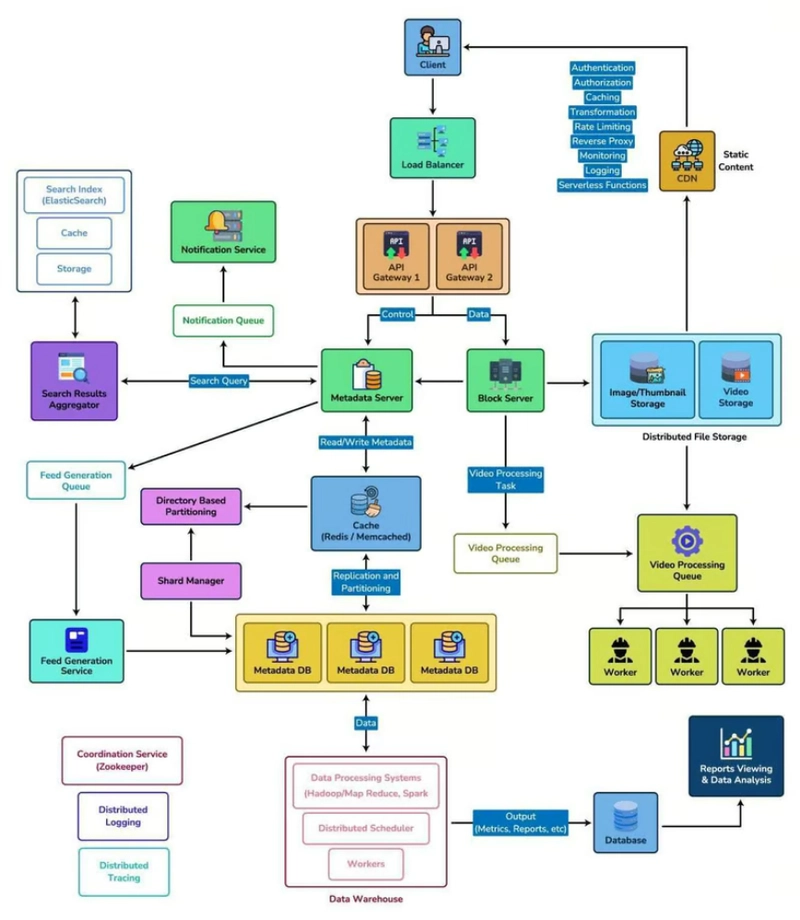
Problem
To prevent an unnecessary load, API requests should be throttled when made maliciously or due to an error.
Context
- The API Gateway of a distributed system runs in multiple instances, each with an in-memory state that does not allow tracking the current quota usage.
- Precise quota enforcement (per request, per second) is not critical; the goal is to prevent significant overuse.
- Quota configuration is static.
Forces
- No per request IO is allowed (centralized solutions do not fit).
- In a distributed system, there is no concept of a global current time.
- Failure to retrieve the quota state should not result in Gateway failure.
Solution
Implement in-memory quotas in each process, periodically synchronizing them asynchronously using Redis.
Consider a basic throttling rule:
- No more than
MAX_REQUESTSwithinINTERVALtime for any API route (KEY). - If the limit is exceeded, block requests to
KEYforCOOLDOWNseconds.
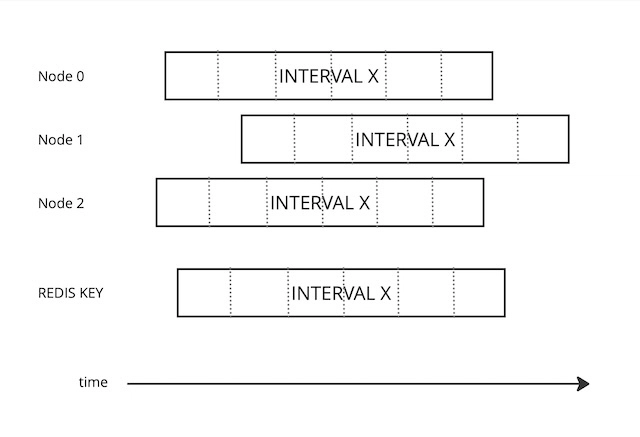
Concept
- Divide
INTERVALintoNspans (N >= 2). - At the end of each span, atomically increment the value in Redis (INCRBY) by the number of requests received for each
KEY, using a key composed of theKEYand the current ordinal number ofINTERVALin Unix epoch. - If the returned value exceeds
MAX_REQUESTS, block access toKEY, remove afterCOOLDOWN. - If the write operation fails and
REQUESTS > MAX_REQUESTS / N(i.e., the quota is exceeded locally), block access toKEY, remove afterCOOLDOWN.
Each API Gateway instance will generate the KEY based on its own local time, which, in general, will lead to simultaneous writes (from Redis’s local time perspective) to different KEYs. However, the total contribution of each node to each KEY will correspond to the actual request rate experienced by that node.
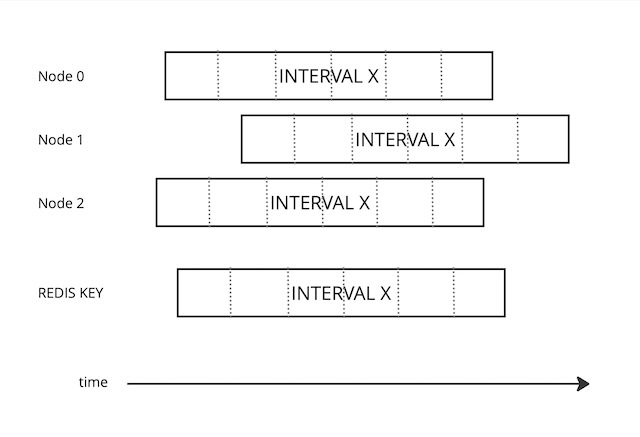
Dividing the INTERVAL into spans smooths the desynchronization effect.
Extension
Introduce nodes, the approximate number of active API Gateway instances, to improve the algorithm.
- Initially,
nodesequals to1. - During each
INTERVAL, sum the total request count for eachKEY, keep current and previous values. - At the end of each interval:
- Read the value from the
KEYfor the previous interval. At this point, it is assumed that all nodes have switched to the next interval. - Update the
nodesvalue by dividing response form Redis by the number ofREQUESTScounted for the previous interval. - Set the previous value to the current value.
- Set the current value to
0
- Update point 4 of the Concept:
REQUESTS * nodes > MAX_REQUESTS / N. This will increase the precision of the local quota enforcement. - Add a new step: if
REQUESTS * nodes > MAX_REQUESTS, block access toKEY, remove afterCOOLDOWN.
When nodes are added or removed, the algorithm will adapt in the upcoming intervals.
Caveats
- In the worst case scenario (really, really unlikely), the quota is exceeded by
MAX_REQUESTS / Nin a span on each node. - Time desynchronization between nodes should be insignificant for the selected
INTERVAL(i.e.,INTERVAL>> desync). See Extension point 3.