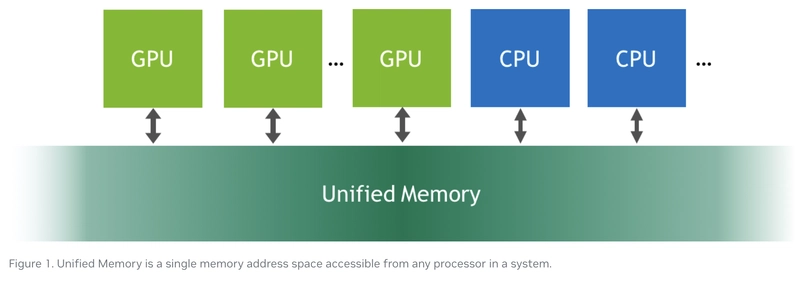
6. CUDA Unified Memory
= Managed Memory
6.1 cudaMallocManaged
__host__ cudaError_t cudaMallocManaged(void **devPtr, size_t size);cudaMallocManaged behaves differently internally depending on whether it's running on a pre-Pascal or Pascal(2016) and later architecture.
pre-Pascal GPUs
It allocates size bytes of managed memory and sets devPtr to refer to the allocation. Internally, the driver also sets up page table entries for all pages covered by the allocation, so that the system knows that the pages are resident on that GPU.
On Pascal and later GPUs
On Pascal and later GPUs, managed memory may not be physically allocated when cudaMallocManaged() returns; it may only be populated on access (or prefetching). In other words, pages and page table entries may not be created until they are accessed by the GPU or the CPU. The pages can migrate to any processor’s memory at any time. link
Managed memory allocations may be accessed concurrently by all CPUs and GPUS in the system.
The CUDA system software and/or the hardware takes care of migrating memory pages to the memory of the accessing processor. link
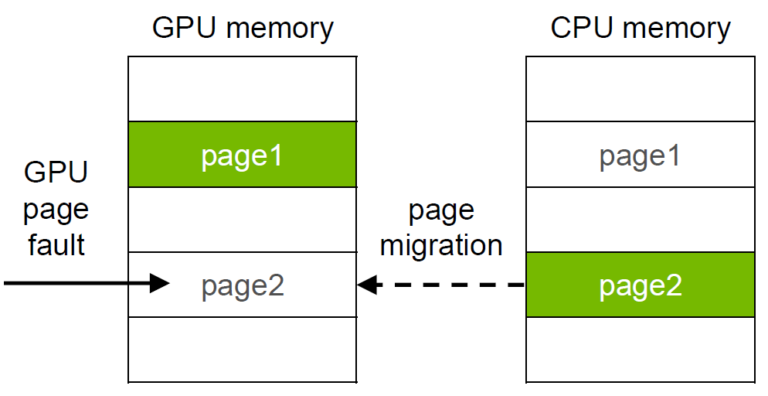
Migration overhead (page fault on device)
In pre-Pascal architectures, page faults occur only on the CPU, and the GPU cannot handle page faults. Therefore, all data must be migrated to GPU memory before kernel execution, resulting in a single bulk migration.
In Pascal and later architectures, page faults can occur on the GPU. If a required page is not in GPU memory during kernel execution, multiple page migrations occur on a per-page basis. Without proper handling, this can cause the kernel to stall multiple times due to page migration I/O, potentially leading to performance degradation compared to pre-Pascal architectures.
Solution (2)
- Move the data initialization to the GPU in another CUDA kernel.
-
Prefetch the data to GPU memory before running the kernel. (
cudaMemPrefetchAsync())
6.2. cudaDeviceSynchronize
__host__ __device__ cudaError_t cudaDeviceSynchronize ( void )Wait for compute device to finish.
cudaDeviceSynchronize() after the kernel launch. This ensures that the kernel runs to completion before the CPU tries to read the results from the managed memory pointer.
- Use of cudaDeviceSynchronize in device code was deprecated in CUDA 11.6 (Only allows in host)
6.3. Unified Memory on PASCAL+
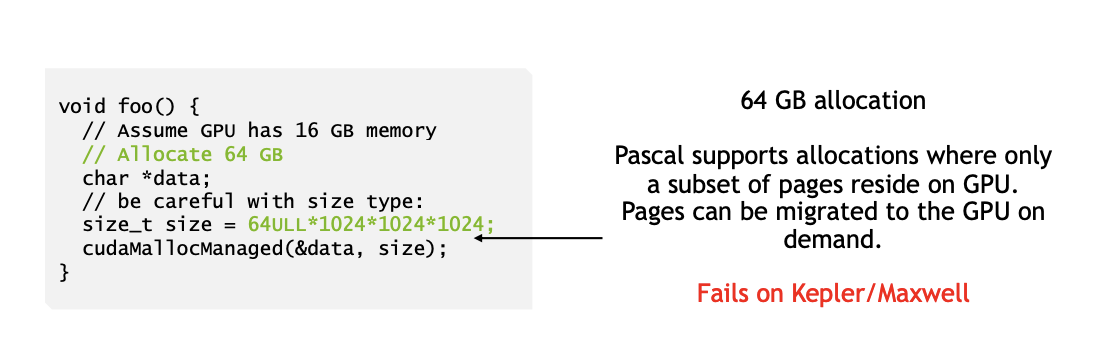
1. GPU Memory Oversubscription
2. Concurrent CPU/GPU Access to Managed Memory

⚠️ Although this works on
Pascal+due to page fault handling, CPU and GPU accessing the same page (e.g., data[0] and data[1]) is not truly parallel. data[0] and data[1] may seem independent, but they likely reside on the same 4KB page; in Pascal+, accessing one from the CPU while the GPU accesses the same page triggers a page fault and page migration, causing serialization and potential performance overhead—physical migration (e.g., via NVLink or PCIe) is still required unless system memory is truly shared, such as in Jetson devices.
3. System-Wide Atomics

7. CUDA Concurrency
Pinned Host memory
= Page-locked Memory
- Host Memory is pageable by default
- The GPU cannot directly access pageable host memory, because it can be page-fault.
So when transferring data from pageable host memory(CPU) to device memory(GPU):
- The CUDA driver allocates a temp pinned(page-locked) memory buffer.
- Data is copied from pageable -> pinned buffer -> device.
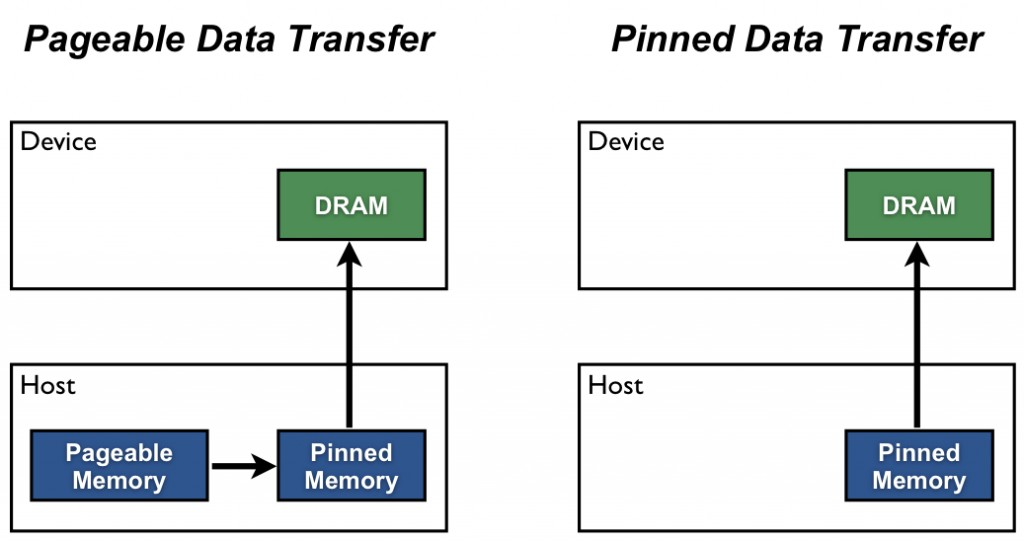
- Pinned mem acts as a staging area for host-device data transfers.
- To avoid extra copying overhead, allocate host memory directly as pinned
// 1. Alloc Page-Locked Memory
__host__cudaError_t cudaMallocHost ( void** ptr, size_t size )
__host__cudaError_t cudaHostAlloc ( void** pHost, size_t size, unsigned int flags )
// 2. Frees page-locked memory
__host__cudaError_t cudaFreeHost ( void* ptr )CUDA Streams
Kernel launches are async with CPU but cudaMemcpy block CPU thread. However cudaMemcpyAsync is async with CPU(Actually if host mem is not pinned, it still block). So it is able to concurrently(parallel) execute a kernel and a memcopy both.
A
Stream?
A stream is a sequence of operations that execute on the GPU inissue-order, meaning operations within the same stream run sequentially. However, ops from different streams may beinterleaved— that is, they(streams) can be executed in a mixed order by the GPU, either in parallel or through concurrent context switching.
- A kernel and
memcopyfrom different streams can be overlapped.
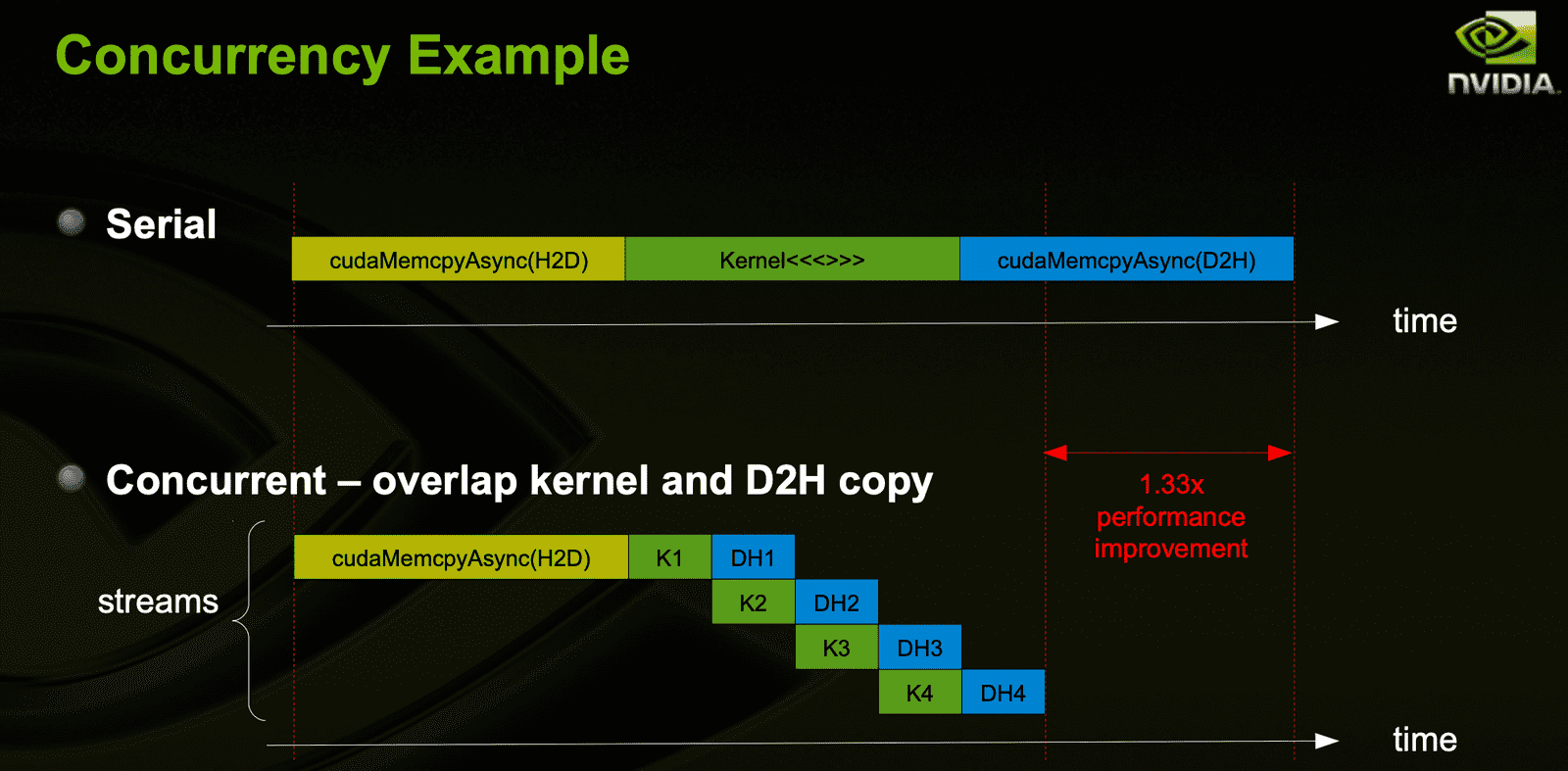
Overlappedin CUDA?
Possibly parallelly executed. (Possibly because of resource competition, HW limitation, scheduling, dependancy..)
Stream Semantics
- Two operations issued into the same stream will execute in issueorder. Operation B issued after Operation A will not begin to execute until Operation A has completed.
- Two operations issued into separate streams have no ordering prescribed by CUDA. Operation A issued into stream 1 may execute before, during, or after Operation B issued into stream 2.
Operation?
Usually,cudaMemcpyAsyncor akernel call. More generally, most CUDA API calls that take a stream parameter, as well as stream callbacks.
Example
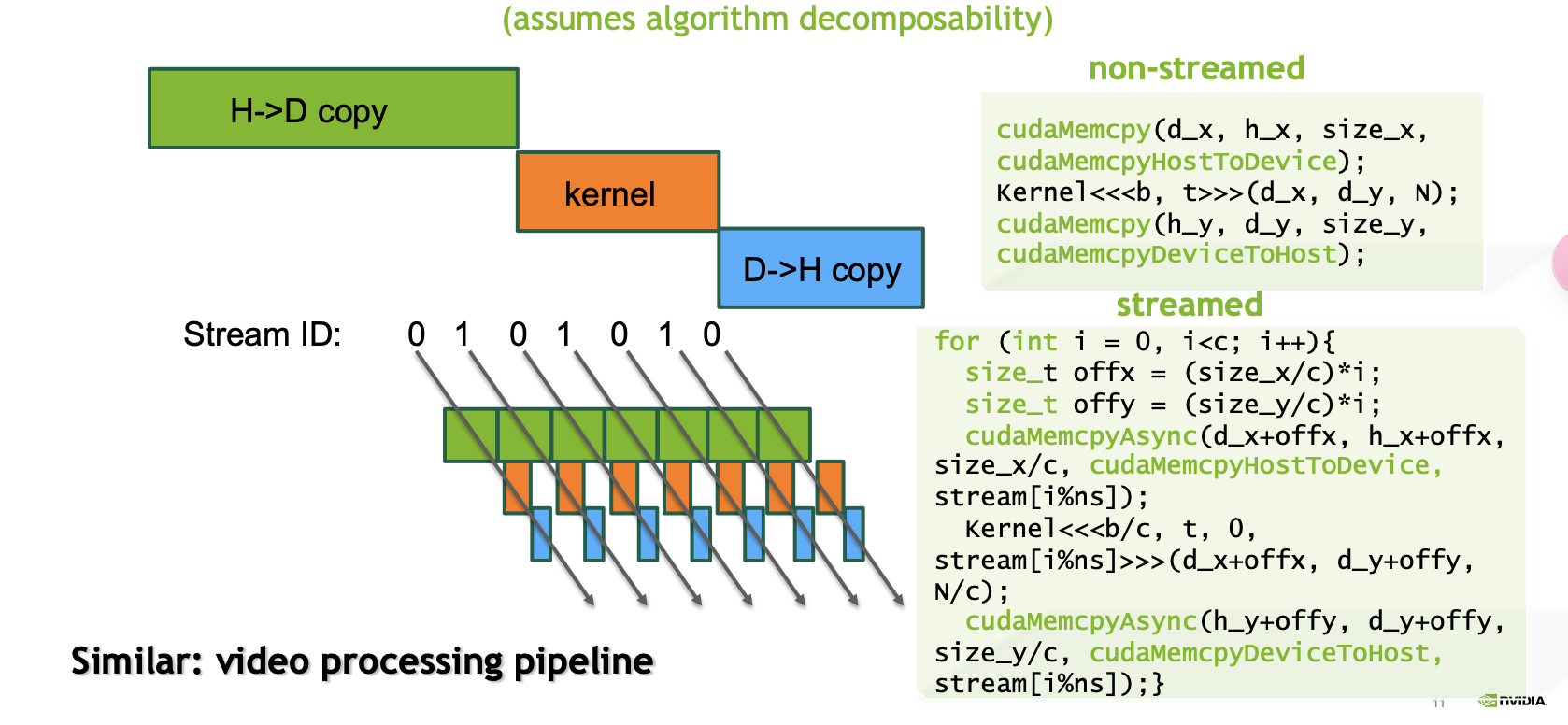
Default Stream

cudaLaunchHostFunc()
Stream Callbacks
It allows definition of a host code function that will be issued into a CUDA stream. Function will not be called until stream execution reaches that point. (It follows stream semantics)
cudaStreamAddCallback()is legacy ->cudaLaunchHostFunc()
- Uses a thread spawned by the GPU driver to perform the work.
- Useful for deferring CPU work until GPU rsults are ready
Limitations
- do not use any CUDA runtime API calls (or kernel launches) in the function
Overlap with Unified memory?
- use
cudaMemPrefetchAsync()instead ofcudaMemcpyAsync()-
cudaMemPrefetchAsync()has more overhead compare tocudaMemcpyAsync(), updating of page tables in CPU and GPU.
-
- still stream semantics will guarantee that any needed migrations are performed in proper order
