When analyzing issues with our internal npm registry, I was quite surprised how the package installation in npm works. This post summarizes the principles, analyzes the behavior using a sample package.json and points out some gotchas that you may encounter.
Disclaimer: I'm aware, that there are other (and newer) package managers available, but npm has still been widely used and at least for my work, I have no other choice.
Package registry
Before delving into the details of npm install, let's look briefly at the package registry, which provides the packages to install. You are well aware of the public registry at https://registry.npmjs.org/, but there are many other public and private registries as well.
API specification
The package registries provide simple REST API to get package metadata as well as actual package contents:
-
GET /{package}- Gets package metadata for all package versions.For example, https://registry.npmjs.org/react provides metadata about the react package. Notice, that the metadata is quite large. In this case, it is about 5.6 MB (1.2 MB compressed) at the time of writing. This is caused by the fact, that the metadata contains details for all package versions, which means 2,280 versions in this case.
-
GET /{package}/{version}- Similar to the previous one, but returns metadata just for a single version. The version must really be a single version, no floating versions like^19.0.0are supported.For example, we can get metadata for react version 19.0.0 using https://registry.npmjs.org/react/19.0.0. As there is just a single version, the metadata is much smaller - about 2 KB in this case.
-
GET /{package}/-/{package}-{version}.tgz- Gets actual package content as a single compressed tarball. This endpoint is not documented (and does not have to be), because it is referenced from the package metadata.For example, we can download react version 19.0.0 from https://registry.npmjs.org/react/-/react-19.0.0.tgz.
There are also endpoints used e.g. for package publishing, but these are not needed for package installation, so they are not mentioned here.
API behavior
It is obvious, that in general npm install can use only two out of these endpoints - the first one to get package metadata for all versions and the last one to get package content. The second one cannot be used in many cases due to floating package versions being requested. When evaluating floating versions, npm must use the first endpoint to get metadata for all versions and then evaluate the floating version locally.
Metadata endpoint
As we will need it later, let's analyze behavior of the first endpoint using curl:
curl -I -H 'accept: application/json' https://registry.npmjs.org/react
HTTP/2 200
date: Sun, 20 Apr 2025 19:52:23 GMT
content-type: application/json
cf-ray: 93372e8c4bdbf99e-PRG
cf-cache-status: HIT
accept-ranges: bytes
access-control-allow-origin: *
age: 141
cache-control: public, max-age=300
etag: "25b33cc1cc58fb5a156c19f2ec3408ca"
last-modified: Sun, 20 Apr 2025 01:17:26 GMT
vary: accept-encoding, acceptThe endpoint returns package metadata (not shown here) and a couple of headers. Out of these headers, we will further need the following ones:
-
cache-control- based on this header, the metadata should be cached for 300 seconds, i.e. 5 minutes. I have checked several packages and this value is the same for all of them, so it seems, that it is a common default. -
etag,last-modified- values of these headers can be used in the future to check, whether there is a new version available.
Let's try to use the last-modified header in another request:
curl -I \
-H 'accept: application/json' \
-H 'if-modified-since: Sun, 20 Apr 2025 01:17:26 GMT' \
https://registry.npmjs.org/react
HTTP/2 200
date: Sun, 20 Apr 2025 19:59:19 GMT
content-type: application/json
cf-ray: 933738b08aa0b377-PRG
cf-cache-status: HIT
accept-ranges: bytes
access-control-allow-origin: *
age: 254
cache-control: public, max-age=300
etag: "25b33cc1cc58fb5a156c19f2ec3408ca"
last-modified: Sun, 20 Apr 2025 01:17:26 GMT
vary: accept-encoding, acceptThe result is quite surprising. With the if-modified-since header, the server should have returned HTTP code 304 Not Modified, but we get 200 instead. You can try to use etag with if-none-match and the result is the same. Even when specifying both if-modified-since and if-none-match, HTTP 200 is still returned.
This means, that the public npm registry does not support effective checks of new versions. As we will see later, after the cache expires (i.e. after 5 minutes), the complete metadata has to be re-downloaded even if there is no change.
For the purposes of this post, I also have my own local npm registry running on Sonatype Nexus. The registry is set up to mirror content from the public https://registry.npmjs.org, so we can easily repeat the previous test:
curl -I \
-H 'accept: application/json' \
-H 'if-modified-since: Sun, 20 Apr 2025 01:17:26 GMT' \
http://localhost:8081/repository/npmjs/react
HTTP/1.1 304 Not Modified
Date: Sun, 20 Apr 2025 20:24:56 GMT
Server: Nexus/3.79.1-04 (COMMUNITY)
X-Content-Type-Options: nosniff
Content-Security-Policy: sandbox allow-forms allow-modals allow-popups allow-presentation allow-scripts allow-top-navigation
X-XSS-Protection: 1; mode=block
ETag: W/"25b33cc1cc58fb5a156c19f2ec3408ca"Now, HTTP code 304 is correctly returned. This means, that if the metadata is not modified, only a few HTTP headers (and no content) are transferred resulting in substantial bandwidth savings.
There is one more difference when comparing the behavior of my local Nexus with the public npm registry - my local Nexus does not return cache-control header. As a result, the client application (npm in this case) does not know, how long the returned data can be safely cached, so it has to use a heuristic algorithm, as we will see later.
Package content endpoint
The package content endpoint works similarly:
curl -I -H 'accept: text/html' \
https://registry.npmjs.org/react/-/react-19.0.0.tgz
HTTP/2 200
date: Sun, 20 Apr 2025 20:57:35 GMT
content-type: application/octet-stream
cf-ray: 93378e0f7e5771ef-PRG
cf-cache-status: HIT
accept-ranges: bytes
access-control-allow-origin: *
age: 1705545
cache-control: public, immutable, max-age=31557600
etag: "7860ab2d152873bfbc3e990b2bbc62da"
last-modified: Thu, 05 Dec 2024 18:10:24 GMT
vary: Accept-EncodingWe can see similar headers as for the package metadata:
-
cache-control- based on this header, the metadata is cached for 31,557,600 seconds, i.e. 1 year. Again, this value seems to be the same for all packages. -
etag,last-modified- values of these headers can be used in the future to check, whether there is a new version available
If we try to use the last-modified value to check for new version, the behavior is the same as for the package metadata endpoint - we get HTTP code 200 with the public npm repository and 304 with my local Nexus. And the cache-control header is also missing for Nexus.
Package cache
To optimize package installation, npm maintains local cache of package metadata and package content. This is described in the npm documentation. However, the documentation does not mention anything about the cache policy. It is not clear when a cache entry is considered stale and needs to be refreshed.
To analyze the cache policy, we can check the source code. The cache policy is implemented in the http-cache-semantics package in its index.js file. After analyzing this file, we can easily find out, that the cache behavior depends on the HTTP cache headers. Without any technical details, the principles can be summarized as follows:
- If there is
cache-controlheader withmax-ageparameter, then this value is used. This means, that package metadata fetched from https://registry.npmjs.org is cached for 5 minutes, while package content is cached for 1 year. 5 minutes for package metadata seems to be quite aggressive, but up-to-date metadata is probably more important than the extra bandwidth required for frequent checks. One year for package content is fine because the content should never change. - If there is no
cache-controlheader (as is the case for my local Nexus), the caching behavior is not defined by the server. In this case, the implementation uses heuristics defined in RFC 7234, which calculatesmax-ageas(current-time - last-modified) * 0.1. As a result, the data is cached one-tenth of the time elapsed since its last modification. For example, if the data was last modified 10 months ago, it will be cached for one month. If this behavior is not intended, it can always be overridden for example using a reverse proxy, which adds thecache-controlheader to standard headers returned by Nexus. Using this approach, the same behavior as for https://registry.npmjs.org can be configured.
The cache behavior can be observed when running npm install with the --loglevel=http option. The output then looks as follows:
npm http fetch GET 200 https://registry.npmjs.org/@testing-library%2fjest-dom 11ms (cache hit)
npm http fetch GET 200 https://registry.npmjs.org/@testing-library%2freact 5ms (cache hit)
npm http fetch GET 200 https://registry.npmjs.org/react 13ms (cache hit)
npm http fetch GET 200 https://registry.npmjs.org/react-dom 15ms (cache hit)
npm http fetch GET 200 https://registry.npmjs.org/@testing-library%2fuser-event 4ms (cache hit)
npm http fetch GET 200 https://registry.npmjs.org/@testing-library%2fdom 5ms (cache hit)
npm http fetch GET 200 https://registry.npmjs.org/react-scripts 4ms (cache hit)
...Cache behavior is shown at the end of each request as cache . Specific values are not documented, but based on my analysis of the npm source code, they are as follows:
-
cache hit- The requested data was found in the cache and was not fetched from the server. The HTTP status 200 in this case is misleading because there was no HTTP request sent. -
cache miss- The requested data was not found in the cache, so it was fetched from the server. -
cache revalidated- The requested data was found in the cache, but it is stale, so a request withif-none-matchandif-modified-sinceheaders was sent to the server. The server returned HTTP 304 without any data, so the cache item was marked as up-to-date. Similarly tocache hit, the log contains HTTP status 200, which is misleading. -
cache updated- Similar tocache revalidated, but in this case server responded with HTTP 200 and provided up-to-date data. -
cache stale- The requested data was found in the cache, it was identified as stale, but it was used anyway because, for example, cached data is preferred using--prefer-offlineoption. The HTTP status 200 in this case is misleading again because there was no HTTP request sent.
Installing packages using npm install and others
When installing packages using npm install (just plain npm install without any options is assumed), npm performs the following steps (see documentation):
-
package.jsonresolution -npmreads thepackage.jsonfile. - Package resolution - based on the direct dependencies specified in
package.json,npmcalculates complete dependency tree including transitive dependencies. If there is apackage-lock.jsonfile present, npm first checks, if the locked versions satisfy version requirements frompackage.json. If they do, thepackage-lock.jsonis used instead of resolving the dependency tree, otherwise the conflicts are resolved using the dependency tree. - Package download -
npmdownloads all missing packages used in the dependency tree. -
node_modulescreation/update -npmcreatesnode_modulesdirectory based on the dependency tree and the downloaded packages. If thenode_modulesdirectory already exists,npmupdates its content to reflect the dependency tree. - Scripts execution -
npmruns scripts defined in installedpackage.jsonfiles. -
package-lock.jsoncreate/update -npmcreates or updates thepackage-lock.jsonfile to reflect the installed packages.
But npm install is not the only command to install packages. Another command is npm update (see documentation), which behaves similarly to npm install. The key difference is in the way, how existing package-lock.json file is handled. npm update ignores the package-lock.json file, always calculates complete dependency tree and updates package-lock.json accordingly. If there is no package-lock.json file, npm update behaves the same as npm install.
The last package installation command is npm ci (see documentation). This command requires existing package-lock.json, but otherwise its behavior is similar to npm install. The key difference is in the way, how conflicts between package.json and package-lock.json are handled. npm ci does not try to resolve them, but fails instead.
Behavior of all package installation commands can be summarized using the following table.
| Scenario | npm install | npm update | npm ci |
|---|---|---|---|
No package-lock.json
|
Resolves complete dependency tree using package.json and installs resolved dependencies |
Same as npm install
|
Fails |
package-lock.json consistent with package.json
|
Installs dependencies based on package-lock.json
|
Same as with no package-lock.json
|
Same as npm install
|
package-lock.json inconsistent with package.json
|
Resolves dependency conflicts and installs dependencies based on package-lock.json
|
Same as with no package-lock.json
|
Fails |
Package installation behavior analysis
Now, we have all the important theoretical information about npm, so let's try to analyze package installation in more detail. To do this, we are going to install npm packages in multiple scenarios and observe npm behavior in each of them.
Environment
- Hardware
- CPU: Intel(R) Core(TM) Ultra 7 [email protected] GHz
- RAM: 32 GB
- Network bandwidth: 100 Mbps (this applies to my local Nexus registry as well)
- Software
- OS: Ubuntu 24.04.1 LTS (in a virtual machine)
- Node.js version: 22.14.0 (latest LTS version)
- npm version: 10.9.2 (bundled with the Node.js)
Scenarios
The tested scenarios are as follows:
-
npm ciwith no cache -
npm ciwith cache -
npm installwith no cache and nopackage-lock.json -
npm installwith no cache, nopackage-lock.jsonand--package-lock-onlyoption -
npm installwith no cache andpackage-lock.json -
npm installwith up-to-date cache and nopackage-lock.json -
npm installwith up-to-date cache, nopackage-lock.jsonand--prefer-onlineoption -
npm installwith up-to-date cache, nopackage-lock.jsonand--package-lock-onlyoption -
npm installwith up-to-date cache andpackage-lock.json -
npm installwith up-to-date cache,package-lock.jsonand--prefer-onlineoption -
npm updatefor the same scenarios asnpm install
Each of the scenarios will be run using the public https://registry.npmjs.org registry as well as my local Nexus registry.
package.json
In order to run each scenario, there must be a package.json file present. For this analysis, we will use the following package.json file. This is a real package.json file, that I've used when creating a simple demo of Recharts library.
{
"name": "recharts-random-data",
"version": "0.1.0",
"private": true,
"dependencies": {
"@testing-library/jest-dom": "^5.17.0",
"@testing-library/react": "^13.4.0",
"@testing-library/user-event": "^13.5.0",
"react": "^18.2.0",
"react-dom": "^18.2.0",
"react-scripts": "5.0.1",
"recharts": "^2.9.0",
"html2canvas": "^1.4.1",
"web-vitals": "^2.1.4",
"typescript": "^4.0.0"
}
}You may notice dependency on typescript version ^4.0.0, which is not really needed, it is only a transitive dependency of other packages. However, without this dependency, npm install installs typescript version 5.x and the following npm ci complains, that the generated package-lock.json is not in sync with the package.json. This seems to be a bug in npm, but as a workaround, the typescript dependency can be explicitly added.
The package.json generates node_modules directory with the following contents:
- Total number of packages: 1,507 (as reported by
npm install) - Total number of unique packages (excluding version): 1,168
- Total number of unique packages (including version): 1,317
- Total number of files: 41,087
- Total number of directories: 5,240
- Total file size: 258 MB
- Total used disk space: 387 MB
Observed metrics
For each scenario, we will observe the following metrics:
- Number of HTTP requests sent to the registry for each request type (package metadata and package content) and HTTP response code - see below for more details.
- Total size of the downloaded data with the same breakdown as for the number of HTTP requests - see below for more details.
- Number of duplicate HTTP requests - it may seem surprising, but
npmreally generates duplicate HTTP requests. This is probably connected with the fact, that the dependency tree is being resolved in parallel, but it still seems like a bug. - Total duration of the whole scenario
- Time to generate complete dependency tree - this information is provided when running
npmwith--timingparameter as a single log line with the following contents:npm timing idealTree Completed in 5800ms.
As we already know from previous sections, the npm log at the http level does not provide real HTTP response codes. Additionally, it does not provide the size of the downloaded data. And it seems, that there are no other command-line options, that would provide us with this information. So we need to add additional logging directly to the npm source code. The HTTP requests are handled by the minipass-fetch package, which can be easily extended by adding the following code to its index.js source:
let totalSize = 0;
res.on('data', (chunk) => {
totalSize += chunk.length;
return body.write(chunk);
})
res.on('end', () => {
console.log("minipass-fetch", url.url, res.statusCode, totalSize, headers.get("cache-control"));
return body.end();
});Here we calculate the total size of the download data (without HTTP headers) and log it together with the HTTP status code.
Tooling
To run the scenarios, I've created a simple Node.js script, which runs the scenarios one-by-one and for each of them performs the following:
- Cleans
npmcache usingnpm cache clean --forcecommand. - Removes
node_modulesdirectory andpackage-lock.jsonfile, which may have been created by a previous scenario. - Runs
npm install, if there are cached data orpackage-lock.jsonneeded for the scenario. - Cleans
npmcache orpackage-lock.jsonfile, if not needed for the scenario. - Synchronously runs command specific for the scenario, measures its execution time and gathers its log.
- Analyzes the log to gather statistics about HTTP requests and time to generate complete dependency tree.
- Saves the log as well as all metrics to files.
Complete source code is available in my GitHub repository. The code can be run using node benchmark.js.
Results
Complete results are available in a Google sheet.
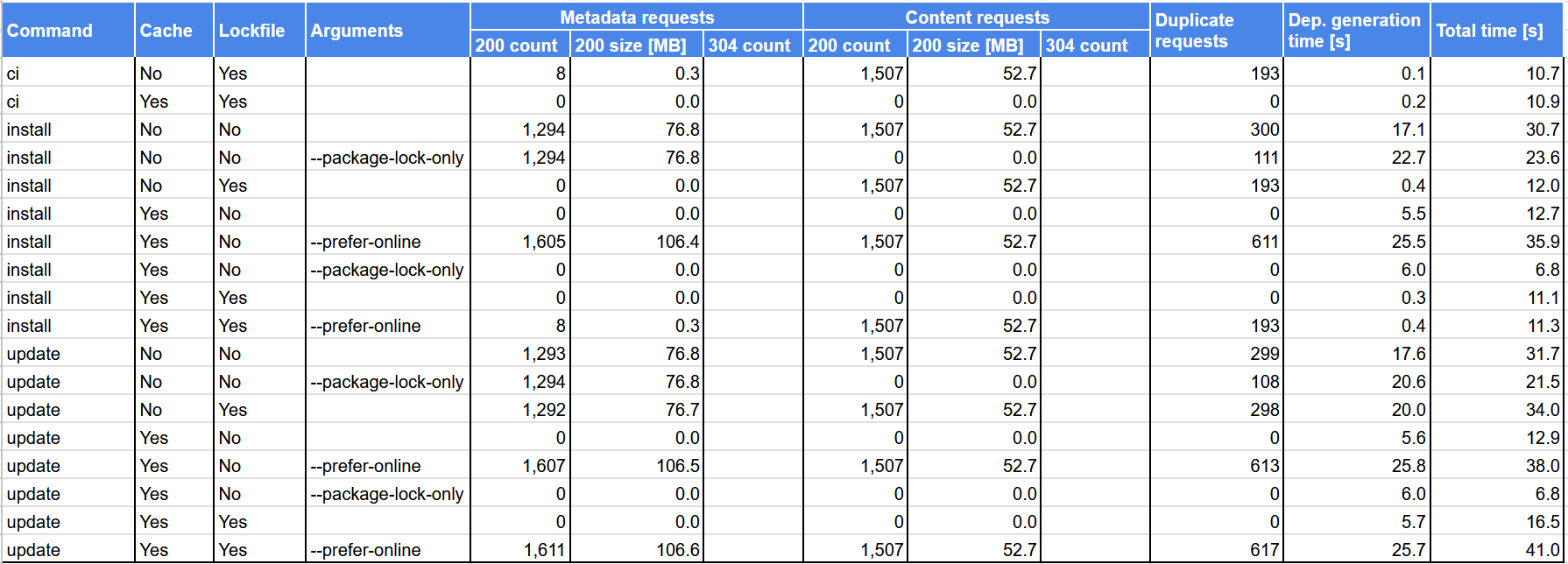
If you prefer the results directly in the article, the following table contains results for each scenario for the public https://registry.npmjs.org registry.
And the same table for my local Nexus registry follows.
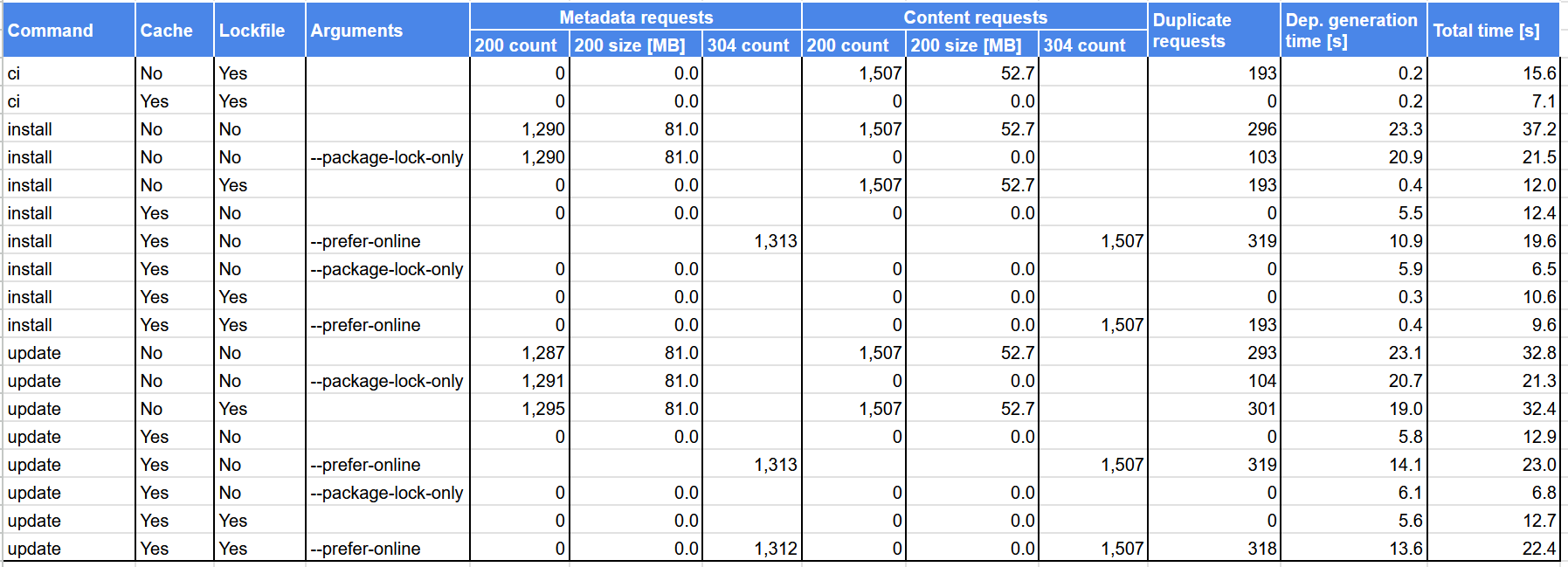
The results contain the following columns:
- Command -
npmcommand being run. - Cache - indicates, whether up-to-date cache data was used.
- Lockfile - indicates, whether the
package-lock.jsonfile was present. - Arguments - additional command-line arguments passed to
npm. - Metadata requests - count and size of HTTP requests to get package metadata split by HTTP status code (200 and 304).
- Content requests - count and size of HTTP requests to get package content split by HTTP status code (200 and 304).
- Duplicate requests - number of duplicate HTTP requests, i.e. requests, that get the same data as a previously sent request.
- Dep. generation time - time to generate complete dependency tree in seconds. Each scenario was run just once, so this time should be taken cautiously.
- Total time - total time of the scenario in seconds. Each scenario was run just once, so this time should be taken cautiously.
Observations
The following list summarizes observations based on the results presented above:
- Metadata is huge - One may expect package metadata to be smaller than package contents. The results show, that exactly the opposite is true with package content size being about 53 MB, while package metadata size being about 77 MB (or 81 MB for Nexus). This should be no surprise since metadata contains all package versions, which can easily be more than a thousand as evidenced above for the react package.
- Number of HTTP requests needed to install packages is huge - When starting with no
package-lock.jsonand no cache (or with the--prefer-onlineoption), there are about 2800 requests generated. And even thoughnpmruns them in parallel (15 by default), the requests take some time depending especially on your bandwidth and latency. - Dependency tree generation is slow - The time to generate complete dependency tree is about 6 seconds even when all the metadata is cached. For 1,507 packages in total, this seems to be quite slow. And this is one of the pain points, that other package managers try to address.
- Total metadata size with Nexus is higher than with the public registry - I suppose, that the metadata of the public registry is gzipped with maximum compression and then stored on a CDN to be available for end users. Nexus itself supports no metadata compression, so I configured dynamic compression at a reverse proxy. Due to its nature, this compression is probably not as efficient as the one-off compression used by the public registry.
- Missing support of HTTP 304 by the public registry - As already explained above, the public registry does not support HTTP 304 status code. As a result, when you ask for up-to-date data using the
--prefer-onlineoption, be prepared to download everything - complete package metadata as well as package content. On the other hand, with Nexus and up-to-date local cache, the traffic is low, because only HTTP headers are transferred. -
--prefer-onlinetries to fetch not only up-to-date package metadata but also package content - This does not make sense in most cases, because the package content should not be modified. If a package content needs to be modified, new package version should be published instead. - Many duplicate requests - The number of duplicate requests is quite high, especially in some scenarios. For example when using the
--prefer-onlineoption with nopackage-lock.jsonand the public registry, there are 611 duplicate requests out of 3,112 requests in total, which is about 20%. In this case, the duplicate requests also result in the increase of transferred data from 77 MB to 106 MB. -
npm updatebehaves the same asnpm installwithoutpackage-lock.json- This confirms the principles ofnpm updatedescribed above. -
npm cibehaves the same asnpm installwithpackage-lock.json- This confirms the principles ofnpm cidescribed above.
Key takeaways
- Package metadata is huge, so be prepared to download a lot of data when installing packages.
- Check the caching headers and HTTP 304 support of your npm registry to understand, how your packages are cached and refreshed.
- When you need to install up-to-date packages,
npm installwith--prefer-onlineoption can be used. However, this approach tries to refresh package metadata as well as package content. A better approach might be to usenpm install --package-lock-only --prefer-onlineto generate up-to-datepackage-lock.jsonand then usenpm install --prefer-offlineto install packages based on thepackage-lock.jsonfile. This way, the package content is only downloaded, when it is not present in the cache.