Welcome back to the third part of our dive into Chapter 2 of Designing Data-Intensive Applications. In the previous sections, we explored how document and relational databases handle various data relationships. Now, we’ll explore graph-like data models—particularly useful for modeling complex, interconnected data—and their query languages: Cypher, SQL (recursive), and SPARQL.
Graph‑Like Data Models
When you start modeling data, relationships are everything:
- One‑to‑many → Document model
- Many‑to‑many → Relational model
- Complex many‑to‑many → Graph model
Graphs shine when the connections themselves carry meaning.
But wait, what is a Graph? 🤔
A graph is made of:
- Vertices (nodes or entities)
- Edges (relationships or arcs) Examples:
- Social graph: vertices = people, edges = friendships
- Web graph: vertices = pages, edges = hyperlinks
- Road network: vertices = intersections, edges = roads
Even better—graphs can hold heterogeneous data in one store!
Facebook’s graph includes people, locations, events, check‑ins, comments…
Edges capture friendships, check‑in locations, comments-on-posts, event attendance, and more.
Taking an example
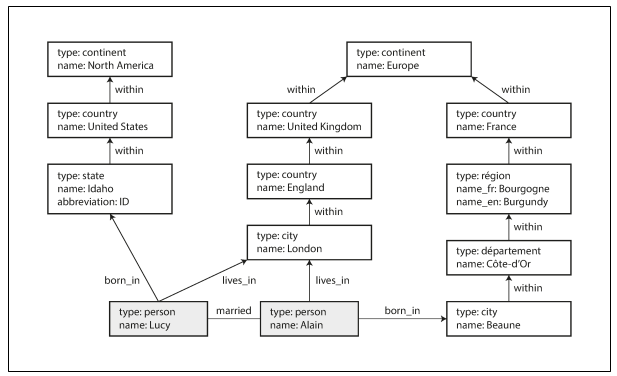
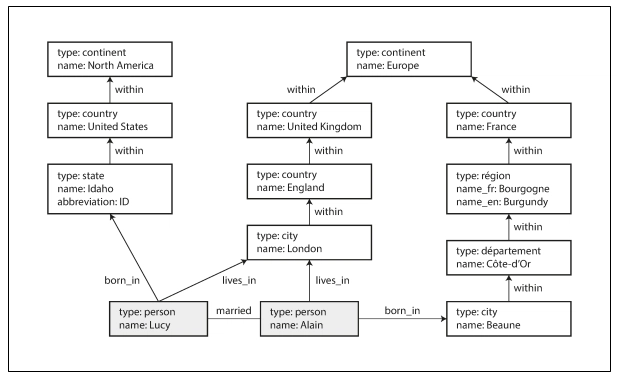
Imagine two people:
- Lucy (from Idaho, USA)
- Alain (from Beaune, France)
They’re married and live in London.
A graph can capture:
-
Lucy
- born in → Idaho
- lives in → London
-
Alain
- born in → Beaune
- lives in → London
- Idaho within → USA
- Beaune within → France
- London within → England → Europe
You could imagine extending the graph to also include many other facts about Lucy and Alain, or other people. For instance, you could use it to indicate any food allergies they have.
Evolvability, that's what graphs provide us.
Property Graph Model
Vertices have:
- Unique ID
- Incoming & outgoing edge lists
- Properties (key–value pairs)
Edges have:
- Unique ID
- Tail vertex (start)
- Head vertex (end)
- Label (relationship type)
- Properties (key–value pairs)
Under the hood, you can imagine two tables:
CREATE TABLE vertices ( vertex_id INTEGER PRIMARY KEY, properties JSON ); CREATE TABLE edges ( edge_id INTEGER PRIMARY KEY, tail_vertex INTEGER REFERENCES vertices(vertex_id), head_vertex INTEGER REFERENCES vertices(vertex_id), label TEXT, properties JSON ); CREATE INDEX edges_tails ON edges(tail_vertex); CREATE INDEX edges_heads ON edges(head_vertex);This gives you fast lookups of incoming/outgoing edges and lets you mix any labels you like—all in one graph!
Important aspects of this model include :
- Any vertex can have an edge with any other vertex. No schema restricts which kinds of thing can or cannot be associated
- Given any vertex, you can definitely, find both it's incoming and outgoing edges, leading to any path.
- By using labels for different relationships, you can store several different kind of info in a single graph, while maintaining a clear data model.
Cypher Query Language
Cypher is a declarative query language for property graphs, created for the Neo4j
graph database.
It works in the following manner :
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country'}),
(Idaho:Location {name:'Idaho', type:'state'}),
(Lucy:Person {name:'Lucy'}),
(Idaho)-[:WITHIN]->(USA)-[:WITHIN]->(NAmerica),
(Lucy)-[:BORN_IN]->(Idaho);The same arrow notation is used in a MATCH clause to find patterns in the graph.
Eg: Cypher query to find people who emigrated from the US to Europe
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name[:WITHIN*0..] means “follow 0 or more WITHIN edges”
The query can be read as follows:
Find any vertex (call it person) that meets both of the following conditions:
- Person has an outgoing BORN_IN edge to some vertex. From that vertex, you can follow a chain of outgoing WITHIN edges until eventually you reach a vertex of type Location, whose name property is equal to "United States".
- That same person vertex also has an outgoing LIVES_IN edge. Following that edge, and then a chain of outgoing WITHIN edges, you eventually reach a vertex of type Location, whose name property is equal to "Europe".
Hence, with cypher, graphs has become more advantageous over relational DB for more complex and evolving, schemas that involve interesting many-to-many relations.
SQL with Recursive CTEs
This SQL query demonstrates the use of recursive Common Table Expressions (CTEs) to navigate hierarchical graph data stored in a relational database. It models entities like countries, continents, and people as vertices, and relationships such as "within", "born_in", and "lives_in" as directed edges. The goal is to identify individuals who were born in the United States and currently live in Europe.
- The recursive CTEs
in_usaandin_europetraverse the "within" hierarchy to build complete sets of locations within the U.S. and Europe, respectively. - Subsequent CTEs then use these sets to filter people based on their "born_in" and "lives_in" relationships.
WITH RECURSIVE
in_usa(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties->>'name'='United States'
UNION
SELECT e.tail_vertex
FROM edges e JOIN in_usa u ON e.head_vertex=u.vertex_id
WHERE e.label='within'
),
in_europe(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties->>'name'='Europe'
UNION
SELECT e.tail_vertex
FROM edges e JOIN in_europe eu ON e.head_vertex=eu.vertex_id
WHERE e.label='within'
),
born_in_usa AS (
SELECT tail_vertex AS vertex_id
FROM edges JOIN in_usa ON edges.head_vertex=in_usa.vertex_id
WHERE edges.label='born_in'
),
lives_in_europe AS (
SELECT tail_vertex AS vertex_id
FROM edges JOIN in_europe ON edges.head_vertex=in_europe.vertex_id
WHERE edges.label='lives_in'
)
SELECT v.properties->>'name'
FROM vertices v
JOIN born_in_usa b ON v.vertex_id=b.vertex_id
JOIN lives_in_europe l ON v.vertex_id=l.vertex_id;That's 29 lines vs. 4 lines for the same job!
Use appropriate DB for your Application
Triple Stores & SPARQL
The triple-store model is mostly equivalent to the property graph model, using different words to describe the same ideas.
In a Triple store, all information is stored in the form of very simple three-part statements: (subject, predicate, object):
- _Predicate_s are either properties or edges
- Objects can be literals (strings, numbers) or other vertices
The subject of a triple is equivalent to a vertex in a graph. The object is one of two things:
- A value in a primitive datatype, such as a string or a number. In that case, the predicate and object of the triple are equivalent to the key and value of a property on the subject vertex. For example, (lucy, age, 33) is like a vertex lucy with properties {"age":33}.
- Another vertex in the graph. In that case, the predicate is an edge in the graph, the subject is the tail vertex, and the object is the head vertex. For example, in (lucy, marriedTo, alain) the subject and object lucy and alain are both vertices, and the predicate marriedTo is the label of the edge that connects them.
Turtle (N3) example:
@prefix : .
_:lucy a :Person;
:name "Lucy";
:bornIn _:idaho.
_:idaho a :Location;
:name "Idaho";
:type "state";
:within _:usa.
_:usa a :Location;
:name "United States";
:type "country";
:within _:namerica.
_:namerica a :Location;
:name "North America";
:type "continent".In this example, vertices of the graph are written as _:someName. The name doesn’t mean anything outside of this file; it exists only because we otherwise wouldn’t know which triples refer to the same vertex. When the predicate represents an edge, the object is a vertex, as in _:idaho :within _:usa. When the predicate is a property, the object is a string literal, as in _:usa :name "United States".
Semantic Web
Semantic Web
Think of the web as a huge neighborhood where every house can share its address book. RDF (Resource Description Framework) was meant to give each site a common “address label” so computers could easily swap and connect data.
- Triple stores are the filing cabinets that hold all those address cards—simple databases of (subject, predicate, object) facts.
- The Semantic Web is the big idea of using those linked facts across the entire internet, so apps can mix and match data from any site.
Sadly, it never became the norm. Too many complicated rules and acronyms scared people off, so most sites stayed with plain HTML. The idea was clever—it just didn’t catch on.
Conclusion 🎯
Graph‑like models unlock a whole new way to think about data—one where the relationships are just as important as the entities themselves. We’ve seen how:
- Document and relational databases cover one‑to‑many and many‑to‑many cases well
- Graphs step in when those relationships get really intricate or start changing over time
- Cypher, recursive SQL, and SPARQL each shine in expressiveness for different graph flavors
- Triple stores package facts as simple (subject, predicate, object) entries
- The Semantic Web dream of a global, machine‑readable web was bold, if not quite reality
As you design your next data‑heavy app, think about which model fits your use case:
Lots of nested documents? Go document-store.
Predictable joins? Relational is solid.
Dynamic, evolving networks? Graphs are your friend.
Stay tuned for Part IV, where we’ll dive into Datalog, RDF, and more tools for wrangling connected data!