Why Replication Matters
Database replication plays a crucial role in ensuring that business systems remain resilient, responsive, and reliable. For modern companies, data is at the heart of nearly every operation — from handling customer transactions to running analytics and decision-making tools. If the primary database fails, even for a few minutes, it can lead to lost revenue, broken services, and a damaged reputation. Replication helps prevent this by creating and maintaining exact copies of the database (replicas) on other servers, often in real-time. These replicas can be used for failover, meaning if the main system goes down, a replica can immediately take over with minimal disruption.
Beyond disaster recovery, replication supports performance and scalability. In high-traffic environments, read-heavy operations (like showing product listings or dashboards) can be redirected to replicas, easing the load on the primary server. This is known as read scaling, and it's especially valuable for applications with many users or global reach. Replication also enables data locality — storing copies closer to users in different regions — which reduces latency and improves user experience. Additionally, developers and analysts can run heavy reporting or analytics on replicas without affecting the main production system, which ensures better system stability. In essence, database replication is a foundational practice for building systems that are fast, fault-tolerant, and future-ready.
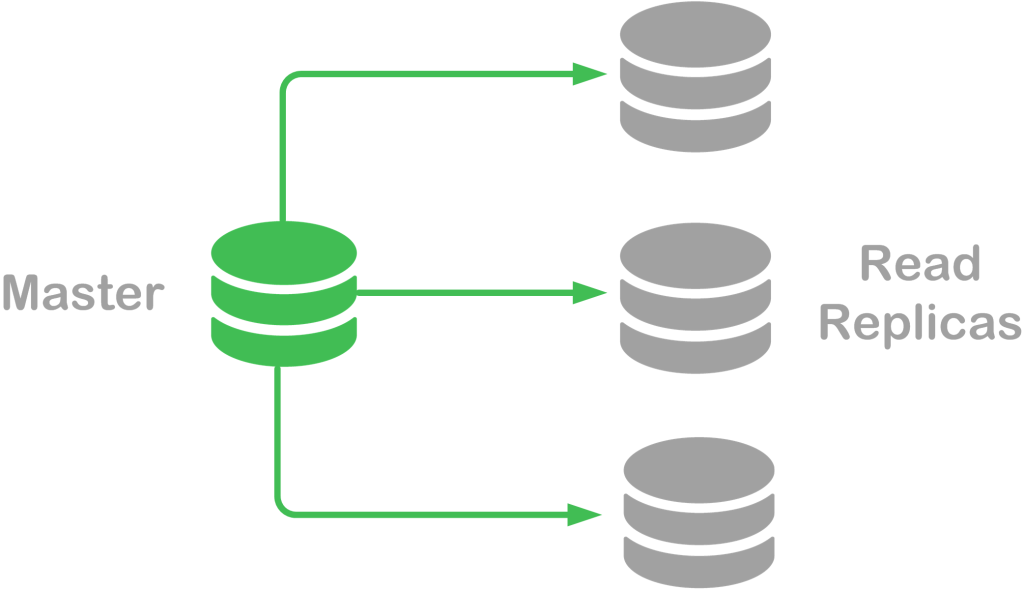
Replication Topologies
In distributed systems, replication is a key technique used to enhance availability, fault tolerance, and performance. The structure and behavior of data replication are determined by the replication topology, which defines how data flows and is synchronized across multiple nodes. Each topology offers a different balance of consistency, latency, scalability, and complexity, making it suitable for various types of applications. Below are the main replication topologies, along with their advantages, disadvantages, and real-world examples:
1. Single-Leader
In a single-leader replication topology, one node, called the leader, handles all write operations, while one or more replica nodes handle read operations by copying data from the leader. This setup ensures strong consistency because all writes go through a single node, which makes it easier to reason about system state and resolve conflicts. However, the leader becomes a single point of failure—if it goes down, the system cannot process writes until a new leader is chosen. Additionally, write throughput is limited by the leader's capacity, and there may be read inconsistencies if the replicas lag behind.
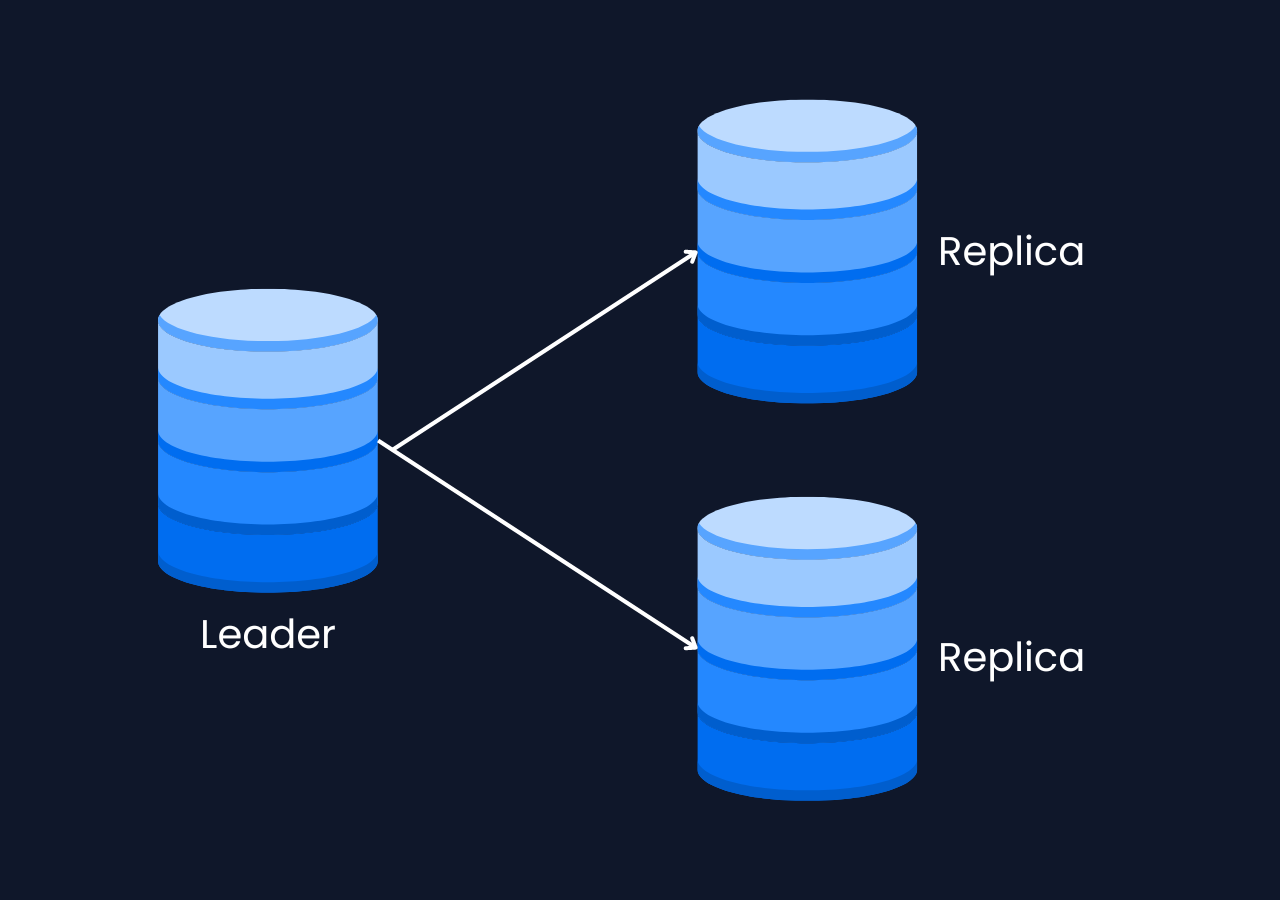
🤓 This topology is ideal for systems where strong consistency is a priority and write operations need to be tightly controlled, such as financial applications or systems where it is critical that all data changes are reflected correctly. It is also useful when read scalability is needed, as replicas can handle read-heavy workloads without affecting the leader's performance.
2. Multi-Leader
A multi-leader topology allows multiple nodes to accept write operations and synchronize with each other. This setup is particularly beneficial for geographically distributed applications, where users across different regions need to perform updates with minimal delay. By having multiple leaders, the system can offer better write availability and reduce latency for users who are far apart. However, this topology introduces the challenge of conflict resolution, as multiple nodes may try to write to the same data simultaneously, and syncing those changes becomes more complex. There’s also the risk of data divergence if synchronization between leaders is delayed.
🤓This topology is most useful for geo-distributed applications that require low-latency writes, such as collaborative platforms or social media apps where users across different regions need to interact and update data simultaneously without waiting for a central leader to process the changes.
3. Leaderless
In a leaderless replication topology, every node is equal and can accept both read and write operations. Consistency is typically achieved through consensus protocols, such as quorum-based approaches where a majority of nodes must agree on a change. There is no designated leader in this model, so the system avoids the single point of failure that exists in other topologies like single-leader. However, leaderless replication may introduce eventual consistency, meaning that data might not be immediately consistent across all nodes, especially in cases of network partitions or concurrent updates. Conflict resolution can also be more complex, especially as the number of nodes increases.
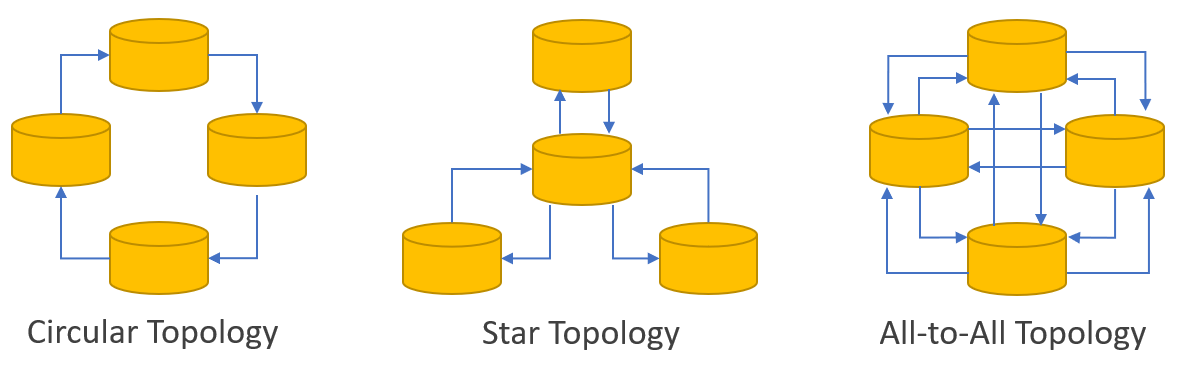
Leaderless replication can be implemented in several configurations, each with its own advantages and trade-offs. Three common configurations are star, circle, and all-to-all:
Star - In this setup, one node acts as a central hub that coordinates communication between other nodes. The central node may not necessarily handle all writes, but it ensures that the data is synchronized across all nodes. This configuration reduces the complexity of having every node communicate with each other but can introduce a single point of failure at the central hub if not managed properly.
Circle - The nodes are arranged in a circular fashion, where each node communicates with its immediate neighbors. When a write happens, it propagates through the circle of nodes until it is agreed upon by a majority. The circle setup helps distribute the load more evenly compared to the star configuration, but there is still potential for delays in synchronization due to the sequential nature of the communication.
All-to-All - In an all-to-all setup, each node communicates directly with every other node. This configuration allows for high redundancy and fault tolerance, as there is no central point of communication. However, it can be complex to manage because the system must ensure that all nodes agree on data changes, which can lead to conflicts and synchronization issues in larger networks.
🤓 This topology is ideal for highly available, partition-tolerant systems where eventual consistency is acceptable. It is often used in systems that require horizontal scaling without a single point of failure, such as large-scale e-commerce websites or distributed data storage systems that need to handle massive traffic loads without downtime.
Replication Strategies
When it comes to database replication, the strategy you choose will depend on your business needs and how you want your system to function. Here are the most common replication strategies:
Full Replication
In full replication, every replica of the database contains an identical copy of all data. This means that each server stores a complete version of the database, ensuring that data is always available across multiple locations. This approach is particularly useful for systems where high availability and fast access to all data are critical. It’s like having several backup copies of everything in the database.
Partial Replication
Partial replication is when only a subset of the database is replicated to each server. Instead of duplicating the entire database, each replica holds only part of the data that’s needed for its specific use case. For example, one server may hold customer data, while another holds order information. This approach is more efficient when certain types of data are accessed more frequently than others.
Snapshot Replication
Snapshot replication involves periodically taking a snapshot (or copy) of the database and sending it to the replicas. Rather than constantly updating the replicas in real time, the system refreshes the replica at set intervals—such as once a day or once an hour. This is useful when you don’t need constant updates, but want to ensure that all replicas are eventually up-to-date at specific times.
Transactional Replication
Transactional replication is a more dynamic approach where data changes (such as inserts, updates, and deletes) are continuously propagated to the replicas. This ensures that all replicas remain in sync with the leader server in near real-time. Whenever there is a change to the database, whether it's adding a new record or modifying an existing one, those changes are immediately reflected across all replicas. This is ideal for applications that require near-instant consistency across all nodes.
Merge Replication
Merge replication allows multiple replicas to independently modify the data. Changes made at different nodes are later merged together to maintain consistency across all replicas. This approach is especially useful in scenarios where different users or locations need to make updates simultaneously, such as collaborative platforms or distributed systems. Once the data is merged, any conflicting changes are resolved using pre-defined rules to ensure consistency.
🤓 Each replication strategy serves a different purpose, and choosing the right one depends on your system’s needs. For businesses that require high availability and low latency, full replication might be the best option. For applications with less critical real-time data needs, snapshot replication might be a more efficient choice. On the other hand, transactional replication works well for systems that require consistency and real-time synchronization. Merge replication is perfect for systems where independent data changes are common, and data needs to be synchronized later.
Synchronous vs Asynchronous Replication
In the world of database replication, one of the most important decisions revolves around timing: when should data be copied from the primary node to its replicas? This decision shapes the system’s performance, consistency, and resilience — and it boils down to two main strategies: synchronous and asynchronous.
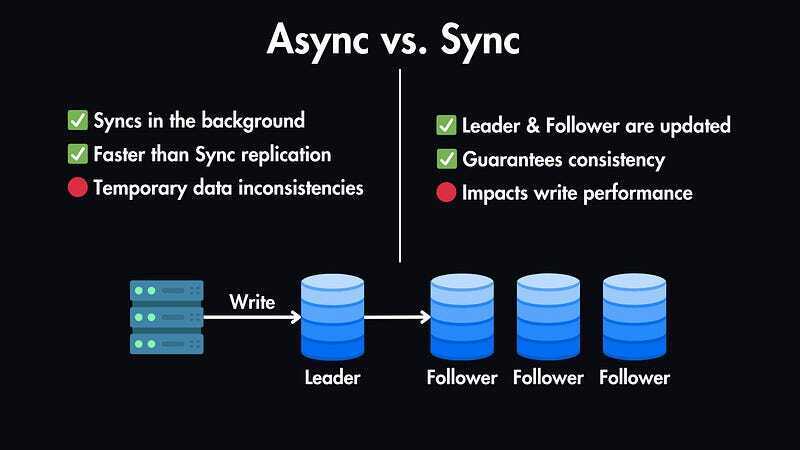
Synchronous Replication
Synchronous replication means the primary database and its replicas stay perfectly in sync at all times. Every time a user performs a write — like submitting a transaction or saving a form — that change must be successfully written not only to the primary database but also to one or more replicas before the transaction is confirmed as complete. In other words, the user has to wait until the data is safely stored in all participating databases.
The main benefit of this strategy is strong consistency. You can be confident that if a node goes down, no recent transactions will be lost — all copies are up-to-date. This is essential in systems where data integrity is critical, such as banking, medical records, or inventory systems. But the cost of this safety is performance: every write is slower, and system responsiveness can suffer if any replica is slow or unreachable. In extreme cases, a single failed node might prevent new transactions from being processed at all.
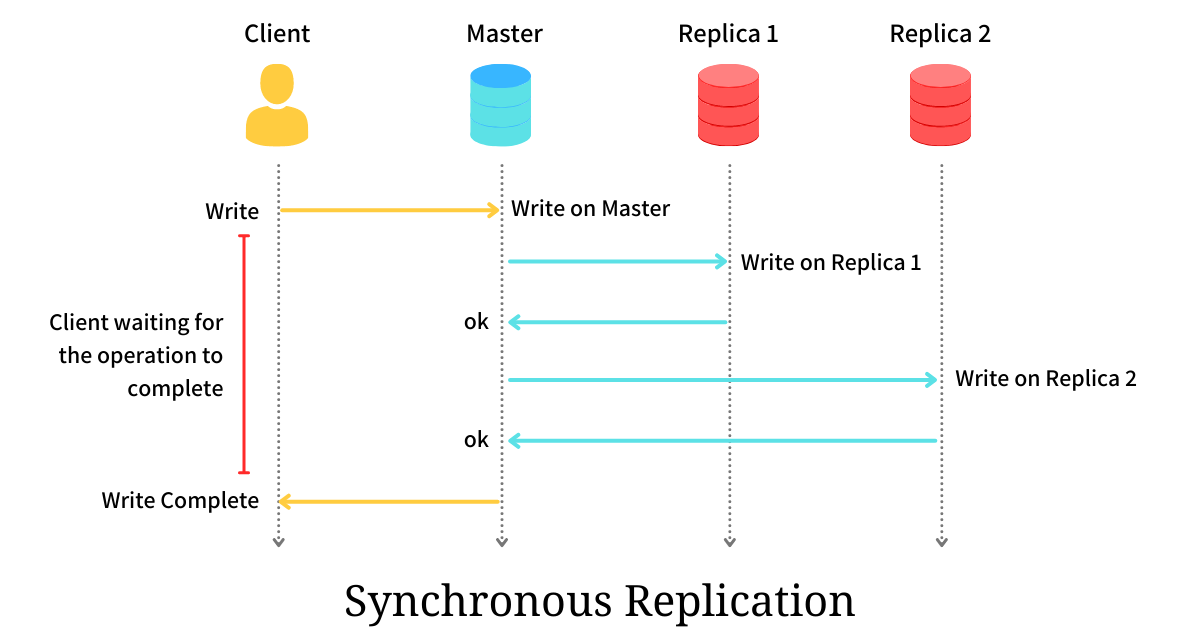
👷🌎 Example 🌎👷
Online banking platforms and financial exchanges are textbook cases for synchronous replication. In these environments, even a tiny inconsistency — like a payment not registering or a trade executing twice — can result in major financial and legal consequences. Therefore, maintaining perfect synchronization is worth the performance trade-off
Asynchronous Replication
Asynchronous replication takes a different approach: it prioritizes speed. When a user submits a write, the primary database processes and commits the change immediately, without waiting for replicas. The changes are sent to replicas afterward, in the background. This dramatically improves performance and responsiveness, making it ideal for systems with very high throughput or where users are distributed globally.
However, this speed comes at the cost of eventual consistency. If the primary node crashes before all changes reach the replicas, there’s a risk of data loss. This is acceptable in use cases where perfect, real-time consistency is less important — for example, in social media apps, content platforms, or analytics dashboards, where occasional data lag isn’t a major concern.
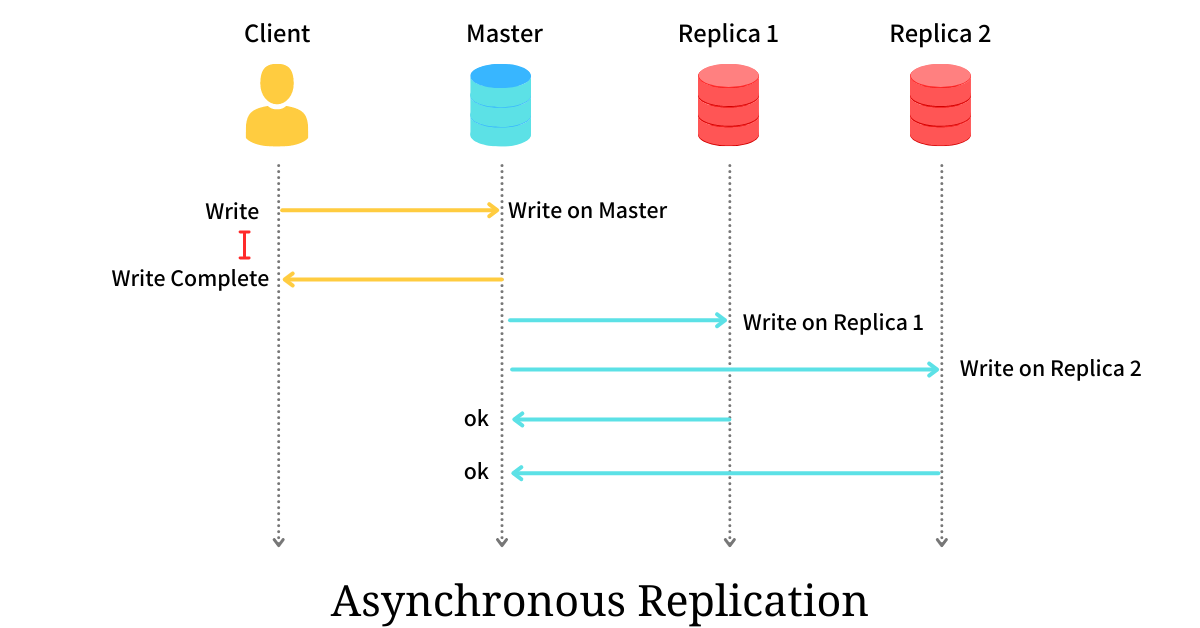
👷🌎 Example 🌎👷
Instagram’s “like” system is a great example of asynchronous replication in action. When you double-tap a photo, your like is recorded instantly, giving you fast feedback — but the update might take a second or two to appear for your friends or even disappear briefly during high load. That’s okay, because likes are non-critical data. Prioritizing speed over strict consistency enables Instagram to serve billions of actions per day efficiently without slowing the user experience
Database Backup vs Replication
Though often mentioned together, database backup and replication serve very different purposes in a data infrastructure. Understanding their roles can help businesses make smarter choices when designing systems for reliability, disaster recovery, and performance.
Database Backup
Backups are periodic snapshots of your database, usually stored in a separate location from the original system. Their primary goal is data recovery — if something catastrophic happens (like accidental data deletion, or corruption), you can restore your system to a previous, known-good state.

👷🌎 Backups are ideal when you need long-term recovery options or protection from human error. They’re also essential for compliance in industries where historical data must be retained, such as healthcare or finance.
Database Replication
Replication, on the other hand, is about maintaining live copies of your data across multiple servers in real time or near-real time. It’s designed for high availability, load balancing, and fault tolerance. If one server goes down, another replica can immediately take over with little or no downtime. Unlike backups, replication doesn’t protect against logical errors — if bad data is written to the primary database, it’s usually also written to all replicas. Replication is about system continuity, not recovery from past states.
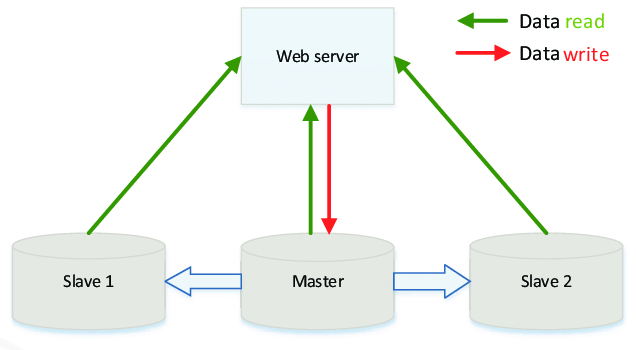
👷🌎 Replication is ideal when you need a system to stay online 24/7, or when you're serving global users and want to distribute read requests closer to them. It’s widely used in microservices, content platforms, SaaS applications, and any system requiring real-time access to data.
Considerations and Challenges
Helpful Links 🤓
Text resources:
- Database Replication
- Complete Guide to Database Replication
- Database replication: Definition, types and setup
Video resources:
