We recently ran the first-ever Hera developer survey, with great results! The goal of this survey was to inform the roadmap of Hera, so we are thrilled with the 34 responses and the broad range of feedback and insights that we’ve got. This post will summarise and interpret some of the results – look out for the roadmap coming at a later date!
Roles and Use Cases
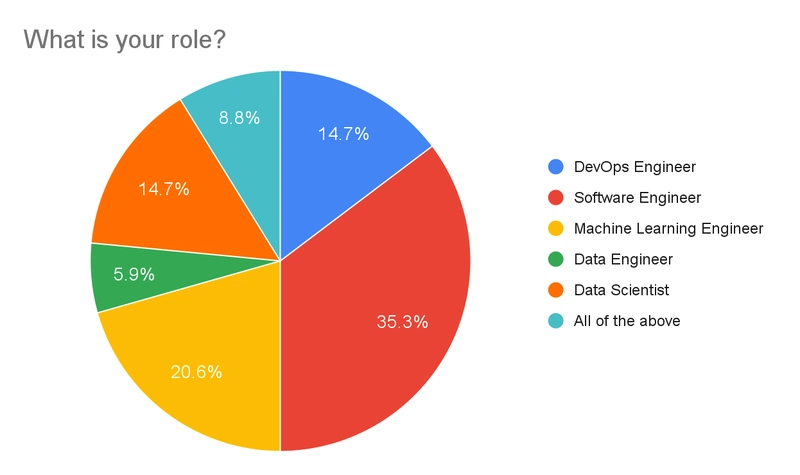
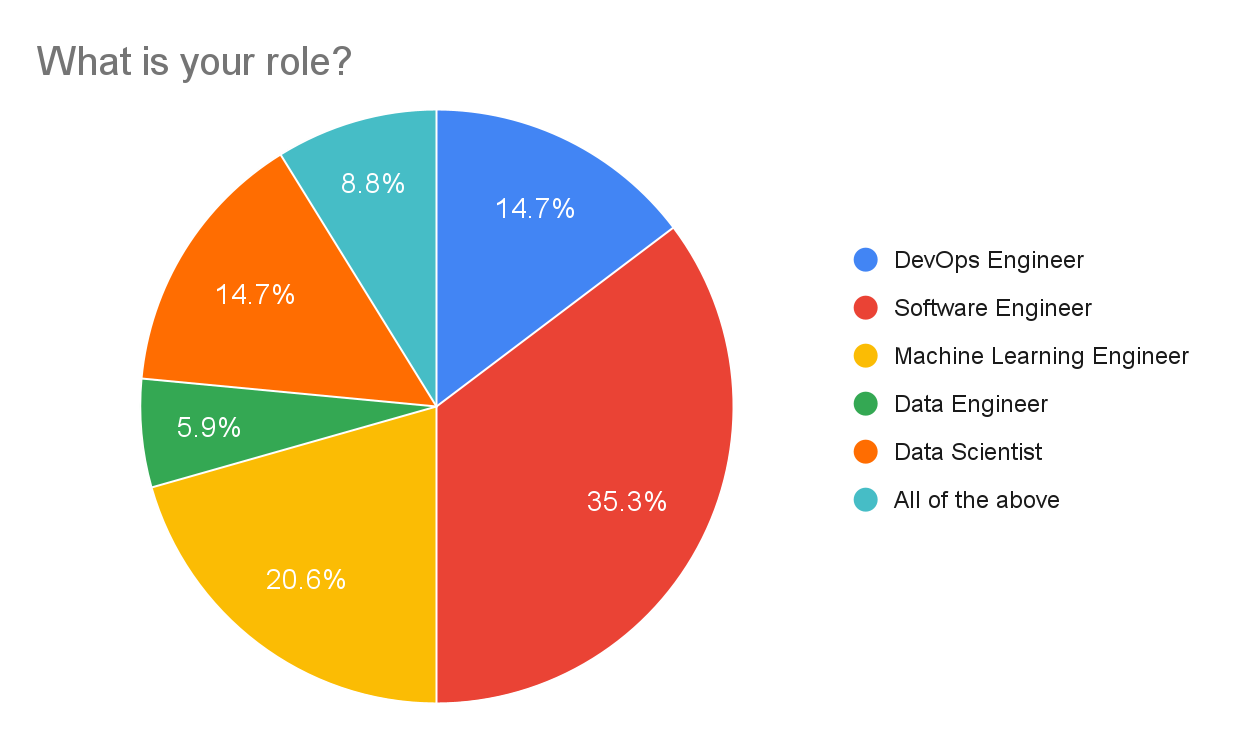
We had a good spread of roles, but mainly Software Engineers and Machine Learning Engineers representing just over 50% of responses. A few respondents added their own answer with some variation of “all of the above”, so they are collected together in the results. We had only two Data Engineer responses, which could mean people consider “data engineering” to be a part of their day-to-day and not their job title, or that Data Engineers aren’t using Hera (or Argo Workflows) – tough to make any conclusions here.
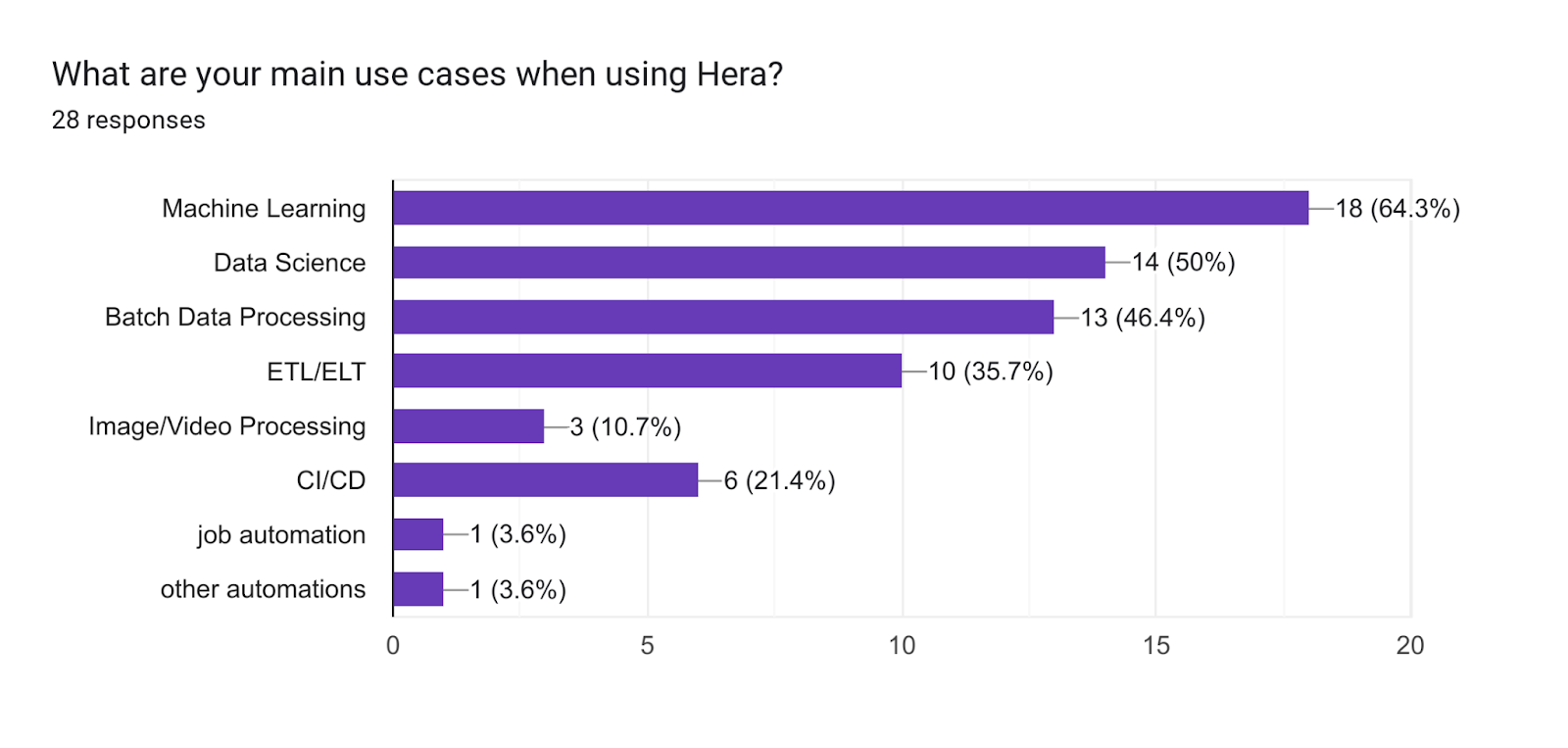
In terms of use cases, for this question, respondents were asked to select the 3 most relevant options. Machine Learning and Data Science lead the pack, with Batch Data Processing not far behind. There are varying data processing use cases, including ETL/ELT (which suggests the respondents do consider Data Engineering a part of the day-to-day) and Image/Video Processing. Finally, some folks are using Hera for CI/CD (which is surprising!) and other task automation (via custom responses).
Hera Features Usage
In this section of the survey we wanted to confirm where the main value-adds of Hera are, which means finding out the features that are being actively used.
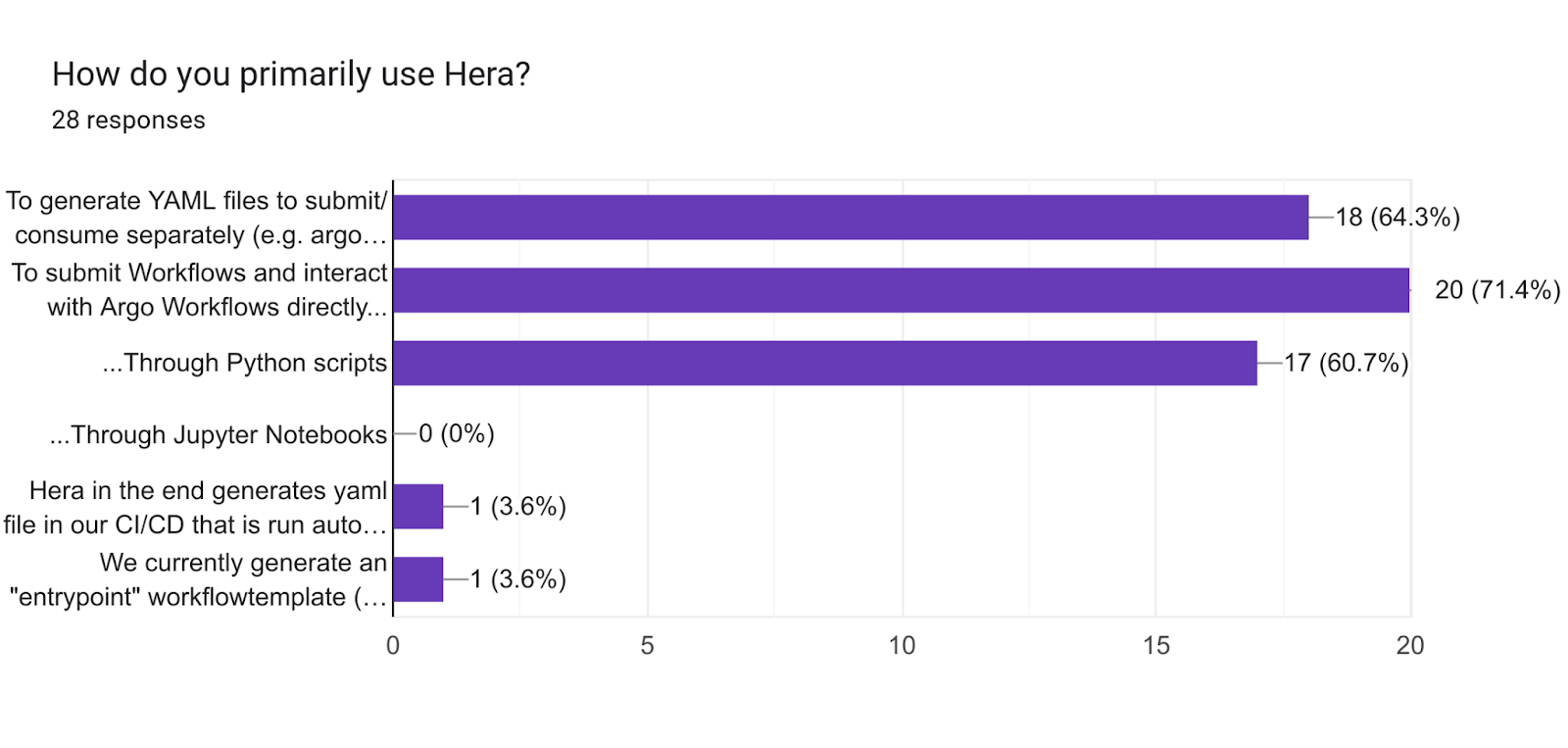
The results show a roughly equal balance of users generating YAML for separate consumption / processing, and users interacting with the Argo Workflows server directly through Hera.
What was especially surprising was that no respondents said they are using Hera in Jupyter Notebooks! There are a few possible conclusions we can draw from that:
- Respondents don’t use Jupyter at all
- There is no need to use Hera in Notebooks
- There is a need, but it’s not possible to use Hera in Notebooks (note, only inline script templates can be used in Notebooks, as runner templates require an image of the code to be built)
Considering the lack of GitHub issues and Slack questions mentioning Jupyter, I’m inclined to say it’s at least not the third option.
The next question was to confirm the key feature of Hera, turning Python functions into templates, was being used by the community, and if so, which flavour – “inline” or “runner”.
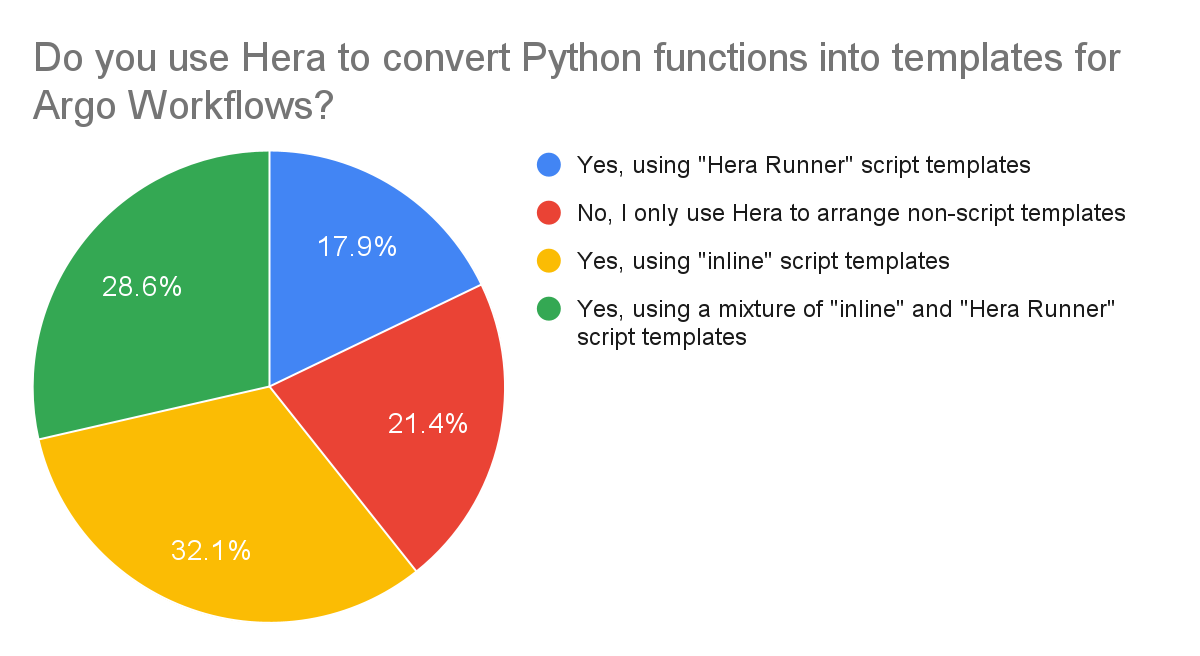
It’s surprising to see a substantial number, ~20%, only use Hera to arrange non-script templates, which suggests Hera is still valuable just to be able to define Workflows in Python, even if the business logic isn’t contained in Python functions. Beyond this use case, we see good adoption of the Hera Runner, while the “inline” templates make up the majority percentage of the results, suggesting we should still look to improve the template authoring experience for these users, for example through better input Parameter / Artifact handling.
Where the Community Gets Updates
The final closed-options question was looking to find out where users learn about Hera’s newest features.
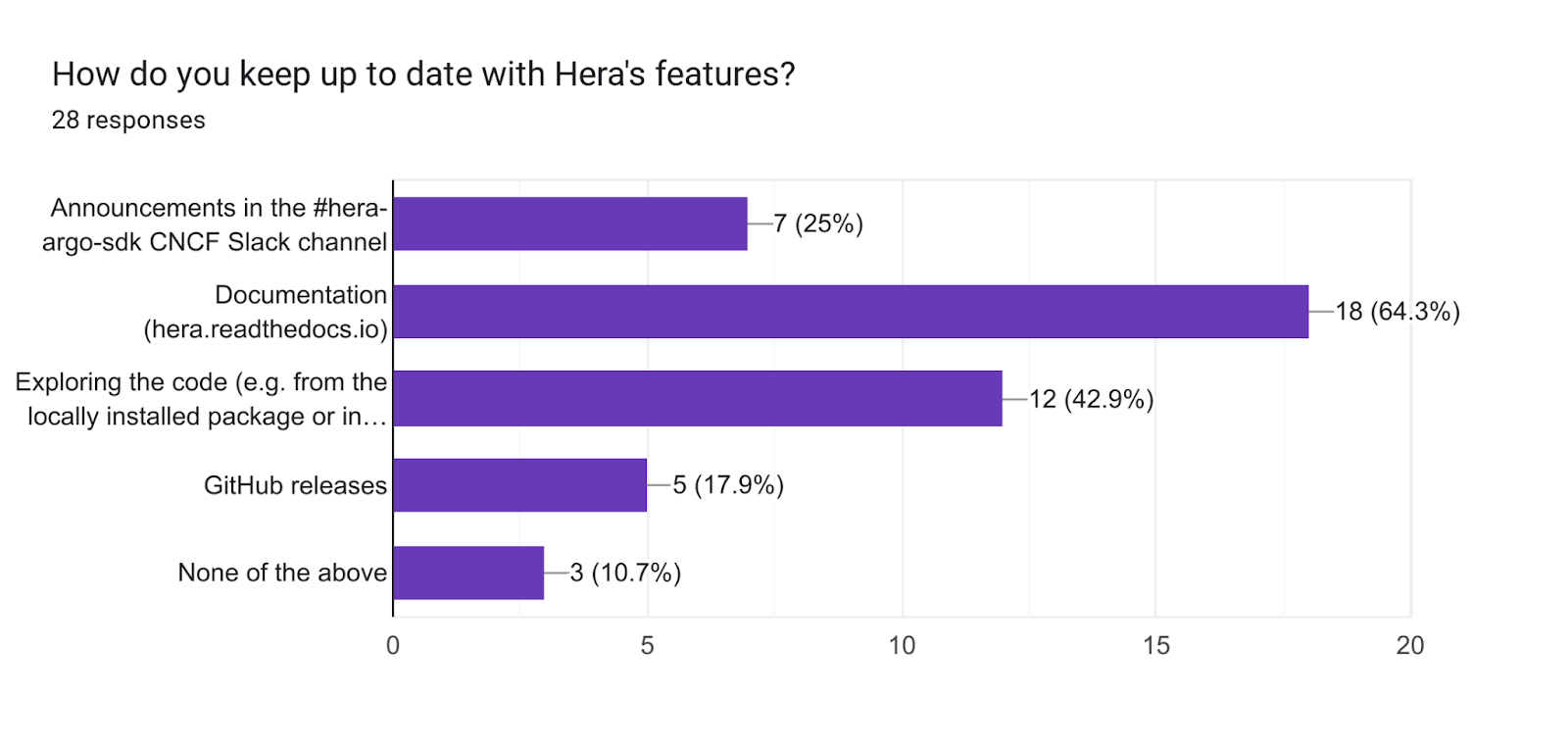
The docs website leads the results, which suggests a specific section to shout-out “new features” for readers would be helpful. This could be combined with a “breaking changes” section (though we have generally avoided breaking changes to non-experimental features). Users also naturally explore the code themselves, so we should aim to keep the codebase clean and commented. The GitHub release notes are automated, while the Slack announcement is adapted from the release notes, and often expanded on, so we’ll keep doing these! 🚀
Free-Form Questions
These questions gave space for users to say exactly what they like and dislike about Hera. We were thrilled with the breadth and depth of responses – many thanks to all who shared their thoughts in this section!
“What do you enjoy about using Hera?”
The main themes in the responses to this question were:
- Eliminates YAML Complexity: Hera removes the need to write and maintain complex YAML, making workflow creation easier, less error-prone, and more flexible
- Seamless Python Experience: Users love that Hera feels like writing standard Python with minimal overhead, making it more intuitive and accessible than Argo YAML
- Ease of Use: Python-based workflows are easier to debug, test, and reuse, allowing for faster iteration and dynamic workflow generation
Unsurprisingly, our community prefers Python over YAML! However, the key benefit of Hera over similar Python orchestrators is touched on in the second point about “minimal overhead” – users appreciate being able to write native Python, and separate out the orchestration logic. Also cool to see is Hera being used for dynamic workflow generation, something that is impossible in native Argo YAML – you need an abstraction layer to generate these dynamic workflows!
“What frustrations do you have when using Hera? Or, what is its biggest missing feature?”
We saw many themes from this question, with the main frustrations being the documentation and learning curve. This is understandable as Hera intends to be a thin wrapper to the Argo API, so users often have to learn two things at once – what they need from Argo, and how to do it in Hera.
Another interesting theme was the desire for a better debugging experience and local execution, which would make Hera feel like a more complete, all-in-one solution for Python orchestration, rather than being a wrapper for Argo Workflows. There are different ways to go about this in terms of using a local Kubernetes cluster, or writing our own native execution engine, so it’s something we’d love to hear more feedback about in GitHub issues or the Hera Slack channel!
Finally, there could be better support around using Hera/Argo Workflows, in terms of image building, job submission, Workflow versioning, as well as helping existing Argo Workflows users migrate their YAML definitions to Hera.
Summarising the main themes:
Documentation Gaps & Learning Curve
- Users find the documentation lacking, particularly for newer features and best practices.
- More full-fledged, complex examples are needed, especially for users unfamiliar with Python.
- Some struggle with understanding whether a limitation is from Hera or Argo.
- Uncertainty in best practices, users struggle with knowing the recommended way to use key features like
@scriptvs. theScriptclass.
Also learning curve related – specific Argo-Hera mappings and syntax issues:
- Unclear how parameters, artifacts behave in Hera, creating confusion.
- Some aspects of Hera behave differently than Python norms (e.g.
@scriptdecorator scoping behavior) due to it being a DSL.
Debugging & Local Execution Challenges
- Users struggle with debugging workflows, often needing to check Argo directly.
- Error messages can lack context, making troubleshooting harder.
- The inability to run complete workflows locally for testing is a major pain point.
- Users need clearer examples and guides for troubleshooting common issues in Argo Workflows and Hera.
Hera API Usability
- Users find setting up a good workflow requires a lot of scaffolding (image builds, job submission scripts, etc.).
- Would like higher-level utilities to simplify common tasks and versioning workflows.
Migration & Integration Pain Points
- Difficulty converting existing Argo YAML workflows to Hera syntax.
- Users want tools or guides for migrating from YAML-based workflows to Hera.
- Need for a way to define and manage generic CRDs.
“What’s missing in Argo Workflows or Hera that would make you use them? If you’re not using them, why?”
If you completed the survey, you might not have seen this question – this was a single follow-up question for the respondents who said “no” to “Do you currently use Hera?”. A special shoutout to these folks who don’t use Hera, but still told us possible reasons why!
- Local Testing & Debugging: Users want the ability to run workflows locally for testing before deploying to Kubernetes
- Migration Challenges: Existing YAML-based workflows make migration to Hera difficult. A structured migration guide from Kubernetes YAML to Hera would help adoption.
- Hera’s Value Proposition: Some users aren’t convinced Hera adds enough value beyond Argo Workflows' native YAML syntax and are happy to create their own abstraction layer. They feel it acts as a simple wrapper rather than providing a meaningful abstraction that reduces complexity.
Conclusions
Before we talk about conclusions, I wanted to say thank you once again to all respondents of the survey, and all our Hera users! The project is growing steadily, with a recent shout-out in the Argo project updates at ArgoCon EU 2025, plus a talk featuring a migration from Airflow to Hera. We’ve seen some new faces contributing to the repo with new issues and pull requests and we'd love for more people to get involved in designing new features and having discussions in the Hera Slack channel!
In terms of informing the roadmap, clearly, documentation is first on the list. Stay tuned for a more detailed roadmap, but overall it should look something like this:
- We hear the need for a refreshed, concise but still informative walkthrough, a more comprehensive set of examples, and a collection of best practices for teams to follow.
- We want to improve the Workflow-authoring experience through better error messages and syntax improvements coming out of best practices.
- We’d like to support more varied ML use cases, including experiment tracking, and a plug-in system to better integrate with common libraries.
- Finally, we want to improve the overall developer experience for users outside of just their Python code, by building on the Hera CLI, which could be used to create the scaffolding for a better developer workflow, and even generate the equivalent Hera workflow in Python from your existing YAML Workflows!
We're looking forward to the next year of progress for Hera! If you haven't joined the CNCF Slack channel yet, come and find us on #hera-argo-sdk to chat about Hera and ask any questions!