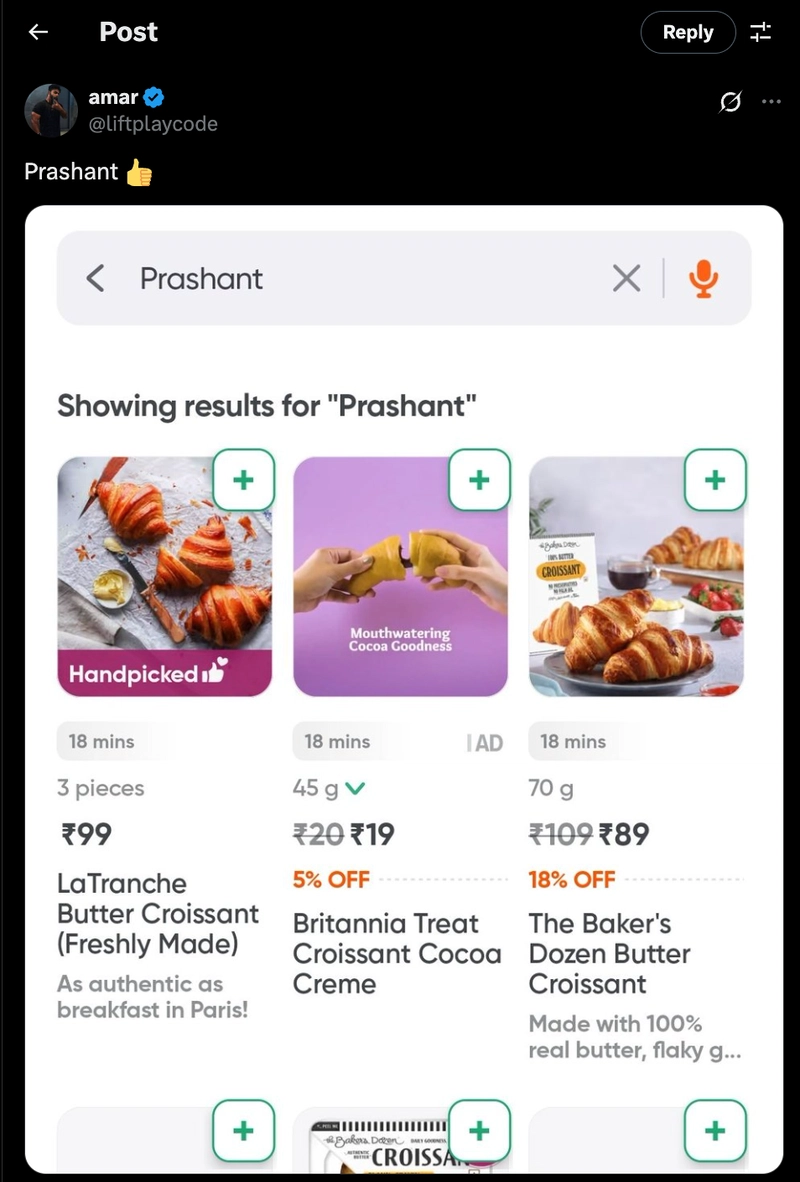
Saw a viral post on Twitter comparing "Prashant" and "Croissant" and it got me thinking — how exactly does search work? What logic is behind it?
Luckily, I follow Arpit who had already made a video breaking this down (I’ve linked that below). After watching it, I figured: why not try building something similar over the weekend? Surprisingly, it only took 2 hours because I already had a basic understanding of search algorithms.
To really get into this, I had to go deeper — here’s what I found:
🧠 Lexical Search
Lexical search is your classic, text-based search. It matches documents based on exact word matches.
How it works:
- Words are put into an inverted index — a data structure mapping words to the documents they appear in.
word 1 -> [doc1, doc2, doc3]
word 2 -> [doc1, doc4, doc5]Real-world example:
"optimization" -> ['git.pdf','codeofconduct.md','readme.md']
"CICD" -> ['azurefundamentals.pdf','readme.md']🔴 Limitations:
- Doesn't understand meaning or sound of words.
- One-to-one word mapping only:
"PullRequest" ≠ "PullRaquest"Common issues:
- Spelling variations:
Hrushi vs Hrishi vs Rishi vs Rushi - Typos/misspellings:
hrushikesh vs hrushkesh vs hrushiksh - Synonyms:
car vs vehicle,automobile vs SUV - Abbreviations:
AI vs Artificial Intelligence
🔍 Fuzzy Search
Fuzzy search handles typos or small spelling differences. It matches terms even when they aren’t exact.
Example:
Query: Prashant
Result matches (within edit distance ≤ 4):
- merchant
- elephant
- present
- variantEdit Distance is how many changes you need to convert one word to another.
🔊 Phonetic Search
Phonetic search matches based on how a word sounds, not how it’s spelled.
It uses algorithms like:
- Soundex
- Metaphone
- NYSIIS
How it works:
word -----------> phonetic key
"coffee" -------> KF (metaphone)Example:
mikaela -> MKL (Soundex)
micaela -> MKL (Soundex)
kristen -> KRSTN (Metaphone)
cristen -> KRSTN (Metaphone)✅ Strengths:
- Great for matching spelling variations that sound alike.
- Fast & doesn't need training data.
- Lookup is indexed and efficient (O(n) encoding).
⚠️ Concerns:
- Can lead to false positives — different words that sound similar can match.
Example:
text
"file" => Soundex: F400 | Metaphone: FL
"phile" => Soundex: P400 | Metaphone: FL
🧠 Semantic Search
Semantic search goes beyond words — it captures the meaning using NLP and embeddings.
How it works:
- Each word/sentence is converted into a vector.
"laptop" -> [0.25, 0.742, 0.1232, 0.5453]- Perform k-NN search to find the closest vectors (similar meaning).
Pre-reqs:
- Trained language model (like BERT, Word2Vec).
- Corpus for training (e.g., news articles).
✅ Strengths:
- Understands context.
- Matches concepts not present in the corpus.
For example, your data doesn’t have "laptop" but has "notebook" — it’ll still match!
⚠️ Concerns:
- Needs training and resources.
- Vector comparisons are resource-intensive.
- Approximation (ANN) may be needed for large datasets.
💡 Back to "Prashant vs Croissant"
None of the phonetic or semantic algorithms would match them — because:
prashant => Soundex: P625 | Metaphone: PRXNT | NYSIIS: PRASAD
croissant => Soundex: C625 | Metaphone: KRSNT | NYSIIS: CRASADThey're phonetically and semantically unrelated.
So how did that tweet match them?
💭 Solution: Manual Synonym Mapping
Define a custom synonym map.
1. When query is "prashant"
2. Expand to "prashant OR croissant"
3. Fire the expanded query
4. Elasticsearch returns docs matching eitherSimple and effective!
🔧 ElasticSearch Demo
I’ve created a full demo showing different types of search using AWS ElasticSearch. Check it out on GitHub.
References :
1) https://youtu.be/gZIVHSFgkvk?si=6YWgxL4PitvhZL8L
2) https://medium.com/@tzhaonj/metaphone-a-quick-and-efficient-method-for-fuzzy-name-matching-aaeb68d3c481