
So, as with most things, I thought this was going to be more difficult than anticipated.
Really - you can sit down and build your own web scraper in less than an hour with Ruby.
Plus, it's interesting and makes you feel like this:

Intro
Let's say I have a business and want to gather data for upcoming events. The data on websites is populated in different manners and can sometimes be deeply nested. Grabbing that first h4 element on every page isn't going to always return a nice little event title.
It would be nice if you could just grab "Event name" from your chosen websites and extract that pertinent data. Well, you sort of can with some work. I'm going to show you a simple down and dirty method that works for many websites.
This assumes you have some experience with Ruby, or simple understanding of request/response cycle so you can follow along.
In this follow-along we will:
- Create a simple Ruby project
- Understand and implement the Faraday gem
- Get custom results for slightly more complicated websites with the Nokogiri gem.
- Output our hard work to the terminal - yay!
Let's Begin!
I use VSCode and my screenshots will be from there is you want to follow.
Make sure you have Ruby installed by running ruby -v in the terminal. If you need to install Ruby check out the docs.
Make a folder called ruby_scraper and open it in your editor. Assuming you already have Ruby installed, run
bundle initto create your Gemfile.With Gemfile created, next make your ruby file. For simplicity I'll call it
scraper.rb
You should have one folder, ruby_scraper with your two files inside.
Install Faraday
According to the Faraday Docs:
"Faraday gives you the power of Rack middleware for manipulating HTTP requests and responses, making it easier to build sophisticated API clients or web service libraries that abstract away the details of how HTTP requests are made."
...cleaner, faster, and easily understood.
Sounds legit. Add Faraday to your Gemfile:
gem 'faraday', '~> 2.0'You know, or whatever version we are rolling with upon your reading of this. As of now it's 2.0-ish.
After adding the gem in your Gemfile, head to the terminal and run our favorite:
bundle installFor performance, you may want to install Faraday-Gzip, which allows faster transmissions and stuff for the performance-conscious.
In your Gemfile add:
gem 'faraday-gzip', '~> 3'In the terminal:
bundle installPause - If you want to create your response with JSON you can read the docs here about how that may need to look. But I prefer using the following Nokogiri gem for more serious digging.
Let's also install the Nokogiri gem, which allows you to more exactly pick data out of a web page - using CSS!
In your Gemfile add:
gem 'nokogiri', '~> 1.18'Then in terminal:
bundle installSuper exciting. Yes - you can grab that exact piece of data from a webpage using a css class name or id! This is SO useful. Many websites may not have an API for you to navigate. You have to make your own jerry-rigged pathway. Setting up my scraper I wondered: "What if I want a specific deeply-nested div from a page?" Nokogiri is your answer, assuming it has a class or id of some sort.
If you are navigating a classless website, well - probably just poke around with JSON. Most of what you will find today is going to have class names. Moving on...
Check your Gemfile
I had to install some additional gems to run bundler properly. Here's mine:
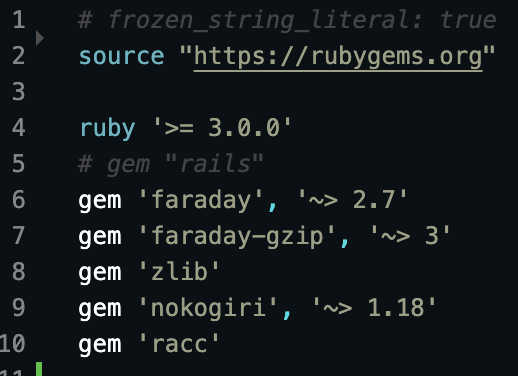
Check Folder Structure
The items highlighted in green are important, ignore the readme and png - they are not important here. You just want to make sure that Gemfile, Gemfile.lock (If new to Ruby - Do not mess with Gemfile.lock, it auto-configures with your bundling!) and scraper.rb are directly in the folder, no sub-folders.
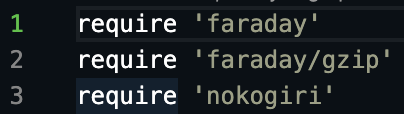
Ruby file setup
Pull in your required gems by adding them to the very top of your scraper.rb file.
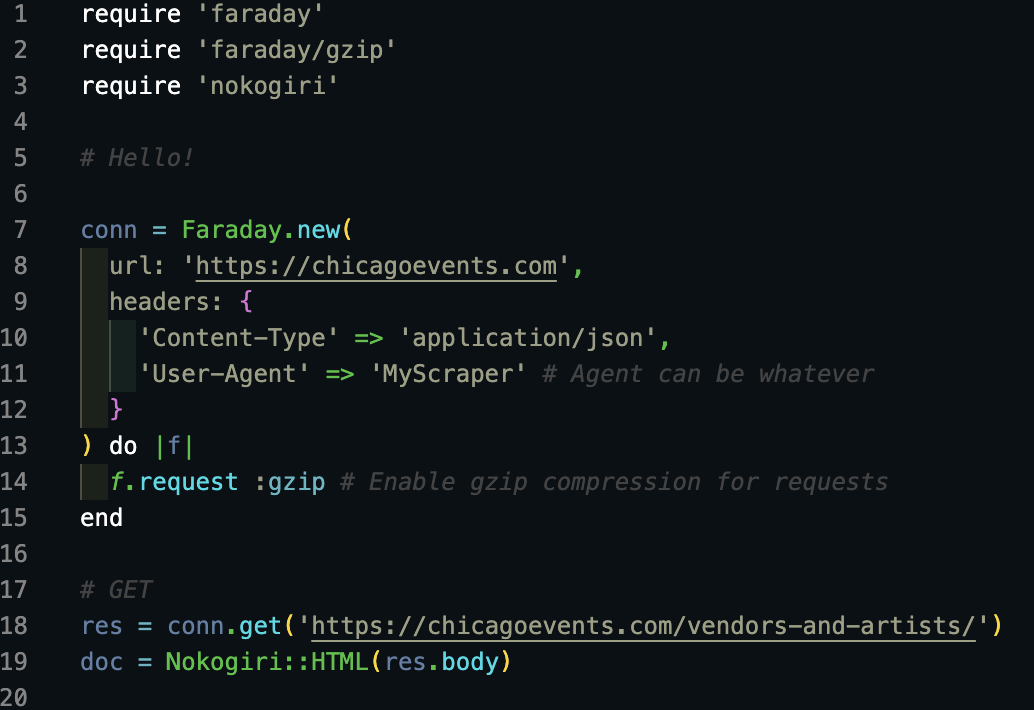
Lets setup our Faraday connection next. We need to know our base URL, our content type, create a user-agent name. Were gonna add a a little snippet at the end for gzip compression as well.
conn = Faraday.new(
url: 'https://chicagoevents.com',
headers: {
'Content-Type' => 'application/json',
'User-Agent' => 'MyScraper' # Agent can be whatever
}
) do |f|
f.request :gzip # Enable gzip compression for requests
endURL - https://chicagoevents.com - don't include a complicated path here. Just Base URL.
Content-Type will be application/json as Faraday will parse this.
User-Agent can be a name you create.
After that, we are going to make a connection to the specific web page we want:
res = conn.get('https://chicagoevents.com/vendors-and-artists/')
Then we wanna run the response through the Nokokiri gem so we can access items with CSS. Save it to a new variable so we can access it later.
doc = Nokogiri::HTML(res.body)
So far we have:
Picking out data
Let's take our doc variable, and essentially activate out ability to navigate the CSS on the page from a certain point. You will have to inspect your website of choice, and see where to start to grab all the data you want.
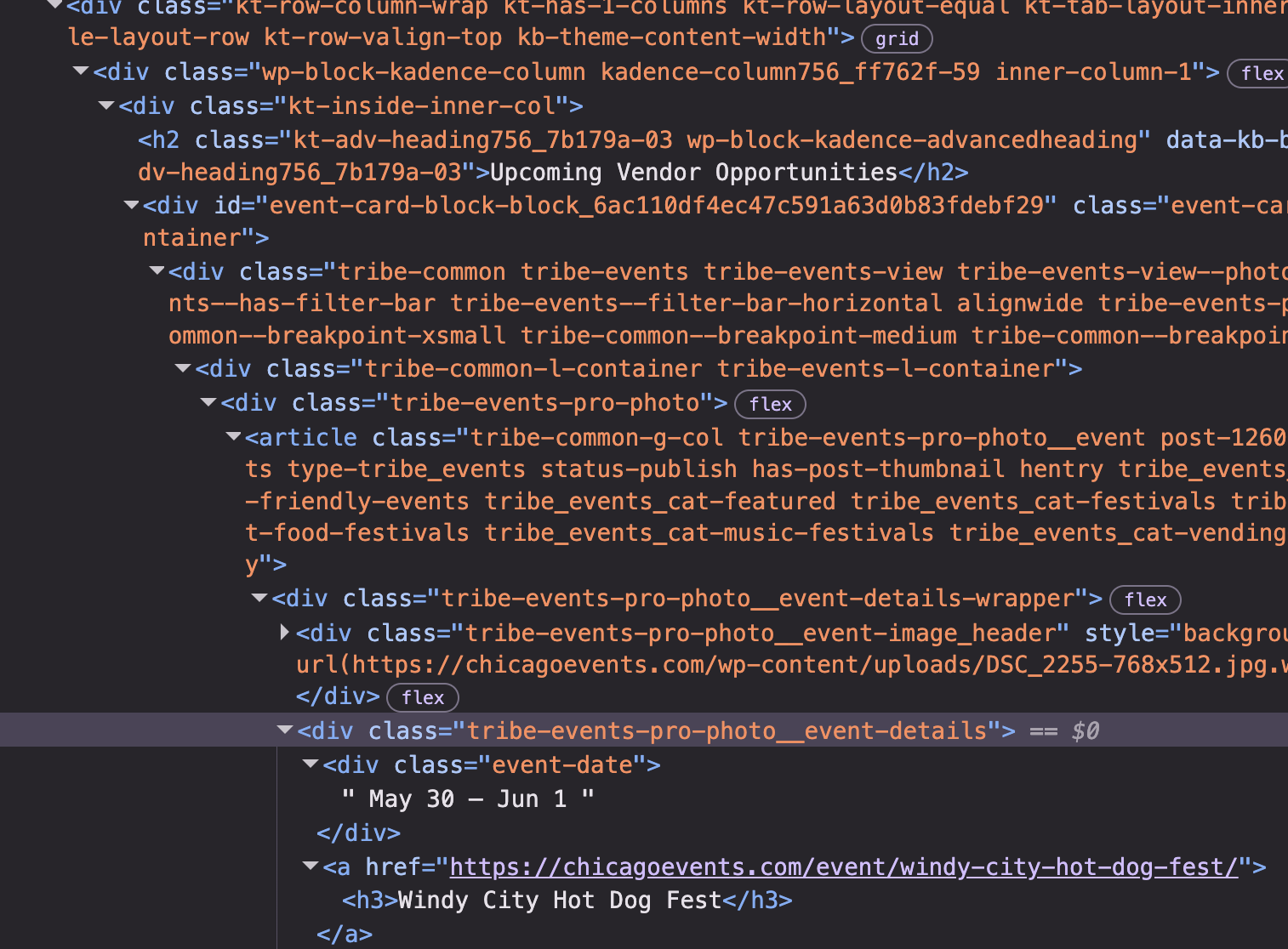
I see that all the data I want starts in places where the css class is .tribe-events-pro-photo__event-details. I set that as my CSS area of interest as such:
articles = doc.css('.tribe-events-pro-photo__event-details')Implement the loop
Now that I have my hot little hands on the interesting part, I can grab each one using a loop.
articles.each do |article|
# some code stuff
endI loop over each instance of this class occurrence, picking out items with classes or tags. In our loop we use article.at_css() method to make our selections. It's important to clean up or response to remove annoying whitespaces.
Let's get the event title. I see on my inspect that an h3 tag contains the titles. So I create a new variable, grab the h3 element, display and clean it up like in ruby.rb:
articles.each do |article|
title = article.at_css('h3')&.text&.strip
puts "Event: #{title}"
end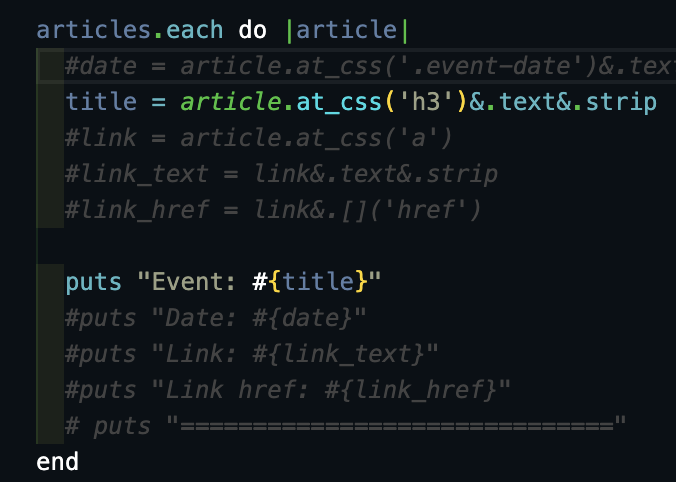
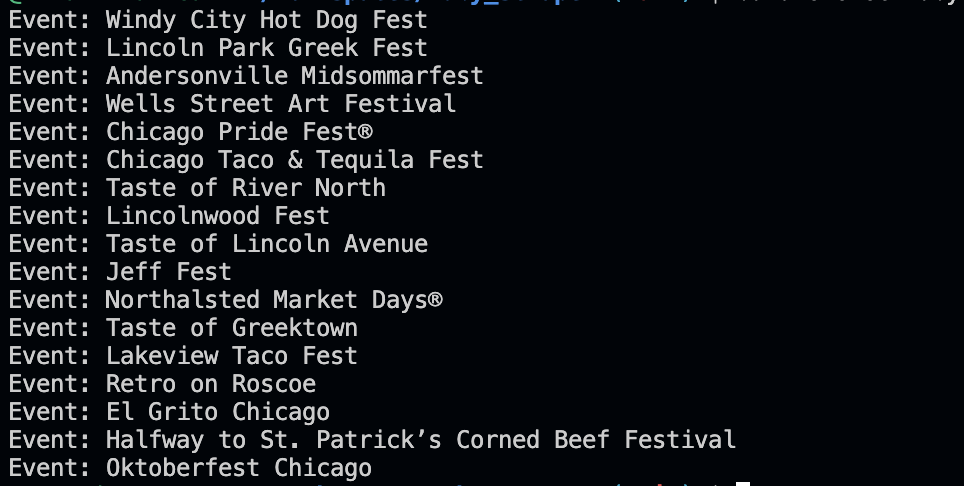
Run it using bundle exec ruby scraper.rb. It should be something like this:
Cater to your needs
Once you've got it working, you can easily add whatever your heart desires.
Here is an example of the full custom scraper:
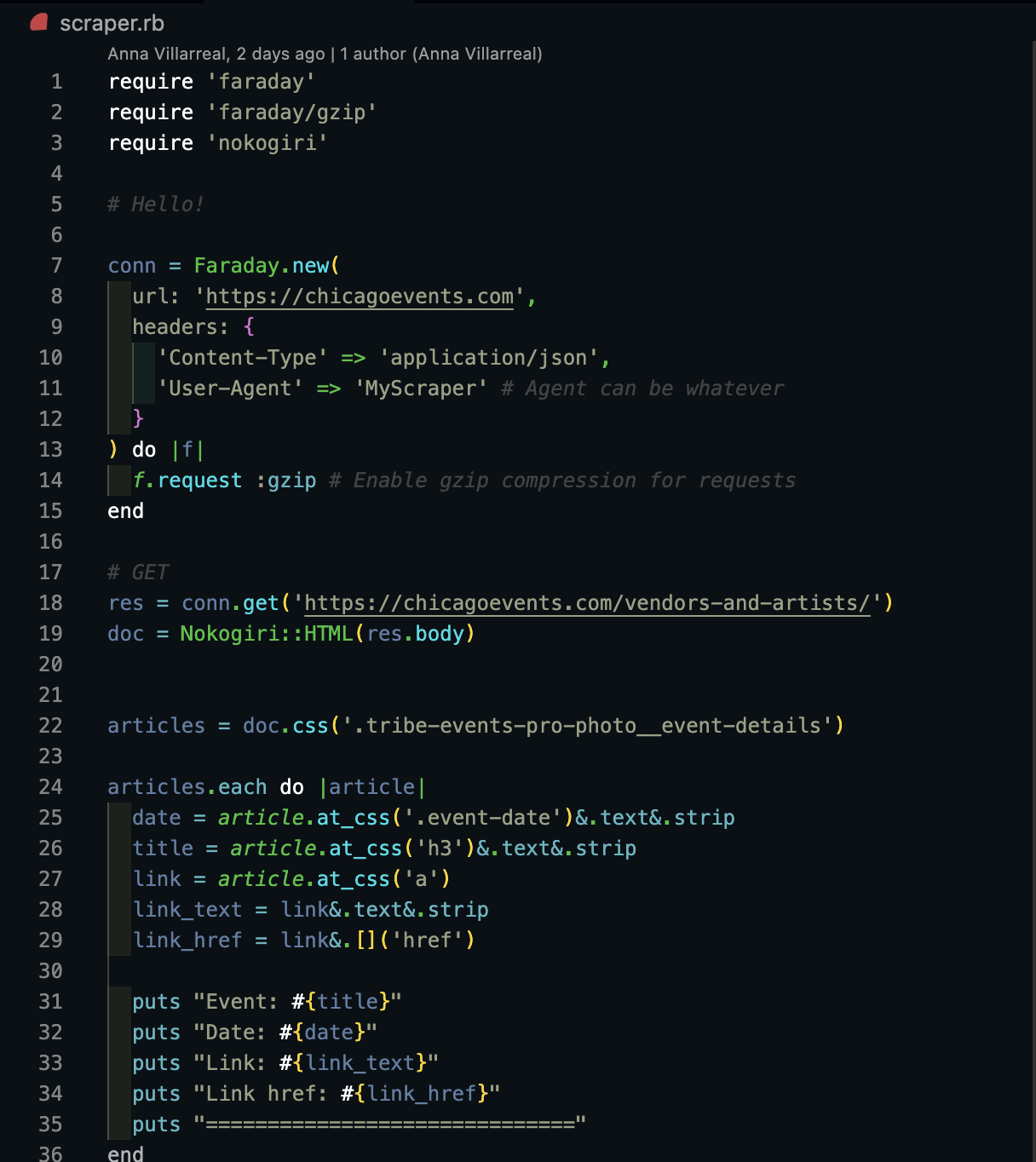
Then run bundle exec ruby scraper.rb again. Results output will be something like:
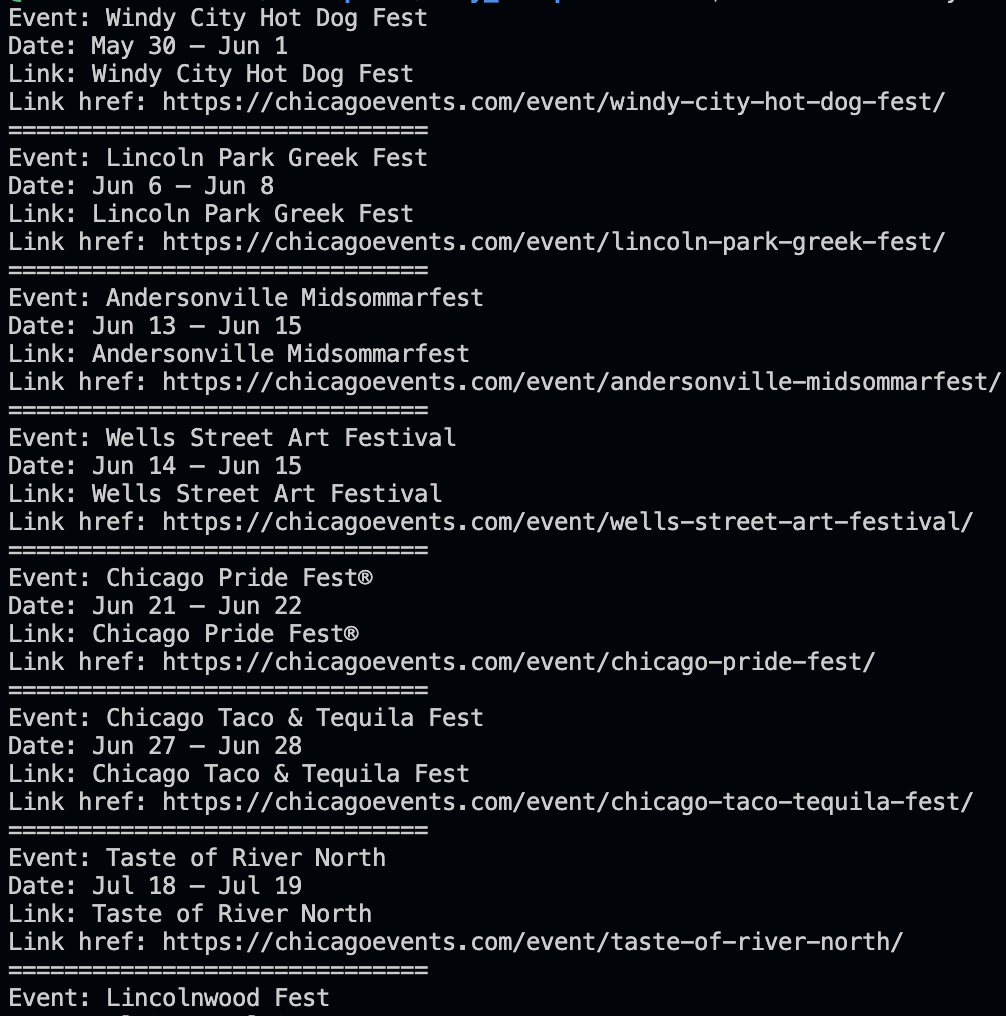
I highly recommend adding a line between each result to make your life visually easier.
Beast mode activate, pretty much.
