This is a Plain English Papers summary of a research paper called DRAGON: Reward-Driven Diffusion Models Outperform RLHF Without Human Data. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
A New Approach to Fine-Tuning Diffusion Models with Reward Signals
Aligning diffusion models with desired outcomes remains a significant challenge in AI research. Current approaches like Reinforcement Learning with Human Feedback (RLHF) and Direct Preference Optimization (DPO) require expensive human preference data and struggle with distribution-level metrics.
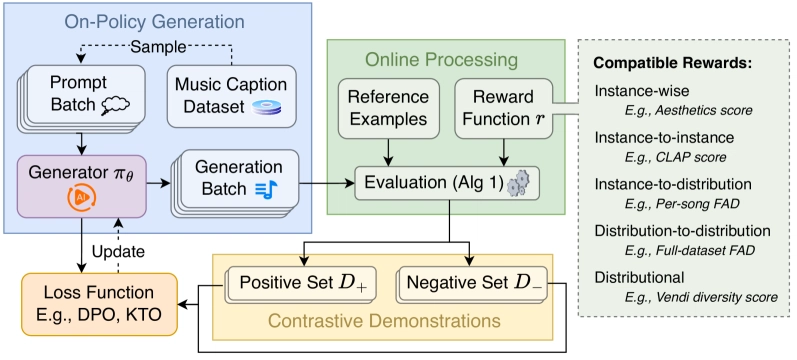
Enter DRAGON (Distributional RewArds for Generative OptimizatioN), a flexible framework that handles various reward types beyond instance-level feedback. Unlike traditional methods, DRAGON can optimize reward functions that evaluate both individual examples and distributions of content, making it compatible with instance-wise, instance-to-distribution, and distribution-to-distribution rewards.
Left: Overall diagram of DRAGON, a versatile on-policy learning framework for media generation models that can optimize various types of reward functions. Right: Performance visualization showing DRAGON significantly improves across multiple reward metrics.
DRAGON consists of three key components:
- A pre-trained embedding extractor and reference examples
- A reward-based scoring mechanism creating positive and negative sets from online generations
- An optimization process leveraging contrast between these sets
When tested across 20 different reward functions for music generation, DRAGON achieved an impressive 81.45% average win rate. Even more remarkably, it achieved a 60.95% human-voted music quality win rate without requiring extensive human preference annotations.
This approach represents a significant advancement over previous alignment techniques, particularly for perceptual media like music where gathering human preference data is especially challenging.
Background: Foundation Concepts and Related Work
The Evolving Field of Music Generation
Music generation has advanced rapidly with both auto-regressive token-based models and diffusion/flow-matching models. Notable examples include MusicLM, MusicGen, and Stable Audio, with each architecture showing distinctive strengths.
Reward optimization for diffusion models presents unique challenges compared to auto-regressive ones. While auto-regressive models generate content sequentially, making reward optimization more straightforward, diffusion models generate content through an iterative denoising process, which complicates incorporating reward signals.
These challenges have motivated research into specialized optimization approaches, where ongoing work in reinforcement learning provides valuable insights, though diffusion-specific solutions remain necessary.
Understanding Diffusion Models
Diffusion models generate high-quality content through iterative denoising. The process involves a denoising network (fθ) that takes a noisy input, diffusion time step, and conditioning signal (like text), gradually removing noise until a clean output emerges.
The training process adds Gaussian noise to training examples, teaching the model to reverse this process. At inference time, generation starts with pure noise which is progressively denoised through multiple steps. Recent advances have shown advantages for transformer-based architectures, leading to Diffusion Transformers (DiT).
Latent diffusion models perform this process in a lower-dimensional embedding space, enabling efficient generation across modalities including images, video, speech, audio, and music.
Current Approaches to Reward Optimization for Diffusion Models
Traditional reinforcement learning methods struggle with diffusion models due to the iterative denoising process. Some researchers have formulated the diffusion process as a Markov Decision Process, assigning rewards either at the final time step or throughout all steps.
More recent work explores implicit reward optimization through contrastive demonstrations. Approaches like Diffusion-DPO and MaPO optimize rewards defined with explicit binary preferences between paired samples. Diffusion-KTO offers more flexibility by accommodating unpaired collections of preferred and non-preferred samples.
These methods represent important progress in fine-tuning diffusion models using rewards, but they still face limitations when optimizing distribution-level metrics that evaluate sets of outputs rather than individual samples.
Human Feedback Data and Aesthetics Models
Human feedback datasets and aesthetics models guide the optimization of generative models toward human preferences. For images, datasets like SAC, AVA, LAION-Aesthetics V2, and Pick-a-Pic have been instrumental in improving generation quality.
However, such resources remain scarce for audio and music generation. The few examples, like MusicRL for music and BATON for in-the-wild audio, demonstrate the potential but also highlight the gap in available resources.
To address this limitation, the DRAGON researchers created their own aesthetics dataset and model for music generation, showing how even smaller preference datasets can be effectively leveraged with the right optimization approach.
How DRAGON Works: Distributional Reward Optimization
DRAGON introduces a mathematical framework for optimizing diffusion models with diverse reward signals. It considers a distributional reward function rdist that assigns a value to a distribution of generations, allowing for optimization beyond instance-level rewards.
The key innovation is how DRAGON constructs positive and negative demonstration sets. For a given reward function, DRAGON gathers online and on-policy generations, then selects the most promising examples to form a positive set (𝒟+) and a negative set (𝒟−). The model parameters are then optimized to make future generations more similar to 𝒟+ and less similar to 𝒟−.
This on-policy approach keeps the demonstrations aligned with the current model capabilities, avoiding the off-policy challenges faced by methods using pre-collected data. The optimization process leverages contrastive learning principles, with the contrast between positive and negative sets providing clear learning signals.
DRAGON can be implemented using either a DPO-style loss function (for paired demonstrations) or a KTO-style loss function (which can handle both paired and unpaired demonstrations). This flexibility offers advantages over other reward learning approaches that might be more restrictive in their demonstration requirements.
DPO versus KTO loss function comparison; showing the difference between paired and unpaired demonstrations.
A Taxonomy of Reward Functions
Training AI to Match Human Preferences: Instance-Wise Reward
One of the most valuable applications of DRAGON is aligning generative models with human preferences. For this purpose, the researchers created the Dynamo Music Aesthetics (DMA) dataset, consisting of 800 prompts, 1,676 music pieces (totaling 15.97 hours), and 2,301 ratings from 63 raters on a scale of 1-5.
The DMA dataset provides more fine-grained feedback than binary comparison datasets. Despite being much smaller than comparable image aesthetics datasets, its effectiveness demonstrates DRAGON's data efficiency.
| Collection Phase | Prompt Source | Music Source | Occurrences | Mean Rating |
|---|---|---|---|---|
| Phase-1 | User prompts | Generated | 634 | 2.992 |
| Phase-2 | User prompts (reused) | Generated | 487 | 2.875 |
| Phase-2 | Training dataset captions | Generated | 361 | 3.277 |
| Phase-2 | LLM-generated prompts | Generated | 196 | 2.546 |
| Phase-2 | Training dataset captions | Human-created | 119 | 3.966 |
| Total | 1,676 | 2.919 |
Table showing the DMA dataset's data sources, occurrences, and mean ratings of each source.
This dataset was used to train an aesthetics predictor consisting of a pre-trained CLAP audio encoder and a kernel regression prediction head. The model evaluates music quality without seeing the text prompt, focusing purely on audio quality.
| Dataset | Modality | Size | Content Source | Rating Source | Rating Scale |
|---|---|---|---|---|---|
| SAC (Pressman et al., 2022) | Image | $>238,000$ | AI-generated | Human-rated | 1-10 score |
| AVA (Murray et al., 2012) | Image | $>250,000$ | Human-created | Human-rated | 1-10 score |
| LAION-Aes V2 (Schuhmann, 2022) | Image | 1.2 Billion | Human-created | Model-predicted | 1-10 score |
| Pick-a-Pic (Kirstain et al., 2023) | Image | $>1$ Million | AI-generated | Human-rated | Paired binary |
| RichHF-18K (Liang et al., 2024) | Image | 18,000 | AI-generated | Human-rated | 1-5 multi-facet |
| BATON (Liao et al., 2024) | In-the-wild Audio | 2,763 | AI-generated | Human-rated | Paired binary |
| Audio-Alpaca (Majumder et al., 2024) | In-the-wild Audio | 15,000 | AI-generated | Model-predicted | Paired binary |
| MusicRL (Cideron et al., 2024) | Music | 285,000 | AI-generated | Human-rated | Paired binary |
| Ours | Music | 1,676 | Mostly AI-generated | Human-rated | 1-5 score |
Comparison of aesthetic datasets across different modalities, sources, and rating scales, highlighting the relatively small size of the DMA dataset used with DRAGON.
Aligning with Textual Prompts: Instance-to-Instance Reward via CLAP Score
CLAP score demonstrates DRAGON's ability to optimize instance-to-instance rewards. This metric measures the cosine similarity between the CLAP embedding of a generated audio and a reference embedding (in this case, the CLAP text embedding of the matching prompt).
Higher CLAP score indicates better alignment between the generated music and the text description. An advantage of this reward is that it requires only text prompts, not human-created music or human ratings.
When optimizing CLAP score, DRAGON constructs 𝒟+ and 𝒟− through pair-wise comparison, selecting generations with higher and lower CLAP scores, respectively. The results show that optimizing CLAP score not only improves text-audio alignment but also enhances overall generation quality.
Matching Statistical Distributions: Full-Dataset FAD
Fréchet Audio Distance (FAD) exemplifies DRAGON's unique ability to optimize distribution-to-distribution rewards. FAD measures the difference between two distributions (generated music vs. reference music) in an embedding space.
For two distributions with means μθ and μref and covariance matrices Σθ and Σref, FAD is computed as:
FAD(μθ, Σθ, μref, Σref) = ||μθ - μref||²₂ + Trace(Σθ + Σref - 2(Σθ½ΣrefΣθ½)½)
This metric is typically used for evaluation rather than optimization since it requires comparing entire distributions. DRAGON's innovation is directly optimizing this distribution-level metric by approximating the generation distribution with all examples in a training batch and constructing 𝒟+ to minimize dataset FAD.
The reference distribution can be in any modality supported by the embedding space. With CLAP, the reference can be either audio or text embeddings, providing remarkable flexibility in supervision sources.
Bridging Individual and Distributional: Per-Song FAD
Per-song FAD represents an instance-to-distribution reward, bridging individual and distributional metrics. It compares a single generation to a reference distribution by splitting the audio into shorter chunks, encoding each chunk, and forming a "per-song embedding distribution."
This approach allows individual generations to be scored against reference statistics computed from an entire dataset. Since per-song FAD assigns a score to each example, DRAGON constructs 𝒟+ and 𝒟− through element-wise comparison, selecting generations with lower and higher per-song FAD values, respectively.
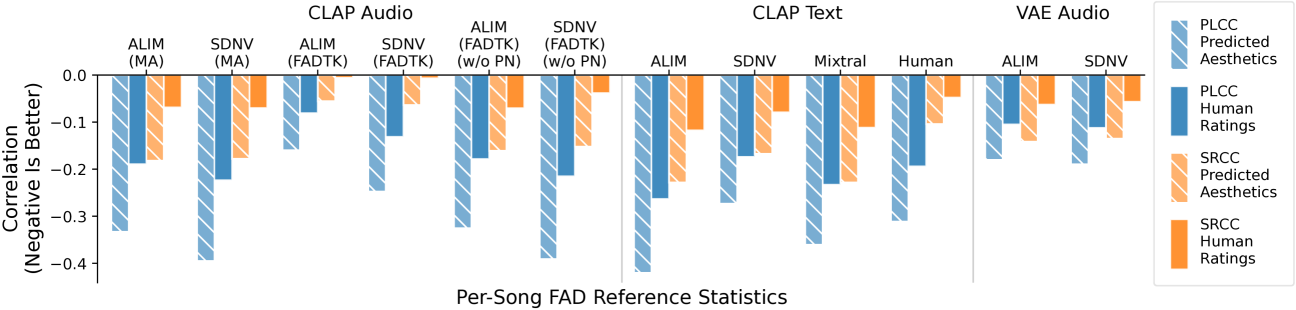
Correlation between per-song FAD with various reference statistics and aesthetics score. All numbers are negative because smaller is better for FAD whereas larger is better for aesthetics.
The research showed per-song FAD correlates with human preference, making it a valid proxy for music quality. Surprisingly, using text embeddings from high-quality music descriptions as the reference sometimes produced stronger correlations than using audio embeddings.
Promoting Generation Diversity: Vendi Score
Vendi score represents a reference-free distributional reward measuring output diversity. A higher score indicates more diverse generations, with a value of v suggesting diversity equivalent to v completely dissimilar vectors.
To compute Vendi score for n embeddings with dimension d, represented as a matrix X∈ℝⁿˣᵈ:
- Assemble an n×n kernel matrix K using normalized embeddings
- Compute eigenvalues λ₁,...,λₙ of K
- Calculate Vendi(X) = exp(-Σᵢ₌₁ⁿ λᵢlog λᵢ)
During training, Vendi score is computed across all generations in each batch. DRAGON can directly optimize this metric using Algorithm 1, demonstrating its ability to improve generation diversity, a capability that wouldn't be possible with traditional instance-level optimization methods.
Experimental Results: Proving DRAGON's Effectiveness
Experimental Setup: Models, Data, and Evaluation
The experiments used a baseline diffusion model from Presto, generating 32-second single-channel 44.1kHz audio. The model architecture included a latent-space score-prediction denoising module based on DiT-XL, a convolutional VAE, and a FLAN-T5-based text encoder.
For evaluation, the researchers used prompts from:
- ALIM test split (800 pieces)
- Non-vocal Song Describer subset (585 pieces)
- DMA dataset (800 pieces)
Evaluation metrics included predicted aesthetics score, CLAP score, per-song FAD, full-dataset FAD, and Vendi diversity score, with performance reported as win rates over the baseline model.
| Reward Optimized | Reward Win Rate | Reward Before/After | Individual Metric Win Rates | |||||
|---|---|---|---|---|---|---|---|---|
| Aesthetics Score | CLAP Score |
VAE Encoder ALIM | SDNV | CLAP Encoder ALIM | SDNV | |||
| Aesthetics | $85.2 \%$ | $.187 / .638$ | $85.2 \%$ | $52.2 \%$ | $54.9 \%$ | $55.3 \%$ | $58.9 \%$ | $55.1 \%$ |
| CLAP-Score | $60.1 \%$ | $.300 / .317$ | $68.7 \%$ | $60.1 \%$ | $64.9 \%$ | $61.4 \%$ | $65.2 \%$ | $54.2 \%$ |
| Per-Song VAE-FAD ALIM-Audio | $93.9 \%$ | $30.8 / 16.3$ | $78.3 \%$ | $50.9 \%$ | $93.9 \%$ | $94.0 \%$ | $83.9 \%$ | $81.0 \%$ |
| Per-Song VAE-FAD SDNV-Audio | $66.4 \%$ | $31.1 / 28.4$ | $51.3 \%$ | $49.0 \%$ | $63.5 \%$ | $66.4 \%$ | $48.3 \%$ | $42.8 \%$ |
| Per-Song CLAP-FAD ALIM-Audio | $73.6 \%$ | $.947 / .867$ | $61.5 \%$ | $51.6 \%$ | $49.5 \%$ | $49.6 \%$ | $73.6 \%$ | $70.7 \%$ |
| Per-Song CLAP-FAD SDNV-Audio | $56.3 \%$ | $.990 / .973$ | $49.1 \%$ | $46.0 \%$ | $35.7 \%$ | $33.1 \%$ | $54.0 \%$ | $56.3 \%$ |
| Per-Song CLAP-FAD ALIM-Text | $83.5 \%$ | $1.58 / 1.48$ | $78.3 \%$ | $65.4 \%$ | $64.0 \%$ | $65.7 \%$ | $70.4 \%$ | $65.9 \%$ |
| Per-Song CLAP-FAD SDNV-Text | $70.1 \%$ | $1.56 / 1.53$ | $49.7 \%$ | $55.7 \%$ | $57.6 \%$ | $57.1 \%$ | $63.8 \%$ | $58.2 \%$ |
| Per-Song CLAP-FAD Human-Text | $83.7 \%$ | $1.60 / 1.54$ | $52.9 \%$ | $60.7 \%$ | $38.0 \%$ | $41.0 \%$ | $64.3 \%$ | $63.3 \%$ |
| Per-Song CLAP-FAD Mixtral-Text | $70.1 \%$ | $1.53 / 1.49$ | $65.5 \%$ | $52.2 \%$ | $52.8 \%$ | $52.2 \%$ | $60.3 \%$ | $60.5 \%$ |
DRAGON's win rates across various instance-level reward functions. The "reward win rate" and "reward before/after" columns evaluate the specific reward function being optimized, which differs for each model.
Improving Human Preference Metrics: Aesthetics and CLAP Score Optimization
When optimizing the aesthetics score, DRAGON consistently achieved at least an 80% reward win rate over the baseline. This validates both that the aesthetics model encodes learnable information and that DRAGON can effectively optimize it.
For CLAP score optimization, DRAGON achieved a 60.1% CLAP score win rate and a 68.7% aesthetics score win rate. This suggests CLAP score can serve as a surrogate when human ratings aren't available, though directly optimizing human ratings (when available) is more effective.
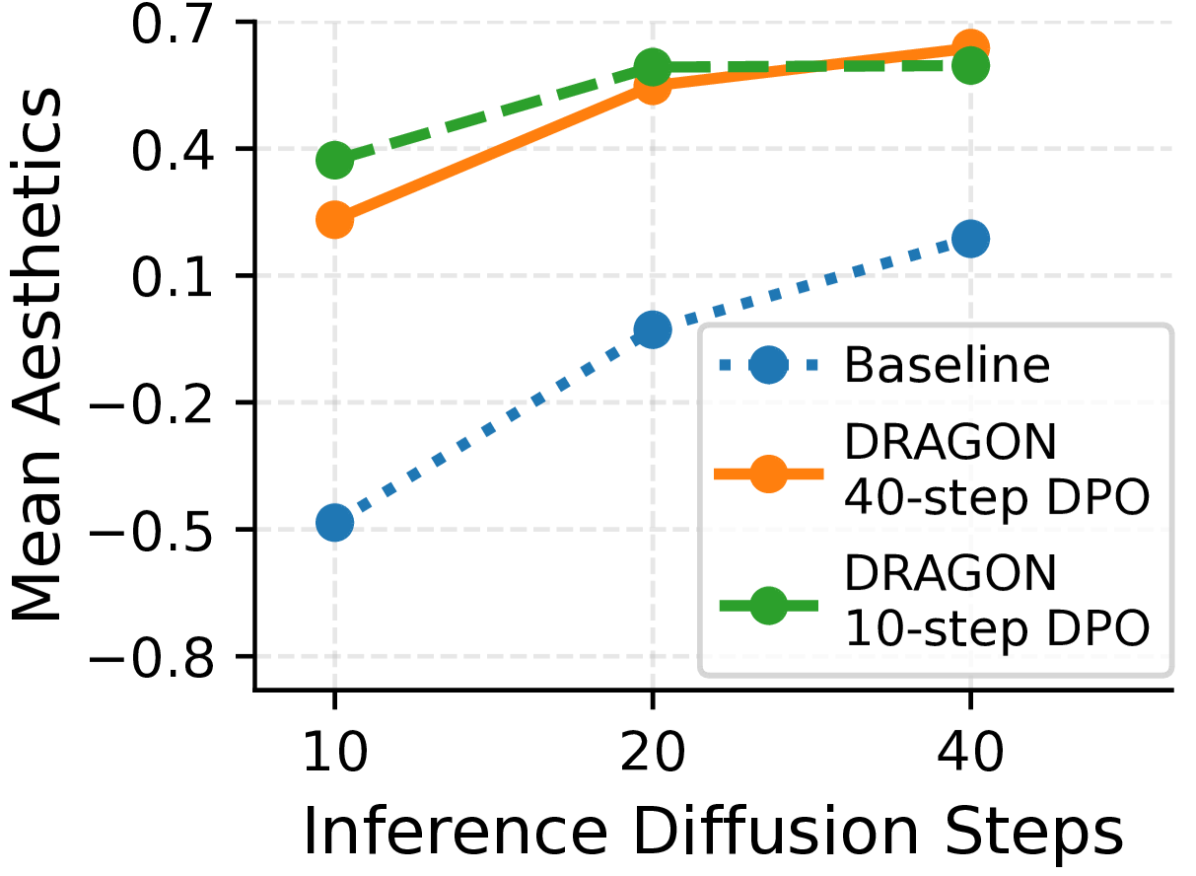
DRAGON performance with different demonstration diffusion steps and inference steps, showing how reducing training-time diffusion steps affects quality.
The researchers also ablated different aspects of the training process:
- Comparing DPO loss with paired demonstrations against KTO loss with paired and unpaired demonstrations showed DPO-Paired slightly outperformed KTO-Paired
- Reducing diffusion steps from 40 to 10 during training only caused minimal quality reduction, allowing for faster training
- DRAGON models showed flatter quality-vs-steps curves, with their 10-step generations outperforming the baseline model's 40-step generations
Enhancing Music Quality without Human Feedback: Per-Song FAD Optimization
The per-song FAD optimization results revealed several important findings:
- Using ALIM ground-truth embeddings as the reference, minimizing per-song FAD enhanced both the target reward and aesthetics score
- The diffusion VAE embeddings proved particularly powerful – optimizing per-song VAE-FAD achieved a 93.9% win rate in this metric and generalized well to other metrics
- Using SDNV statistics as the optimization target was less effective, highlighting the importance of high-quality reference music and avoiding dataset mismatches
- Leveraging CLAP's cross-modality embedding space, using text embeddings as FAD reference statistics for generated audio achieved impressive results
- Per-song FAD to ALIM captions' CLAP embeddings achieved improvements across all metrics, sometimes outperforming optimization with audio reference
These results demonstrate DRAGON's ability to enhance music generation without human feedback, simply by using statistical properties of reference distributions.
Directly Optimizing Distribution Metrics: Full-Dataset FAD Results
| Reward Optimized | Reward Win Rate |
Reward Before/After |
Individual Metric Win Rates | |||||
|---|---|---|---|---|---|---|---|---|
| Aesthetics Score | CLAP Score |
VAE Encoder ALIM | SDNV | CLAP Encoder ALIM | SDNV | |||
| Dataset VAE-FAD ALIM-Audio | $70.5 \%$ | $8.26 / 7.58$ | $51.4 \%$ | $49.7 \%$ | $70.5 \%$ | $58.7 \%$ | $1.0 \%$ | $1.5 \%$ |
| Dataset VAE-FAD SDNV-Audio | $59.4 \%$ | $8.30 / 8.05$ | $42.8 \%$ | $47.8 \%$ | $61.9 \%$ | $59.4 \%$ | $0.0 \%$ | $0.2 \%$ |
| Dataset CLAP-FAD ALIM-Audio | $73.6 \%$ | $.214 / .207$ | $58.3 \%$ | $45.7 \%$ | $61.5 \%$ | $50.2 \%$ | $73.5 \%$ | $29.9 \%$ |
| Dataset CLAP-FAD SDNV-Audio | $83.2 \%$ | $.260 / .251$ | $47.7 \%$ | $48.8 \%$ | $0.0 \%$ | $0.0 \%$ | $42.4 \%$ | $83.2 \%$ |
| Dataset CLAP-FAD ALIM-Text | $85.4 \%$ | $.983 / .967$ | $68.8 \%$ | $59.5 \%$ | $88.2 \%$ | $84.7 \%$ | $2.1 \%$ | $0.9 \%$ |
| Dataset CLAP-FAD SDNV-Text | $81.6 \%$ | $.799 / .788$ | $41.4 \%$ | $52.4 \%$ | $1.2 \%$ | $1.9 \%$ | $6.2 \%$ | $5.8 \%$ |
| Dataset CLAP-FAD Human-Text | $98.4 \%$ | $.837 / .813$ | $57.4 \%$ | $55.8 \%$ | $26.5 \%$ | $38.9 \%$ | $26.2 \%$ | $14.1 \%$ |
| Dataset CLAP-FAD Mixtral-Text | $99.8 \%$ | $.832 / .786$ | $64.6 \%$ | $61.1 \%$ | $8.3 \%$ | $14.1 \%$ | $1.3 \%$ | $0.0 \%$ |
Win rates of DRAGON models that optimize distribution-to-distribution reward functions, showing strong performance across different reference types.
Optimizing full-dataset FAD presents unique challenges due to reward ambiguity (difficulty determining each instance's contribution to the overall reward) and the baseline model's already decent FAD performance. Despite these challenges, DRAGON improved the target reward function in nearly all cases.
Key findings include:
- Using ALIM as reference statistics achieved multi-metric improvements
- CLAP text embeddings as reference achieved the best performance
- Ungrounded text embeddings (Human-Text and Mixtral-Text) enhanced music generation, especially in aesthetics and CLAP scores
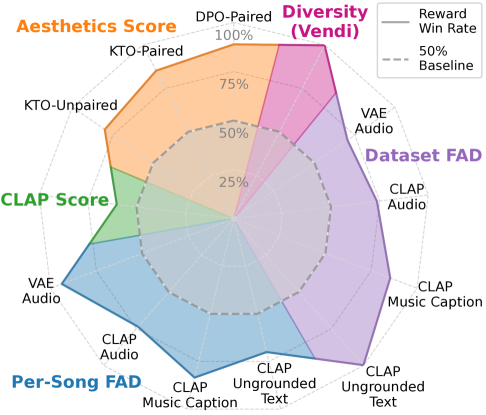
- Dataset FAD optimization achieved an 81.5% average reward win rate, matching per-song FAD optimization
Comparing dataset FAD to per-song FAD results revealed several trends:
- VAE embeddings were comparatively weaker for dataset FAD due to their lower dimensionality
- Cross-reference generalization was weaker in dataset FAD optimization
- Optimizing dataset FAD preserved more generation diversity than instance-level rewards
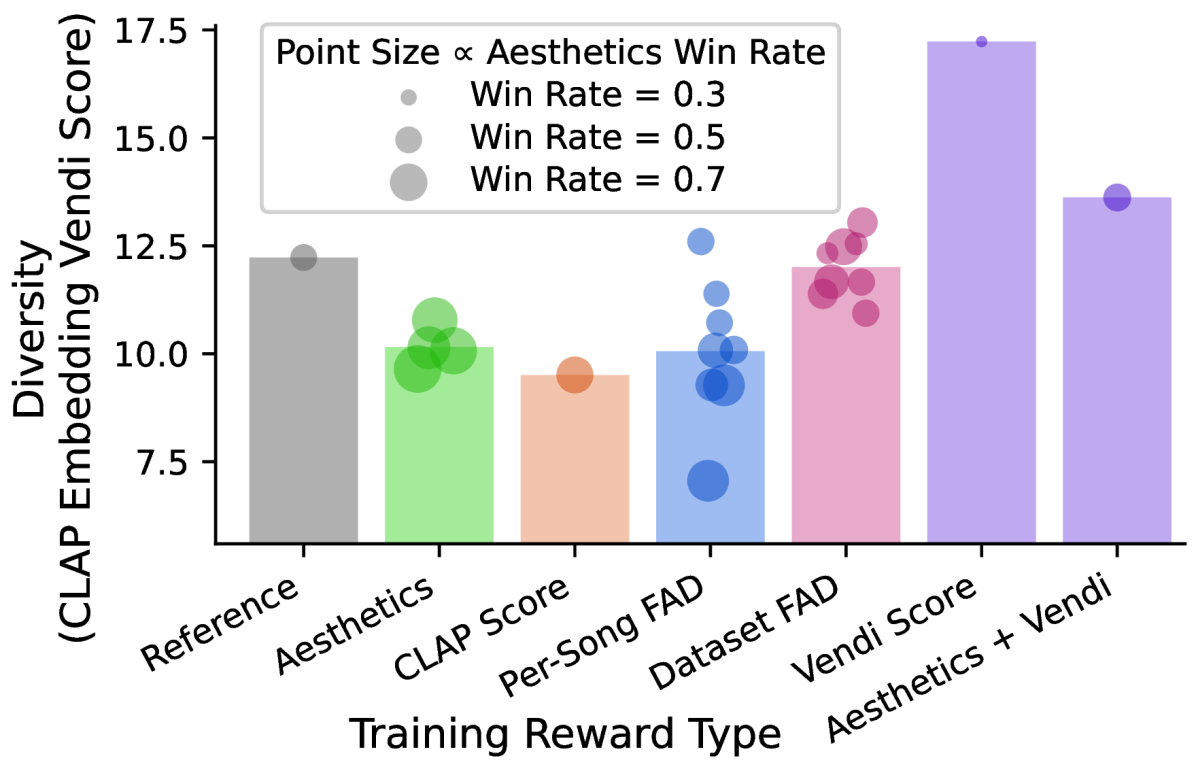
Vendi score comparison across models optimized for different reward types. Point height represents Vendi score and point size represents aesthetics win rate.
Optimizing Reference-Free Distributional Reward: Vendi Diversity Score
To demonstrate DRAGON's ability to improve generation diversity, the researchers optimized Vendi score across CLAP embeddings. This resulted in a significant 40.84% relative improvement in diversity.
However, since Vendi score doesn't provide any music quality information, optimizing it alone distorted the generations and hurt their aesthetics. To address this, they co-optimized Vendi score and aesthetics score by randomly selecting one of the two rewards at each training iteration with equal probability.
This balanced approach produced a model that simultaneously improved both Vendi and aesthetics, creating diverse high-quality music - another demonstration of DRAGON's versatility.
The Ultimate Test: Human Listening Test
The researchers conducted a listening test with 21 raters comparing the baseline model against two DRAGON variants: one optimizing aesthetics score and another optimizing per-song VAE-FAD to ALIM audio.
Each rater evaluated 40 randomly selected SDNV prompts with corresponding generation pairs. The audio clips were loudness-normalized and randomly cropped to 5-second snippets.
| Model | Measured WR | $95 \%$ Conf WR Lower Bound | $p$-Value | $\mathbb{P}(\mathrm{WR}>50 \%)$ |
|---|---|---|---|---|
| DRAGON-Aesthetics | $60.24 \%$ | $56.15 \%$ | $1.58 \times 10^{-5}$ | $99.9987 \%$ |
| DRAGON-VAE-PSFAD-ALIM | $60.95 \%$ | $56.87 \%$ | $4.15 \times 10^{-6}$ | $99.9997 \%$ |
Statistical analysis of human evaluation results showing strong confidence in DRAGON's improvement over the baseline model.
The results were decisive: both DRAGON models outperformed the baseline, with DRAGON-aesthetics achieving a 60.2% human-labeled win rate and DRAGON-VAE-FAD achieving 61.0%.
Interestingly, despite DRAGON-aesthetics receiving a higher machine-predicted aesthetics win rate (85.2%) than DRAGON-VAE-FAD (78.3%), its human-perceived quality was slightly worse. This suggests DRAGON-aesthetics may have experienced some overfitting by directly maximizing the predicted aesthetics score, while DRAGON-VAE-FAD's instance-to-distribution approach reduced overfitting by not relying on the DMA preference dataset.
Statistical analysis confirmed these improvements with high confidence, demonstrating that DRAGON enhances human-perceived music quality with sparse human feedback or even no human feedback at all.
A More Flexible Path to Model Alignment
DRAGON represents a versatile framework for optimizing diffusion models with a wide variety of reward signals. Its unique ability to handle distribution-level metrics alongside traditional instance-level rewards opens new possibilities for model alignment.
The research demonstrated DRAGON's effectiveness across 20 reward functions, including human preference, CLAP score, per-song FAD, full-dataset FAD, and Vendi diversity. It consistently achieved high win rates, with an 81.45% average across all target rewards.
Perhaps most impressively, DRAGON improved human-perceived music quality at a 60.9% win rate without extensive human preference annotations. It accomplished this by leveraging reference exemplar sets to create novel reward functions, drastically reducing the need for expensive human preference data collection.
As fine-tuning methods for diffusion models continue to evolve, DRAGON offers a promising alternative that lessens human data acquisition needs while maintaining or improving quality. Its ability to optimize diverse reward functions and work with exemplar-based rewards points to a more flexible and efficient path for aligning generative models with human preferences.
With audio examples available at the DRAGON project website, this research demonstrates how thoughtful reward design and optimization can lead to significant improvements in generated media quality, even without the massive preference datasets that have become common in other domains.
