This is a Plain English Papers summary of a research paper called GAN Voice Conversion Breakthrough: Collective Learning Beats the Quality Gap. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Challenge of Natural Voice Conversion in GAN-Based Systems
Voice Conversion (VC) aims to transform a source speaker's vocal identity to match a target speaker while preserving the original linguistic content. Over the years, VC technology has evolved significantly, moving from early Gaussian Mixture Models and Phonetic Posteriorgrams to more sophisticated Generative Adversarial Network (GAN) approaches. Despite these advancements, state-of-the-art GAN-based VC models still exhibit a substantial disparity in naturalness between real and synthetic speech.
The CLOT-GAN-VC model addresses this challenge through a novel collective learning mechanism combined with Optimal Transport theory. While conventional GAN models typically employ a single generator-discriminator architecture, CLOT-GAN-VC integrates multiple discriminators—Deep Convolutional Neural Network (DCNN), Vision Transformer (ViT), and conformer—within a single framework. This approach draws inspiration from multi-modal adversarial training for zero-shot voice conversion, where diverse model architectures collaborate to capture different aspects of speech characteristics.
The key innovation lies in how these discriminators work together to comprehend the formant distribution of mel-spectrograms through a collective learning mechanism, while the Optimal Transport loss precisely bridges the gap between source and target data distributions.
Evolution of GAN-Based Voice Conversion Systems
GAN-based VC has seen remarkable progress through various model iterations. Early models like CycleGAN laid the groundwork, followed by improvements in MaskCycleGAN-VC, which leveraged the concept of filling frames to enhance performance. More recent models such as FLSGAN-VC introduced frame-based processing with multiple generators, while FID-RPRGAN-VC incorporated Frechet Inception Distance-based loss functions with dual DCNN discriminators.
Despite these advancements, a notable quality gap remains between real and synthesized speech. Most current models rely on a single generator-discriminator approach, which limits their ability to fully capture the complexity of speech characteristics. This limitation has prompted exploration into more efficient distribution modeling strategies using multi-tier discriminator networks, where different discriminator architectures can collaboratively learn various aspects of the target distribution.
The literature review reveals a promising opportunity to enhance voice conversion through single-generator, multi-discriminator learning strategies that incorporate diverse deep learning architectures, enabling more precise modeling of the target speaker's characteristics.
CLOT-GAN-VC: Architecture and Collective Learning Mechanism
CLOT-GAN-VC introduces a novel framework that employs a single generator with multiple discriminators working in concert. The model architecture builds upon the MaskCycleGAN-VC framework, adding significant innovations in how discriminators collaborate.
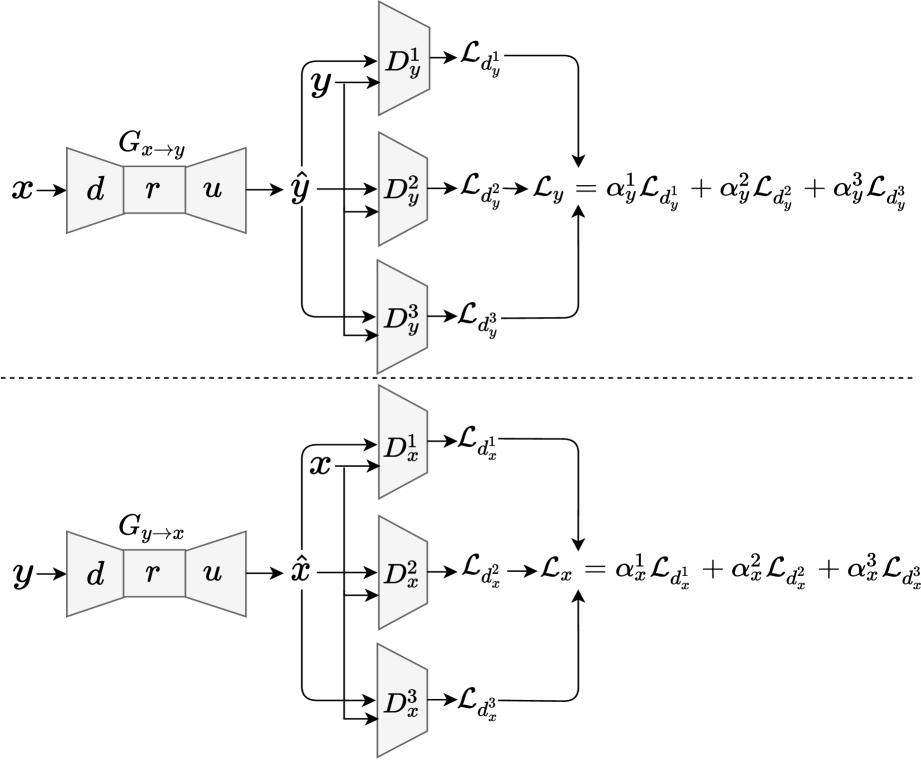
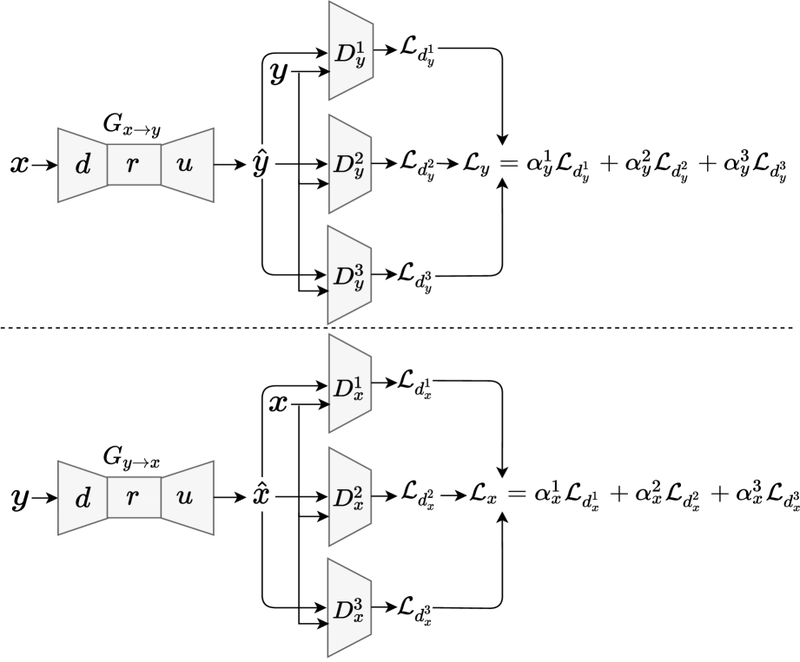
Figure 1: Overview of the proposed CLOT-GAN-VC model, showing the generator with downsample, residual, and upsample blocks, connected to multiple discriminators.
As shown in Figure 1, the generator processes source mel-spectrograms and transforms them into the target speaker's voice characteristics. The generated outputs are then evaluated by three different discriminators: DCNN, Vision Transformer (ViT), and conformer. Each discriminator architecture brings unique capabilities:
- DCNN: Extracts spatial hierarchies of features from mel-spectrograms
- Vision Transformer: Captures local feature distribution through attention mechanisms
- Conformer: Combines convolution and transformer capabilities for enhanced feature extraction
Unlike traditional ensemble approaches where models vote or are simply averaged, CLOT-GAN-VC implements a true collective learning mechanism inspired by generative approaches for counter-narratives. Each discriminator updates its weights based on its evaluation of feature similarity between generated and original mel-spectrograms. This weighted averaging provides comprehensive, multidimensional feedback to the generator.
The incorporation of Optimal Transport (OT) loss, implemented through the Sinkhorn algorithm, measures the minimal work needed to transform one probability distribution into another. This approach offers advantages over traditional Kullback-Leibler and Jensen-Shannon divergence measures by considering the entire distribution rather than point-by-point differences.
Experimental Setup: Datasets, Training, and Evaluation Methods
The performance evaluation of CLOT-GAN-VC was conducted using three speech datasets:
- VCC 2018 with speakers VCC2-TM1/SM3/TF1/SF3
- VCTK with speakers P-229F2/304M2/306F1/334M1
- CMU Arctic with speakers cmu-us-bld/-rms/-clb/-slt-Arctic
To test the model's adaptability for low-resource scenarios, relatively small datasets were used: 81 training samples, 35 validation samples, and 25 evaluation samples. The model was trained using the Adam optimizer with a learning rate of 1×10^-4 for 1000 epochs, using a mini-batch size of 1 and input mel-spectrograms of size 2×80×64.
For speech reconstruction, a pre-trained MelGAN vocoder was employed. The experiments were conducted on a Dell Precision 7820 workstation with an Intel Xeon Gold 5215 processor and Nvidia Quadro RTX5000 graphics, using PyTorch 1.1.2 and NumPy 1.19.5.
The evaluation methodology included both objective metrics—Mel Cepstral Distortion (MCD) and Mel Spectral Distortion (MSD)—and subjective assessment through Mean Opinion Score (MOS). This comprehensive evaluation approach aligns with methods used in improving GANs for coherency in agnostic sound generation, ensuring a robust assessment of both technical accuracy and perceived naturalness.
Results and Discussion
Objective Metrics Demonstrate Superior Performance
The CLOT-GAN-VC model outperformed existing voice conversion approaches in objective evaluations across multiple datasets, as demonstrated in the following table:
| Dataset | Models | M-M | F-F | M-F | F-M |
|---|---|---|---|---|---|
| VCC 2018 | MCD ( $\downarrow$ ) | ||||
| CLOT-GAN-VC | 6.67 | 6.54 | 7.56 | 6.69 | |
| MaskCycleGAN-VC | 6.77 | 7.37 | 7.64 | 6.73 | |
| MelGAN-VC | 8.23 | 8.54 | 8.37 | 8.61 | |
| CMU-Arctic | CLOT-GAN-VC | 7.12 | 8.66 | 8.11 | 7.91 |
| MaskCycleGAN-VC | 7.12 | 7.81 | 8.20 | 8.07 | |
| MelGAN-VC | 8.53 | 8.49 | 8.46 | 8.61 | |
| CSTR-VCTK | CLOT-GAN-VC | 4.60 | 7.73 | 4.97 | 5.86 |
| MaskCycleGAN-VC | 4.85 | 7.93 | 5.28 | 5.92 | |
| MelGAN-VC | 4.62 | 9.42 | 6.73 | 5.26 | |
| VCC 2018 | MSD ( $\downarrow$ ) | ||||
| CLOT-GAN-VC | 1.21 | 1.15 | 1.42 | 1.21 | |
| MaskCycleGAN-VC | 1.17 | 1.18 | 1.50 | 1.24 | |
| MelGAN-VC | 1.53 | 1.55 | 1.49 | 1.57 | |
| CMU-Arctic | CLOT-GAN-VC | 1.15 | 1.16 | 1.41 | 1.23 |
| MaskCycleGAN-VC | 1.18 | 1.19 | 1.32 | 1.29 | |
| MelGAN-VC | 1.57 | 1.50 | 1.55 | 1.55 | |
| CSTR-VCTK | CLOT-GAN-VC | 1.40 | 1.63 | 1.37 | 1.60 |
| MaskCycleGAN-VC | 1.38 | 1.62 | 1.48 | 1.68 | |
| MelGAN-VC | 1.66 | 1.63 | 1.88 | 1.72 |
Table I: MCD and MSD values for VCC 2018, CMU-Arctic and CSTR-VCTK datasets, showing performance across male-to-male (M-M), female-to-female (F-F), male-to-female (M-F), and female-to-male (F-M) conversion scenarios. Lower values indicate better performance.
For intra-gender voice conversion (M-M and F-F), CLOT-GAN-VC achieved an average improvement of 1.57% and 12.54% in MCD values compared to MaskCycleGAN-VC and MelGAN-VC, respectively. For inter-gender conversion (M-F and F-M), the improvements were 1.93% and 9.82%.
Similarly, MSD values showed improvements of 0.35% and 18.63% for intra-gender conversion compared to MaskCycleGAN-VC and MelGAN-VC. The proposed model performed particularly well in inter-gender conversion scenarios across all datasets, with the exception of M-F conversion in the CMU-Arctic dataset.

Figure 2: Visual comparison of mel-spectrograms generated by different models for male-to-female voice conversion, with Grad-CAM visualizations highlighting the regions that each discriminator focuses on.
Figure 2 provides a visual comparison of the mel-spectrograms generated by different models. The mel-spectrograms are divided into three frequency regions (marked as 1, 2, and 3). The CLOT-GAN-VC model effectively captures the pitch contour of the target speaker while preserving the formant patterns that represent the speech content of the source speaker. The Grad-CAM visualizations reveal how different discriminators focus on different regions of the mel-spectrogram, demonstrating the complementary nature of the multi-discriminator approach.
An ablation study was conducted to evaluate the contribution of each component of the model:
| Models | M-M | F-F | M-F | F-M |
|---|---|---|---|---|
| MCD $(\downarrow)$ | ||||
| CLOT-GAN-VC | 6.67 | 6.54 | 7.56 | 6.69 |
| CLOT-GAN-VC(1) | 6.97 | 7.42 | 7.78 | 6.93 |
| CLOT-GAN-VC(2) | 7.07 | 6.75 | 7.64 | 7.22 |
| CLOT-GAN-VC(3) | 7.89 | 6.88 | 7.78 | 7.18 |
| MSD $(\downarrow)$ | ||||
| CLOT-GAN-VC | 1.21 | 1.15 | 1.42 | 1.21 |
| CLOT-GAN-VC(1) | 1.21 | 1.18 | 1.50 | 1.44 |
| CLOT-GAN-VC(2) | 1.62 | 1.44 | 1.45 | 1.44 |
| CLOT-GAN-VC(3) | 1.61 | 1.41 | 1.44 | 1.43 |
Table II: Ablation study results on the VCC 2018 dataset, comparing the full CLOT-GAN-VC model with variants lacking specific components: (1) without multiple discriminators, (2) without weighted averaging, and (3) without OT loss.
The ablation study confirms that each component of the CLOT-GAN-VC model contributes to its overall performance. The full model consistently outperforms variants that lack multiple discriminators (replaced by a single PatchGAN discriminator), weighted averaging (replaced by simple averaging), or Optimal Transport loss (replaced by L2 loss). This validates the design principles of the collective learning mechanism based on optimal transport approach.
Human Perception Confirms Enhanced Naturalness
Subjective evaluation through Mean Opinion Score (MOS) testing provides crucial insights into the perceived naturalness of the converted speech:
| Dataset | Models | M-M | F-F | M-F | F-M |
|---|---|---|---|---|---|
| VCC 2018 | CLOT-GAN-VC | 3.57 ± 0.53 | 3.73 ± 0.57 | 2.73 ± 0.21 | 2.84 ± 0.38 |
| MedCycleGAN-VC | 3.47 ± 0.50 | 3.26 ± 0.44 | 2.53 ± 0.19 | 2.68 ± 0.33 | |
| MelGAN-VC | 2.10 ± 0.93 | 2.10 ± 0.99 | 2.21 ± 0.13 | 2.59 ± 0.04 | |
| CMU-Arctic | CLOT-GAN-VC | 3.22 ± .09 | 4.11 ± 0.45 | 3.05 ± 0.05 | 2.88 ± 0.97 |
| MedCycleGAN-VC | 3.16 ± 0.03 | 3.50 ± 0.24 | 2.72 ± 0.01 | 2.61 ± 0.18 | |
| MelGAN-VC | 2.72 ± 0.82 | 2.58 ± 0.83 | 2.38 ± 0.19 | 2.11 ± 0.07 | |
| CSTR-VCTK | CLOT-GAN-VC | 3.63 ± 0.57 | 3.21 ± 0.43 | 3.36 ± 0.38 | 3.10 ± 0.22 |
| MedCycleGAN-VC | 3.52 ± 0.54 | 2.94 ± 0.26 | 3.31 ± 0.45 | 2.94 ± 0.44 | |
| MelGAN-VC | 2.84 ± 0.57 | 2.63 ± 0.83 | 2.05 ± 0.91 | 2.00 ± 0.88 |
Table III: Mean Opinion Score (MOS) results with 95% confidence intervals across all datasets and conversion scenarios. Higher scores indicate better perceived naturalness.
The MOS evaluation, conducted with 17 volunteers, consistently rates CLOT-GAN-VC speech samples higher than those generated by MaskCycleGAN-VC and MelGAN-VC across all datasets and conversion scenarios. The difference is particularly pronounced in female-to-female conversions on the CMU-Arctic dataset, where CLOT-GAN-VC achieved a score of 4.11 compared to 3.50 for MaskCycleGAN-VC and 2.58 for MelGAN-VC.
These subjective results align with the objective metrics, confirming that the collective learning mechanism and optimal transport loss function effectively enhance the naturalness of the converted speech.
Conclusion
The CLOT-GAN-VC model introduces a novel approach to voice conversion that leverages collaborative learning within a GAN framework. By integrating multiple discriminators with diverse deep learning architectures—DCNN, Vision Transformer, and conformer—and incorporating Optimal Transport loss, the model more effectively captures the formant distribution in mel-spectrograms.
Both objective and subjective evaluations confirm that CLOT-GAN-VC outperforms existing voice conversion models. The ablation study further validates the importance of each component in the overall architecture, demonstrating that the collective learning mechanism and Optimal Transport loss function are essential for achieving superior performance.
The success of this approach opens promising avenues for future research, particularly in applying these techniques to voice conversion in low-resource languages. The collective learning principles demonstrated in this work have potential applications beyond voice conversion, potentially benefiting other speech synthesis and transformation tasks.
