01. CUDA C Basics
-
Host: The CPU and its memory -
Device: The GPU and its memory
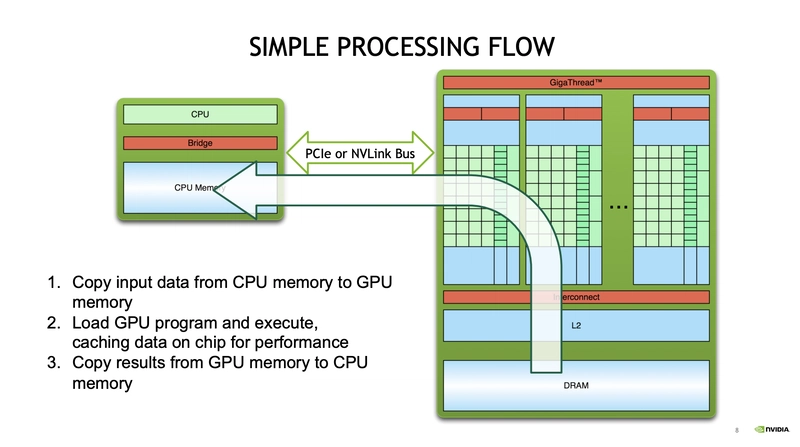
Simple Processing Flow
-
COPYmemory (from CPU to GPU) -
LoadGPU program andExecute -
COPYmemory (from GPU to CPU) Free
Problem::vector addition
- 1:1 (input:output)
Concepts
__global void mykernel(void) {};
mykernel<<<N,1>>>(); // Grid (N blocks), Block(1 thread)-
__global__is kernel code (run in device) -
<<, which means>> - GRID: # of blocks per grid
- Block: # of threads per block
// 1-1. prepare gpu's global memory
cudaMalloc((void **)&d_a, size);
// 1-2. copy (to device A from host A)
cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);
// 2. Load and Execute
add<<<N,1>>>(d_a, d_b, d_c)
// 3. Copy (GPU -> CPU)
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
// 4. Free
free(a);cudaFree(d_a);02. Shared Memory
Problem::1D Stencil

- It is not an 1:1 (input: ouput) problem.
- e.g. blue element is read seven times (if radius 3)

Concept::Shared Memory
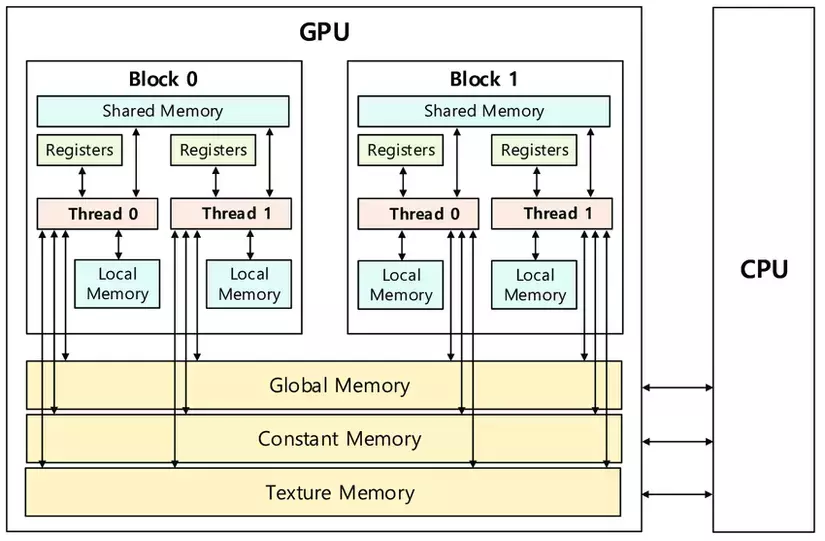
- On Chip memory (>= Global memory)
- Per Block (invisible other blocks)
- User managed memory
__shared__ int s[64];
...Starting from Volta (2017 and later),
__shared__(SW) and the L1 cache(SW) share the same on-chip SRAM(HW) resources. Developers can configure how much of this SRAM is allocated to shared memory versus L1 cache depending on the application needs.
03. CUDA Optimization (1 of 2)
Architectures
- Tesla -> Fermi -> Kepler -> Maxwell -> Pascal -> Volta(2017) -> Turing -> Ampere -> Hopper(2022) -> Ada -> Blackwell(2024)

-
CC: Compute Capability -
GK110: Chip name -
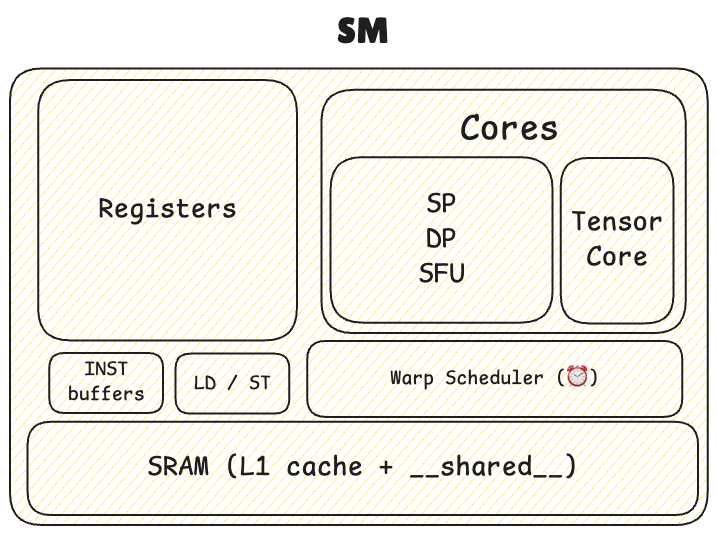
SMX,SMM: Enhanced SM - Processors
- SP: Scalar Processor (ALU, FP32)
- DP: Double Precision Unit (ALU, FP64)
- SFU: Special Function Unit (sin, cos ...)
- Tensor Core: Matrix mul
- INT
- LD / ST: Load / Store Unit
- Tensor Cores: for matrix multiplicaiton
Warp scheduler
Each warp scheduler is dual issue capable
dual issue capable: It can issue and execute two instructions simultaneously in a single clock cycle
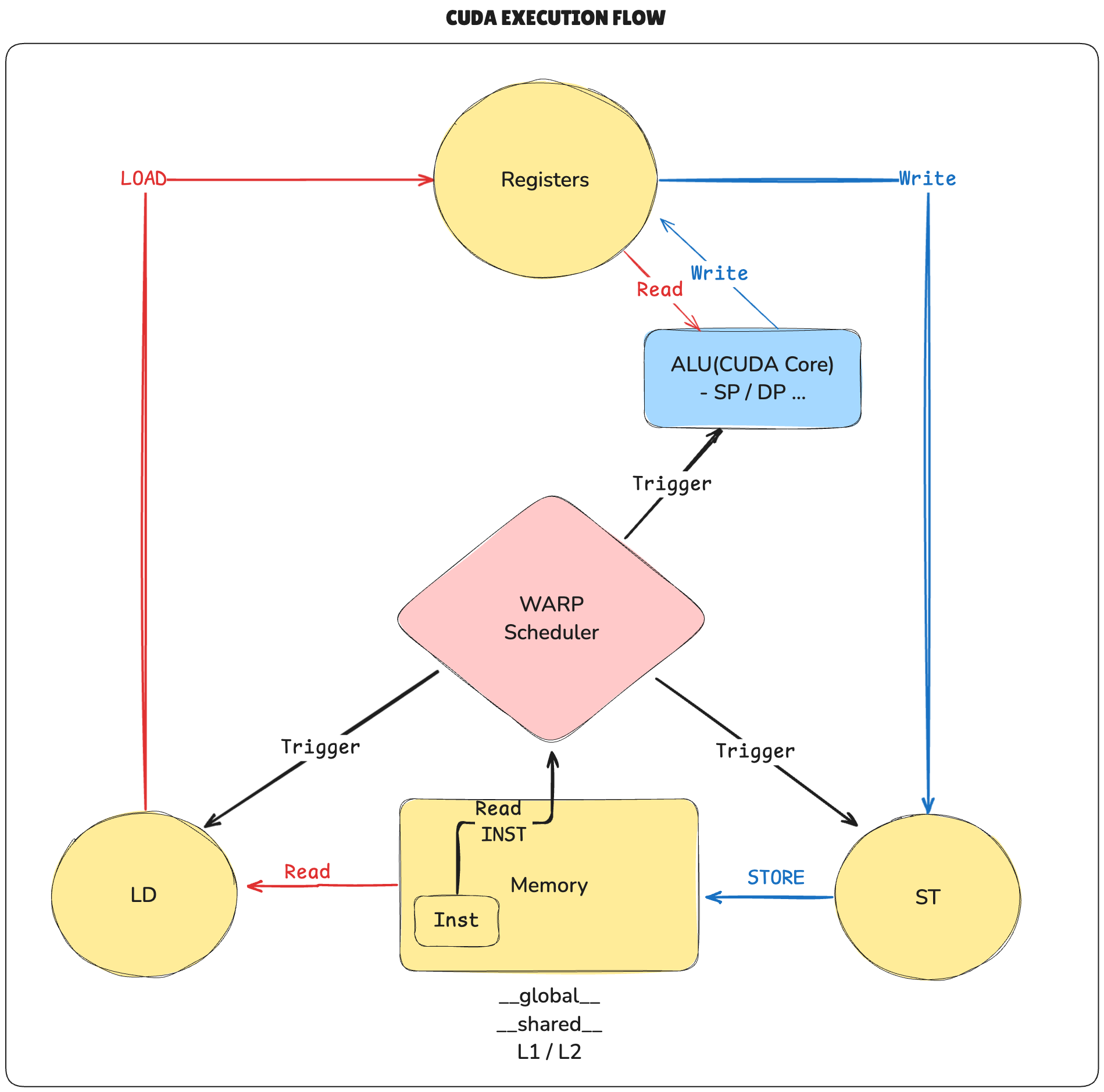
Execution Model
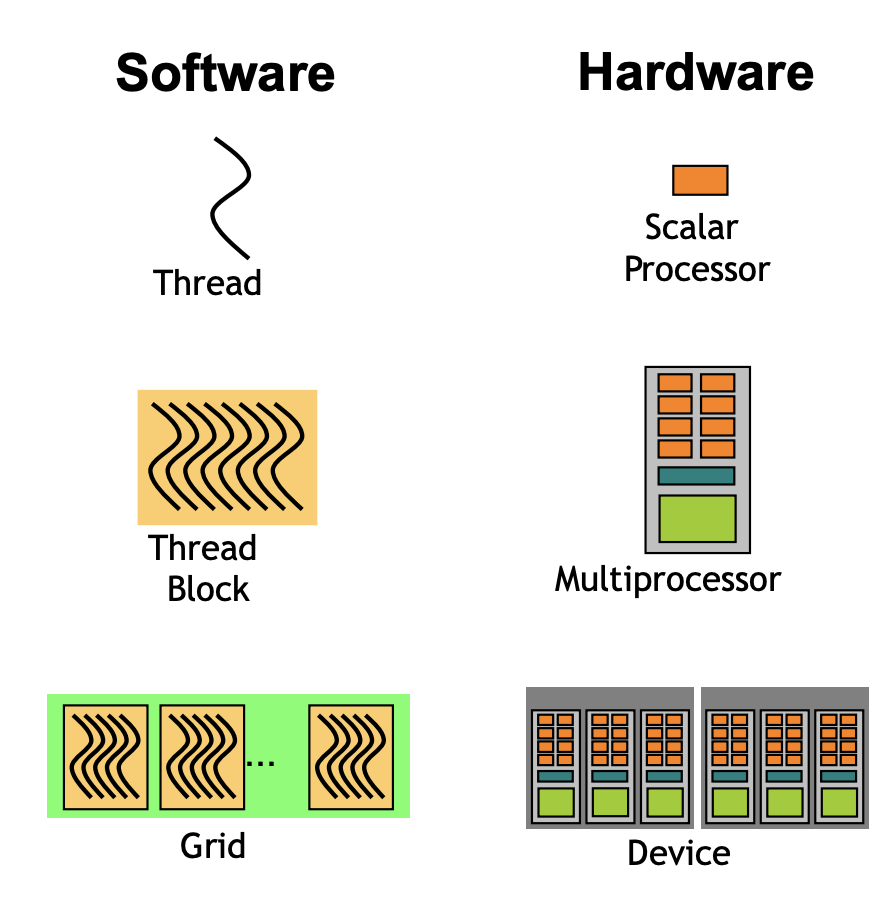
- Scalar Processor: SP / DP / Tensorcore ...
- Multi-Processor:
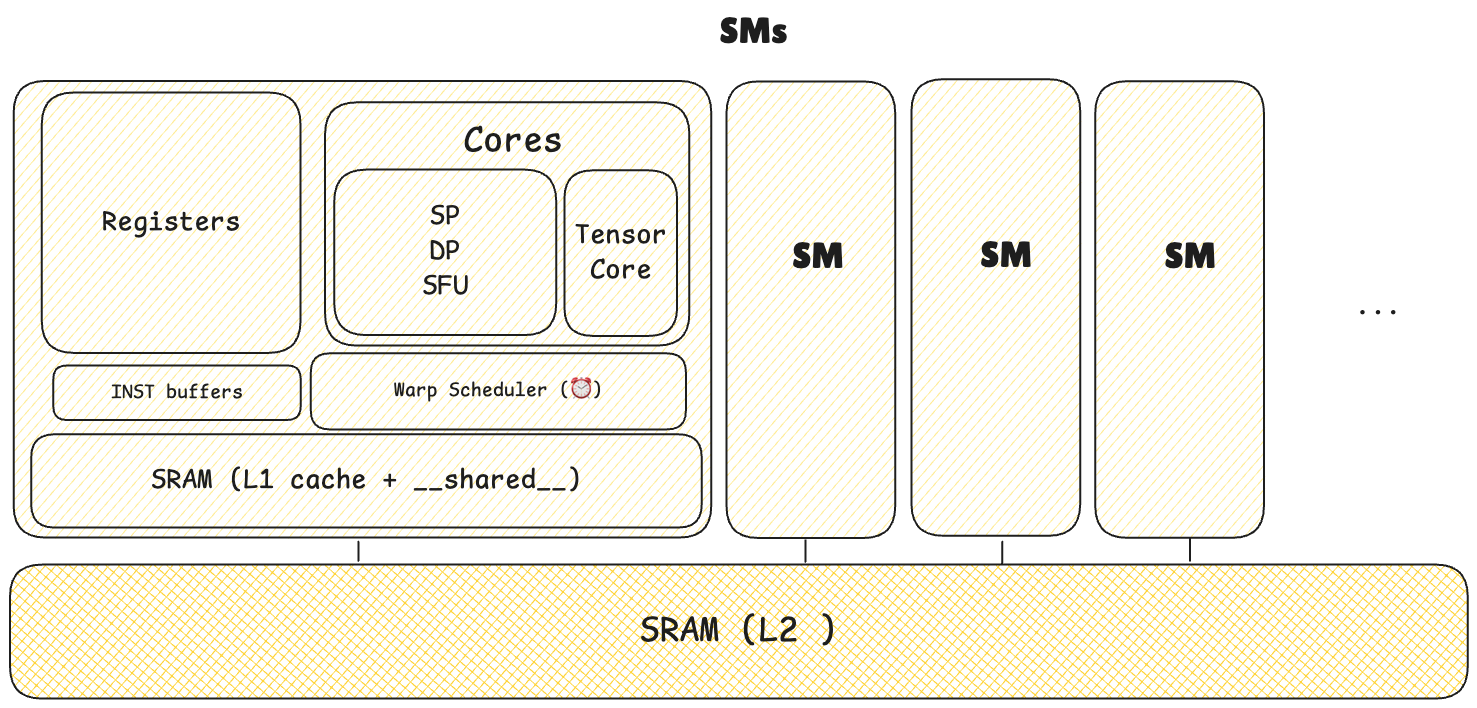
SM(Streaming Multiprocessors)
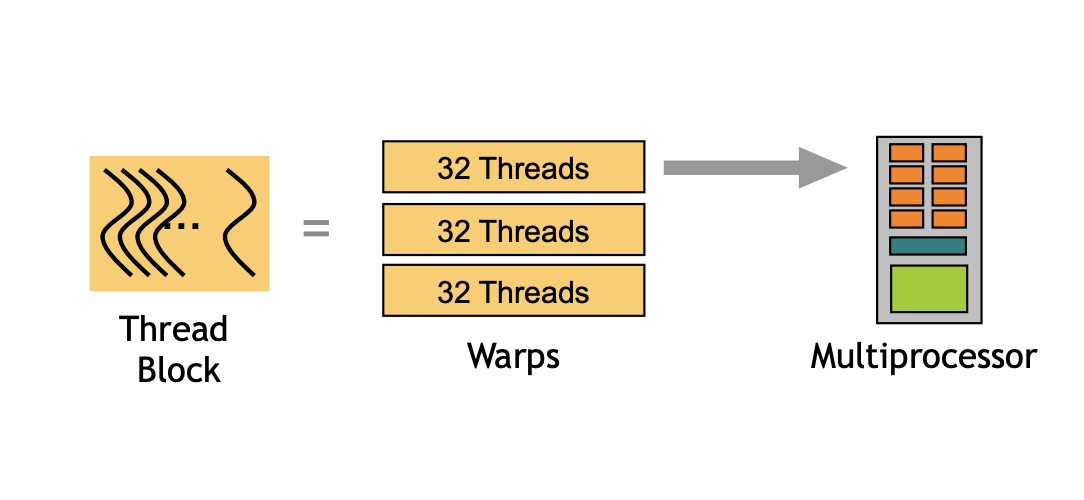
Multiple threads in a thread block are not (never) spread across different SMs.
1 Block(SW) --> N Warps(HW) --> 1 SM(HW)For example, 1024 tasks and if BLOCK_SIZE is 1024 would create 32 warps (1024 / 32), all of which must execute on the same SM. This can create bottlenecks.
Once threads begin execution on an SM, they cannot migrate to a different SM. They must complete execution on their assigned SM.
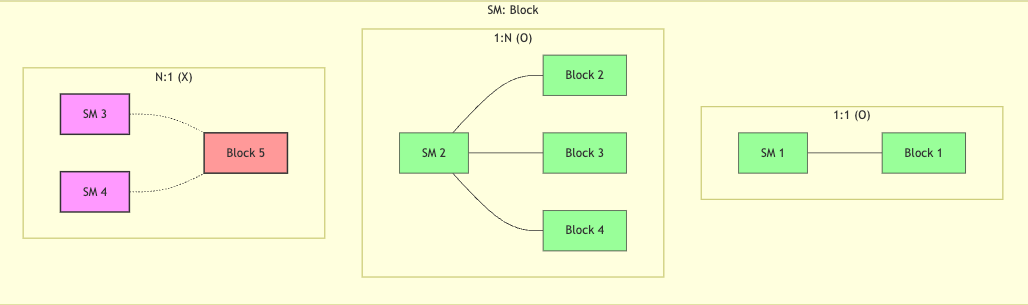
- 1 block :1 SM (ok)
- N block :1 SM (ok)
- 1 block :N SM (x)
Launch Configuration
- Instructions are issued in order
-
Thread Stall: A thread stalls when one of the operands isn’t ready -
Latency hiding: Hide latency by thread Context switching
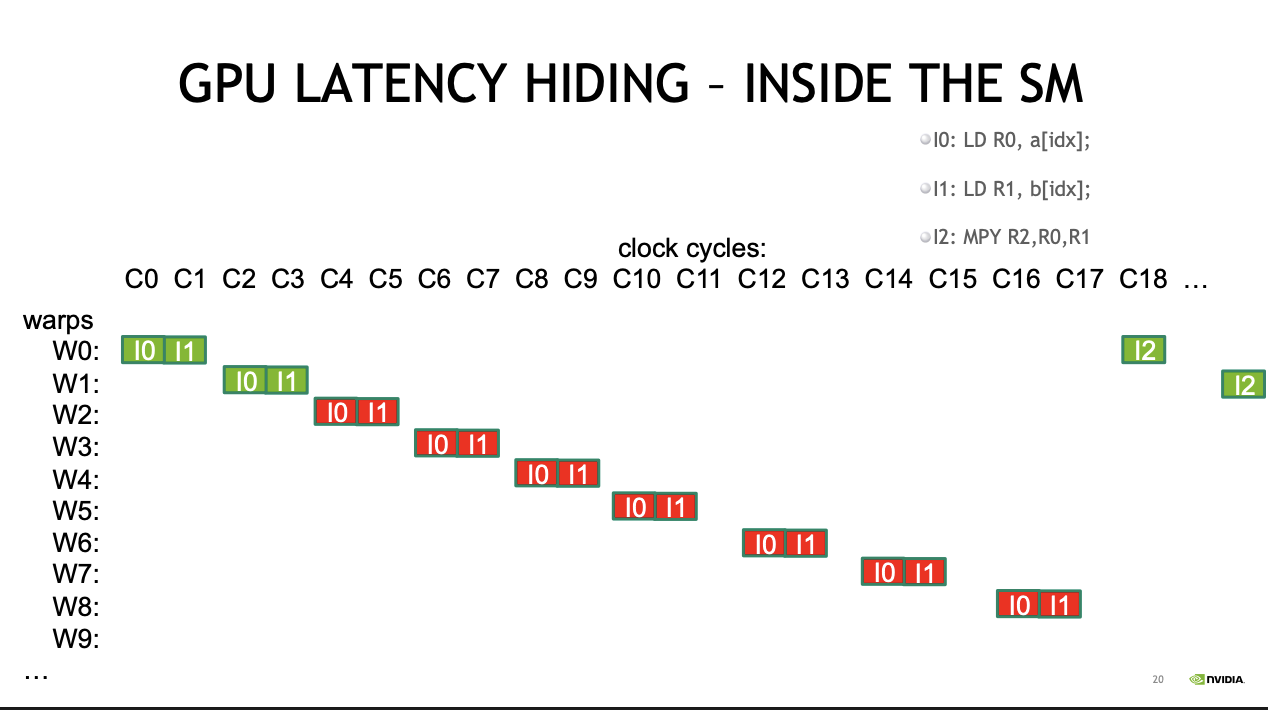
CUDA need enough threads to hide latency
Since CUDA uses SIMT, each warp can be in a different instruction execution state.
-> Also CUDA processes instructions in-order
-> if data isn't ready (e.g. LD memory -> register), operations like SP, DP, MPY(multiply) cannot execute, leading to a thread stall.
-> To prevent idle cycle(wastage), context switching is performed at the warp level to hide latency (latency hiding)
Conclusion

- Launch enough
threadsper SM to hide latency - Launch enough
threadblocksto load the GPU

Occupancy= Active warps / Maximum number of warps per SM
It represents how efficiently the GPU’s Streaming Multiprocessors (SMs) are utilized.
An occupancy of 1.0 (or 100%) indicates the SM is working at full capacity.
04. CUDA Optimization (2 of 2)
Memory OP
Memory operations are issued per warp (LD, ST, 32 threads in parallel), just like all other instructions.
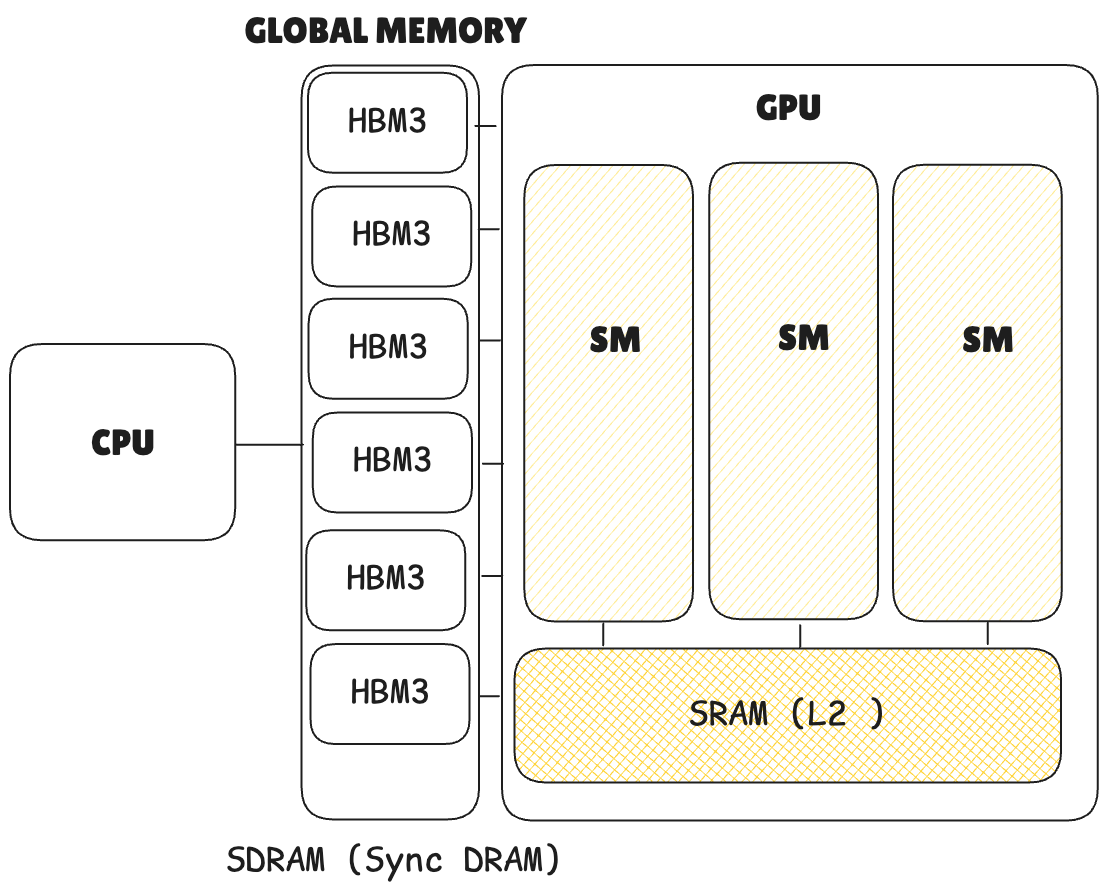
Even if only 4 bytes are needed (e.g., for int or float), global memory requires a 32-byte segment, while fetching from the cache requires loading a 128-byte line.
| Property | Line | Segment |
|---|---|---|
| Size | 128 bytes | 32 bytes |
| For Cache | Yes (Used in L1, L2 cache) | No |
| For Global Mem | No | Yes (Used in global memory) |
| Hardware | SRAM (Static RAM) | S-DRAM (Synchronous Dynamic RAM) |
Coalescing
Coalescing happens when a warp (32 threads) needs data from multiple memory addresses, and those addresses are grouped together in a single chunk (e.g., 0, 4, 8, ..., 124). The GPU can fetch this chunk in one go, making it efficient.
If the addresses are scattered (e.g., 0, 100, 500), the GPU has to fetch multiple chunks, which is slower and less efficient.
Bus Utilization
c = a[idx] // idx = global thread idxIn a single operation, 32 warps × 4 bytes = 128 bytes are needed. Ideally, this can all be fetched with one cache line (128 bytes).
- Bus utilization: 100%
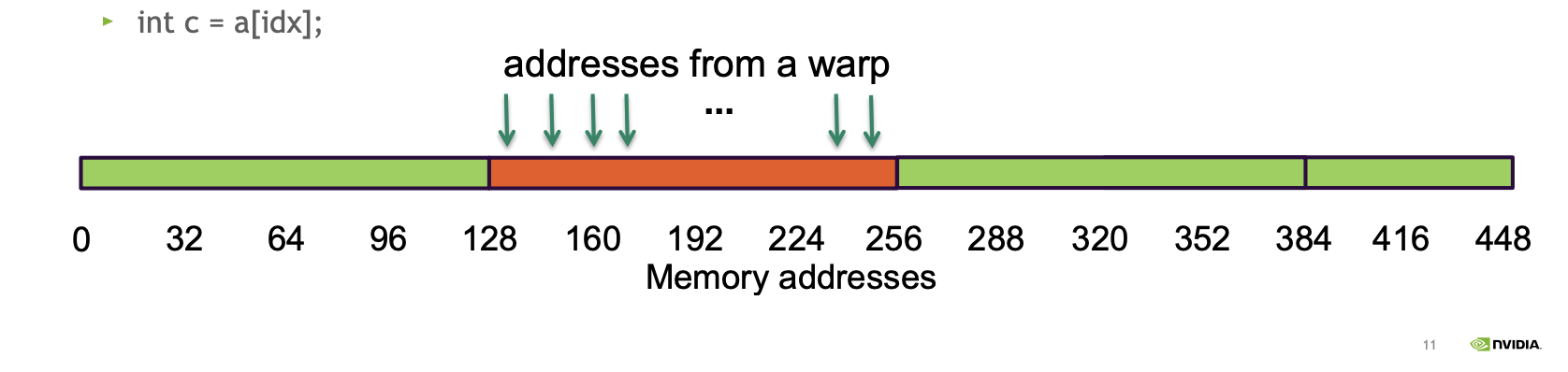
This achieves 100% bus utilization (ideal coalescing), meaning no bytes are wasted. (Typically, waste occurs due to the minimum size imposed by line or segment fetches.)
- Bus utilization: 50%
c = a[idx-2]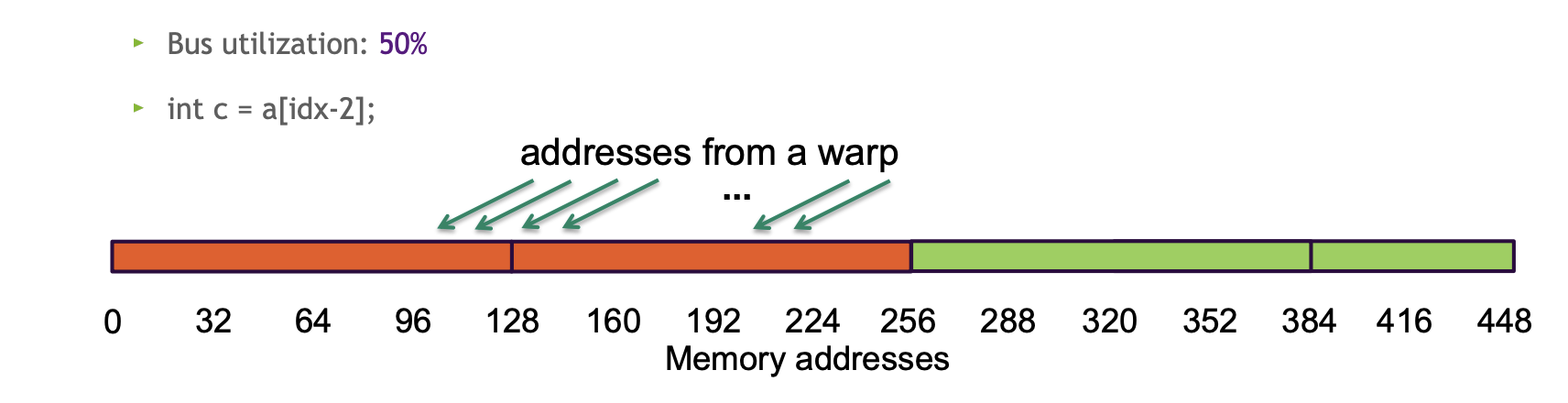
- Bus utilization: 3.125%
c = a[40];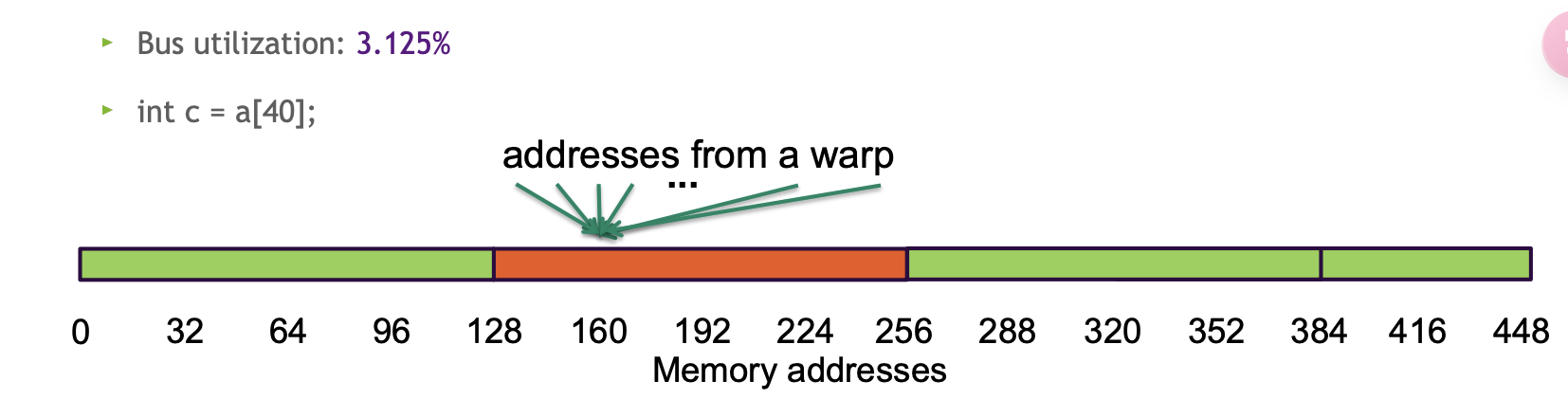
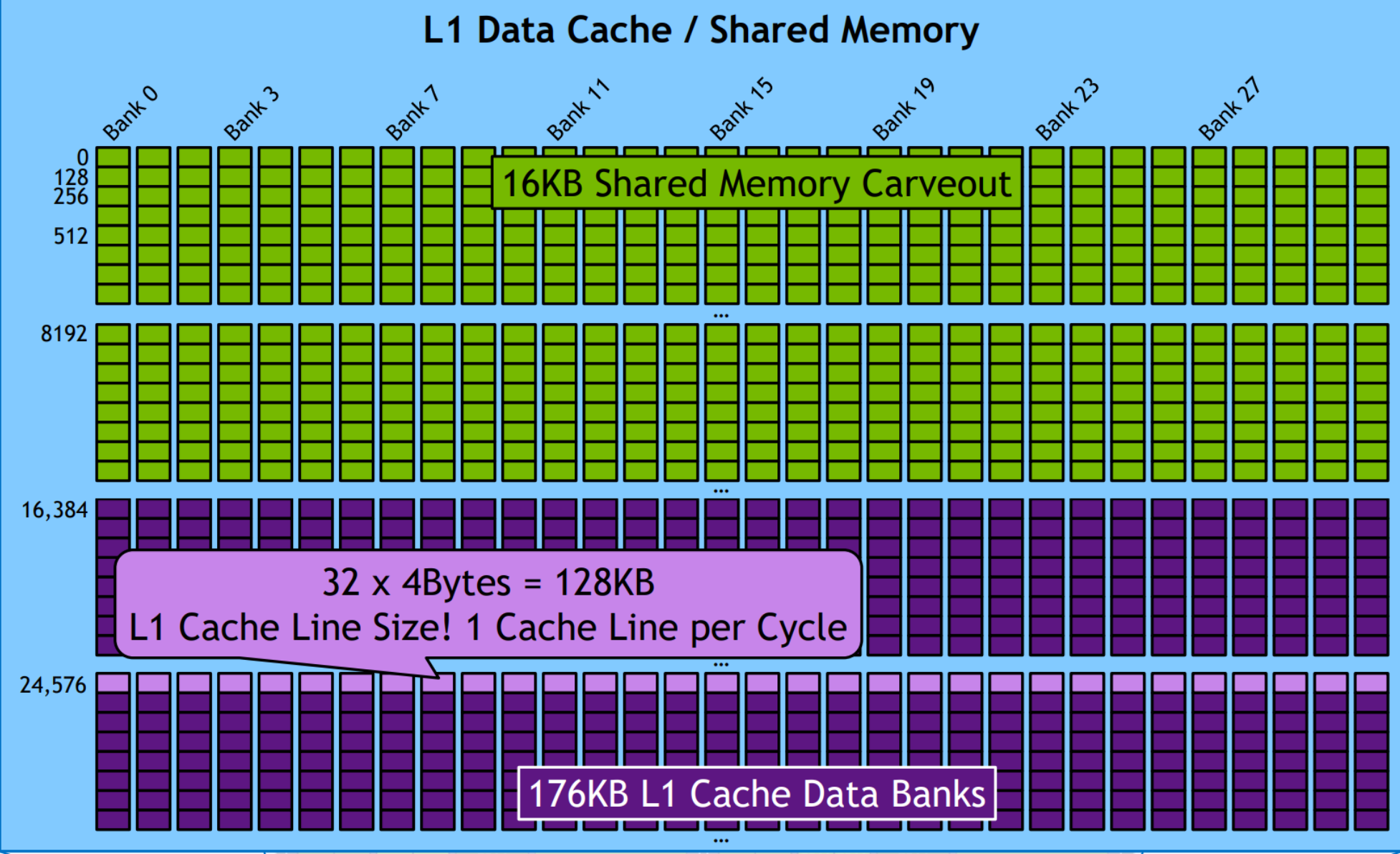
Shared Memory Optimization in CUDA
- Divided into 32 banks, each 4 bytes wide.
- Typically 4 bytes per bank per 1-2 clock cycles per multiprocessor.
- Shared memory accesses are issued per warp (32 threads).
Memory Bank: A bank is a hardware unit in shared memory (SMEM) that splits data across multiple memory chips for parallel load/store operations. This increases bandwidth and reduces contention. In contrast, cache uses "lines," and global memory (SDRAM) uses "segments."
-
Bank Layout: In CUDA, shared memory has 32 parallel banks. For example, if
__shared__memory is 64KB, it's split across 32 banks (2KB per bank). - Each bank can serve 4 bytes per cycle in parallel.
Code
__global__ void kernel(float* in, float* out, int n) {
__shared__ float s_data[256]; // 256 floats = 1KB, split across 32 banks
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (threadIdx.x < 256 && idx < n) {
s_data[threadIdx.x] = in[idx]; // Each thread loads to a bank
}
__syncthreads();
if (idx < n) out[idx] = s_data[threadIdx.x];
}
// Launch: kernel<<<(n+255)/256, 256>>>(in, out, n);Bank Access Details
- Single Precision (4 bytes): A warp (32 threads) reading 4-byte floats = 128 bytes (32 × 4). Matches a 128-byte cache line, so it takes 1 cycle if aligned and contention-free.
- Double Precision (8 bytes): A warp reading 8-byte doubles = 256 bytes (32 × 8). If the GPU fetches 128 bytes per cycle, it needs 2 cycles to get all 256 bytes.
Bank Conflicts
When a warp's 32 threads try to access the same bank, causing serialized reads (multiple cycles).
-
Example (FP32 Array):
- Assume a
__shared__array of 32 floats (128 bytes) stored across banks 0–31. - If each float is 4 bytes and continuous, banks 0–31 hold the first 128 bytes (32 floats).
- Problem: If threads need more than 4 bytes from the same bank (e.g., misaligned doubles), a bank conflict occurs, slowing it down.
- Assume a
- Impact: For an FP32 array, fetching all 32 elements in one cycle fails if alignment or bank access overlaps (e.g., FP32 array[16] takes 2 cycles due to bank contention).
Code
// ❌ With bank conflicts
__global__ void transposeWithBankConflicts(float *odata, float *idata, int width, int height) {
__shared__ float tile[32][32];
int x = blockIdx.x * 32 + threadIdx.x;
int y = blockIdx.y * 32 + threadIdx.y;
if (x < width && y < height) {
tile[threadIdx.y][threadIdx.x] = idata[y * width + x];
}
__syncthreads();
x = blockIdx.y * 32 + threadIdx.x;
y = blockIdx.x * 32 + threadIdx.y;
// 32-way Bank conflicts / per warp
if (x < height && y < width) {
odata[y * height + x] = tile[threadIdx.x][threadIdx.y];
}
}
// ✅ Without bank conflicts
__global__ void transposeWithoutBankConflicts(float *odata, float *idata, int width, int height) {
// Added padding to avoid bank conflicts
__shared__ float tile[32][33];
int x = blockIdx.x * 32 + threadIdx.x;
int y = blockIdx.y * 32 + threadIdx.y;
if (x < width && y < height) {
tile[threadIdx.y][threadIdx.x] = idata[y * width + x];
}
__syncthreads();
x = blockIdx.y * 32 + threadIdx.x;
y = blockIdx.x * 32 + threadIdx.y;
// No bank conflicts due to padding
if (x < height && y < width) {
odata[y * height + x] = tile[threadIdx.x][threadIdx.y];
}
}
void transposeMatrix(float *d_out, float *d_in, int width, int height) {
dim3 blockDim(32, 32);
dim3 gridDim((width + blockDim.x - 1) / blockDim.x,
(height + blockDim.y - 1) / blockDim.y);
// transposeWithBankConflicts<<>>(d_out, d_in, width, height);
transposeWithoutBankConflicts<<<gridDim, blockDim>>>(d_out, d_in, width, height);
}The key solution is to add padding to make the row length (33) coprime with the number of memory banks (32), which offsets each row by one bank and ensures column elements are distributed across different banks during transpose operations.
This technique prevents the worst-case scenario of 32-way conflicts, but doesn't completely eliminate all potential bank conflicts or timing variations, it simply distributes memory accesses more evenly across banks.
5. CUDA Atomics, Reductions, and Warp Shuffle
Atomic Tips
- Serialize flow
- Serialize Offset
1. Serialize flow
Mostly atomic returns "old" value loc.
%%writefile atomic.cu
#include
#include
__global__ void testAtomicAdd(int *order, int *positions, int num_threads) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < num_threads) {
int old_pos = atomicAdd(order, 1);
positions[tid] = old_pos;
// printf("Thread %d: old_pos = %d\n", tid, old_pos); // debug
}
}
#define CUDA_CHECK(err) \
do { \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA Error at line %d: %s\n", __LINE__, cudaGetErrorString(err)); \
exit(EXIT_FAILURE); \
} \
} while (0)
int main() {
int num_threads = 32;
int threads_per_block = 32;
int num_blocks = (num_threads + threads_per_block - 1) / threads_per_block;
int *h_order = (int *)malloc(sizeof(int));
int *h_positions = (int *)malloc(num_threads * sizeof(int));
*h_order = 0;
for (int i = 0; i < num_threads; i++) {
h_positions[i] = -1;
}
int *d_order, *d_positions;
CUDA_CHECK(cudaMalloc(&d_order, sizeof(int)));
CUDA_CHECK(cudaMalloc(&d_positions, num_threads * sizeof(int)));
CUDA_CHECK(cudaMemcpy(d_order, h_order, sizeof(int), cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(d_positions, h_positions, num_threads * sizeof(int), cudaMemcpyHostToDevice));
printf("Launching kernel with %d blocks, %d threads per block\n", num_blocks, threads_per_block);
testAtomicAdd<<<num_blocks, threads_per_block>>>(d_order, d_positions, num_threads);
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess) {
fprintf(stderr, "Kernel launch error: %s\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
CUDA_CHECK(cudaDeviceSynchronize());
CUDA_CHECK(cudaMemcpy(h_positions, d_positions, num_threads * sizeof(int), cudaMemcpyDeviceToHost));
CUDA_CHECK(cudaMemcpy(h_order, d_order, sizeof(int), cudaMemcpyDeviceToHost));
printf("Final order value: %d\n", *h_order);
printf("Positions assigned to threads:\n");
for (int i = 0; i < num_threads; i++) {
printf("Thread %d: Position %d\n", i, h_positions[i]);
}
cudaFree(d_order);
cudaFree(d_positions);
free(h_order);
free(h_positions);
return 0;
}$ nvidia-smi # tesla t4
%%shell
nvcc -arch=sm_75 atomic.cu -o atomic
./atomic
Launching kernel with 1 blocks, 32 threads per block
Final order value: 32
Positions assigned to threads:
Thread 0: Position 0
Thread 1: Position 1
Thread 2: Position 2
Thread 3: Position 3
Thread 4: Position 4
Thread 5: Position 5
Thread 6: Position 6
Thread 7: Position 7
Thread 8: Position 8
Thread 9: Position 9
Thread 10: Position 10
Thread 11: Position 11
Thread 12: Position 12
Thread 13: Position 13
Thread 14: Position 14
Thread 15: Position 15
Thread 16: Position 16
Thread 17: Position 17
Thread 18: Position 18
Thread 19: Position 19
Thread 20: Position 20
Thread 21: Position 21
Thread 22: Position 22
Thread 23: Position 23
Thread 24: Position 24
Thread 25: Position 25
Thread 26: Position 26
Thread 27: Position 27
Thread 28: Position 28
Thread 29: Position 29
Thread 30: Position 30
Thread 31: Position 312. Serialize Offset
Reserve space in a buffer

Classical parallel reduction
Atomics don't run at full memory bandwidth. Because it serialize threads, we would like to effectively use all threads.
- Decompose
- Atomic
- Thread Block draining
- Cooperative groups
We'll gonna use decompose and hybrid way (grid-stride loop)
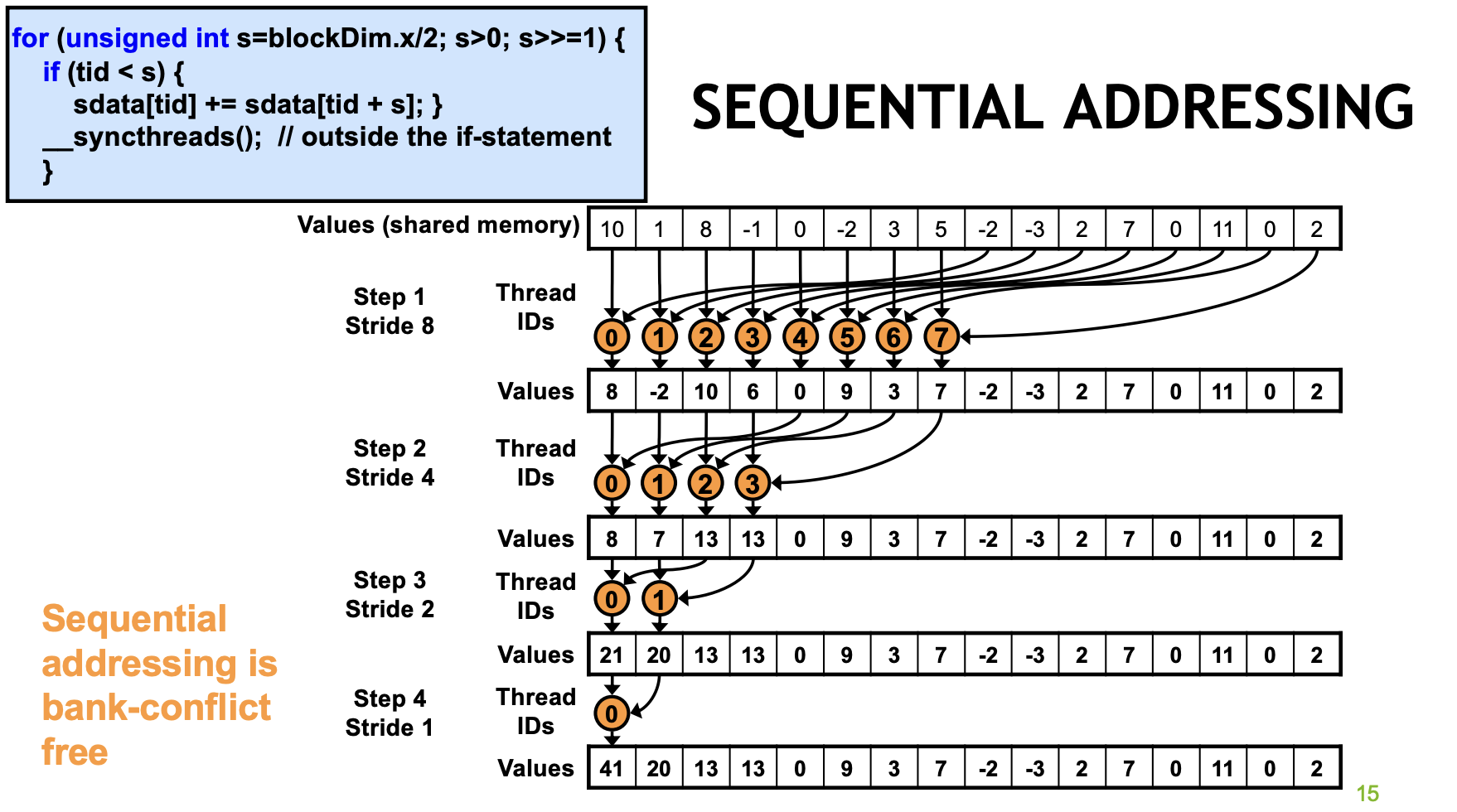
Sequential Addressing
decompose
Hybrid way Grid Stride Loop
decompose + atomic


Warp Shuffle

Enables thread communication within a warp without using Shared or Global Memory. Supported at the register level via shuffle instructions (Kepler Architecture, compute capability 3.0+).
Key Concepts
-
Lane: A single thread within a warp (32 threads, indexed 0–31).
- Unique within a warp.
- Multiple threads in a block may share the same lane index.
- Lane index calculated as
threadIdx.x % 32.
-
WarpID: Identifies a warp within a block.
- Calculated as
warpID = threadIdx.x / 32.
- Calculated as
Shuffle Instructions
T __shfl_sync(unsigned mask, T var, int srcLane, int width=warpSize);
T __shfl_up_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_down_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width=warpSize);-
downmeans index down (left in arr) -
upmeans index up (right in arr)
__shfl_sync
-
mask: Specifies participating threads (e.g.,
0xfffffffffor broadcasting). -
var: Value from
srcLaneto broadcast to all threads inmask. -
width:
widthis required to create sub-groups from the active threads specified by the mask.- Must be a power of 2 in [1, warpSize]
- 1, 2, 4, 8, 16, or 32
Code:: Broadcast
#include
__global__ void bcast(int arg) {
int laneId = threadIdx.x & 0x1f;
int value;
if (laneId == 0)
value = arg;
value = __shfl_sync(0xffffffff, value, 0);
printf("Thread %d, lane %d, value = %d, arg = %d\n", threadIdx.x, laneId, value, arg);
}
int main() {
bcast<<<1, 32>>>(1234);
cudaDeviceSynchronize();
return 0;
}Code::SubGroup
%%writefile warp.cu
#include
__global__ void subgroup_shuffle()
{
// 1. init
int laneId = threadIdx.x & 0x1f; // 0~31
int val = laneId; // val is idx
__shared__ int original[32];
__shared__ int shuffled[32];
// 2. shuffle
original[laneId] = val;
int res = __shfl_down_sync(0xffffffff, val, 2, 8); // delta 2, group size 8
shuffled[laneId] = res;
__syncthreads();
// 3. check
if (laneId == 0)
{
printf("Original Values [0~31]: [");
for (int i = 0; i < 31; i++)
{
printf("%d, ", original[i]);
}
printf("%d]\n", original[31]);
printf("Shuffled Values [0~31]: [");
for (int i = 0; i < 31; i++)
{
printf("%d, ", shuffled[i]);
}
printf("%d]\n", shuffled[31]);
}
}
int main()
{
subgroup_shuffle<<<1, 32>>>();
cudaDeviceSynchronize();
return 0;
}nvcc -arch=sm_75 warp.cu -o warp
./warp
Original Values [0~31]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]
Shuffled Values [0~31]: [2, 3, 4, 5, 6, 7, 6, 7, 10, 11, 12, 13, 14, 15, 14, 15, 18, 19, 20, 21, 22, 23, 22, 23, 26, 27, 28, 29, 30, 31, 30, 31]You can verify that the pairs [6,7], [14, 15], [22, 23], [30, 31] are not influenced by other subgroups. (down delta 2)
