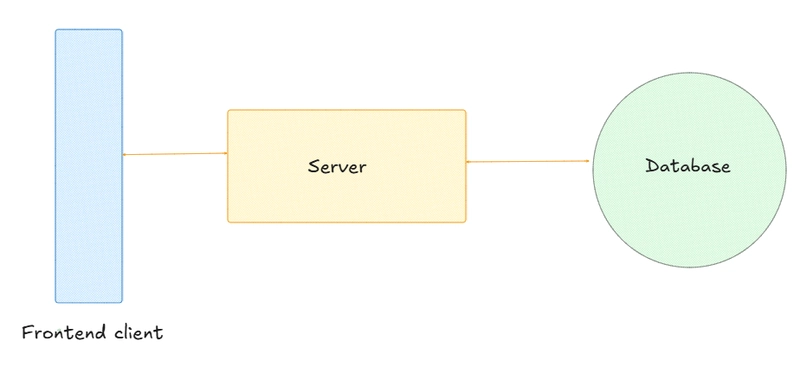
The system
When we start with designing large scale systems, we usually have a three tier set up. The frontend(client), backend(app servers) and the database server. We start development with such an idea and most of the time during development our architecture remains the same.
Once we deploy the application, we are faced with a certain problem: Scaling.
If our app, fortunately, manages to gather a bunch of users around the world and one day explodes, we'll have to make sure it's accessible to all the users who try to access our services.
Scaling Servers
Scaling strategies largely depend on the nature of your system and the type of data you handle.. You might have come across scaling app servers, which involve vertical and horizontal scaling along with caching.
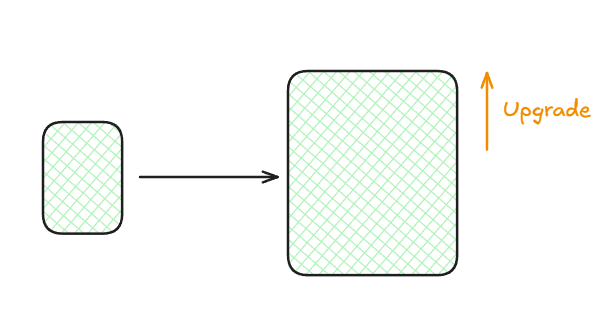
Vertical scaling: We simply have one server but we upgrade it with more powerful hardware to handle more processes. For example, upgrading RAM from 32GB to 64GB (illustrative numbers — actual upgrades may vary depending on system needs).
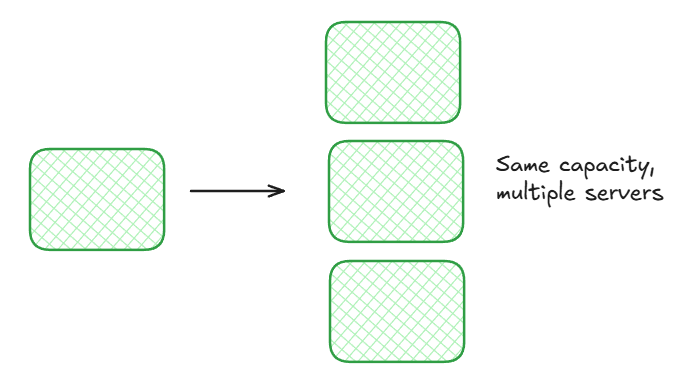
Horizontal scaling: We add more servers to the server segment and add a load balancer between the client and servers to redirect requests to all the different servers available.
Database Scaling
Similar to scaling app servers when facing high request loads, we need to to scale the Database server as well to handle high loads of write and read requests. Scaling databases can be a bit different from scaling app servers. The app server handles client request and communication to the DB, i.e. it handle the business logic while databases hold data to be persistent for reads.
Let's say the current database we have, can handle around 100wps. If at all when traffic is high and our app needs to handle 300 wps, we can't do that, since our server can handle only a load of 100wps. At this point, we need to scale our database.
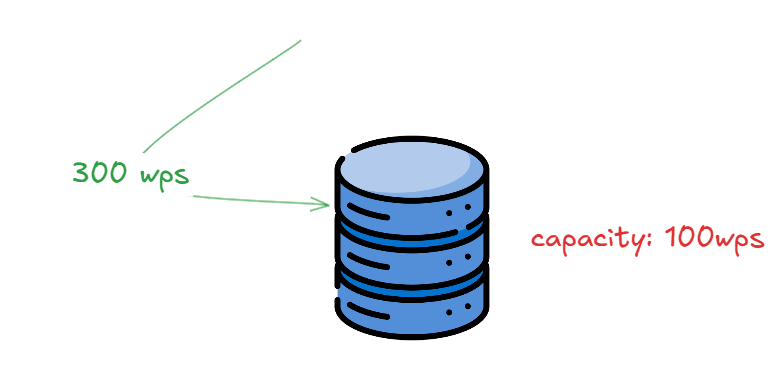
Now one option is to upgrade the database server to handle more wps(Vertical scaling), but there is a capacity limit to which we can upgrade a system due to hardware constraints. So let's say the maximum we can upgrade our database server is to 250wps. So scaling only vertically wouldn't help us here
We still need 300 wps and it might only get bigger from here on!
Let's look at basic horizontal scaling now. So if one server can handle 100 wps and we need to handle 300 wps, then we can set up 3 servers each handling 100 wps right? Not quite.
Remember that we're talking about databases here and each database has to have all the data that the server expects. So writes have to be made to all three databases and we'd still end up with 3 100wps servers trying to handle 300 wps each, which isn't going to work.
There are a bunch of ways we can solve this, one of them being Database Sharding..
Database Sharding
Database sharding is similar to the horizontal scaling we just discussed above, but instead of creating read replicas i.e. entire new databases that retain all data, we partition the data into several chunks and each new server will hold a chunk of data(partition).
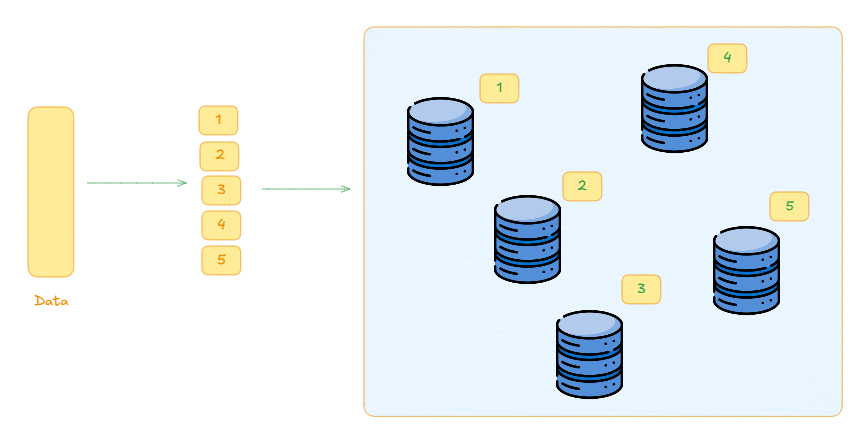
the data is split into 5 partitions that are distributed across the database shards
Since now we have 5 database shards, the incoming requests can be routed into the different available databases, much like load balancing.
Say if we get 500wps, and we shard based on the user's ID(userID). Then we can find which database to write by using:
userId % 5In this case each DB in the cluster of 5 shards would get 100 wps each and hence we'll be able to handle the requests properly.
We use a shard key to determine to which shard a write must be written to and choosing the proper shard key is crucial to ensure proper functioning of the system.
If we used the shard key based on user's location for an app that had 95% of the userbase from one single region, we're not exactly optimizing anything with sharding. A location based shard key would be appropriate for systems where the user base is distributed evenly across all regions.
You might have noticed that while discussing sharding we were mostly concerned about the writes-per-second or wps. Sharding is a write scalability technique that is used to optimize efficiency during writes and hence is a good fit for systems that are write heavy.
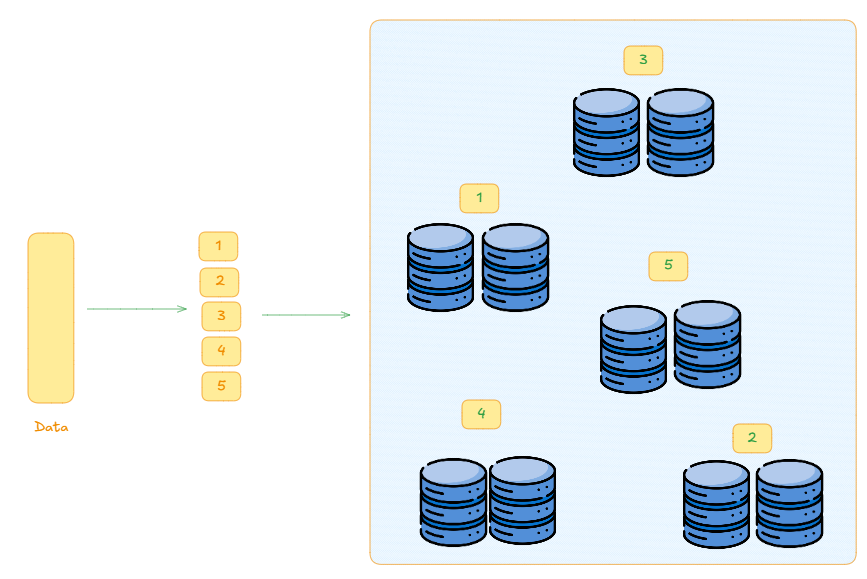
The earlier technique we discussed about having read replica's, i.e. multiple copies of the same database server can be used for read heavy systems where the no of reads per second are far more than writes.
Scaling Shards
Since each shard acts like a separate server, we are also introduced to the issue where if a shard fails, the data in the shard becomes unavailable since only that shard had the specific data. For example, if we performed sharding on our database based on location, i.e. people from India would have one shard and people from Singapore would have another and likewise for other regions. If the shard for India failed, everyone in India would lose access to that data and the app would crash in India.
To prevent this we can simple horizontally scale each shard and have multiple shard servers for each shard. It is important to note that this is an expensive operation and the trade-offs based on expense should determine which action should be taken.
Sharding challenges
It is also important to note that once a set of shards are set up, it is quite challenging to change the architecture and the process might get expensive. If we have three shards where we write data using 'some id' % 3, then if we have to add another shard, complications may arise.
For example,
if we had 3 shards initially,
shard for id 1234 = 1234 % 3 = 1
but if we decided to add another shard, so that the total no of shards becomes 4
shard for id 1234 = 1234 % 4 = 2
that means now we have to move data in all the shard to the new shards based on the new modulo which can get quite expensive and might bring down the servers for some time. This is also an issue if you decide to remove a shard.(We can tackle this issue using a technique called Consistent Hashing)
Sharding also makes joins across tables very expensive if the tables are present in different shards and cause major issues in systems that rely on a lot of cross-joins.
In sharded systems, maintaining strong transactional guarantees (ACID) across shards also becomes challenging.
So it's crucial to understand your system's needs before choosing a scaling strategy like sharding.
Before you shard, ask: do you really need to?
Many systems can scale further using replication, caching, partitioning, or query optimization which are all simpler than dealing with cross-shard joins and data movement. Sharding is powerful, but it should be your last resort, not your first option.
