
This is a Plain English Papers summary of a research paper called DynPose-100K: Large-Scale Dynamic Video Dataset with Camera Poses. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Challenge of Camera Pose Estimation in Dynamic Videos
Annotating camera poses on dynamic Internet videos at scale is critical for advancing fields like realistic video generation and simulation. However, collecting such a dataset is difficult because most Internet videos are unsuitable for pose estimation, and dynamic scenes present significant challenges even for state-of-the-art methods.
Existing datasets use synthetic data, which provides ground truth but lacks scale and diversity, or real-world videos from restricted domains with constraints that make pose estimation easier, such as turntable-style captures, multiple cameras, or dense viewpoints.
DynPose-100K addresses these limitations by providing a large-scale dataset of diverse dynamic Internet videos annotated with camera poses. The dataset is curated through a carefully designed pipeline that solves two key challenges: identifying suitable videos for pose estimation and developing an effective method to estimate camera poses in dynamic scenes.

We introduce DynPose-100K, a large-scale video dataset of dynamic content with camera annotations. DynPose-100K consists of 100,131 Internet videos that span diverse settings. We curate DynPose-100K such that videos contain dynamic content while ensuring the cameras are able to be estimated (including intrinsics and poses).
The key contributions include:
- DynPose-100K, a large-scale dataset of dynamic Internet videos with camera annotations
- A filtering pipeline that combines task-specific models and a vision-language model
- A dynamic pose estimation pipeline that integrates state-of-the-art components in tracking and masking
- Experiments showing that the filtering method selects videos with high precision and the pose estimation method reduces error by up to 90% compared to alternatives
Previous Approaches to Dynamic Camera Pose Datasets
Creating datasets of dynamic videos with camera poses has been challenging. Most existing approaches use synthetic data or constrained real-world settings.
Synthetic datasets like MPI Sintel and FlyingThings3D provide ground truth camera data but are relatively small-scale due to the high cost of 3D assets and face a sim-to-real gap. Real-world datasets often rely on constraints that make structure-from-motion (SfM) easier, such as ego-centric videos (EpicFields), LiDAR sensory data (Waymo), multiple cameras (Ego-Exo4D), or turntable-style videos (CoP3D). These constraints limit the diversity of the collected data.
Camera pose estimation for dynamic scenes is particularly challenging because dynamic correspondences cannot be used for bundle adjustment and also limit static correspondence. Recent work has attempted to address this through masking dynamics using learned prediction or motion and semantic cues, and improving correspondence estimation.
Concurrent works like CamCo and B-Timer also collect diverse videos but are smaller in scale and privately held. DynPose-100K builds on advances in tracking (BootsTAP) and masking methods trained on large amounts of real data to create a large-scale public dataset.
Building DynPose-100K: A Three-Step Process
Defining What Makes a Good Video for Camera Pose Estimation
Most Internet videos are not suitable for camera pose estimation. Analysis of a random test set from Panda-70M reveals that only 9% of videos satisfy the necessary criteria.

Statistics reflect human labels on held-out 1K video Panda-Test set. Only 9% are target dynamic camera pose estimation videos due to various issues, e.g. static scene, low-quality or non-real content, and ambiguous or blurry frame of reference. We focus on moving cameras to facilitate downstream tasks e.g. camera-controlled video generation and learned pose estimation.
Videos suitable for camera pose estimation must satisfy three criteria:
Real-world and quality video: Videos must be from the real world (not cartoons, screen recordings, composited videos, or heavily edited content) and have sufficient quality, resolution, and frame rate without non-perspective distortion.
Feasibility for pose prediction: Videos should not contain severe zoom effects, abrupt shot changes, or ambiguous reference frames (e.g., scenes filmed inside a moving car). Videos without static correspondences (e.g., when the background is fully blurred or occluded) should be excluded.
Dynamic camera and scene: Non-static camera allows non-trivial pose for training pose estimation or camera-controlled video generation methods. Videos with moving cameras and dynamic scenes provide richer data for a wider range of downstream applications.
Finding the Needle in the Haystack: Filtering Suitable Videos
The filtering process aims to identify videos that match these three criteria. It combines specialized models that address specific, frequently occurring reasons for rejection, with a generalist vision-language model (VLM) that can detect a variety of issues.
Specialized models include:
Cartoons and presenting: Removes videos failing criteria C1 (e.g., cartoons, screen recordings) and C3 (e.g., static scenes of people sitting in front of cameras).
Non-perspective distortion: Removes videos with high predicted distortion (C1).
Focal length: Removes videos with high focal length variance (indicating zoom effects or shot changes - C2) or very long focal lengths (C2, C3).
Dynamic object masking: Removes videos with excessively large predicted mask sizes, which make pose estimation infeasible (C2).
Optical flow: Removes videos with high peak sequential flow (indicating shot changes - C2) or low mean flow (indicating static scenes - C3).
Point tracking: Removes videos with abrupt disappearance of predicted point tracks (C2) or extremely stable tracks (C3).
The generalist VLM addresses various other reasons for rejection by answering questions about ambiguous reference frames, blurry backgrounds, distortion, static scenes, cartoons, post-processing, and the presence of children.
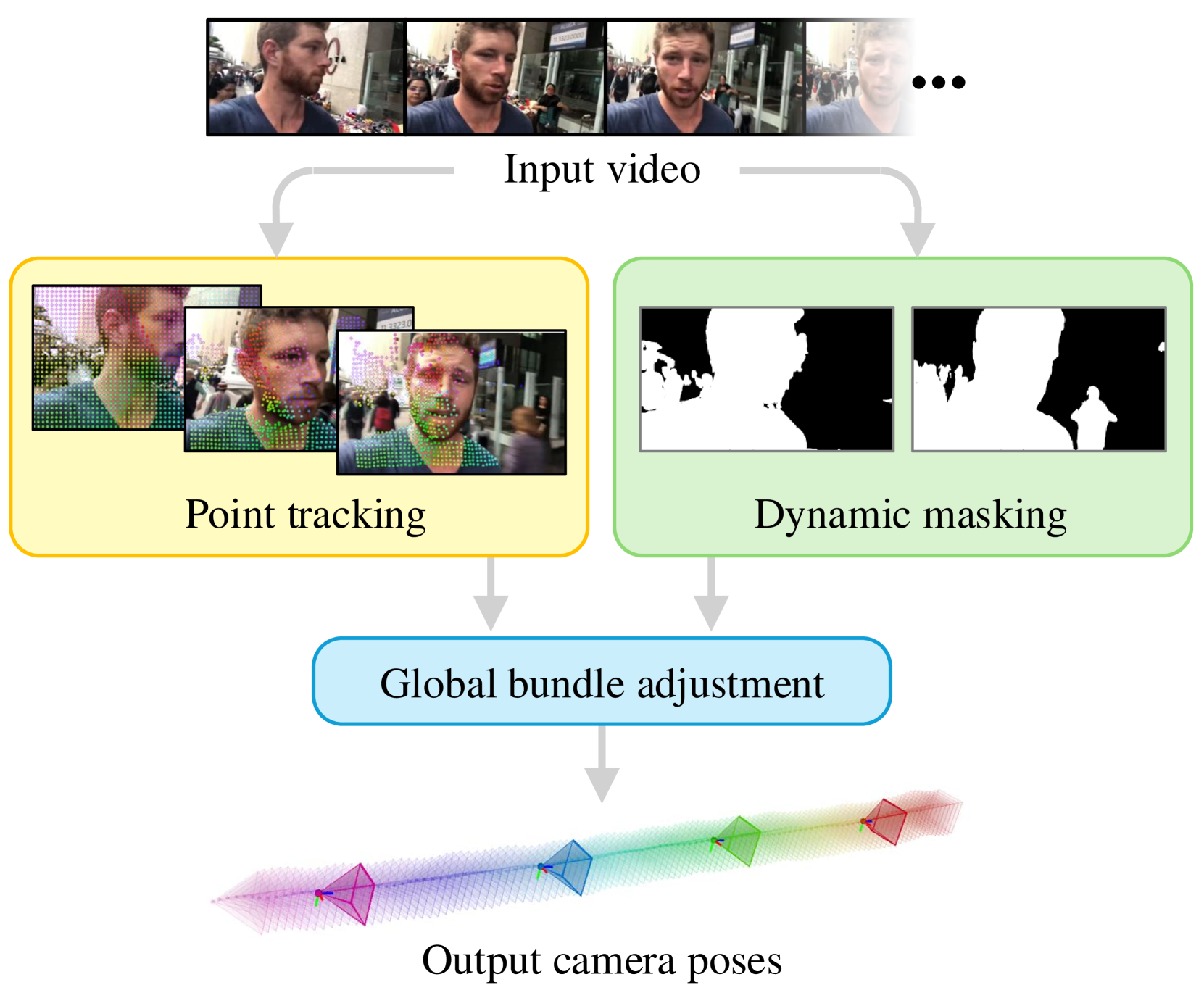
We apply the state-of-the-art point tracking method at a sliding window to produce dense, long-term correspondences. Complementary dynamic masks are used to remove non-static tracks. The remaining static tracks are provided as input to global bundle adjustment.
Starting from 3.2 million Panda-70M videos, the filtering process yielded 137,000 candidate videos for pose estimation. After estimating pose on 107,000 videos and dropping trajectories with less than 80% of frames registered, the final dataset contains 100,131 videos.
The Technical Core: Estimating Camera Poses in Dynamic Scenes
Pose estimation on dynamic Internet video is challenging because dynamic objects occlude the underlying static scene, and the static scene can change appearance, making correspondence estimation difficult. The approach addresses both challenges through:
-
Dynamic masking: Combines four complementary approaches:
- Semantic segmentation using OneFormer to mask common dynamic classes
- Object interaction segmentation using Hands23 to mask held objects
- Motion segmentation using RoDynRF to mask regions with high Sampson error
- Mask propagation using SAM2 to provide smooth masks with precise boundaries
Point tracking: Uses BootsTAP to track a grid of points in a sliding window fashion, taking advantage of temporal information to improve correspondence estimation. This provides dense, long-term correspondences and reduces drift.
Global bundle adjustment: Uses Theia-SfM with correspondences from tracklets as input, excluding pairs containing frames where tracklets are contained within dynamic masks.
| Dataset | Real/Syn. | Num. vids. | Num. frames | Domain | Access |
|---|---|---|---|---|---|
| T.Air Shibuya [62] | Syn. | 7 | 0.7 K | Street | Public |
| MPI Sintel [7] | Syn. | 14 | 0.7 K | Scripted | Public |
| PointOdyssey [105] | Syn. | 131 | 200 K | Walking | Public |
| FlyingThings3D [51] | Syn. | 220 | 2 K | Objects | Public |
| Kubric Movi-E [28] | Syn. | 400 | 10 K | Objects | Public |
| EpicFields [81] | Real | 671 | 19,000K | Kitchens | Public |
| Waymo [75] | Real | 1,150 | 200 K | Driving | Public |
| CoP3D [72] | Real | 4,200 | 600 K | Pets | Public |
| Ego-Exo4D [27] | Real | 5,035 | $\mathbf{2 3 , 0 0 0 K}$ | Set tasks | Public |
| Stereo4D [37] | Real | $\mathbf{1 1 0 , 0 0 0}$ | 10,000 K | S. fisheye | Public |
| CamCo [93] | Real | 12,000 | 385 K | Diverse | Private |
| B-Timer [45] | Real | 40,000 | 19,000K | Diverse | Private |
| DynPose-100K | Real | 100,131 | 6,806K | Diverse | Public |
Dynamic camera pose datasets. DynPose-100K has the most videos of diverse Internet video datasets. Datasets with more frames are private or more uniform; e.g. stereo fisheye is typically outdoor PoV walking. We use short videos, yielding fewer frames but high dynamics.
This table shows that DynPose-100K contains many more videos than existing diverse datasets. The largest alternatives are typically limited to specific settings, such as kitchens, driving, or pet turntable videos. Concurrent works CamCo and B-Timer also feature diverse content but have fewer videos and are private.
Analyzing DynPose-100K: Quality and Diversity
Validating the Filtering Approach
The effectiveness of the filtering pipeline was evaluated on Panda-Test, a set of 1,000 randomly selected held-out videos from Panda-70M, manually classified as suitable or unsuitable for pose estimation. Only 90 videos (9%) were found to be suitable.
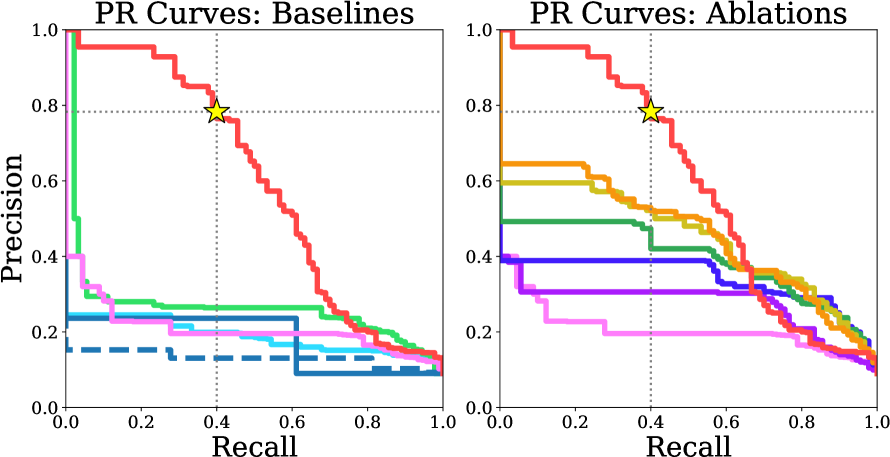
Dynamic video filtering on Panda-Test. The PR curves show that the proposed filtering method outperforms all baselines and ablations by a considerable margin.
The primary evaluation metrics were precision (the proportion of selected videos that are actually suitable) and recall (the proportion of suitable videos that are selected). The filtering approach achieved a test precision of 0.78 at the threshold used for collecting DynPose-100K, a level that no baseline achieved at any recall except for reprojection error at 0.02 recall.
Each component in the filtering method improved performance, with the VLM providing a large boost, even though it was relatively weak as a standalone approach.
What's in the Dataset: Scale, Content, and Characteristics
DynPose-100K contains 100,131 videos, making it the largest public dataset of diverse dynamic Internet videos with camera annotations. The content is varied, with frequent nouns covering a wide range of subjects (person, hand, car), objects (shirt, table, food), and settings (room, kitchen, street), while verbs span diverse actions (using, working, playing).
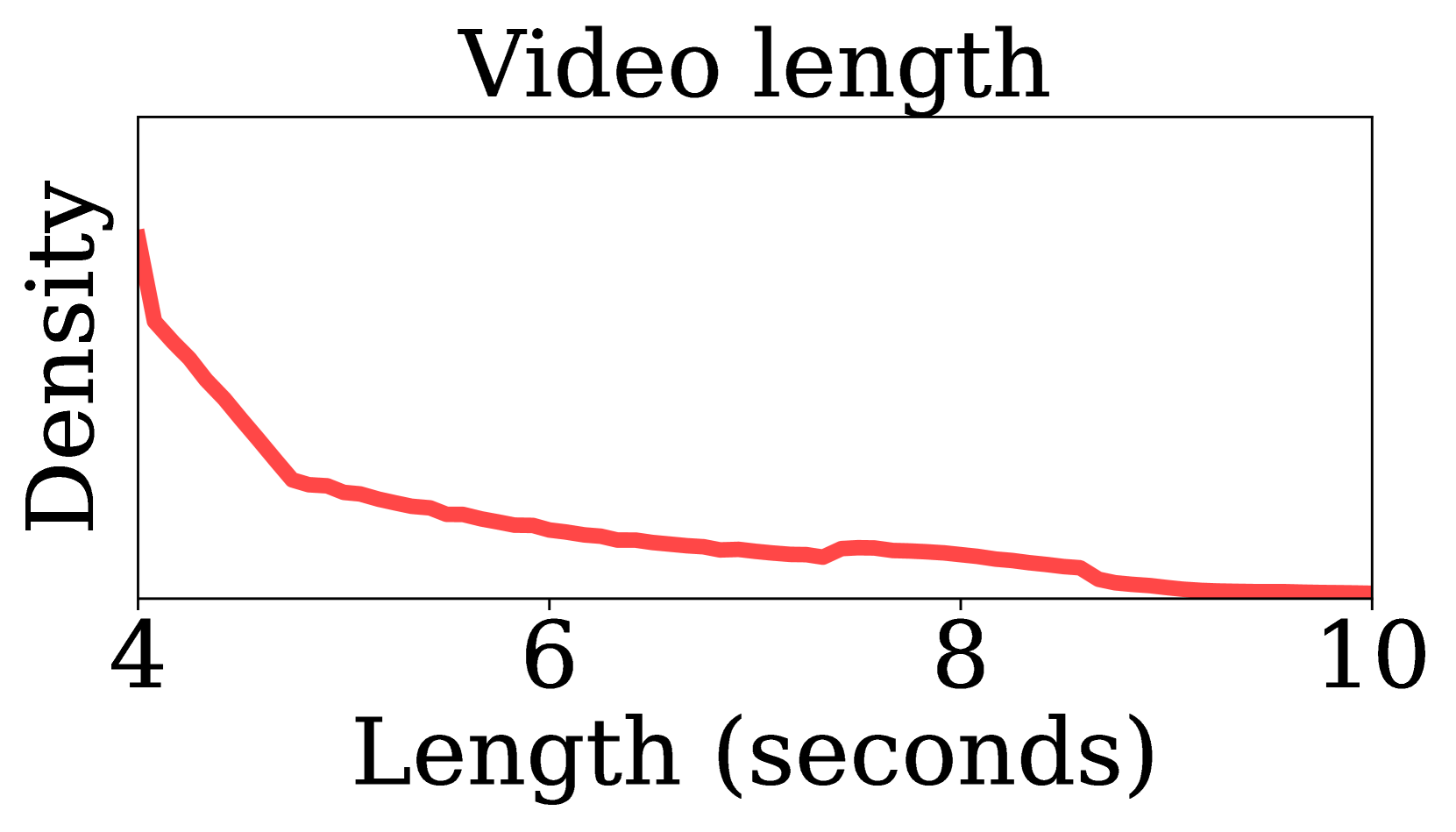
Left: Targeted video length. DynPose-100K videos are primarily 4-10s, ideal for dynamic pose: shorter videos contain little ego-motion, longer videos have less dense dynamics and ego-motion. Right: Diverse dynamic apparent size. Mean size in % across video. Large dynamic objects occlude static correspondences, making pose estimation challenging.
Most videos span 4 to 10 seconds, which is ideal for pose estimation: long enough for substantial camera motion but short enough to maintain dense dynamics. The dataset also features a wide range of apparent dynamic object sizes, from small to large. This diversity is important because large objects occlude static correspondences (making pose estimation challenging), while small objects can move quickly (making precise masking difficult).
Similar work on synthesizing pose data has shown the importance of diversity in training data for robust pose estimation models. DynPose-100K complements such synthetic approaches with real-world data.
Proving the Quality: Evaluating Camera Pose Estimation
Testing on Synthetic Data: The Lightspeed Benchmark
Direct evaluation on dynamic Internet videos is challenging due to the lack of ground truth camera pose data. To address this, the researchers created Lightspeed, a photorealistic synthetic benchmark with ground truth camera poses.
Lightspeed follows several RC cars moving quickly through challenging indoor and outdoor scenes, featuring day and night lighting, and first and third-person views. Like DynPose-100K, it contains diverse environments, large dynamic objects, and varied clip lengths.
| All 36 videos (Iden. Rot. + Rand. Tr. if fail) | 8 videos: all succeed only | ||||||
|---|---|---|---|---|---|---|---|
| Method | \% Vids. reg. $\uparrow$ | ATE (m) $\downarrow$ | RPE Tr. (m) $\downarrow$ | RPE Rot. $\left({ }^{\circ}\right) \downarrow$ | ATE (m) $\downarrow$ | RPE Tr. (m) $\downarrow$ | RPE Rot. $\left({ }^{\circ}\right) \downarrow$ |
| Iden. Rot. + Rand. Tr. | 100. | 0.652 | 0.139 | 1.60 | 0.390 | 0.080 | 1.00 |
| DROID-SLAM [79] | 100. | 0.198 | 0.046 | 1.75 | 0.048 | 0.017 | 0.82 |
| DUSt3R [86] | 97.2 | 0.412 | 0.177 | 20.1 | 0.256 | 0.124 | 18.5 |
| MonST3R [100] | 100. | 0.149 | 0.046 | 1.21 | 0.036 | 0.011 | 0.46 |
| LEAP-VO [13] | 100. | 0.206 | 0.049 | 1.70 | 0.037 | 0.011 | 0.73 |
| COLMAP [66] | 44.4 | 0.388 | 0.082 | 2.03 | 0.122 | 0.026 | 1.91 |
| COLMAP+Mask [66] | 38.9 | 0.323 | 0.085 | 1.64 | 0.089 | 0.017 | 1.36 |
| ParticleSfM [103] | 97.2 | 0.185 | 0.075 | 2.99 | 0.051 | 0.047 | 2.91 |
| Ours | 100. | 0.072 | 0.033 | 1.31 | 0.003 | 0.002 | 0.30 |
Camera pose estimation on Lightspeed. Our pose estimation algorithm registers all sequences and cuts trajectory error by 50% across all sequences (left) and 90% on easy sequences (right) vs. all other methods.
The results show that COLMAP and COLMAP+Mask struggle to register many challenging sequences in Lightspeed. DROID-SLAM, DUSt3R, LEAP-VO, and ParticleSfM provide registration but are inaccurate. MonST3R offers better trajectory error, but the proposed method is clearly superior, cutting trajectory error by 50% across all videos and 90% on the subset of videos where all methods succeed.

Predicted trajectories on Lightspeed. Pose sequence over time: ROYGBV. We visualize photorealistic renderings of Lightspeed left. Static methods DROID-SLAM, COLMAP and DUSt3R struggle in this dynamic setting, failing to register a consistent sequence or putting too much or too little curvature.
The qualitative results confirm these findings, showing that the proposed method produces smooth and accurate trajectories while all alternatives struggle in at least one sequence.
This improvement in camera pose estimation is particularly important for applications like 6D object pose tracking, where accurate camera trajectories are essential for tracking objects in dynamic scenes.
Testing on Real Data: Evaluating on Panda-Test
To evaluate on real-world data without ground truth poses, the researchers annotated 10,000 precise correspondences on Panda-Test. This allows computation of reprojection error (Sampson error) from the predicted poses.
| All 90 estimable videos (Identity if fail) | 52 videos: all succeed only | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| \% Vids. registered $\uparrow$ |
Mean per-video reprojection error, 720p | Mean per-video reprojection error, 720p | |||||||
| $\%<5 \mathrm{Pix} \uparrow$ | $\%<10 \mathrm{Pix} \uparrow$ | $\%<30 \mathrm{Pix} \uparrow$ | Mean $\downarrow$ | $\%<5 \mathrm{Pix} \uparrow$ | $\%<10 \mathrm{Pix} \uparrow$ | $\%<30 \mathrm{Pix} \uparrow$ | Mean $\downarrow$ | ||
| Identity | 100. | 0.0 | 0.0 | 2.2 | 151 | 0.0 | 0.0 | 0.0 | 133 |
| DROID-SLAM [79] | 100. | 57.8 | 77.8 | 94.4 | 11.0 | 59.6 | 84.6 | 96.2 | 6.78 |
| DUSt3R [86] | 96.7 | 0.0 | 6.7 | 48.9 | 43.0 | 0.0 | 9.6 | 57.7 | 30.3 |
| MonST3R [100] | 100. | 55.6 | 78.9 | 90.0 | 9.86 | 63.5 | 84.6 | 90.4 | 9.71 |
| LEAP-VO [13] | 100. | 64.4 | 76.7 | 96.7 | 7.59 | 75.0 | 84.6 | 98.1 | 6.03 |
| COLMAP [66] | 82.2 | 51.1 | 62.2 | 73.3 | 27.5 | 71.2 | 82.7 | 92.3 | 9.03 |
| COLMAP+Mask [66] | 67.8 | 47.8 | 58.9 | 75.6 | 30.1 | 69.2 | 82.7 | 96.2 | 6.10 |
| ParticleSfM [103] | 92.2 | 70.0 | 76.7 | 88.9 | 12.5 | 80.8 | 86.5 | 96.2 | 6.77 |
| Ours | 95.6 | 72.2 | 84.4 | 98.9 | 5.76 | 82.7 | 94.2 | 100. | 3.75 |
Camera pose estimation on Panda-Test. Reprojection error on 10K image pairs, by video, normalized to 720p. Static methods DUSt3R and COLMAP struggle faced with dynamics while DROID-SLAM lacks precision. ParticleSfM registers more videos than COLMAP+Mask but both fall short of Ours in registration and accuracy.
The results on Panda-Test show similar trends to Lightspeed: static methods like DROID-SLAM and DUSt3R are inaccurate, while COLMAP (even with dynamic masking) struggles to register many videos. ParticleSfM improves registration but has high mean error. The proposed method reduces error across all metrics, including more than 35% reduction in mean error compared to all other methods on the 52 sequences where all methods succeed.
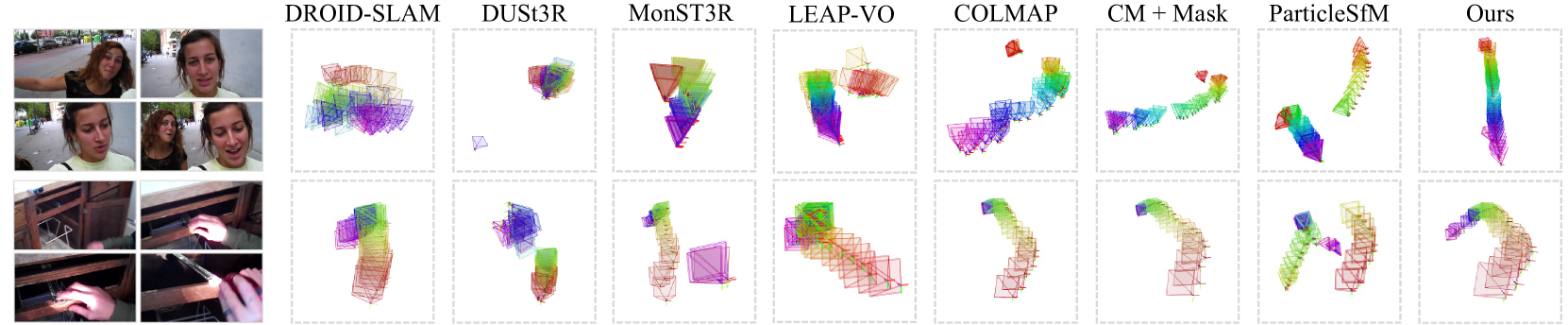
Predicted trajectories on Panda-Test. Pose sequence over time: ROYGBV. Static methods like DROID-SLAM, DUSt3R and COLMAP struggle faced with dynamics. MonST3R, LEAP-VO, COLMAP+Mask and ParticleSfM can struggle with large dynamic regions (top) and tracking across varied appearance and lighting (bottom); while Ours handles these cases.
The qualitative results agree with the quantitative findings: the proposed method better handles difficult cases such as large dynamic regions and varied appearance, while alternatives face various failure modes.
Alternative approaches to the dynamic pose estimation problem, such as using humans as calibration patterns, may benefit from the techniques developed for DynPose-100K, particularly the advanced masking and tracking components.
| All 90 estimable videos (Identity if fail) | |||||
|---|---|---|---|---|---|
| \% Vids. reg. $\uparrow$ |
$\%<10 \mathrm{Pix} \uparrow$ | $\%<10 \mathrm{Pix} \uparrow$ | $\%<30 \mathrm{Pix} \uparrow$ | Mean $\downarrow$ | |
| DUSt3R | 96.7 | 0.0 | 6.7 | 48.9 | 43.0 |
| + Synthetic (MonST3R [100]) | 100. | 55.6 | 78.9 | 90.0 | 9.86 |
| + DynPose-100K (Ours) | 100. | 54.4 | 82.2 | 92.2 | 8.78 |
Camera pose estimation on Panda-Test. DynPose-100K fine-tuning of DUSt3R has lower mean error and similar to or better than accuracy compared to synthetic data (MonST3R).
The dataset also proves its value for improving existing methods. Fine-tuning DUSt3R on just 2,000 videos from DynPose-100K achieves lower mean error and similar or better accuracy compared to training on synthetic data (MonST3R). This demonstrates the dataset's efficiency for supervision.
Impact and Future Directions
DynPose-100K represents a significant advancement in the field of dynamic camera pose estimation. By providing a large-scale, diverse dataset of Internet videos with camera annotations, it enables progress in various downstream applications:
Video generation: Camera-controlled dynamic video generation models can benefit from the diverse camera trajectories and dynamic scenes in the dataset.
View synthesis: Large-scale training of view synthesis models for extended reality applications becomes possible with the annotated camera poses.
Robotics: The dataset can transform imitation learning and training in realistic simulation environments.
The dataset's impact is further enhanced by its public availability, enabling broader research impact compared to concurrent private datasets.
The filtering pipeline and pose estimation method developed for creating DynPose-100K also represent significant technical contributions. The filtering approach effectively identifies the small percentage of Internet videos suitable for pose estimation, while the pose estimation method integrates state-of-the-art components in masking, tracking, and bundle adjustment to achieve superior performance.
Future work could leverage DynPose-100K for developing more robust camera pose estimation methods, particularly for challenging dynamic scenes. The dataset could also serve as a foundation for creating more sophisticated video generation models that accurately respect camera physics and for advancing dynamic object pose estimation in complex scenes.
| Reprojection error | \%Data $\uparrow$ | $\%<5 \uparrow$ | $\%<10 \uparrow$ | Mean $\downarrow$ |
|---|---|---|---|---|
| Full test set | $\mathbf{1 0 0 .}$ | 72.2 | $\underline{84.4}$ | 5.76 |
| Reproj. err. $<1.37$ | $\underline{71.1}$ | 78.1 | $\underline{84.4}$ | 5.04 |
| Reproj. err. $<1.18$ | 41.1 | $\underline{81.1}$ | 83.8 | $\underline{4.49}$ |
| Reproj. err. $<1.00$ | 24.4 | $\mathbf{8 1 . 8}$ | $\mathbf{8 6 . 4}$ | $\mathbf{3 . 8 5}$ |
Identifying high-quality poses. Reprojection error is effective in identifying low error videos in Panda-Test. It is useful to produce high-quality subsets of DynPose-100K.
Future users of DynPose-100K may also consider filtering by reprojection error to create high-quality subsets tailored to specific applications. As shown in the table, retaining only videos with low reprojection error significantly reduces the mean error of the dataset.
