This is a Plain English Papers summary of a research paper called FUSION: Deep Vision-Language Integration Outperforms with Fewer Tokens. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Introduction: The Vision-Language Integration Challenge
Human visual perception doesn't work like a camera passively capturing reality. It's an active, interpretative process shaped by cognitive factors such as language and environmental context. Research has demonstrated that hearing an object's name before searching for it significantly improves both speed and accuracy of detection, highlighting the deep integration between vision and language in human cognition.
Despite this fundamental relationship, current multimodal large language models (MLLMs) often fail to capture vision-language interactions effectively. Traditional approaches process visual information through isolated vision encoders, treating visual features as static information and only fusing them with language at the later LLM decoding stage. This decoupled method results in limited useful information available for textual interaction.
Recent advances have attempted to enhance visual comprehension through techniques like dynamic resolution encoding or multiple vision encoders. However, these improvements focus primarily on enhancing the visual encoding itself, overlooking the deeper, bidirectional integration necessary for effective vision-language fusion.
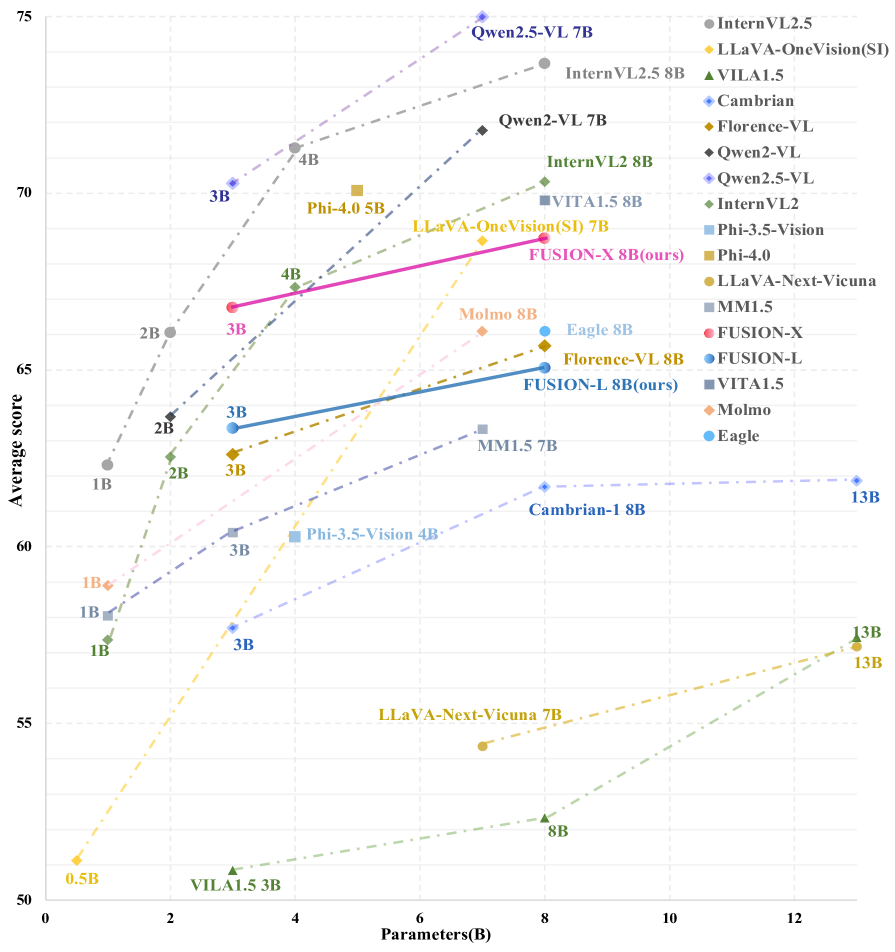
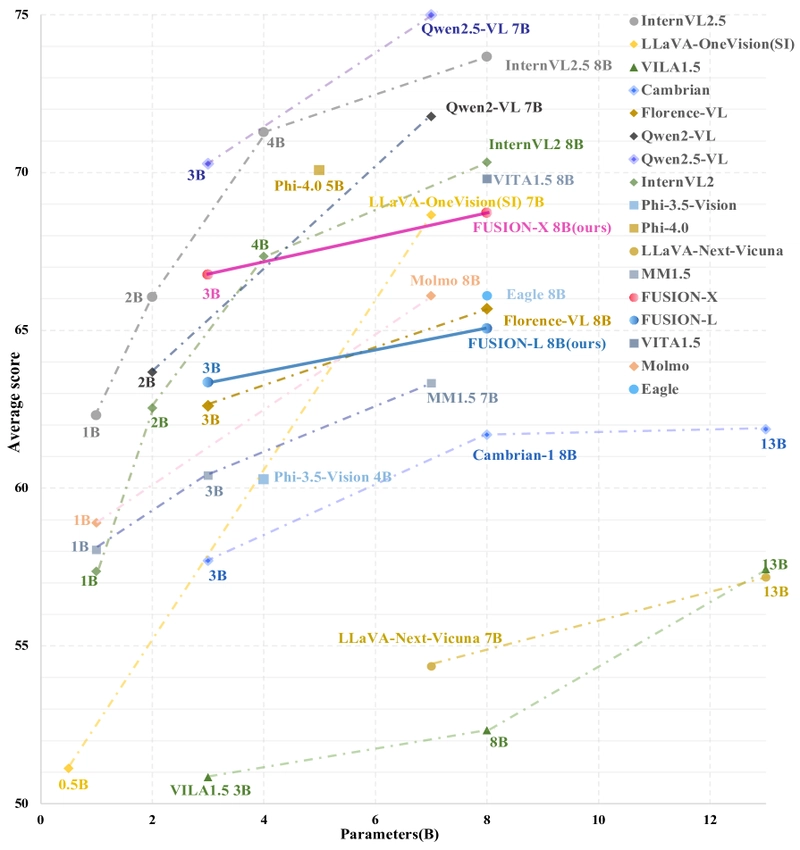
Performance comparison of FUSION with leading MLLM models across benchmark dimensions, showing superior results with fewer vision tokens.
FUSION addresses this challenge by achieving deep, adaptive, and dynamic interaction between vision and language throughout the entire multimodal processing pipeline. Unlike previous approaches that treat modalities separately, FUSION enables consistent integration of textual guidance throughout the visual encoding phase, applies supervised guidance in modality space mapping, and dynamically aggregates vision features based on textual context during decoding.
Background: Current Approaches to Multimodal Learning
Multimodal Large Language Models (MLLMs) are designed to process and integrate information from multiple modalities, combining visual and textual data. These models typically consist of three main components: a vision encoder, a projection module, and a large language model. Images are divided into patches and processed through vision encoders to extract visual representations, which are then mapped into textual embedding space via a projector before being combined with textual data during decoding.
Recent advances have explored dynamic or arbitrary resolution techniques, significantly enhancing the precision and adaptability of visual encoding. Alternative approaches have employed multiple vision encoders to capture a more comprehensive set of visual features. Despite these innovations, most current methodologies emphasize visual encoding quality but neglect deeper and more interactive vision-language dynamics.
Several studies have investigated improved methods for multimodal integration at various stages. Some integrate linguistic guidance by embedding textual queries within projection modules, facilitating language-driven visual feature projection. Others enhance modality alignment by incorporating contrastive loss in the projector module to better associate visual features with entity representations. A fundamental challenge remains: the inherent difference between visual and textual feature spaces makes direct feature alignment difficult, often leading to inconsistencies in multimodal representations.
High-quality instruction tuning data is crucial for the training and generalization capabilities of MLLMs. Existing approaches have constructed training recipes with visual question answering benchmarks or leveraged GPT-4V to generate QA pairs from images. These datasets enhance multimodal understanding but remain predominantly vision-centered, where QA pairs are constructed primarily based on image content, limiting their capacity to support complex tasks across diverse domains.
FUSION Architecture: Deep Cross-Modal Integration
Text-Guided Unified Vision Encoding
FUSION incorporates textual information directly into the vision encoder, refining high-level visual features while preserving the integrity of low-level visual information. Given an image and textual questions, the model first extracts visual embeddings and textual embeddings, then maps the textual representation into vision feature space.
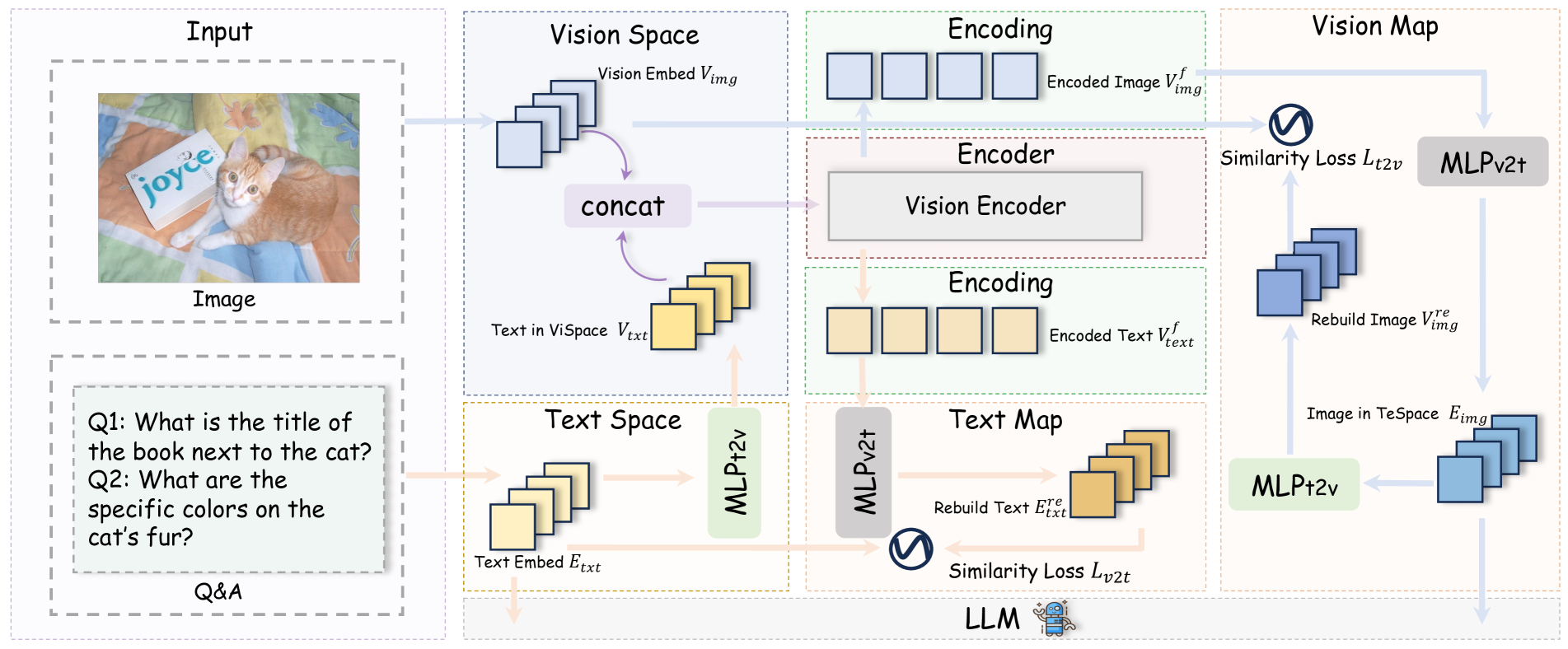
Illustration of Text-Guided Unified Vision Encoding and Dual-Supervised Semantic Mapping Loss, showing the joint processing of visual and textual information.
These mapped textual embeddings and visual embeddings are jointly processed through encoding layers, enabling mutual refinement of multimodal features. To ensure balanced interaction, textual influence is restricted at lower layers by masking textual-to-visual attention in the first half of the encoder. After encoding, visual and textual embeddings are aggregated separately into early and late-stage representations to capture both coarse and fine-grained features.
This integration strategy allows the model to construct rich, question-aware visual representations. High-level features benefit from direct textual guidance, while low-level visual features maintain their integrity. The result is a comprehensive representation that captures the multifaceted nature of visual content while being semantically aligned with textual queries.
Context-Aware Recursive Alignment Decoding
Unlike conventional approaches that position vision tokens solely at the beginning of the input sequence, FUSION introduces additional context-aware latent tokens dedicated to each question. These latent tokens recursively refine visual-textual alignment based on the evolving textual context, ensuring question-level, fine-grained multimodal interaction.
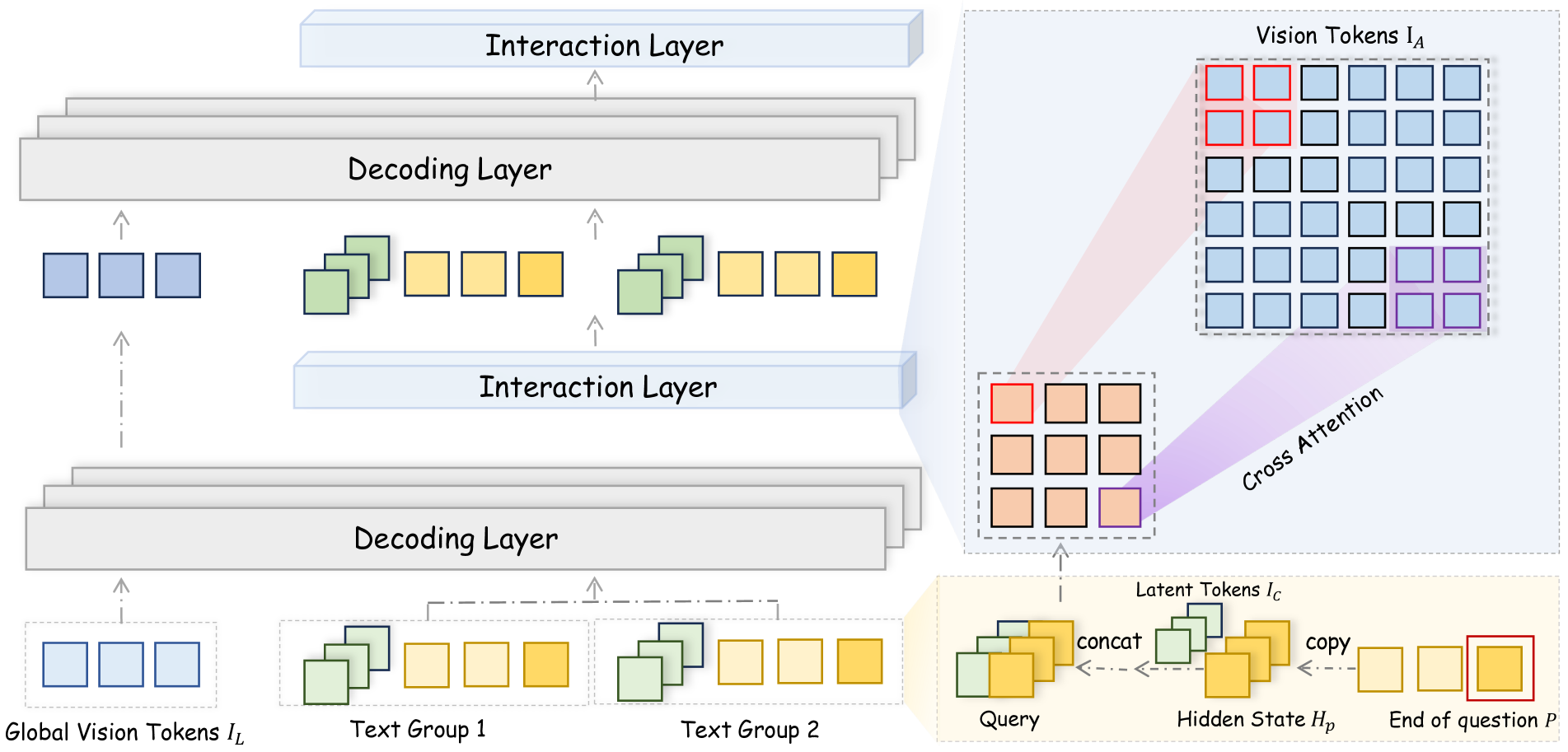
Illustration of Context-Aware Recursive Alignment Decoding with question tokens and latent tokens interacting through additional layers.
To enhance computational efficiency, FUSION employs a localized windowed attention mechanism. The model defines a grid of latent tokens and uses a predefined window size to limit attention operations within manageable regions. To minimize biases from text-guided encoding and maintain the efficacy of window attention, an auxiliary visual representation is constructed by partitioning the original image into sub-images, encoding each without textual conditioning, and concatenating them.
During decoding, for each textual question, the model determines the position corresponding to the question's end within the token sequence. The hidden state representation at this position, which aggregates context information, is extracted and concatenated with each latent token to form context-aware query representations. Each latent token is then updated through localized attention using these queries.
This recursive, context-aware mechanism enables the model to dynamically adapt its visual attention based on the specific textual context, resulting in more precise and relevant multimodal alignment throughout the decoding process.
Dual-Supervised Semantic Mapping Loss
To better guide feature mapping between visual and textual modalities, FUSION introduces a Dual-Supervised Semantic Mapping Loss based on two complementary transformations: vision-to-text and text-to-vision. This bidirectional approach ensures semantic consistency across modalities.
For vision-to-text transformation, the model ensures that mapped visual features closely align with the LLM's feature space. After textual tokens are processed by the vision encoder in the visual feature space, they should be reconstructable to match the original LLM-based textual representation. This alignment is quantified through cosine similarity-based loss between the reconstructed and original features.
Similarly, for text-to-vision transformation, an optimal mapping should transform textual embedding into a rebuilt image representation that closely resembles the vision feature in the visual space. Again, cosine similarity loss is used to assess the quality of this transformation.
This dual-supervised approach creates a consistent, bidirectional bridge between modalities, addressing the fundamental challenge of embedding misalignment and enabling more effective cross-modal integration.
Synthetic Data Creation: Language-Driven QA Dataset
FUSION introduces a novel language-driven approach to constructing QA datasets, fundamentally shifting the traditional emphasis from visual content to the richness and diversity of textual information. This framework prioritizes detailed textual descriptions, making text the central element guiding both image generation and QA pair creation.

Overview of the Text-Centered QA Dataset framework, where textual richness drives both image generation and QA pair construction.
The process begins with selecting high-quality captions from an extensive caption pool. These initial captions are enriched with LLMs, producing detailed and nuanced textual descriptions that capture various visual and contextual attributes. These enriched descriptions serve as prompts for diffusion models, which generate images closely aligned with the provided textual context.
Simultaneously, the enriched descriptions are used as input content for LLMs to construct diverse QA pairs, ensuring broad coverage across multiple-choice questions, multi-turn dialogues, and reasoning-based tasks. This approach distinguishes itself from traditional visual-first methods by directly leveraging comprehensive textual data to enhance the model's understanding of visual contexts.
To address inherent challenges like ambiguity and inconsistencies, FUSION implements a rigorous, multi-stage filtering process. This language-driven framework offers a scalable, adaptable method for synthesizing diverse and high-quality QA datasets, highlighting the essential role of textual richness in enhancing model comprehension.
Experimental Results: Performance Across Benchmarks
FUSION utilizes strong language models (Phi-3.5-mini-instruct and LLaMA3.1-8B-instruct) combined with advanced vision encoders (SigLIP-SO400M-Patch14-384 and SigLIP2-Giant-OPT-Patch16-384). The projector components are implemented as two-layer MLPs.
Training follows a three-stage framework:
- Foundational Semantic Alignment: Pre-training the vision encoder using extensive image-caption datasets to establish precise semantic alignment
- Contextual Multimodal Fusion: Incorporating various QA data along with image-caption pairs to enhance adaptability across scenarios
- Visual Instruction Tuning: Exposing the model to diverse visual tasks for downstream question answering

Visualization of modality alignment and integration at pixel, space, and question levels, showing consistent cross-modal alignment throughout processing.
Performance results across 22 benchmarks demonstrate FUSION's effectiveness. The model variants include FUSION (using SigLIP-SO400M-Patch14-384), FUSION-X (using SigLIP2-Giant-OPT-Patch16-384), and FUSION-L (FUSION-X with reduced tokens through interpolation).
| Synth Data | Stage 1 | Stage 1.5 | Stage 2 | MMBEN | MMBCN | VizWiz | POPE | MM-Vet | MMEP | MMEC | SeedImage | LLaVAW | CVBench | MMVP | AI2D | MMMU | SQA | TextVQA | ChartQA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| baseline | 77.2 | 71.4 | 66.6 | 88.1 | 57.4 | 1544.9 | 379.4 | 73.4 | 84.4 | 74.8 | 74.6 | 77.2 | 42.5 | 84.6 | 73.4 | 74.8 | |||
| +1.5 M | ✓ | 77.5 | 71.6 | 65.7 | 88.2 | 58.2 | 1567.6 | 386.1 | 73.6 | 83.5 | 74.6 | 74.5 | 77.4 | 42.6 | 85.8 | 73.7 | 75.2 | ||
| +1.0 M | ✓ | ✓ | 78.0 | 72.1 | 66.2 | 88.9 | 59.4 | 1567.2 | 408.5 | 74.1 | 81.9 | 86.3 | 74.2 | 78.8 | 43.9 | 85.7 | 73.5 | 74.9 | |
| +0.9 M | ✓ | ✓ | ✓ | 80.3 | 74.8 | 66.1 | 88.7 | 60.3 | 1582.1 | 440.0 | 75.3 | 85.2 | 78.3 | 78.1 | 79.2 | 44.2 | 87.3 | 73.9 | 75.8 |
Impact of synthetic data on performance. Gradual incorporation of generated data into different stages shows improvement in performance across various tasks.
Notably, FUSION-X 3B surpasses Cambrian-1 8B and Florence-VL 8B on most benchmarks with only 630 vision tokens. Even when limited to 300 vision tokens, FUSION-L 3B continues to outperform Cambrian-1 8B, highlighting the efficiency of the approach.
Ablation Studies: Component Contributions
To validate the effectiveness of each component, FUSION was compared to LLaVA-NeXT with identical datasets. Results indicate that each component significantly contributes to overall performance enhancement. Text-Guided Unified Vision Encoding and Dual-Supervised Semantic Mapping notably improve general multimodal tasks, while Context-Aware Recursive Alignment Decoding substantially boosts OCR accuracy and reduces hallucinations.
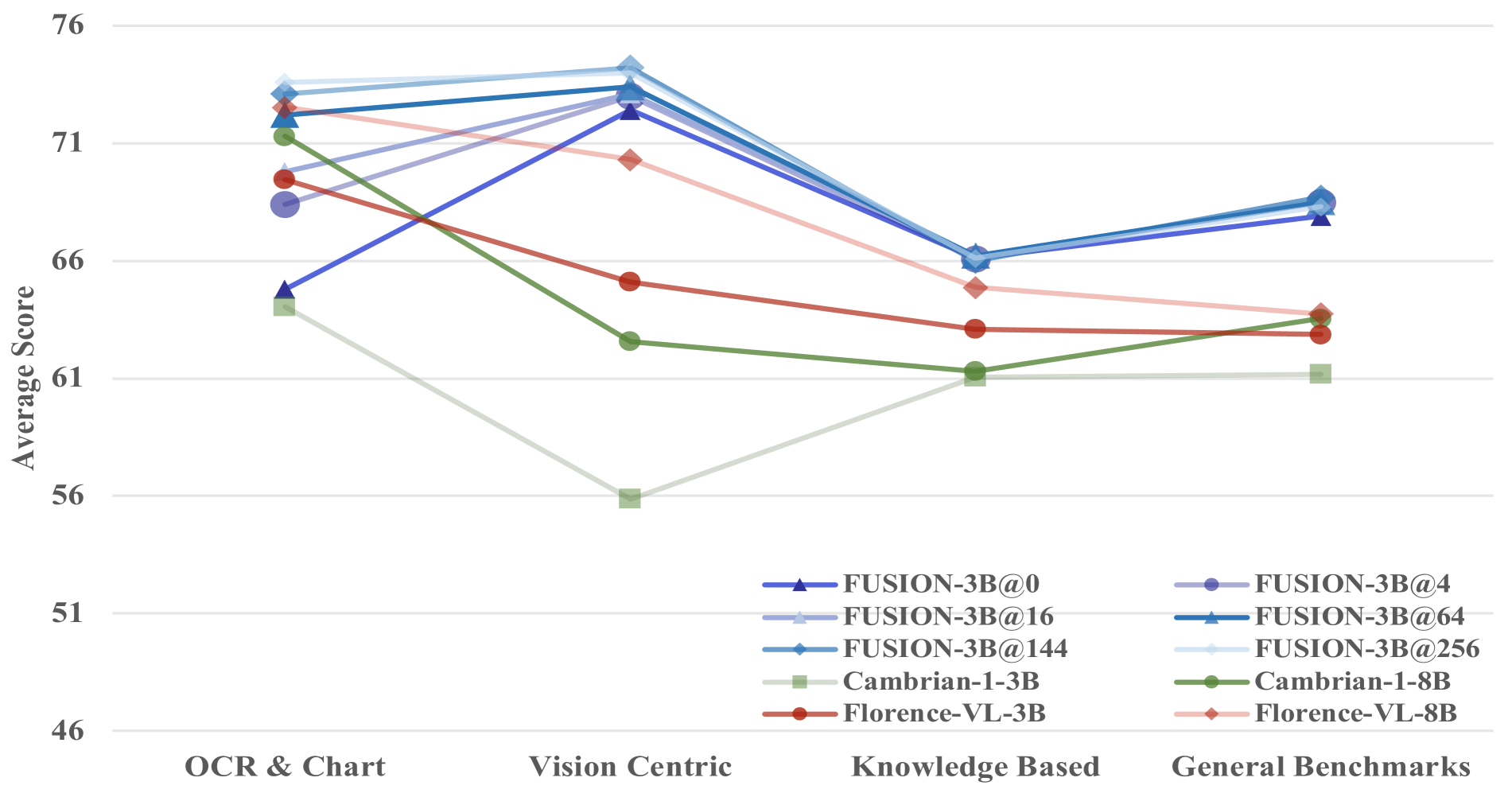
Model performance under varying numbers of latent vision tokens, showing significant improvements with minimal token increases.
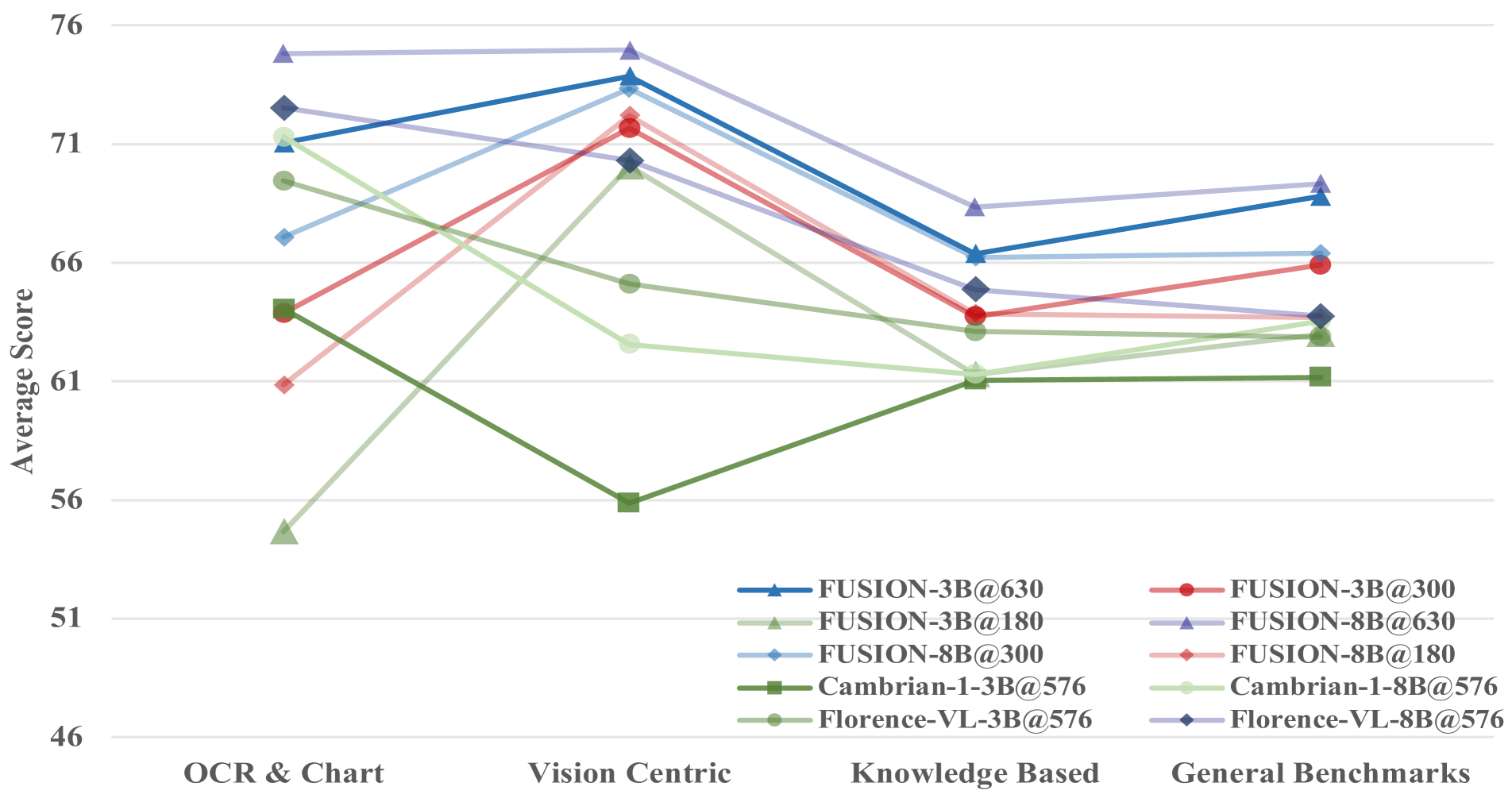
Model performance under varying numbers of global vision tokens, demonstrating robustness even with reduced token counts.
The impact of latent tokens on performance was also examined. Even a small increase in latent token count leads to substantial improvements, particularly in OCR & Chart and Vision-Centric tasks. This indicates that latent tokens play a crucial role in boosting multimodal understanding with minimal resource overhead.
Synthetic data significantly facilitates modality alignment and enhances performance in targeted downstream tasks. Incorporating synthetic data during Stage 2 training markedly improves performance on tasks such as MMBench, SQA, CVBench, and MMVP.
To showcase the effectiveness of comprehensive modality alignment, the model's resilience was tested by progressively reducing the number of image tokens through interpolation. Results demonstrate that FUSION maintains superior performance compared to Florence-VL even when the token count is reduced to 300, underscoring the efficiency and adaptability of the modality fusion approach.
Conclusion: Efficient Multimodal Learning Through Integration
FUSION rethinks how vision and language should be integrated in multimodal models. Rather than treating vision as static input fused only at the decoding stage, this approach enables interaction at every phase—starting from vision encoding guided by text, to decoding that recursively aligns with visual features.
To address semantic mismatch between modalities, FUSION utilizes a dual-supervised loss that enforces consistency through bidirectional reconstruction. Beyond architecture improvements, the model introduces a scalable data generation strategy that synthesizes diverse and informative QA pairs, providing strong supervision for vision-language alignment.
Experiments demonstrate that FUSION achieves superior performance with far fewer vision tokens than existing models, highlighting both its efficiency and accuracy. Even with reduced input, the model matches or surpasses larger baselines, proving the value of deeper modality interaction over simply improving visual encoding quality.
This approach represents a significant step toward more cognitively inspired multimodal learning, where modalities actively inform and enhance each other rather than remaining as separate processing streams with limited interaction.
