Build your own local-first GenAI stack with Docker, LangChain, and no GPU.
Why Local LLMs Matter
The rise of large language models (LLMs) has revolutionized how we build applications. But deploying them locally? That’s still a pain for most developers. Between model formats, dependency hell, hardware constraints, and weird CLI tools, running even a small LLM on your laptop can feel like navigating a minefield.
Docker Model Runner changes that. It brings the power of container-native development to local AI workflows so you can focus on building, not battling toolchains.
The Developer Pain Points:
- Too many formats: GGUF, PyTorch, ONNX, TF...
- Dependency issues and messy build scripts
- Need for GPUs or arcane CUDA configs
- No consistent local APIs for experimentation
Docker Model Runner solves these by:
- Standardizing model access via Docker images
- Running fast with llama.cpp under the hood
- Providing OpenAI-compatible APIs out of the box
- Integrating directly with Docker Desktop
🐳 What Is Docker Model Runner?
It’s a lightweight local model runtime integrated with Docker Desktop. It allows you to run quantized models (GGUF format) locally, via a familiar CLI and an OpenAI-compatible API. It’s powered by llama.cpp and designed to be:
- Developer-friendly: Pull and run models in seconds
- Offline-first: Perfect for privacy and edge use cases
- Composable: Works with LangChain, LlamaIndex, etc.
Key Features:
- OpenAI-style API on
localhost:11434 - GPU-free: works even on MacBooks with Apple Silicon
- Easily swap between models with CLI
- Integrated with Docker Desktop
Getting Started in 5 Minutes
1. Enable Model Runner (Docker Desktop)
docker desktop enable model-runner
2. Pull Your First Model
docker model pull ai/smollm2:360M-Q4_K_M
3. Run a Model with a Prompt
docker model run ai/smollm2:360M-Q4_K_M "Explain the Doppler effect like I’m five."
4. Use the API (OpenAI-compatible)
curl http://localhost:11434/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "smollm2", "prompt": "Hello, who are you?", "max_tokens": 100}'
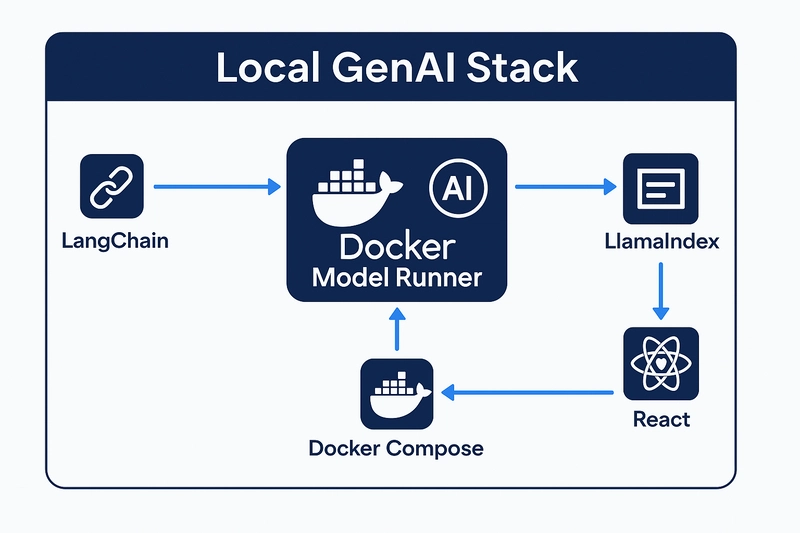
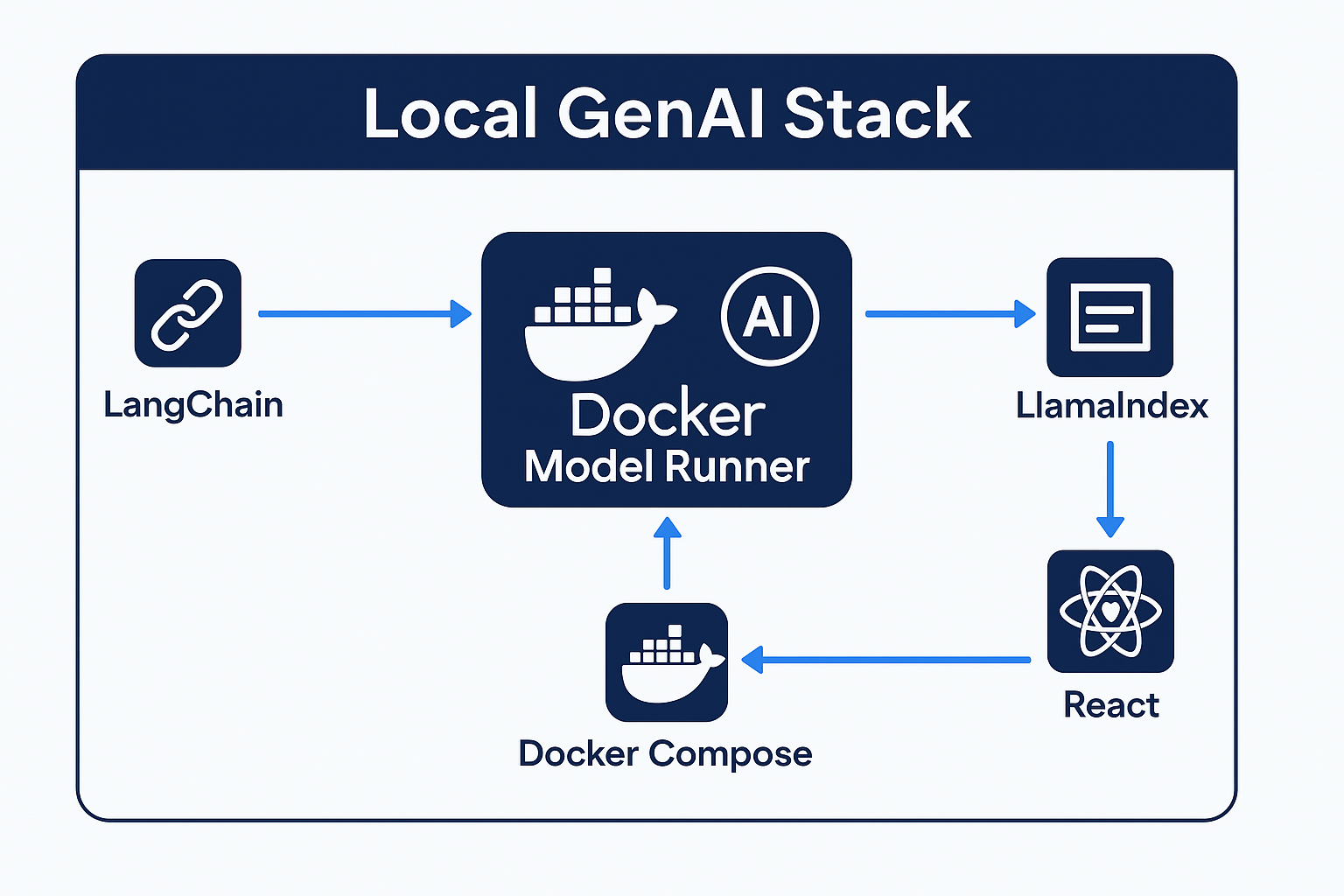
⚙️ Building Your Local GenAI Stack
Here's a simple architecture using Docker Model Runner as your inference backend:
- LangChain: For prompt templating and chaining
- Docker Model Runner: Runs the actual LLMs locally
- LlamaIndex: For document indexing and retrieval (RAG)
- React Frontend: Clean chat UI to interface with the model
- Docker Compose: One command to run them all
docker-compose.yml Example (coming in GitHub repo):
services:
model-runner:
image: ai/smollm2:360M-Q4_K_M
ports:
- "11434:11434"
frontend:
build: ./frontend
ports:
- "3000:3000"
environment:
- API_URL=http://localhost:11434Features:
- Works offline
- Model hot-swapping via env vars
- Fully containerized
💡 Bonus: Add a Frontend Chat UI
Use any frontend framework (React/Next.js/Vue) to build a chat interface that talks to your local model via REST API.
Simple example fetch:
fetch("http://localhost:11434/v1/completions", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ prompt: "What is Docker?", model: "smollm2" })
});This gives you a complete, local-first LLM experience without GPUs or cloud APIs.
🚀 Advanced Use Cases
- RAG pipelines: Combine PDFs + local vector search + Model Runner
- Multiple models: Run phi2, mistral, and more in separate services
- Model comparison: Build A/B testing interfaces using Compose
- Whisper.cpp integration: Speech-to-text container add-ons (coming soon)
- Edge AI setups: Deploy on airgapped systems or dev boards
The Vision: Where This Is Headed
Docker Model Runner could evolve into a full ecosystem:
- ModelHub: Searchable, taggable model registry
- Compose-native GenAI templates
- Whisper + LLM hybrid runners
- Dashboard for monitoring model performance
- VSCode extensions for prompt engineering + test
As a developer, I see this as a huge opportunity to lower the barrier for AI experimentation and help bring container-native AI to everyone.
