So far
In the first two articles in this series, I've stressed that the secret to cratering your database is to do things that don't scale and then try to scale. In the last article, I argued that database aggregation operations like count, min, and max introduce unpredictable scaling into your system. Today, I want to address Normalization and how it introduces a new way for your database to crater under load.
Why normalize?
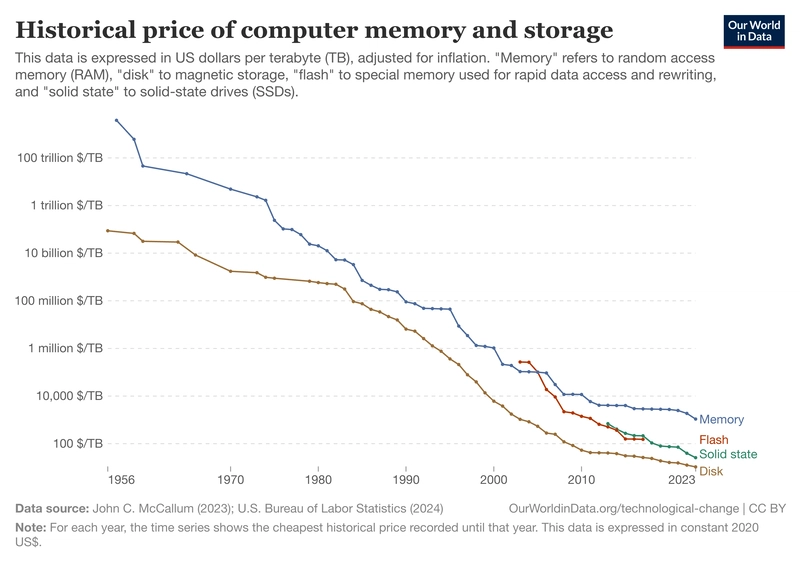
Why do we normalize SQL database tables? Initially, we did this to maximize the most constrained resource in the system: storage. Disk space used to be the most expensive part of a computer. In 1982, PC Magazine1 had hard drive advertisements with a 6MB drive for $2995. That's a staggering $500,000 per Gigabyte (not that you could have bought a GB drive even if you had the money). At the time, people were willing to trade extra compute cycles for more efficient storage.
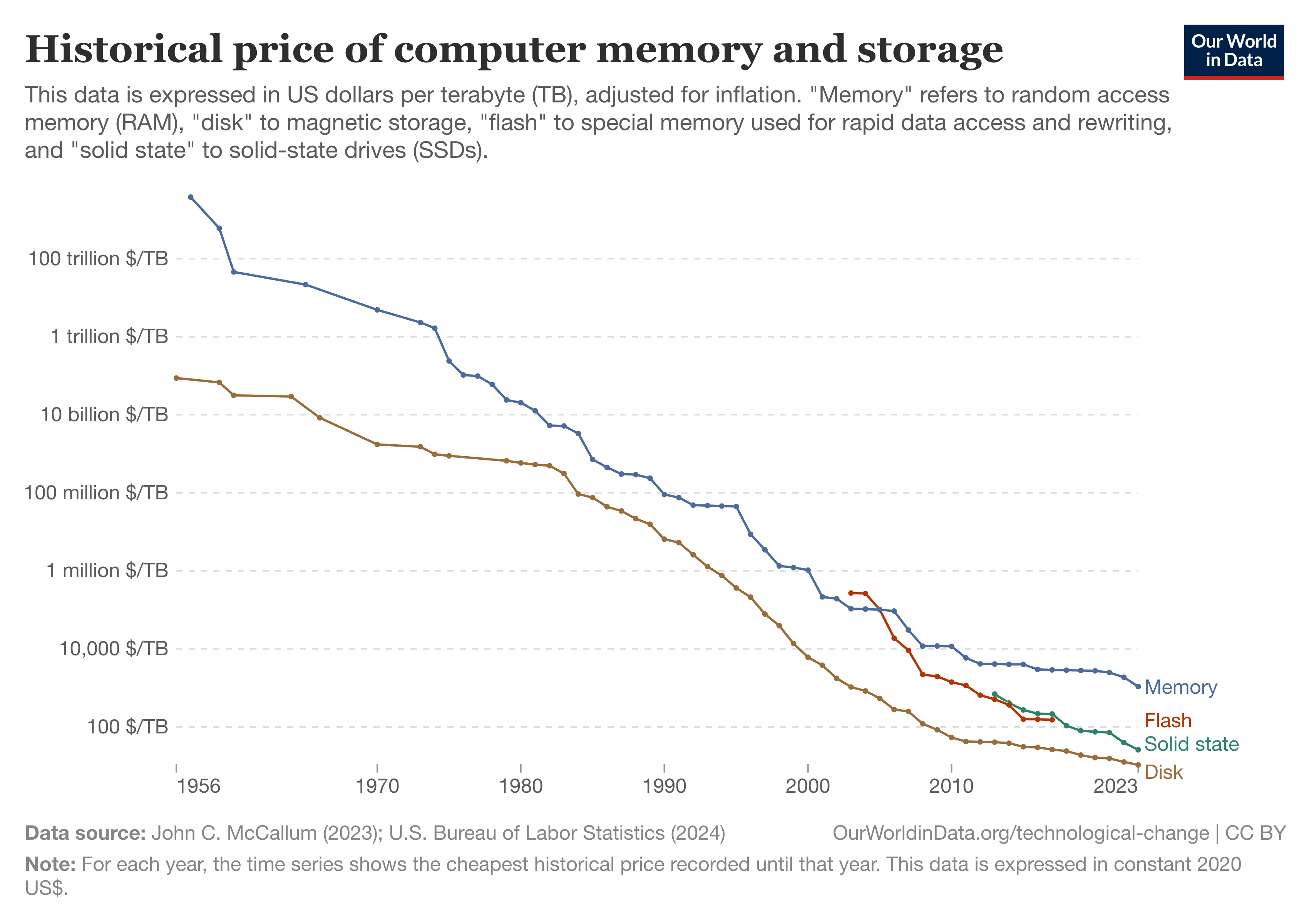
Today, our disk cost per MB is less than $0.000011 (see figure below).2 Storage has become one of the most cost-efficient resources in our systems, while compute has become the bottleneck.
Another reason normalization is still somewhat popular is that it is theoretical and mathematical. It does not care about what the data is for; it only cares about data. This allows normalization to be managed far away from the applications that use it. A database administrator (DBA) can fully control the table schema and ensure a provable third normal form (3NF) without knowing how the data will be used.
The 3NF was designed to reduce data duplication and help preserve referential integrity.3 Other versions exist,4 but 3NF is widely known, and I'll use it as a stand-in for all such storage-reducing data schemas.
Why is this a problem?
Splitting the data into separate tables is easy on disk space but creates a problem. The end user never wants to see "normalized" data; she wants to see "un-normalized" data. The DBMS must stitch the various tables into a single result for each request. This is the purpose of the SQL clause, JOIN.
The JOIN clause combines columns from one or more tables into a unified, un-normalized result. This is precisely what our end user is looking for. So why is this a bad thing?
Joins are computationally expensive. They trade efficient at-rest storage (disk) for runtime manipulation (compute). Let's look at an example.5
Given a typical eCommerce store in 3NF, here is how we would find a particular book by title:
SELECT * FROM PRODUCTS
INNER JOIN BOOKS ON
productId = productId
WHERE name = "The Fountainhead"Assuming a proper index exists on name and productId (a best-case scenario), our time complexity will be O(log(N) + Nlog(M)).
As we need to pull in more tables, our time complexity gets worse:
SELECT * FROM PRODUCTS
INNER JOIN ALBUMS ON
productId = productId
INNER JOIN TRACKS ON
albumId = albumId
WHERE name = "Achtung Baby"Again, assuming proper indexes, this has a time complexity of O(log(N) + Nlog(M) + Nlog(M)).
This gets exponentially worse if you include non-indexed properties in your JOIN.
Unpredictability
A time complexity of linear (O(N)) or worse indicates that we've relinquished predictable performance.6 Once you hit O(N), the performance of a query depends on the number of rows on the disk. A large eCommerce store will perform more poorly than a small eCommerce store. Your best customers will perform worse. This is a terrible business model.
Let's look at how a JOIN affects performance. Here's a simple query7 that finds all Sales Orders for a Customer:
SELECT c.CustomerID, s.SalesOrderID
FROM Sales.Customer c
INNER JOIN Sales.SalesOrderHeader s
ON s.CustomerID = c.CustomerID
WHERE c.CustomerID = 11111Assume there is an index on CustomerID in the Sales table and that CustomerID is the primary key in the Customer table, making this a best-case scenario. Let's look at the query plan for this:
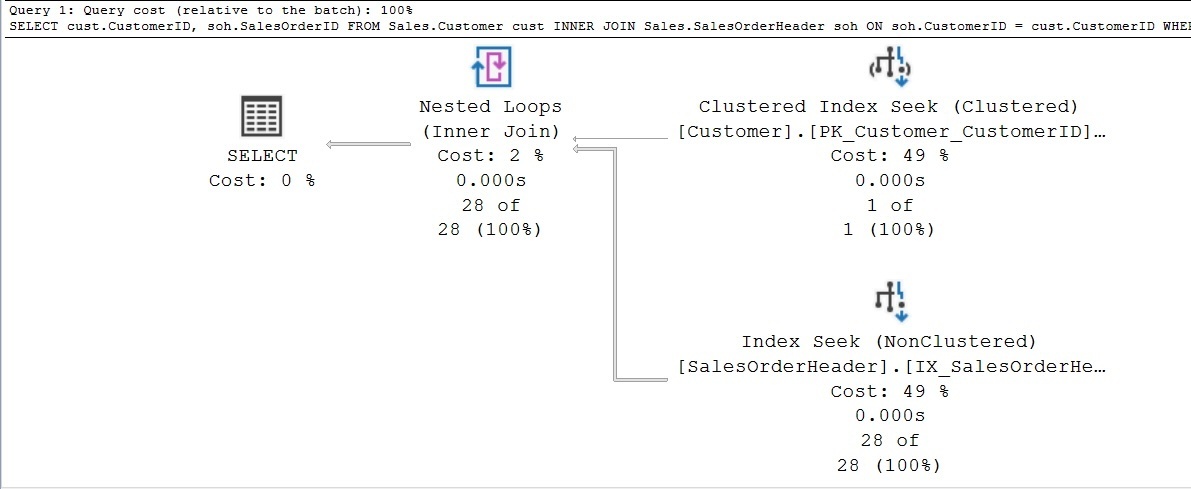
Note that we have a nested loop. That means for each record in the first table, we will have to perform a full table lookup in the second table. For an indexed column, your complexity is O(NlogN). Your complexity will approach O(N^2) for a non-indexed column, guaranteeing a problem as your data grows.
DynamoDB is different
DynamoDB does not support JOIN clauses. This is on purpose. Joins don't scale. DynamoDB doesn't allow you to write a query that won't scale.
To represent the SQL example above, you must design your DynamoDB table to pre-join Customer and Sales. This is sometimes called "denormalization."8 The methods for doing so are beyond the scope of this article. Please see Alex Debrie's excellent The DynamoDB Book for examples and deeper explanations.
If this sounds like extra work, you are right. But it's work that buys you consistent, predictable scaling that you don't get with 3NF and JOIN clauses. This "shift left" of complexity buys you peace of mind while your system is under load in production.9
Summary
Normalization was designed to solve a problem we no longer have. The penalty you pay for normalization (and having to "un-normalize" it for users) is in computational complexity. All JOIN clauses suffer from this penalty.
This penalty becomes more severe as you grow. Remember, business growth means data growth, and you want business growth. Even O(NlogN) will begin to perform poorly as your data grows.
Happy building!
References
Wikipedia: Join (SQL)
YouTube: AWS re:Invent 2019: Amazon DynamoDB deep dive: Advanced design patterns (DAT403-R1)
Alex Debrie: SQL, NoSQL, and Scale: How DynamoDB scales where relational databases don't
Yan Cui: Runtime vs. Author-time Complexity
-
https://ourworldindata.org/grapher/historical-cost-of-computer-memory-and-storage ↩
-
This is the example Rick Houlihan used in his 2019 re:Invent talk on DynamoDB. See References for the link. ↩
-
Thomas LeBlanc, Execution Plans: Nested Loop ↩
-
"De-normalization" vs. "Un-normalization" - I like the term denormalization for the pattern of storing pre-joined data on disk, while I use "un-normalize" to describe the JOIN process in a DBMS ↩
-
See Yan Cui’s post on Runtime vs. Author-time Complexity ↩