Getting Started with Amazon Athena:
Query Your S3 Data with SQL
Amazon Athena makes it incredibly easy to explore and analyze data stored in Amazon S3 using standard SQL queries. Whether you're working with log files, application data, or structured datasets, Athena allows you to treat your S3 files as a database—no ETL or server setup required.
🧠 What Is Amazon Athena?
Amazon Athena is a serverless, interactive query service that lets you analyze data in Amazon S3 using standard SQL. There's no infrastructure to manage, and you only pay for the queries you run.
Athena supports various file formats including:
CSV
JSON
ORC (Optimized Row Columnar)
Apache Avro
Parquet
It’s also optimized for performance through parallelism, making it fast and efficient for large datasets.
💸 How Much Does Athena Cost?
Athena charges you based on the amount of data scanned per query. As of writing, the cost is $5 per TB scanned, so it’s important to optimize your data (e.g., by compressing it or using columnar formats like Parquet or ORC).
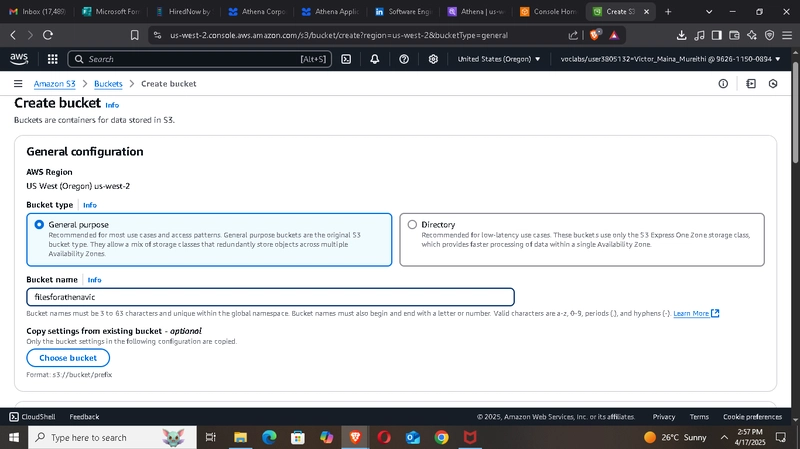
📦 Step 1: Prepare Your S3 Bucket
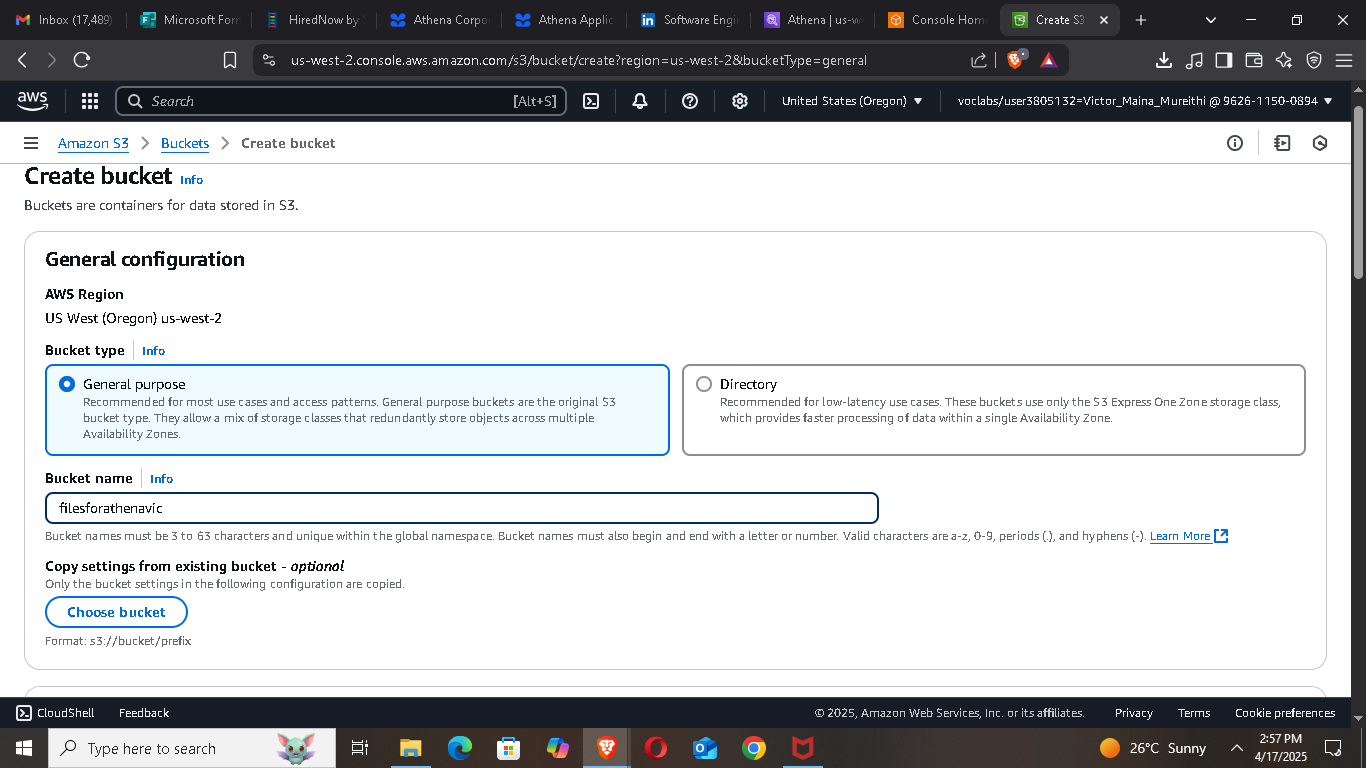
If this is your first time using Athena, you’ll need to set up an S3 bucket to store your data. Here’s how:
Go to the S3 console and create a new bucket.
Make sure you note the AWS region—Athena and the S3 bucket must be in the same region.
Upload your dataset. For this tutorial, we’re using a sample Order data CSV file.
We’ll also create a second S3 bucket to store the results of our Athena queries (this is required by Athena).
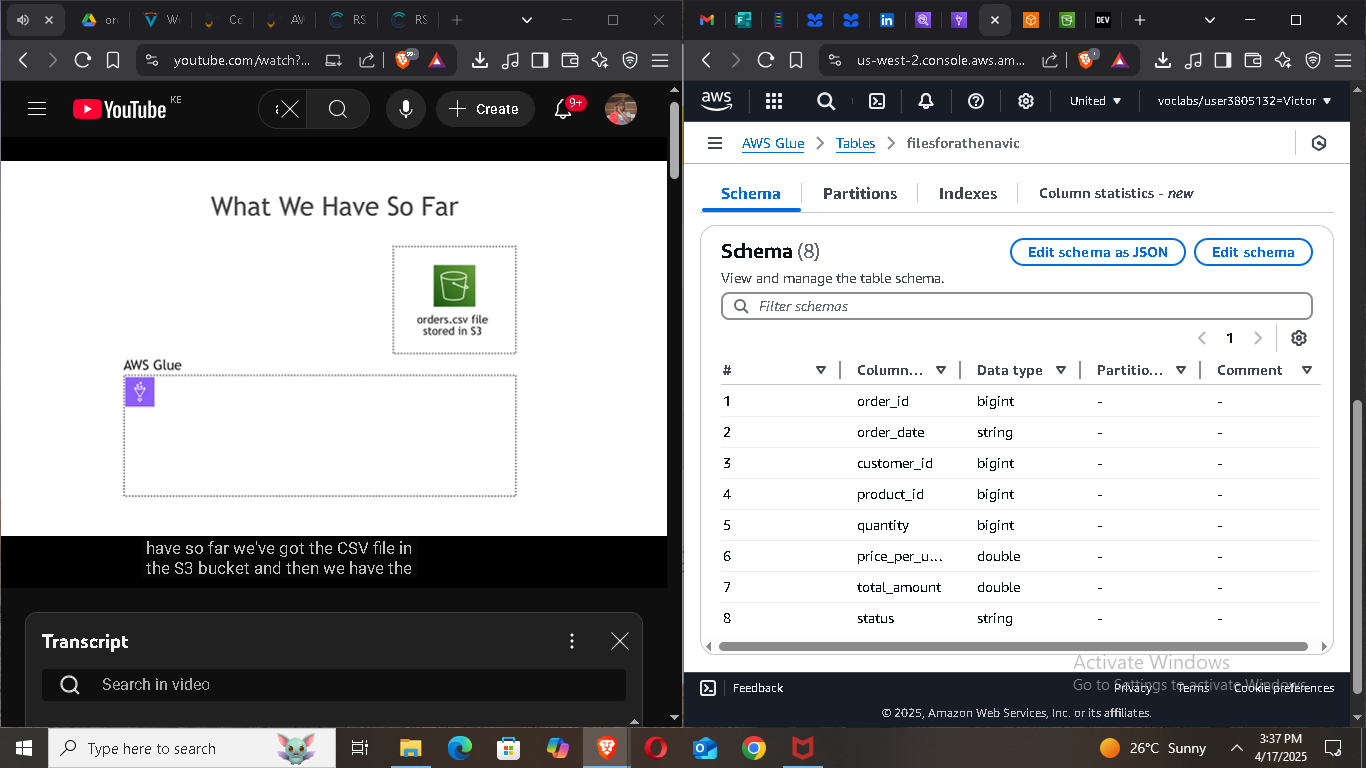
🧰 Step 2: Set Up AWS Glue for Schema Discovery
Athena needs a schema to understand your data. Instead of defining it manually, we’ll use AWS Glue to automatically crawl and catalog our dataset.
Go to the AWS Glue Console.
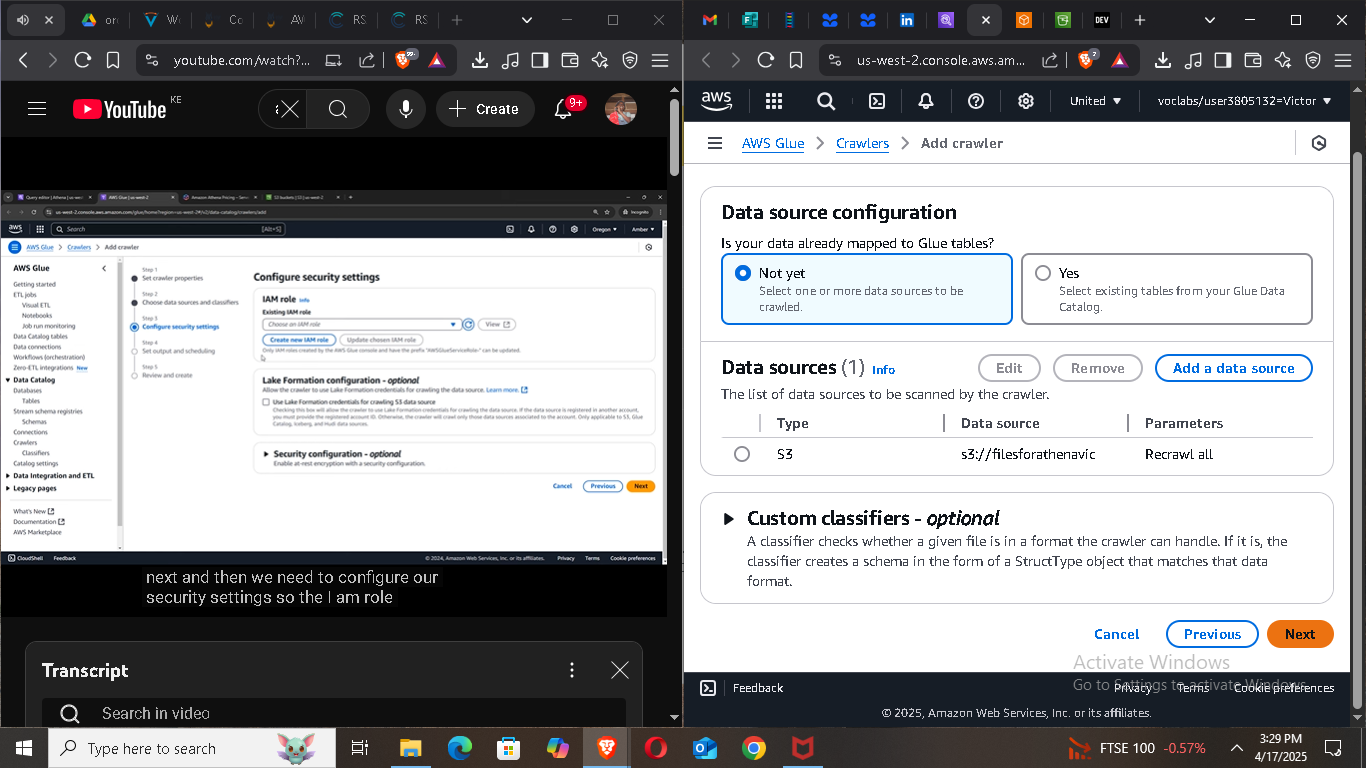
Create a new database (e.g., order_data_db).
Create a crawler:
Set the source as your S3 data bucket.
Choose the database you just created.
Run the crawler to populate the schema.
🔍 Step 3: Query Your Data in Athena
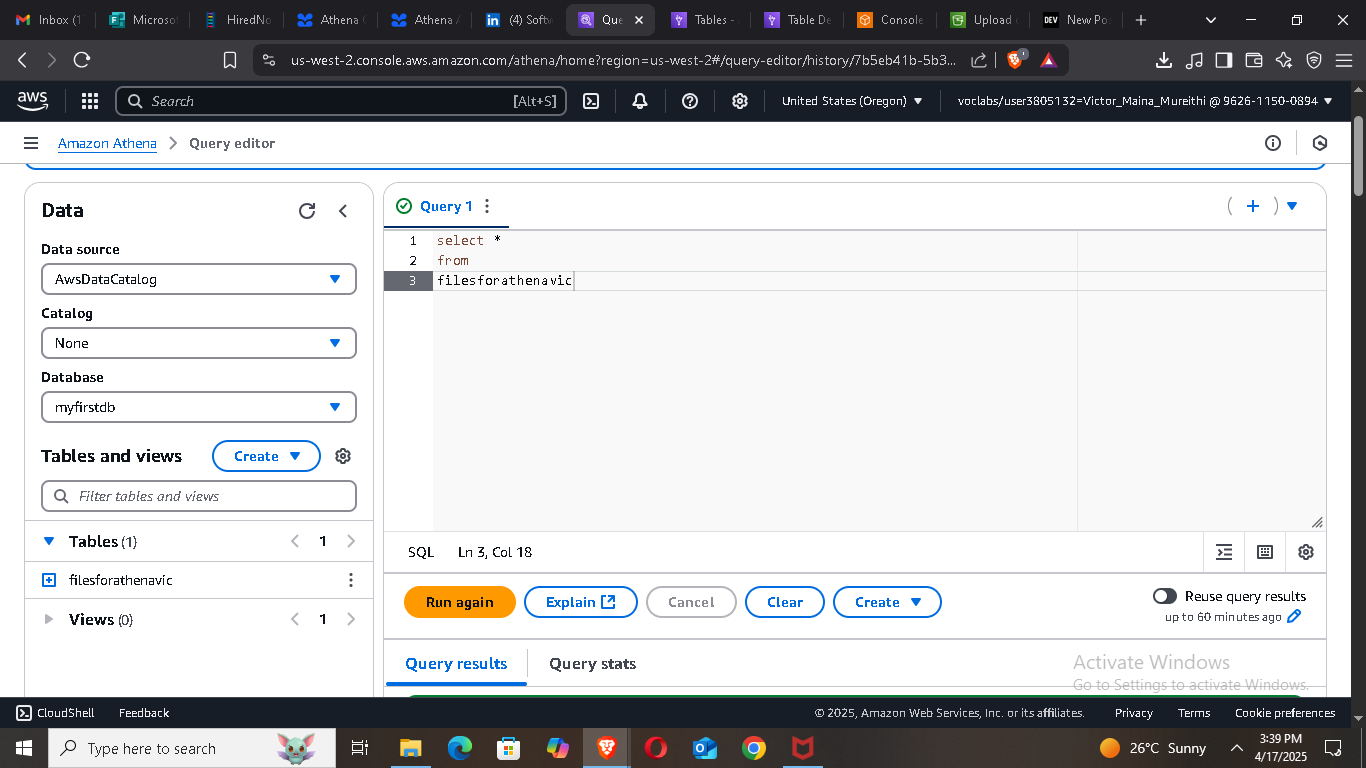
Now that the table is ready, it’s time to query your data:
Open the Athena Query Editor.
Make sure the correct database is selected.
Run a sample SQL query like:
SELECT * FROM orders LIMIT 10;
You’ll see the results right in your browser. Athena also saves them as CSV files in your specified results bucket.
📊 Bonus: Visualize Your Data with Amazon QuickSight
Want to turn your raw queries into dashboards? You can connect Athena to Amazon QuickSight to create dynamic visualizations of your data. This is great for exploring patterns or trends in logs, sales data, and more.
🧹 Step 4: Clean Up Your Resources
Once you're done, be sure to delete any AWS resources to avoid ongoing charges:
Delete the S3 buckets you created (both the data and the results buckets).
Delete the AWS Glue crawler and database.
Remove any saved Athena queries or saved workgroups, if applicable.
Remember, Athena’s billing is based on the volume of data scanned cleanups and query optimization are key to keeping costs low.
✅ Wrapping Up
Amazon Athena is a powerful tool that simplifies querying large datasets stored in S3 using familiar SQL syntax. It’s perfect for analysts, engineers, and data enthusiasts who want fast insights without the overhead of managing infrastructure.
In this tutorial, we walked through setting up S3, using AWS Glue to create a schema, querying with Athena, and finally cleaning up your resources. Now you’re ready to start analyzing your own data!
Would you like me to help turn this into a blog post or Markdown file, or add code blocks/screenshots for each step?
Reason