texto, y Amazon Aurora postgreSQL para almacenamiento vectorial y búsqueda de similitud, puedes construir una aplicación que entiende contenido visual y de audio, permitiendo consultas en lenguaje natural para encontrar momentos específicos en videos.
Por esta vez usaremos Amazon Transcribe, pero este blog se actualizará para implementar Amazon Nova Sonic
Arquitectura de la solución
Crea Amazon Aurora PostgreSQL con este Stack de Amazon CDK
Procesamiento de contenido visual:
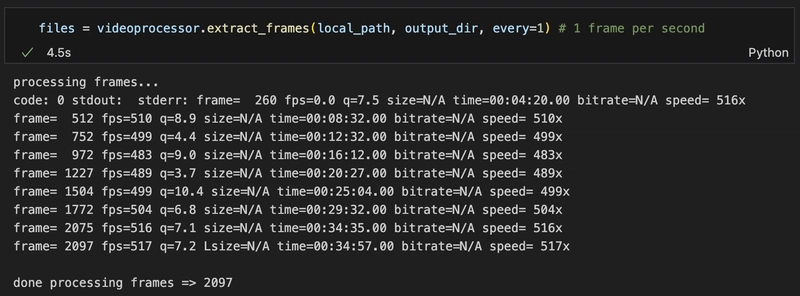
Extraer fotogramas: Una clase VideoProcessor que utiliza la biblioteca ffmpeg libavcodec para procesar video y crear fotogramas a intervalos de un segundo (personalizable a través de la configuración de FPS).
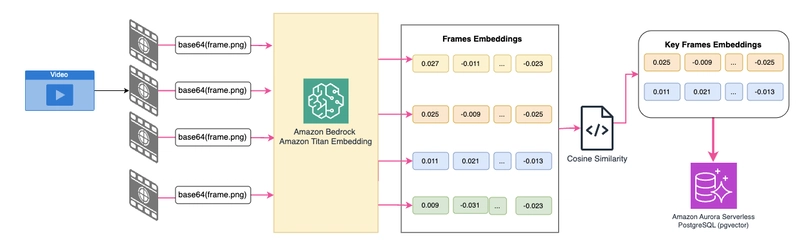
Puedes personalizar el valor de los intervalos cambiando el valor de FPS en el comando.
Generar embeddings: para cada fotograma extraído. Los embeddings se crean con el modelo Amazon Titan Multimodal Embeddings G1 utilizando la API Amazon Bedrock Invoke Model.
Seleccionar fotogramas clave: La clase CompareFrames identifica cambios visuales significativos cuando la similitud de los fotogramas cae por debajo de 0.8, utilizando la Similitud del Coseno.

🚨 97 de 2097 fotogramas es una gran diferencia, especialmente cuando hablamos de costos de almacenamiento.
Almacenamiento de vectores de fotogramas clave: Utilizando la clase AuroraPostgres, los embeddings de los fotogramas clave se almacenan en Amazon Aurora PostgreSQL utilizando pgvector, lo que permite capacidades eficientes de búsqueda por similitud.
La lista de embeddings para la imagen debería verse así:

Para contenido de audio:

Conversión de voz a texto: La clase AudioProcessing extrae y procesa el audio utilizando la API Amazon Transcribe StartTranscriptionJob. Con IdentifyMultipleLanguages como True, Transcribe utiliza Amazon Comprehend para identificar el idioma en el audio. Si conoce el idioma de su archivo multimedia, especifíquelo utilizando el parámetro LanguageCode.
El parámetro ShowSpeakerLabels como True habilita la partición de altavoces (diarización) en la salida de la transcripción. La partición de altavoces etiqueta el habla de los altavoces individuales en el archivo multimedia e incluye MaxSpeakerLabels para especificar el número máximo de altavoces, en este caso es 10.
Segmentación de texto: La transcripción se divide en segmentos de altavoz con el segundo en el que se dijo. Esto permite una alineación precisa con los fotogramas de video correspondientes.
Generar incrustaciones de texto: Cada segmento de transcripción se procesa utilizando Amazon Titan Text Embeddings.
La lista de embeddings para texto debería verse así:

Almacenamiento vectorial: Las incrustaciones de segmentos de texto se almacenan en Amazon Aurora PostgreSQL utilizando la clase AuroraPostgres.
Capacidades de búsqueda multimodal:
Amazon Titan Multimodal Embeddings transforma tanto el texto como las imágenes en representaciones vectoriales, lo que permite potentes capacidades de búsqueda entre modalidades. Cuando envías una consulta de texto, el sistema busca en todo el contenido visual y de audio para encontrar momentos relevantes en tus videos.
La solución admite múltiples enfoques de búsqueda
Búsqueda de similitud vectorial
Utilizando la clase AuroraPostgres y basado en el repositorio pvector, se pueden realizar dos tipos de búsquedas:
- Similitud Coseno: Mide la alineación de vectores (rango: -1 a 1), puntuaciones más altas (más cercanas a 1) indican mayor similitud. Ideal para la coincidencia semántica entre modalidades.
Probé el cuaderno con mi sesión de AWS re:Invent 2024 AI self-service support with knowledge retrieval using PostgreSQL. Pregunto por Aurora y me trae imágenes y textos donde se menciona:
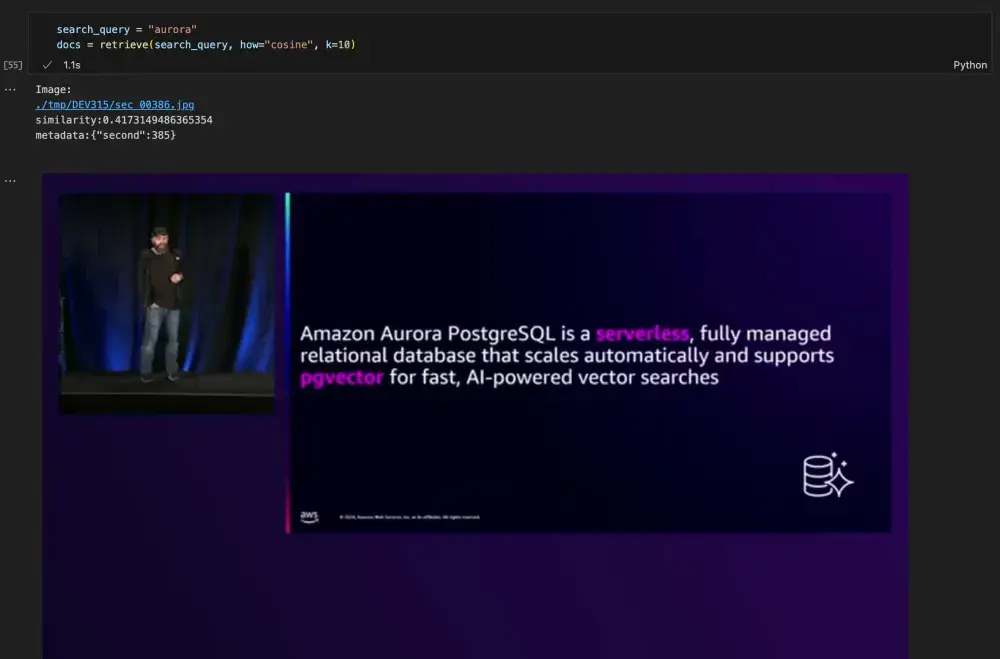
Ahí puedes ver a mi amigo Guillermo Ruiz 😆
- Distancia L2 (Euclidiana): Mide la distancia espacial entre vectores. Puntuaciones más bajas indican coincidencias más cercanas. Útil para la detección de similitud de grano fino.
En este caso, encontré la misma respuesta.
Búsqueda por imagen
Se ingresa una imagen, la cual convierto en un vector para realizar la búsqueda en la base de vectores de Aurora PostgreSQL.
Envío esta imagen para la búsqueda:
Esta es una de las respuestas que me dio la consulta:
Retrieval-Augmented Generation (RAG)
Combina la recuperación con el contexto de contenido visual y de audio, proporcionando respuestas en lenguaje natural.
En el código encontrarás una modificación del Retriever personalizado de langchain que te permite recuperar imágenes y texto como contexto.
Cuando hago una recuperación personalizada para buscar mi nombre: Elizabeth, obtendré una lista de texto e imágenes donde se menciona:
Para generar la respuesta con los Modelos de Lenguaje de Gran Tamaño (LLMs), que es el núcleo del RAG, utilizo la API de Conversación de Amazon Bedrock para invocar a Amazon Nova Pro como model_id, con el siguiente prompt del sistema:
Responde las preguntas del usuario basándote en el contexto a continuación. Si el contexto contiene una imagen, indica que se puede revisar para obtener más información. Si el contexto no contiene información relevante para la pregunta, no inventes nada y simplemente di "No lo sé". (SI INVENTAS ALGO POR TU CUENTA, SERÁS DESPEDIDO). Para cada afirmación en tu respuesta, proporciona un [n] donde n es el número del documento que proporciona la respuesta.
Soy un jefe muy estricto 🤣
Utilizando RAG, puedo hacer preguntas más complejas como: ¿De qué trata la sesión?
El recuperador entregó esta lista de contextos:
Esta es la respuesta final que recibí:
La sesión parece tratar sobre discutir los desafíos y frustraciones enfrentados durante las interacciones de servicio al cliente, particularmente con una aerolínea. El orador destaca problemas como largos tiempos de espera, caídas de llamadas, falta de continuidad con los agentes, solicitudes repetitivas de información y experiencias desconectadas a través de diferentes canales de comunicación. Además, la sesión toca la decepción con un chatbot moderno que no logró proporcionar una mejor experiencia debido a fallas del sistema y falta de personalización. El tema general parece ser la mala experiencia del cliente resultante de estos canales de servicio desconectados e ineficientes. [1][2]
El repositorio tiene una pequeña biblioteca que creé utilizando Amazon Q Cli que te permite cargar un video local a un bucket de Amazon S3.
Espero que la encuentres útil y puedas probarla con tus propios videos. Comparte tu experiencia en esta publicación; me encantaría saber de ti.
Obtén tu builderID para usar Amazon Q dev de forma gratuita.
Notas de implementación
Mientras que esta libreta demuestra la funcionalidad principal, implementar una solución de demostración requiere una arquitectura más robusta. Para abordar esta necesidad, he desarrollado "Pregunta a Tu Video" - una solución completamente sin servidor que puedes desplegar utilizando AWS Cloud Development Kit (CDK) 😏.
En la próxima parte de esta serie, proporcionaré una explicación detallada y paso a paso de cómo funciona "Pregunta a Tu Video". Hasta entonces, puedes explorar la solución completa, incluyendo instrucciones de despliegue y diagramas de arquitectura, en este repositorio de GitHub.
¡Mantente atento para la Parte 2!
Gracias,
Eli
🇻🇪🇨🇱 Dev.to Linkedin GitHub Twitter Instagram Youtube
Linktr