Key LangGraphJS Features
1. What is LangGraphJS?
LangGraphJS is designed for building controllable agents. While LangChain provides integrations and composable components for LLM applications, LangGraphJS focuses on agent orchestration, offering customizable architectures, long-term memory, and human-in-the-loop support. Its core job is to connect nodes in a workflow and manage execution between nodes and their functions.
2. How Edges Work: addEdge() and addConditionalEdge()
-
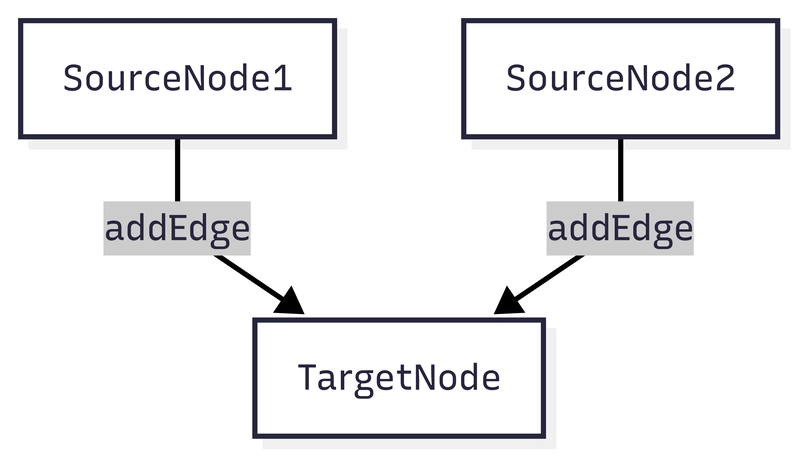
addEdge()- If you use
addEdge(sourceNode, targetNode), the target node runs after the source node. - If you call
addEdge(sourceNode1, targetNode)andaddEdge(sourceNode2, targetNode)separately, the target node runs twice—once after each source node. - If you use
addEdge([sourceNode1, sourceNode2], targetNode), the target node runs once, but only after both source nodes finish.
- If you use
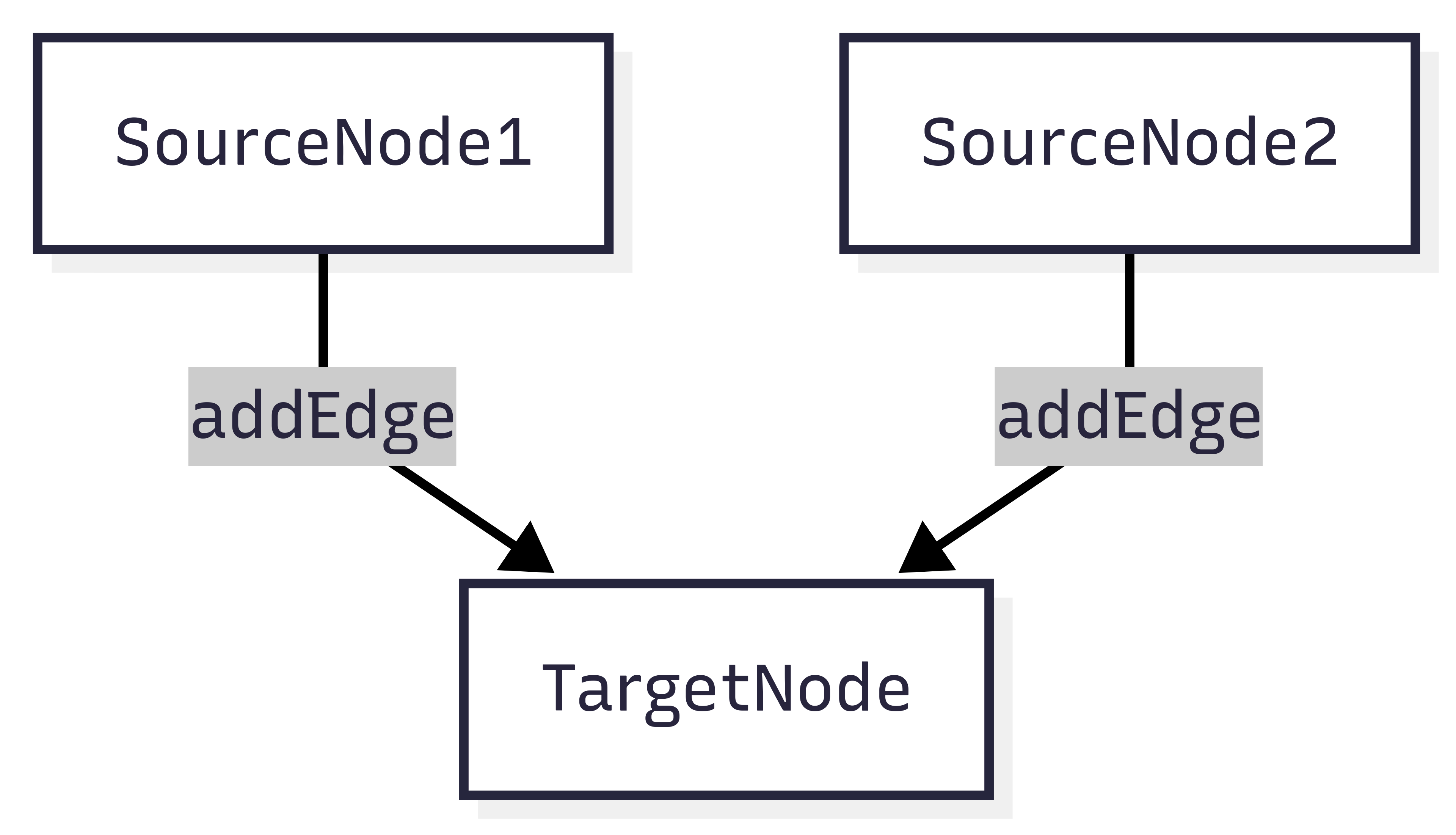
Figure 1.1: Separate addEdge calls: TargetNode runs twice
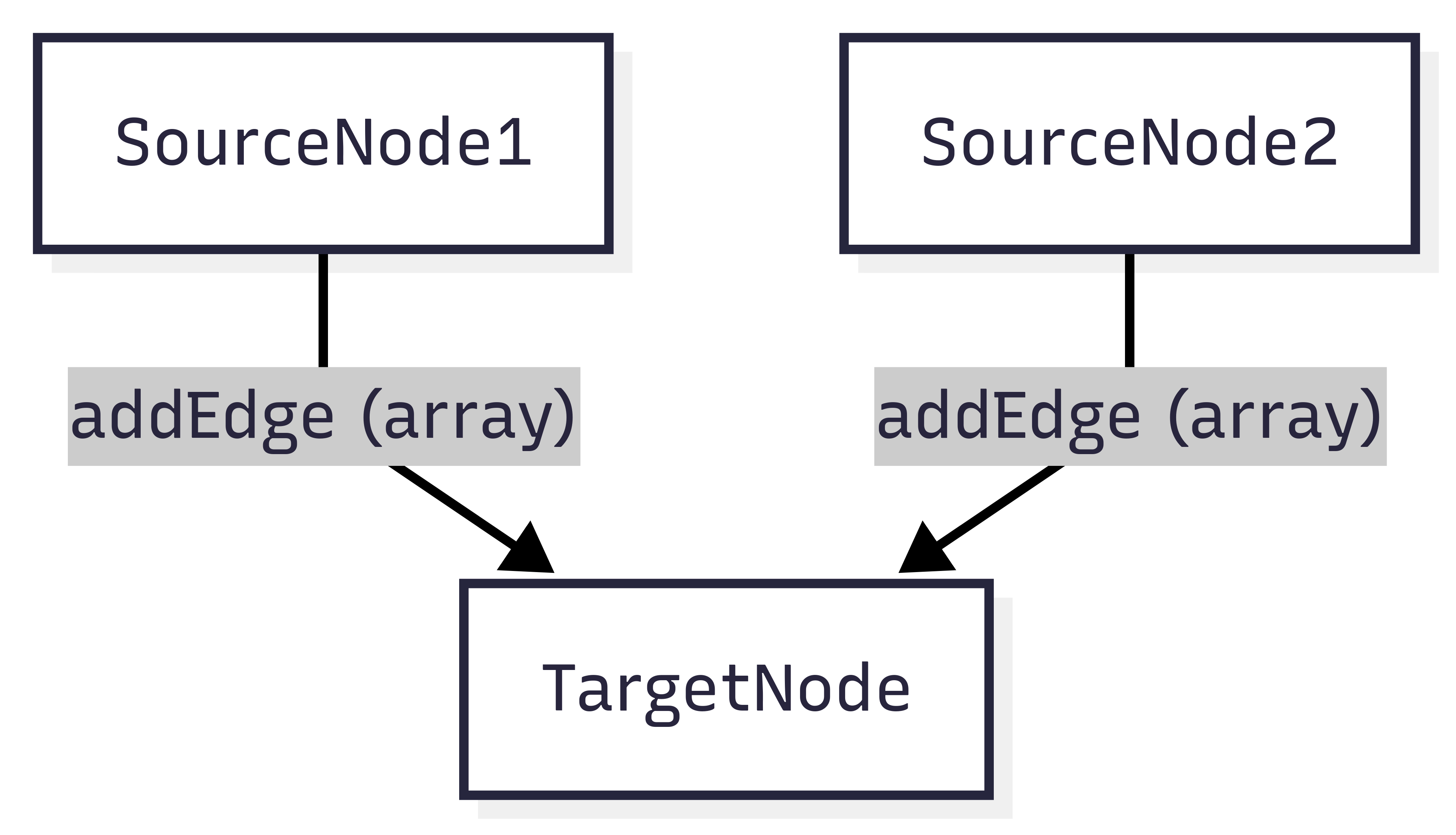
Figure 1.2: Array-based addEdge: TargetNode runs once after both finish
-
addConditionalEdge()- Like
addEdge(), but the target node is triggered based on a condition. - If you use both
addEdge()andaddConditionalEdge()to add the same target node, it may run multiple times.
- Like
3. Context During Execution
-
State:
- The state is the full context passed through the graph. Node functions receive and return this state.
-
Runnable:
- Provided by the engine, it contains metadata about the current execution, such as thread ID, step, node name, triggers, and execution path.
Example runnable metadata:
{
"tags": [],
"metadata": {
"thread_id": "test-001",
"langgraph_step": 4,
"langgraph_node": "nodem",
"langgraph_triggers": [
"branch:node1:condition:nodem",
"branch:node2:condition:nodem",
"join:node1+node2:nodem",
"node1",
"node2"
],
"langgraph_path": ["__pregel_pull", "nodem"],
"langgraph_checkpoint_ns": "nodem:aa367e6e-800f-5af9-9a39-8c24d08103a2",
"__pregel_resuming": false,
"__pregel_task_id": "aa367e6e-800f-5af9-9a39-8c24d08103a2",
"checkpoint_ns": "nodem:aa367e6e-800f-5af9-9a39-8c24d08103a2"
},
"recursionLimit": 25,
"callbacks": [],
"configurable": {}
}From this, you can see that the current node is nodem, triggered by both node1 and node2 via addEdge() and addConditionalEdge(). The langgraph_triggers array shows exactly how the node was triggered.
-
branch:node1:condition:nodemmeansaddConditionalEdges(node1, decideNextNode, [nodem, nodem-else1]) -
branch:node2:condition:nodemmeansaddConditionalEdges(node2, decideNextNode, [nodem, nodem-else2]) -
join:node1+node2:nodemmeansaddEdges([node1, node2], nodem)
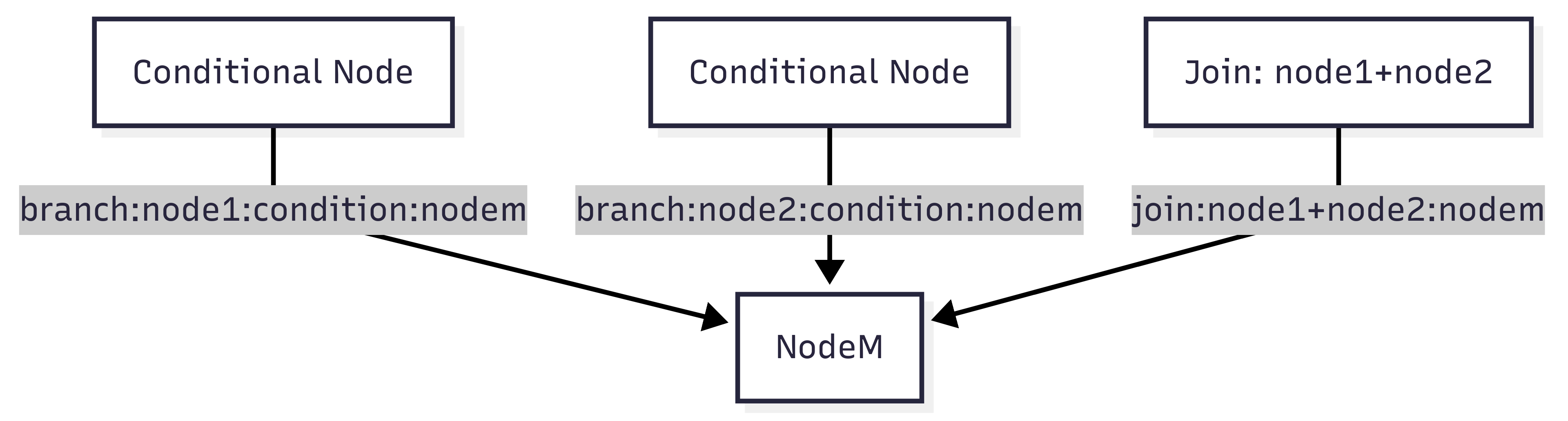
Figure 1.3: Visualization of triggers in langgraph_triggers
In this case, nodem is triggered three times, but all triggers arrive at the same time.
Common Workflow Issues
1. Downstream Blocking at Encounter Nodes
When branches from the same conditional node converge, downstream nodes may block if not all branches are executed. For example:
graph.addConditionalEdges(conditionalNode, decideNextNode, [
"node1-1",
"nodem",
]);
graph.addEdge(["nodem", "node2-1", "node1-1-1"], "nodec");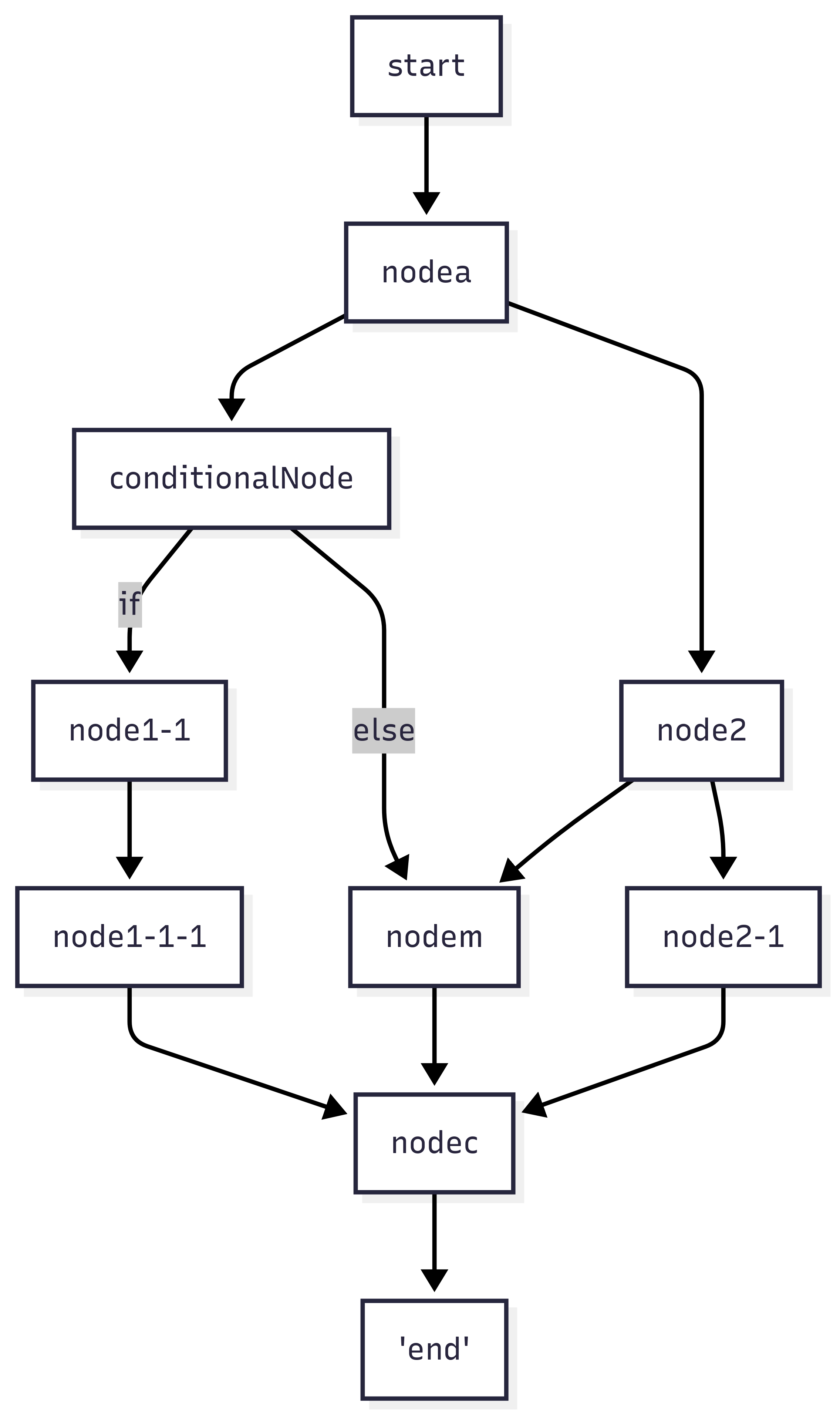
Figure 2.1: Downstream blocking: nodec waits for all branches
If only one branch is triggered by conditionalNode, nodem may never execute, as it waits for both branches. To solve this, you can add addEdge([node-1, node2], nodem) and use the Dynamic Pruning Strategy to ensure only the relevant branch is processed.
2. Multiple Triggers for Encounter Nodes
If an encounter node is a direct successor of a conditional node, it may be triggered prematurely, before all necessary branches complete. To prevent this, introduce a virtualNode between the branch nodes and the encounter node, ensuring correct execution order.
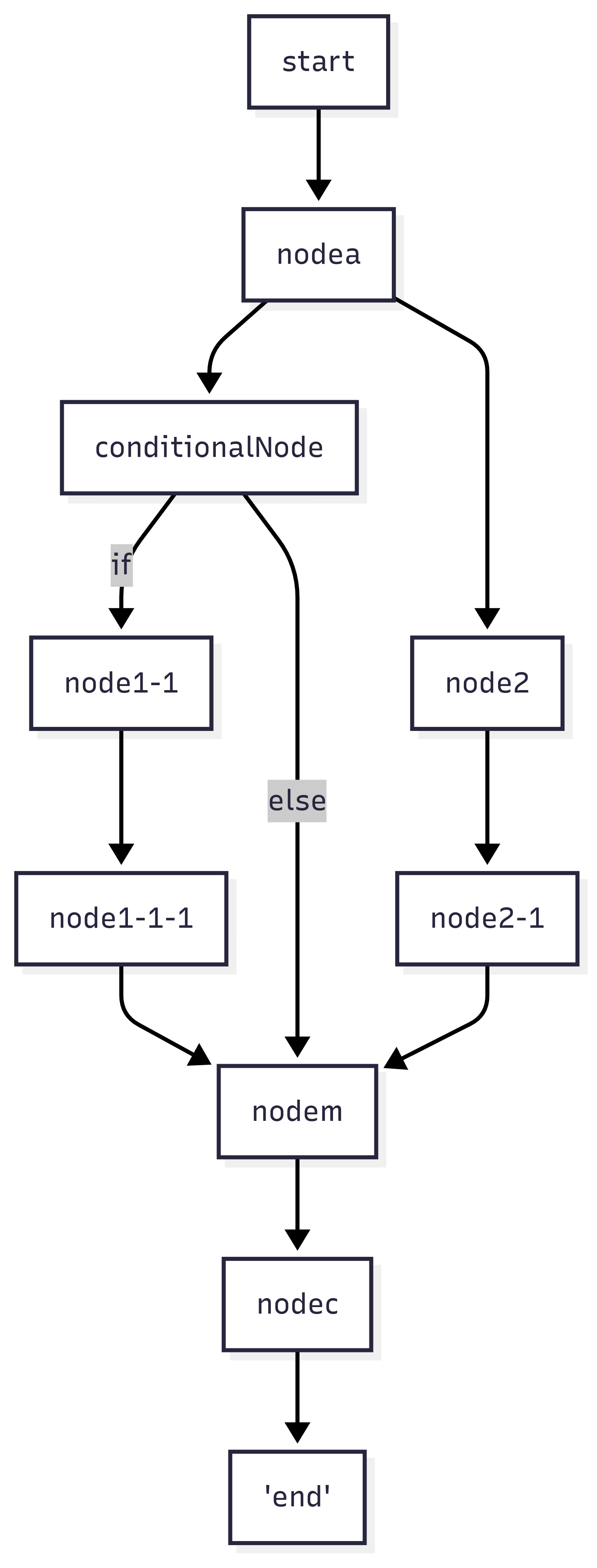
Figure 2.2: Using a virtualNode to prevent premature triggering
The Dynamic Pruning Strategy
Solution Overview
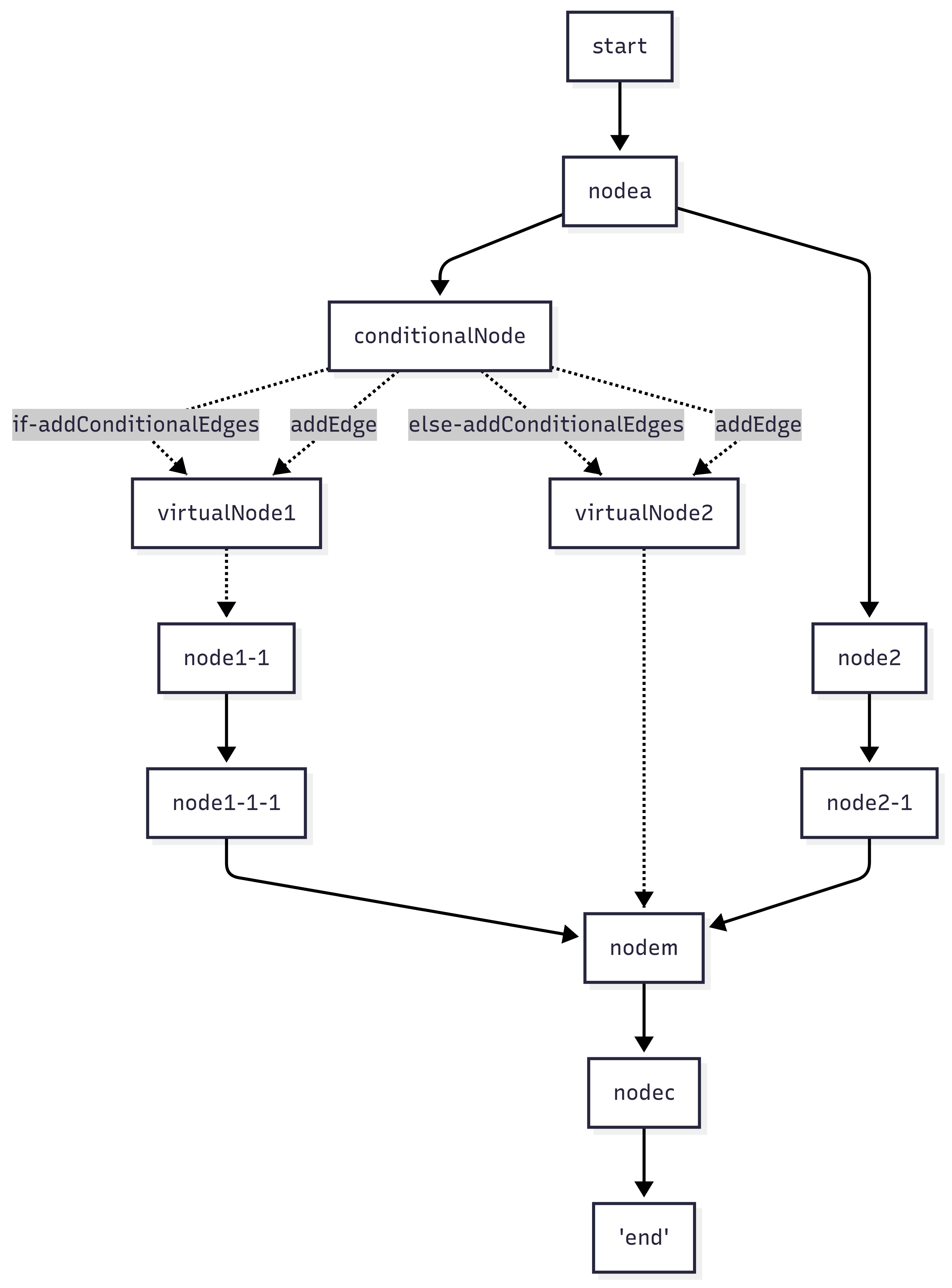
Figure 3.1 The actual workflow built in LanggraphJS
In the Figure 3.1, it's the problem solved graph deprived from Figure 2-2. About the Edges, the original Edges between conditional node and successors are broken and placed with the dashed Edges.
The Dynamic Pruning Strategy dynamically determines whether a node should execute its function or simply pass through, based on the status of upstream nodes and branches.
- Branch Tracking: Assign unique IDs to each branch and use prefix matching to identify related execution paths.
- Node Status Calculation: Before executing a node, check the status of all relevant upstream nodes and branches.
- Conditional Pruning: Skip nodes and branches that are no longer relevant due to conditional logic.
Execution Flow
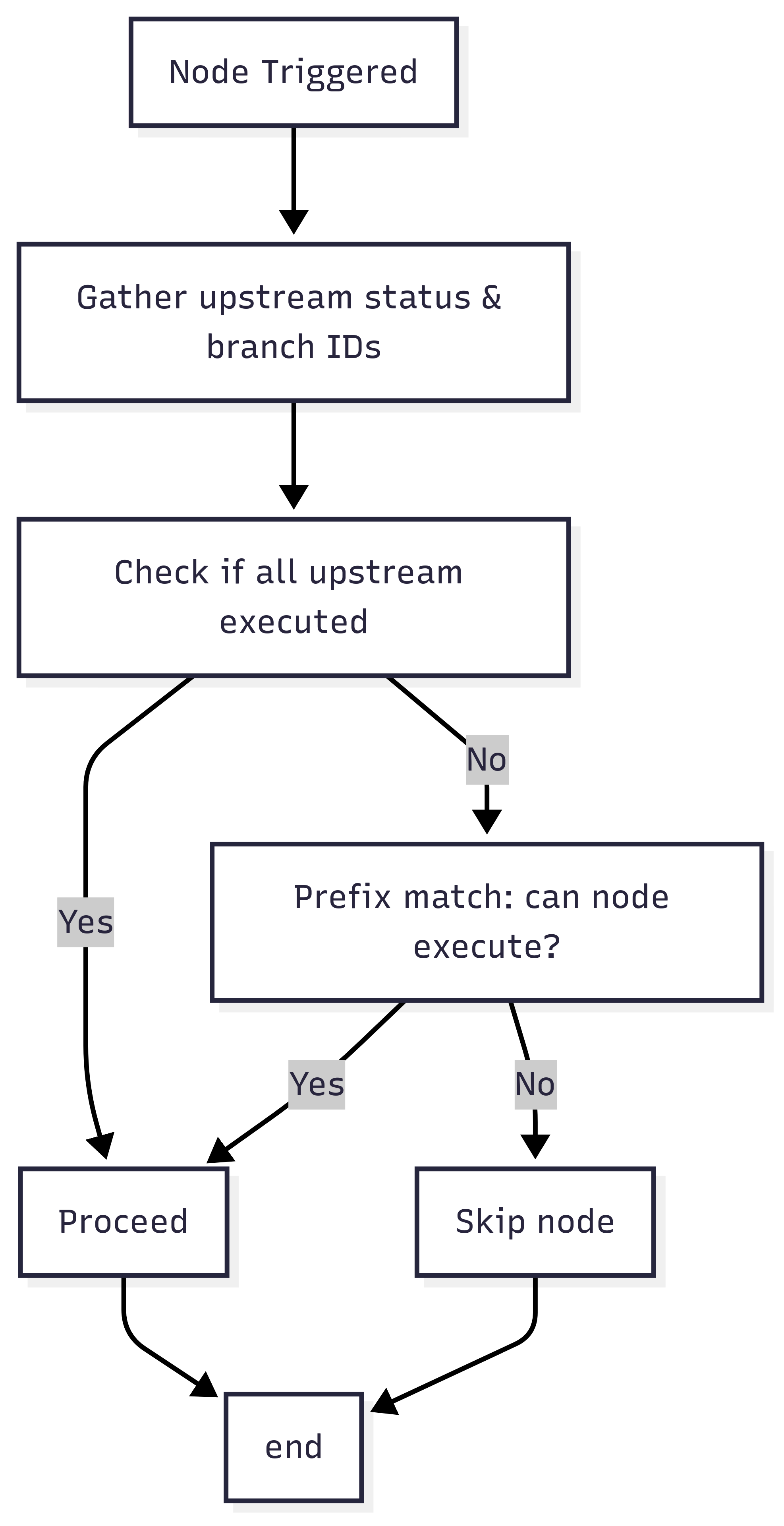
Figure 3.2: Dynamic Pruning Strategy execution flow
- When a node is triggered, gather the status and branch IDs of all dependent nodes.
- If all relevant upstream nodes are executed, proceed; if some are skipped, collect skipped branch IDs and if others are executed, collect executed branch IDs.
- Remove skipped branch IDs whose prefix is same with one of executed branch IDs, as they share the same ancestor conditional node.
- If all skipped branch IDs are removed, the node can execute; otherwise, it is skipped.
Example Implementation
Main Steps
//steps of the Flow
async execute(
state: WorkflowStateType,
langgraphRunnableConfig: LanggraphRunnableConfig,
): Promise<WorkflowStateType> {
try {
/** langgraphRunnableConfig.metadata
* Metadata for this call and any sub-calls (eg. a Chain calling an LLM).
* Keys should be strings, values should be JSON-serializable.
*/
this.runnable = langgraphRunnableConfig;
const curNode = langgraphRunnableConfig?.metadata
?.langgraph_node as string;
const triggers = (langgraphRunnableConfig?.metadata?.langgraph_triggers as string[]) || [];
const [shouldExecuted, updatedState] = await this.shouldExecute(
state,
curNode,
this.node.NodeType,
triggers,
langgraphRunnableConfig,
);
if (!shouldExecuted || this.node.NodeType === FlowNodeTypeEnum._FAKE) {
return updatedState;
}
const input = await this.normalizeData(Object.freeze(updatedState));
const runData = this.createRunData(input);
const stateWithRunData = await this.beforeHandle(
updatedState,
runData,
langgraphRunnableConfig,
);
const result = await this.handle(input, Object.freeze(stateWithRunData));
const finalState = await this.afterHandle(
stateWithRunData,
result,
runData,
langgraphRunnableConfig,
);
return finalState;
} catch (error) {
await this.handleError(error);
throw error;
}
}Dynamic pruning strategy
//core step of should Execute
protected async shouldExecute(
state: WorkflowStateType,
curNode: string,
nodeType: string,
triggers: string[],
runnable: LanggraphRunnableConfig,
): Promise<[boolean, WorkflowStateType]> {
// avoid the state be changed randomly
const newState = { ...state };
if (newState.statusNodes) {
newState.statusNodes = { ...newState.statusNodes };
}
if (newState.branchNodesMap) {
newState.branchNodesMap = { ...newState.branchNodesMap };
}
const statusNodes = newState.statusNodes || {};
const branchNodeSet = runnable.configurable?.branchNodeSet;
let curNodeStatus: NodeCalStatus = NodeCalStatus.WAITING;
const curNodeBranches = new Set<string>();
let skippedNodeBranch = new Set<string>(),
executedNodeBranch = new Set<string>();
let joinedStr: string = '';
if (nodeType === FlowNodeTypeEnum.START) {
curNodeStatus = NodeCalStatus.EXECUTED;
newState.statusNodes = {
...newState.statusNodes,
[curNode]: {
status: curNodeStatus,
branches: Array.from(curNodeBranches),
},
};
return [true, newState];
}
// process the langgraph triggers
for (const trigger of triggers) {
if (trigger.startsWith('branch')) {
// matched the triggers:["branch:node1:condition:nodec"]
const branchArray = trigger.split(':');
const branchId = branchArray[1],
conditionNode = branchArray[3];
//save the context with the matched next node of conditionNode
if (branchId || conditionNode) {
newState.branchNodesMap = {
...newState.branchNodesMap,
[branchId as string]: conditionNode,
};
}
}
if (trigger.startsWith('join')) {
joinedStr = trigger;
}
}
const branchNodesMap = newState.branchNodesMap;
//the encounter node status calculation
if (joinedStr) {
curNodeStatus = NodeCalStatus.EXECUTED;
const dependentNodes = joinedStr.split(':')?.[1]?.split('+') || [];
for (const dependentNode of dependentNodes) {
const dependentBranches: string[] =
statusNodes[dependentNode]?.branches || [];
const dependentNodeStatus: number =
statusNodes[dependentNode]?.status || 0;
if (dependentNodeStatus === NodeCalStatus.WAITING) {
curNodeStatus = NodeCalStatus.WAITING;
break;
}
const branchIdsFromParentNode = await this.getBranchIdsFromParentNode(
branchNodeSet,
dependentNode,
dependentBranches,
);
const statusFromParent = await this.getNextStatusFromParent({
parentNode: dependentNode,
parentNodeStatus: dependentNodeStatus,
branchNodeSet,
curNode,
branchNodesMap,
});
branchIdsFromParentNode.forEach((branchId) => {
curNodeBranches.add(branchId);
if (statusFromParent > 0) {
executedNodeBranch.add(branchId);
} else {
skippedNodeBranch.add(branchId);
}
});
}
}
// remove the branchIds with the prefix matched rule
skippedNodeBranch = await this.removeSkippedNodeBranchIds(
skippedNodeBranch,
executedNodeBranch,
);
if (curNodeStatus > 0) {
curNodeStatus = skippedNodeBranch.size
? NodeCalStatus.SKIPPED
: NodeCalStatus.EXECUTED;
}
newState.statusNodes = {
...newState.statusNodes,
[curNode]: {
status: curNodeStatus,
branches: Array.from(curNodeBranches),
},
};
return [curNodeStatus === NodeCalStatus.EXECUTED, newState];
}
private async getBranchIdsFromParentNode(
branchNodeSet: Set<string> | undefined,
parentNode: string,
parentBranchIds: string[],
): Promise<Set<string>> {
const branchIdsFromParentNode = new Set<string>();
if (branchNodeSet?.has(parentNode)) {
if (!parentBranchIds.length) parentBranchIds.push(`branch`);
parentBranchIds.forEach((v) =>
branchIdsFromParentNode.add([v, parentNode].join(':')),
);
} else {
parentBranchIds.forEach((v) => branchIdsFromParentNode.add(v));
}
return branchIdsFromParentNode;
}
private async getNextStatusFromParent(props: {
parentNode: string;
parentNodeStatus: NodeCalStatus;
branchNodeSet: Set<string> | undefined;
curNode: string;
branchNodesMap?: Record<string, any>;
}): Promise<NodeCalStatus> {
const {
parentNode,
parentNodeStatus,
branchNodeSet,
curNode,
branchNodesMap,
} = props;
let curNodeStatus = parentNodeStatus;
if (parentNodeStatus < 0) {
curNodeStatus = NodeCalStatus.SKIPPED;
} else {
if (branchNodeSet?.has(parentNode)) {
if (branchNodesMap?.[parentNode] != curNode) {
curNodeStatus = NodeCalStatus.SKIPPED;
} else {
curNodeStatus = NodeCalStatus.EXECUTED;
}
} else {
curNodeStatus = NodeCalStatus.EXECUTED;
}
}
return curNodeStatus;
}
/**
* 使用前缀算法从执行分支ID集合中移除跳过分支ID
* @param skippedNodeBranchIds 跳过的分支ID集合
* @param executedNodeBranchIds 执行的分支ID集合
* @returns 更新后的跳过分支ID集合
*/
private async removeSkippedNodeBranchIds(
skippedNodeBranchIds: Set<string>,
executedNodeBranchIds: Set<string>,
): Promise<Set<string>> {
if (skippedNodeBranchIds.size > 0) {
const executedPrefixes = Array.from(executedNodeBranchIds);
Array.from(skippedNodeBranchIds)
.filter((branchId) =>
executedPrefixes.some((prefix) => branchId.startsWith(prefix)),
)
.forEach((item) => skippedNodeBranchIds.delete(item));
}
return skippedNodeBranchIds;
}Conclusion
The Dynamic Pruning Strategy provides a practical solution to two common execution flow problems in LangGraphJS:
- Node blocking issues in workflows with converging branches
- Premature triggering of nodes in conditional workflows
By intelligently calculating node execution status and using prefix matching to track branch relationships, this strategy enables complex agent workflows to run reliably without deadlocks.
While this approach requires adding some boilerplate code to your projects, it solves problems that don't yet have official solutions in LangGraphJS. The technique can be implemented as a wrapper around your existing node functions with minimal changes to your workflow design.


