This is a Plain English Papers summary of a research paper called Emo Pillars: AI Cracks Context for Better Sentiment Analysis. See How!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Building Better Emotion Detectors: How Emo Pillars Brings Context to AI Sentiment Analysis
Detecting emotions in text is harder than it looks. A simple phrase like "I need to land this plane" could express fear, determination, or confidence - depending on the context. Most emotion detection systems struggle with this nuance, either lacking context awareness or working with limited emotion categories.
Researchers from Alexander Shvets have created a solution called Emo Pillars, which uses knowledge distillation to create lightweight, context-aware models for fine-grained emotion detection.
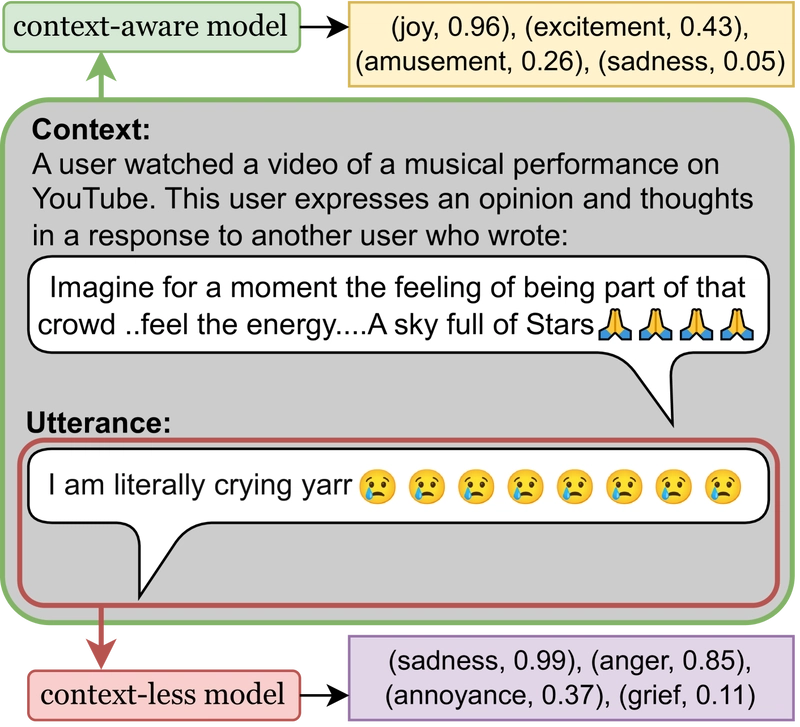
Difference in context-less and context-aware emotion classification. Context-less models detect emotions in the entire input (including context if provided), while context-aware models can grasp the input structure and extract emotions only from the utterance.
The Problem with Current Emotion Detection
Current emotion detection has two major issues:
Limited context: Most datasets provide isolated statements without situational context, making emotion interpretation subjective.
Resource intensity: While large language models like GPT-4 can understand context, they struggle with emotions - often over-predicting them - and require significant computing resources.
The researchers found that medium-sized models like RoBERTa remain better options for emotion detection, but they need more diverse training examples than currently available datasets provide.
Building a Better Dataset Pipeline
To solve these problems, the researchers created a sophisticated data generation pipeline using the Mistral-7B language model.
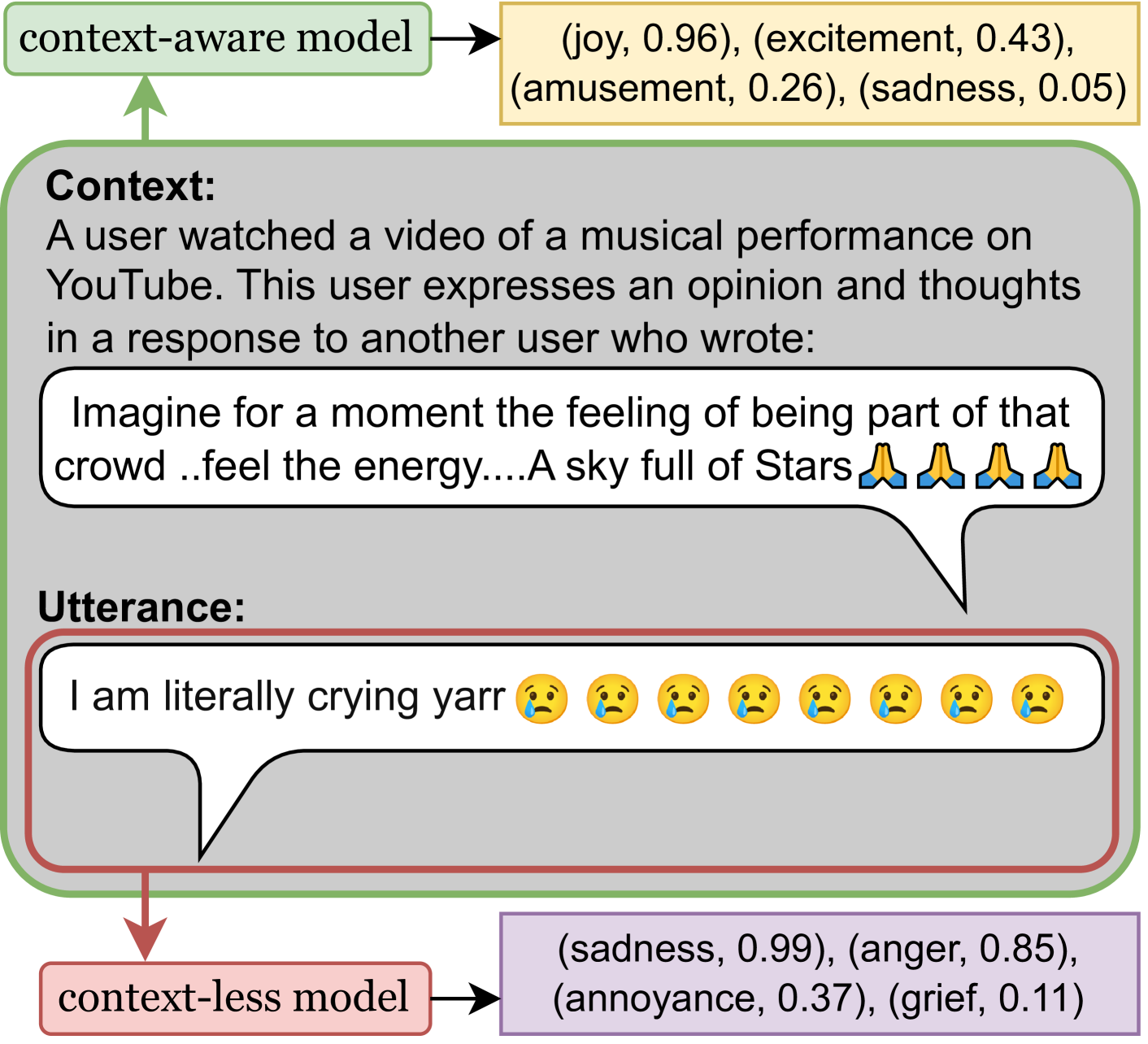
Pipeline for generating a dataset for multi-label context-aware (-less) emotion recognition.
The pipeline involves five key steps:
Content-rich instructions: Using narrative texts (like movie plots) as seeds and generating emotions from different character perspectives.
Multiple example generation: Creating several utterances at once for different emotions to increase diversity.
Soft labelling: Assigning multiple emotion labels with expressiveness scores (0-0.1) to reduce ambiguity.
Context generation and cleaning: Reconstructing situations without revealing emotions and cleaning them to remove emotional cues.
Context importance upscale: Rewriting utterances to be less emotionally explicit, forcing models to rely more on context.
For example, an explicit emotional utterance: "I'm really scared right now. I don't know what to do. I need to get this plane down safely."
Gets rewritten as: "I'm not sure what to do. I need to land this plane."
This makes the context crucial for understanding the emotion.
The Emo Pillars Dataset
Using 113K synopses from Wikipedia as a seed corpus, the researchers generated:
- 300K context-less examples
- 100K context-full examples
- All covering 28 emotion categories
The dataset creation required 450 GPU hours on NVIDIA H100 hardware.
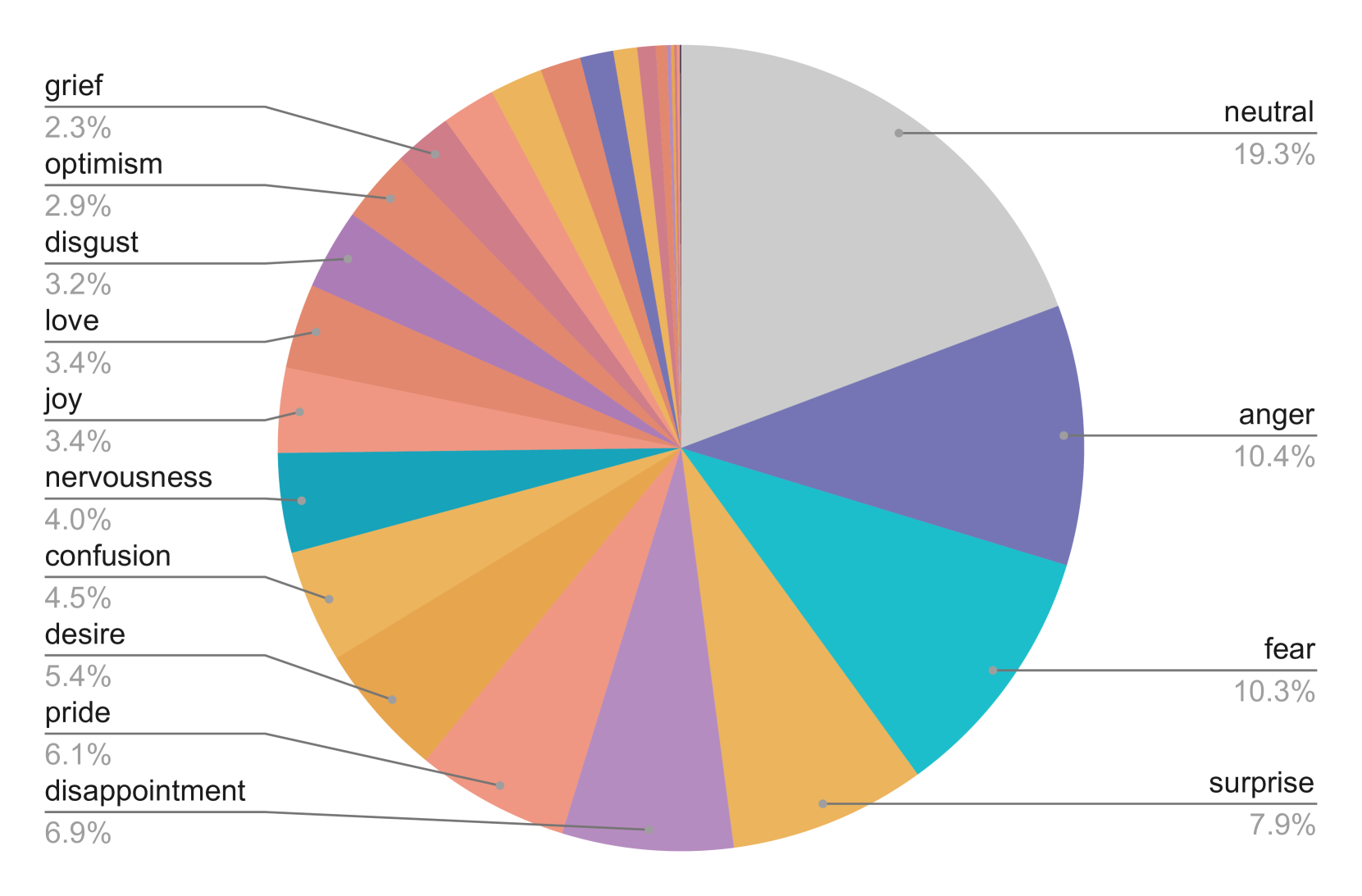
Distribution of primary emotions in the dataset.
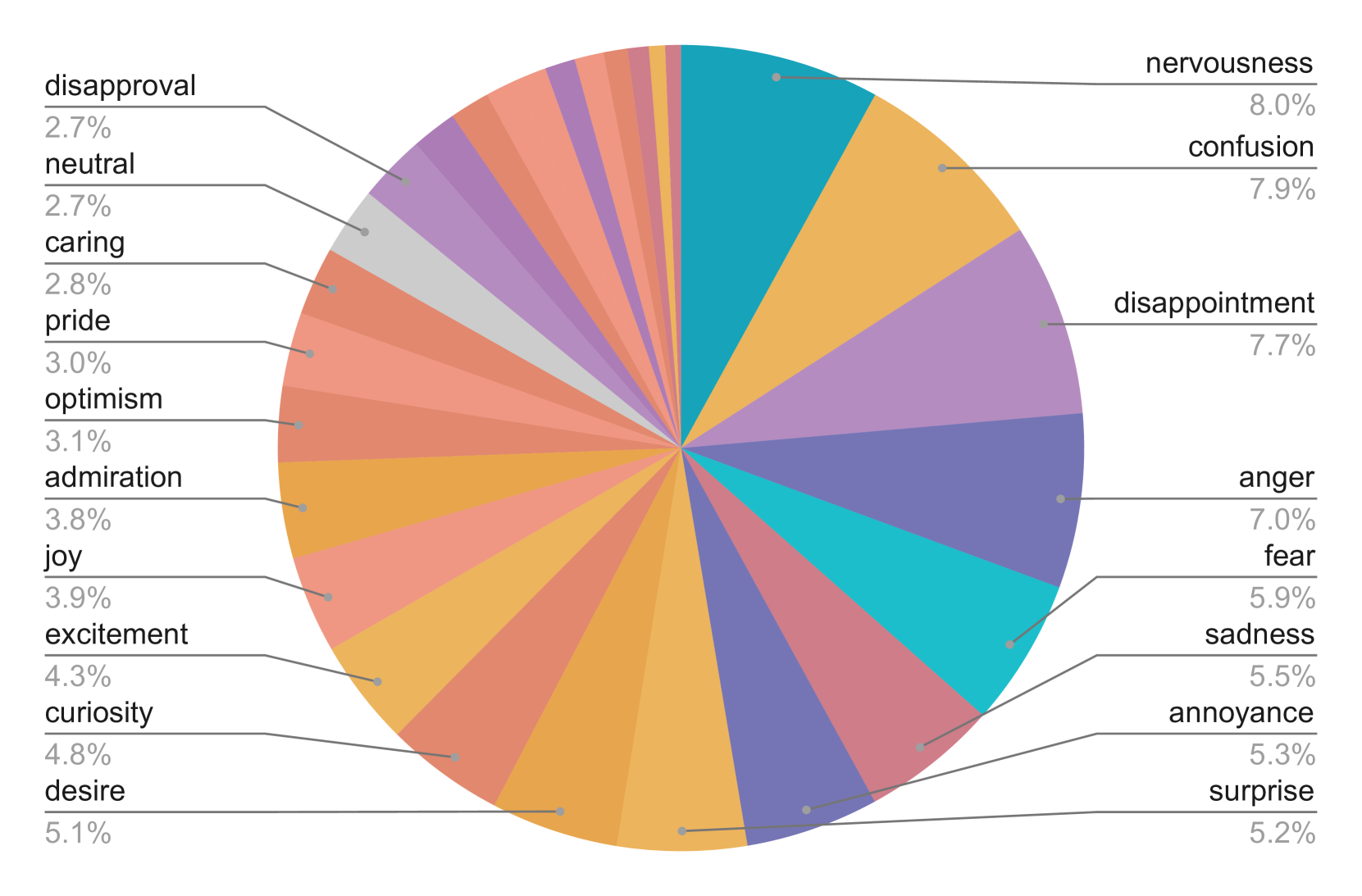
Distribution of soft emotional labels in the dataset (after filtering by the expressiveness level).
The dataset uses the same emotion taxonomy as the popular GoEmotions dataset, but provides 50 times more examples per emotion on average, with better balance across positive, negative, and ambiguous polarities.

Dataset splits: Orig (context-less examples), COrig (context-full examples), CRewr (the same context-full examples with rewritten utterances).
Testing the Models
The researchers fine-tuned various BERT-type encoders using the dataset, creating the Emo Pillars models that handle both context-less and context-aware emotion recognition.
Context-less Emotion Recognition
For the GoEmotions benchmark, Emo Pillars achieved state-of-the-art performance:
| Model | P | R | F1 |
|---|---|---|---|
| GPT4 (Wang et al., 2024) | 0.10 | 0.17 | 0.13 |
| GPT4 (Kok-Shun et al., 2023) | - | - | 0.22 |
| emo π-BERTOrig | 0.26 | 0.42 | 0.28 |
| emo π-RoBERTaOrig | 0.25 | 0.45 | 0.28 |
| emo π-RoBERTaRewr | 0.22 | 0.33 | 0.22 |
| BERT-based (Demszky et al., 2020) | 0.40 | 0.63 | 0.46 |
| BERT-based (Alvarez-Gonzalez et al., 2021) | - | - | 0.48 |
| RoBERTa-based (Cortiz, 2022) | - | - | 0.49 |
| RoBERTa-based GPT-JA (Kok-Shun et al., 2023) | - | - | 0.51 |
| BERT-based BART (Wang et al., 2024) | 0.52 | 0.53 | 0.52 |
| emo π-BERTOrig-fine-tuned | 0.51 | 0.57 | 0.54 |
| emo π-RoBERTaOrig-fine-tuned | 0.53 | 0.58 | 0.55 |
Evaluation on the GoEmotions task. The fine-tuned Emo Pillars models achieve state-of-the-art performance.
The F1 score of 0.55 represents a significant improvement over previous approaches.
Context-aware Emotion Recognition
When testing on context-aware scenarios, the models proved even more valuable:
| Model | Set | P | R | F1 |
|---|---|---|---|---|
| emo π-CRoBERTaCOrig | dev4 | 0.60 | 0.51 | 0.53 |
| emo π-CRoBERTaCRewr | dev4 | 0.50 | 0.58 | 0.54 |
| The 1st at (Chatterjee et al., 2019) | test3 | 0.8086 | 0.7873 | 0.7963 |
| ANA (the 5th) (Huang et al., 2019) | test3 | 0.7785 | 0.7713 | 0.7729 |
| emo π-CRoBERTaCOrig-fine-tuned | dev3 | 0.7467 | 0.7633 | 0.7567 |
| emo π-CRoBERTaCRewr-fine-tuned | dev3 | 0.7633 | 0.7833 | 0.7733 |
| emo π-CRoBERTaCOrig-fine-tuned | dev4 | 0.80 | 0.81 | 0.81 |
| emo π-CRoBERTaCRewr-fine-tuned | dev4 | 0.81 | 0.83 | 0.82 |
Evaluation on the EmoContext task. The number of used classes is in the subscripts of the sets.
The models trained on rewritten utterances with context perform better than those trained on more explicit utterances, showing the value of context-awareness.
Real-World Application: Music Performance Feedback
The researchers tested Emo Pillars on analyzing YouTube comments for music performances - a valuable use case where creators need detailed emotional feedback from their audiences.
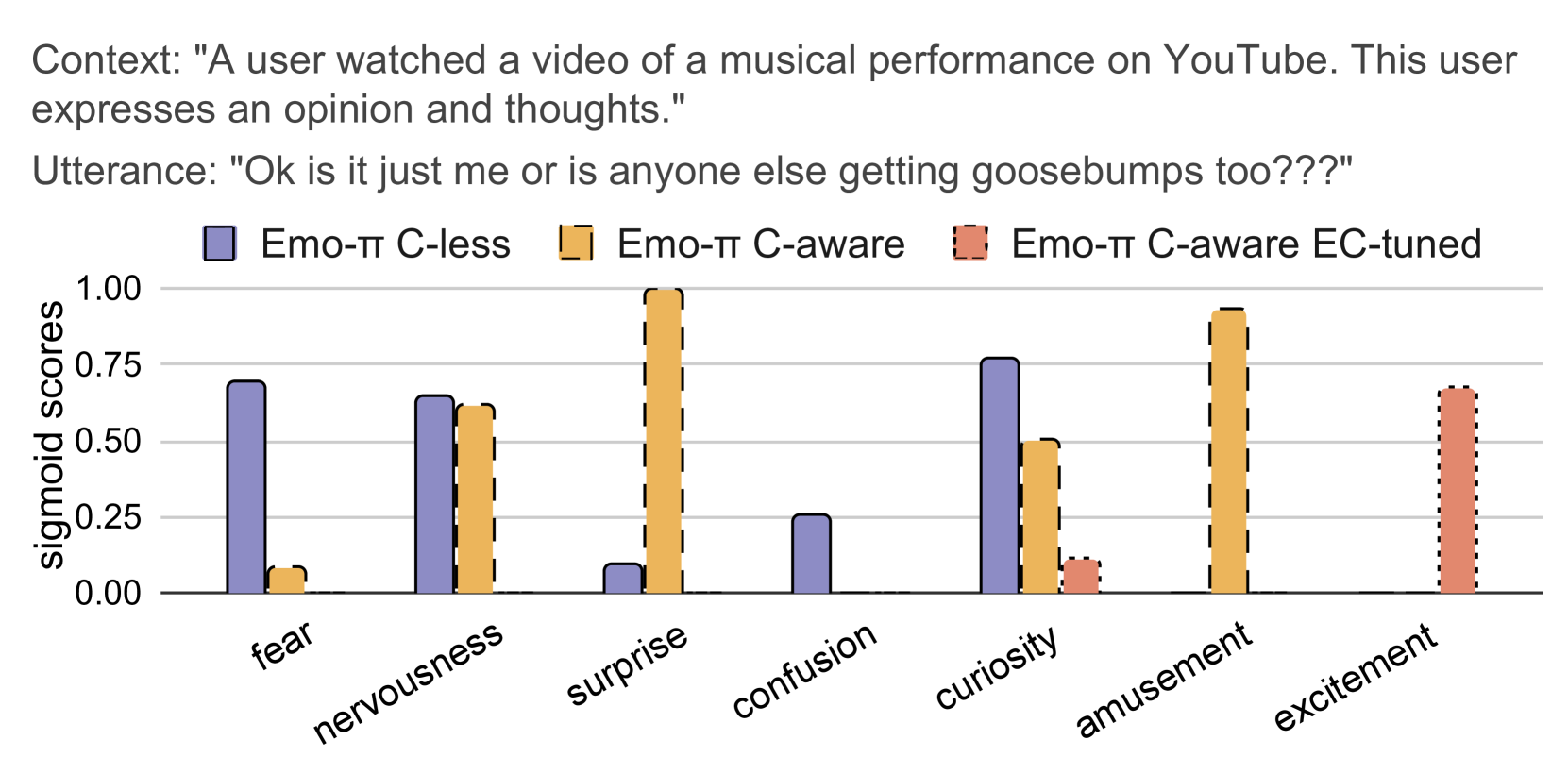
Varied predictions on a YouTube comment from different model variants.
This example shows how different models interpret the same comment:
- The context-less model over-interprets fear
- The context-aware model recognizes multiple emotions including positive ones with some nervousness
- The EmoContext-tuned model provides a more focused interpretation
Dataset Quality and Diversity
The researchers conducted extensive analysis to ensure dataset quality:
- Semantic diversity: Low similarity scores (μ=0.12) between utterances indicate high diversity
- Topic coverage: 300+ distinct topics identified within a single emotion class
- Context personalization: Contexts from the same actor show higher similarity (μ=0.77) than across actors (μ=0.56), showing personalization works
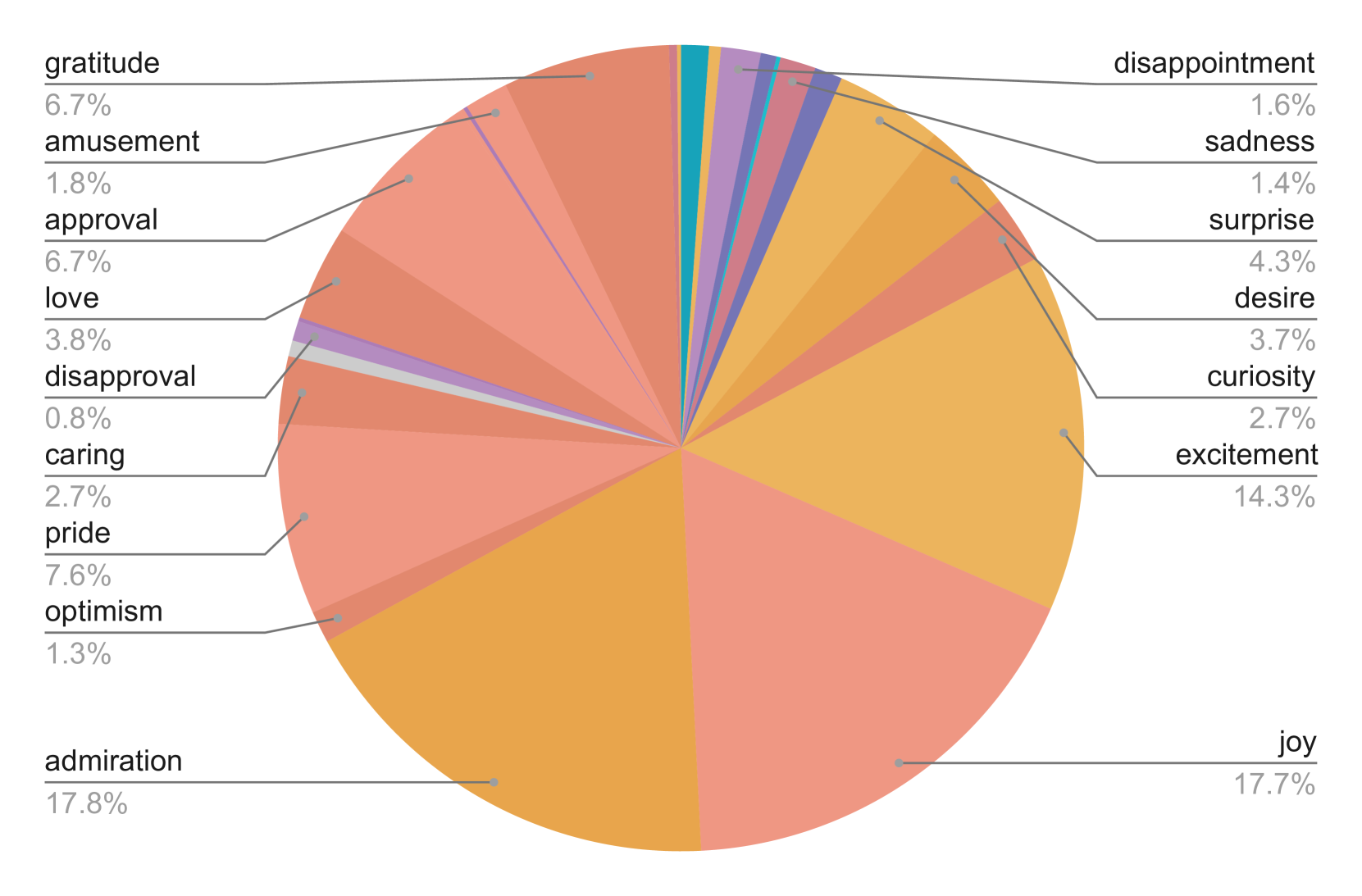
Emotions in the topic of music performances show a distinct distribution.
The emotion distribution within specific topics varies significantly from the global distribution, suggesting the model captures topic-specific emotional nuances rather than just defaulting to common patterns.
A human evaluation confirmed the quality of the dataset, with an inter-annotator agreement (κ=0.365) higher than in prior work (κ=0.293 in GoEmotions), and accuracy of 0.86 on examples where all three annotators agreed.
Limitations and Future Work
The approach has several limitations:
- Using a single LLM (Mistral) for data generation may introduce biases
- Cultural and language implications depending on the data an LLM was pre-trained with
- The training process required significant computing resources (450 GPU hours on H100 GPUs)
Future work will focus on creating multilingual datasets, improving neutral examples, scaling to more emotions, and applying explainability techniques for more focused knowledge access.
Conclusion
Emo Pillars represents a significant advancement in emotion detection by:
- Creating diverse, contextually rich training data through knowledge distillation from LLMs
- Producing lighter, more accurate models that understand both context-less and context-aware scenarios
- Achieving state-of-the-art performance on multiple emotion classification benchmarks
The resulting models are not prone to hallucinations like generative LLMs, require less computing at inference time, and can be fine-tuned for specific domains.
All code, datasets, and models are available open-source, enabling further research and applications in emotion-aware AI systems.
