Greetings!
Fault tolerance is a very important aspect of every non-startup application.
It can be described as a definition:
Fault tolerance is the ability of a system to maintain proper operation despite failures or faults in one or more of its components.
But this gives only slight overview - fault tolerance concerns many areas especially when we are talking about software engineering:
- Network failures (i.e. connection halt due to power outage on intermediate router)
- Dependent service unavailability (i.e. another microservice)
- Hardware bugs (i.e. Pentium FDIV bug)
- Storage layer corruptions (i.e. bit rot)
As a database developer I'm interested in latter - in the end all data stored in disks.
But you should know that not only disks can lead to such faults. There are other pieces that can misbehave or it's developer's mistake that he/she didn't work with these parts correctly.
I'm going to explain how this 'file write stack' (named in opposite to 'network stack') works.
Of course, main concern will be about fault tolerance.
Application
Everything starts in application's code. Usually, there is separate interface to work with files.
Each PL (programming language) has own interface. Some examples:
-
fwrite- C -
std::fstream.write- C++ -
FileStream.Write- C# -
FileOutputStream.Write- Java -
open().write- Python -
os.WriteFile- go
These all means given by PL itself: read, write, etc...
Their main advantage - platform independence: runtime (i.e. C#) or compiler (i.e. C) implements this.
But this have drawbacks. Buffering in this case - all calls to this virtual "write" function store going to be written data in special buffer to later write it all at once (make syscall to write).
Due to documentation, each of all PL above support buffering:
- C - setvbuf
- C++ - filebuf
- C# - BufferedFileStrategy
- Java - Files.newBufferedReader
- Python - io.BufferedIOBase
- go - bufio.Reader
What about C# - class
FileStreamuses another classFileStreamStrategy- it handles all requests (Strategy pattern).
For example, when we are instantiatingFileStreamthroughFile.Open()-BufferedFileStrategywrapsOSFileStreamStrategy.
It adds buffering layer above syscalls.
Generaly, buffering in user space is a good feature - usually it improves performance.
But programmer should be aware of additional buffers. There are 2 types of buffering I can identify:
- Manual (go, Java) - create buffered file object manually
- Transparent (C, C++) - buffer maintained automatically
In first case we know, that buffer should be flushed at end of write session, but in second case can you can easily shoot in your foot:
- File opened in memory, but no callbacks for flushing registered or just forgot to add such code
- Application closed abnormally (i.e. got SIGKILL)
All such cases ends up with all data in in-memory buffer get lost.
So, there are 2 solutions:
- Always flush data after write session. The easiest case for simple application is by adding single write function that accepts batch of write buffers and calls flush function at the end.
- Disable buffering at all and make writes directly.
From performance view - first case is the most attractive.
I have made a small benchmark - sequential write of 64Mb data into a file. The result is obvious: buffered IO faster by at least 8 times.Performance comparison
Test matrix: old laptop with HDD and new laptop with SSD NVMe M.2.
Direct write, s
Buffered write, s
Old
894.7
109.6
New
8.932
1.198
Source code of benchmark here.
Operating system
Programming language gives good platform abstraction - programmer does not need to think about (at least, not very often) on which operating system application works.
But eventually, PL interface will be mapped to some syscalls.
These syscalls are OS dependent, but in common we have 4 main functions:
| Operation | *nix | Windows |
|---|---|---|
| Open/Create |
open/creat
|
CreateFile |
| Read |
pread/read
|
ReadFile |
| Write |
pwrite/write
|
WriteFile |
| Close | close |
CloseFile |
*nixmeans Unix-like OS: Linux, FreeBSD, OSX.
Semantics of some operations can differ, but now it is not very important - common interface/behaviour pattern the same.
There is buffering also at OS layer. It is called page buffer.
And it's even easier to shoot yourself in the foot with it.
Operations with file are perform in pages (huge sequential block of data, usually 4Kb) even if only single byte was requested.
When we read page is stored in buffer. Then we send write request that is not written to device immeately. Instead, it just marked as "dirty" and scheduled to be flushed at near future.
All such pages (clean and dirty) make up a page cache.
How it can harm us? Follow these steps:
- User sends request to update info about himself. For example, it can be his password
- We open file with users information - retrieve required page
- Page is updated with new password (of course it will be password hash for security reasons)
- Application make "write" request to OS (everything is ok)
- We tell user that everything is updated
What could go wrong? Power outage!
- User replaced his old password with new one in his password manager (old cryptographic password)
- "dirty" page with new password (step 3) was lost because of power failure and old password still the same (on disk)
Congratulations - user lost access to his account.
Page cache is very helpfull, especially when there are many operations on same page.
But when we should make a "durable" write (that is it must be saved to disk permanently, not being just updated in memory) we must ensure data is flushed to disk.
Even here there are 2 solutions:
- Special syscall to flush data to disk
- Bypass page cache and always write to disk
Special syscall to flush data
This solution uses separate syscall that ensures that all our write requests were completed.
Linux
In Linux we can use:
-
fdatasync(fd)- checks, that data in memory and on disk are synchronized, that is performs flushing of pending ("dirty") pages. -
fsync(fd)- the same asfdatasync(fd), but also updates file metadata (i.e. last access time). Usually, you don't need this and should preferfdatasyncfor performance. -
sync_file_range(fd, range)- checks that specific range of file is flushed to disk (according tomanthis is very dangerous function, so I added it here just for familiarization) -
sync()- it flushes all pages to disk, but for all files, not some specified
As said earlier, fdatasync synchronizes only contents, without metadata like fsync, so it is faster.
etcd comments this out and makes explicit separation between them:
// Fsync is a wrapper around file.Sync(). Special handling is needed on darwin platform.
func Fsync(f *os.File) error {
return f.Sync()
}
// Fdatasync is similar to fsync(), but does not flush modified metadata
// unless that metadata is needed in order to allow a subsequent data retrieval
// to be correctly handled.
func Fdatasync(f *os.File) error {
return syscall.Fdatasync(int(f.Fd()))
}Windows
For Windows there are functions:
-
_commit- flushes data from file to disk -
FlushFileBuffers(fd)- causes write all buffered data to a file (I'm not a Windows developer, so do not known difference with previous one) -
NtFlushBuffersFileEx(fd, params)- causes page cache flush, but it is more low-level function (marked withNTSYSCALLAPI)
P.S. NtFlushBuffersFileEx used in Postgres as a writer for crossplatform fdatasync, and for fsync it uses _commit.
// https://github.com/postgres/postgres/blob/9acae56ce0b0812f3e940cf1f87e73e8d5784e78/src/include/port/win32_port.h#L85
/* Windows doesn't have fsync() as such, use _commit() */
#define fsync(fd) _commit(fd)
// https://github.com/postgres/postgres/blob/874d817baa160ca7e68bee6ccc9fc1848c56e750/src/port/win32fdatasync.c#L23
int
fdatasync(int fd)
{
// ...
status = pg_NtFlushBuffersFileEx(handle,
FLUSH_FLAGS_FILE_DATA_SYNC_ONLY,
NULL,
0,
&iosb);
// ...
}macOS
It is also worth mentioning macOS. Althrough it is POSIX-complient, but one call to fsync is not enough - fcntl(F_FULLSYNC) call requred.
This is outlined even in documentation.
For applications that require tighter guarantees about the integrity of their data, Mac OS X provides the F_FULLFSYNC fcntl.
Again, this is handled in etcd:
// Fsync on HFS/OSX flushes the data on to the physical drive but the drive
// may not write it to the persistent media for quite sometime and it may be
// written in out-of-order sequence. Using F_FULLFSYNC ensures that the
// physical drive's buffer will also get flushed to the media.
func Fsync(f *os.File) error {
_, err := unix.FcntlInt(f.Fd(), unix.F_FULLFSYNC, 0)
return err
}
// Fdatasync on darwin platform invokes fcntl(F_FULLFSYNC) for actual persistence
// on physical drive media.
func Fdatasync(f *os.File) error {
return Fsync(f)
}Bypass OS page cache
The second solution require us to pass special flag during file opening.
Linux
Linux require passing 2 flags O_SYNC | O_DIRECT to open:
-
O_SYNC- every write flushed immediately to disk. Also, there isO_DSYNC- replacefsyncwithfdatasync -
O_DIRECT- write bypasses page cache (equivalent to disabling it at all for this file)
Using O_SYNC/O_DSYNC is equivalent to calling fsync/fdatasync right after we call write/pwrite.
Also, using fcntl you can change O_DIRECT flag, but no O_SYNC.
This is specified in documentation for fcntl:
... It is not possible to change the O_DSYNC and O_SYNC flags; see BUGS, below.
Windows
In Windows we have similar flags:
-
FILE_FLAG_NO_BUFFERING- disables OS page buffering -
FILE_FLAG_WRITE_THROUGH- all writes flushed to disk, without buffering
Documentation gives description of behaviour when both are specified:
If FILE_FLAG_WRITE_THROUGH and FILE_FLAG_NO_BUFFERING are both specified, so that system caching is not in effect, then the data is immediately flushed to disk without going through the Windows system cache. The operating system also requests a write-through of the hard disk's local hardware cache to persistent media.
And this blog article introduces comparison matrix:
| NO_BUFFERING | |||
| Clear | Set | ||
| WRITE_THROUGH | Clear | Writes go into cache Lazily written to disk No hardware flush | Writes bypass cache Immediately written to disk No hardware flush |
| Set | Writes go into cache Immediately written to disk Hardware flush | Writes bypass cache Immediately written to disk Hardware flush | |
Postgres uses this mapping between Windows/Linux flags:
| Windows | Unix |
|---|---|
| FILE_FLAG_NO_BUFFERING | O_DIRECT |
| FILE_FLAG_WRITE_THROUGH | O_DSYNC |
// https://github.com/postgres/postgres/blob/30e144287a72529c9cd9fd6b07fe96eb8a1e270e/src/port/open.c#L65
HANDLE
pgwin32_open_handle(const char *fileName, int fileFlags, bool backup_semantics)
{
// ...
while ((h = CreateFile(fileName,
// ...
((fileFlags & O_DIRECT) ? FILE_FLAG_NO_BUFFERING : 0) |
((fileFlags & O_DSYNC) ? FILE_FLAG_WRITE_THROUGH : 0),
NULL)) == INVALID_HANDLE_VALUE)
// ...
}Directory sync
Linux
But that's not all. Unix way - everythin is file, even directory. Directory is a file, but read/write operations are different:
-
read- iterate directory entries -
write- create/delete entry
Read is not very interesting for us, but write is - when we create or delete file (moving file is both operations) performed to must ensure these operations are flushed - fsync(directory_fd) is called.
This is documented as well:
Calling
fsync()does not necessarily ensure that the entry in the directory containing the file has also reached disk.
For that an explicitfsync()on a file descriptor for the directory is also needed.
Windows
As for Windows - we can not do it:
- Directory is not openable - we get
EACCESSwhen try to do this -
FlushFileBuffersworks only with files or whole volume (all files in volume), but for the latter elevated privileges required.
Again, Postgres use *nix style - it call fsync for directories, but for Windows it has additional check:
/*
* fsync_fname_ext -- Try to fsync a file or directory
*
* If ignore_perm is true, ignore errors upon trying to open unreadable
* files. Logs other errors at a caller-specified level.
*
* Returns 0 if the operation succeeded, -1 otherwise.
*/
int
fsync_fname_ext(const char *fname, bool isdir, bool ignore_perm, int elevel)
{
returncode = pg_fsync(fd);
/*
* Some OSes don't allow us to fsync directories at all, so we can ignore
* those errors. Anything else needs to be logged.
*/
if (returncode != 0 && !(isdir && (errno == EBADF || errno == EINVAL)))
{
// ...
return -1;
}
return 0;
}fsync errors
Even though write returned success status code, it does not mean that write was successful - recall that we use buffering, so we just updated in-memory page.
When we call fsync it can return error. It was shown in the code above.
But what we should do when we get error code from fsync?
Generally - halt immediately. If developing for specific OS - it depends. Why? Main reason, is that we no longer can be sure about consistency:
- File system can be broken
- File can have a hole (invalid write)
- "Dirty" pages can be just marked "clean" and no longer flushed.
Latter may cause differences in file (contents) view from in-memory and disk perspectives, but we will not notice that.
Marking pages as "clean" is a part of Linux implementation - it assumes, that file system correctly completes write operation.
Postgres hackers make a brief overview of different operating system behaviour on fsync error:
- Darwin/macOS - invalidate buffers
- OpenBSD - invalidate buffers
- NetBSD - invalidate buffers
- FreeBSD - remain "dirty"
- Linux (after 4.16) - marked "clean"
- Windows - unknown
So, if we are developing crossplatform application - the state of buffers after we get fsync error is undefined.
But when developing for specific OS - it is defined.
fsyncgate
We can not talk about fsync errors without touching fsyncgate.
fsyncgate - is a name of a bug found in Postgres that caused data loss. More infor can be found here.
Briefly, initially developers thought fsync semntics is following:
If
fsync()completed successfully, then all writes since last successfulfsync()were flushed to disk.
In another words - try to call fsync until it returns a successful status code.
But as we observed earlier it is a misconception. In reality, if fsync returned error code, than all "dirty" pages will be just forgotten.
Therefore, more correct to state:
If
fsync()completed successfully, then all writes since lastsuccessfulfsync()were flushed to disk.
This was noticed in 2018 year and answer was discussed in mailing list.
That bug was fixed in 12 version (with backpatching) in this commit using next code (increase error level):
// https://github.com/postgres/postgres/blob/30e144287a72529c9cd9fd6b07fe96eb8a1e270e/src/backend/storage/file/fd.c#L3936
int
data_sync_elevel(int elevel)
{
return data_sync_retry ? elevel : PANIC;
}
// Любая функция, например эта - https://github.com/postgres/postgres/blob/30e144287a72529c9cd9fd6b07fe96eb8a1e270e/src/backend/access/heap/rewriteheap.c#L1132
void sample_function()
{
// Любой вызов fsync в логике
if (pg_fsync(fd) != 0)
// ereport(ERROR,
ereport(data_sync_elevel(ERROR),
(errcode_for_file_access(),
errmsg("could not fsync file \"%s\": %m", path)));
}Disk operations - is one of the most important part of each database. So many of them implement their own page cache manager (subsystem) and does not rely on OS. This adds some improvements: Here some examples of several databases: As I said, own page cache/manager can optimize database workflow and smart page eviction algorithm is not only place to optimize:Page cache in databases
COMMIT)
DBMS
Implementation
Page eviction algorithm
Postgres
bufmgr.h, bufmgr.c
clock-sweep
SQL Server
sources N/A
LRU-2 (LRU-K)
Oracle
sources N/A
LRU, Temperature-based
MySQL (InnoDB)
buf0buf.h, buf0buf.cc
LRU
DB_FLASH_CACHE_FILE for Oracle and BPE (buffer pool extension) for SQL Server)pg_prewarm extension to "warm" page cache
I searched Linux kernel source code and found
fsyncimplementation here
File system
Usually, we say "write to disk", but actually it is final destination. There is another layer that should be passed - file system.
Nowadays all data stored in filesystems. As for me, I do not know any system that access block devices using either LBA or CHS - you just write at some offset in a file.
So, before data is written to disk it must be processed by file system.
Today there are huge amount of different file systems, so I primarly focus on small part:
- ext family
- btrfs
- xfs
- ntfs
Choose them, as most popular in my opinion
File systems can be characterized by multiple aspects (i.e. max file name length), but now we are interested in those, who related to fault tolerance.
File system integrity
From programming perspective, file system - is a global, shared object. Everyone has access to and can to modify it.
Taking global lock during write operations seems a bad idea, so there are a couple of mechanisms different file systems use:
- Journaling (ext family, ntfs, xfs) - file system maintains a log of operations and always able to replay it in case of error
- COW, Copy on write (btrfs, zfs) - blocks of data are not modified, but instead they create new block with modifed data
- Log-structured - file system itself is a log of operations
Not all file system support such mechanisms, i.e. ext2 is not journaling fs and all modifications applied directly.
That seems to be an answer - just choose FS with jounaling/COW and here you go. But no.
Research Model-Based Failure Analysis of Journaling File Systems reveals, that even journaled file systems can end up being inconsistent.
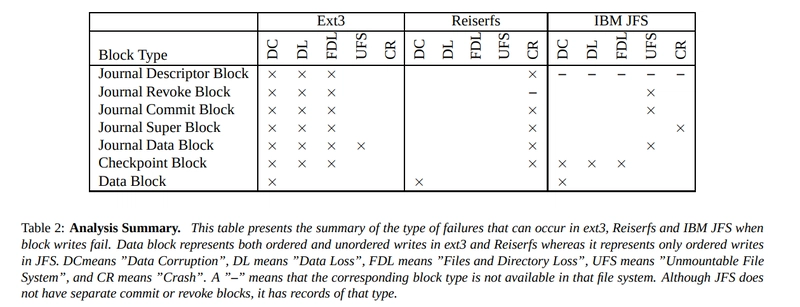
3 file systems (ext3, reiserfs, jfs) were examined when block writing error occurred. Result is presented in table:
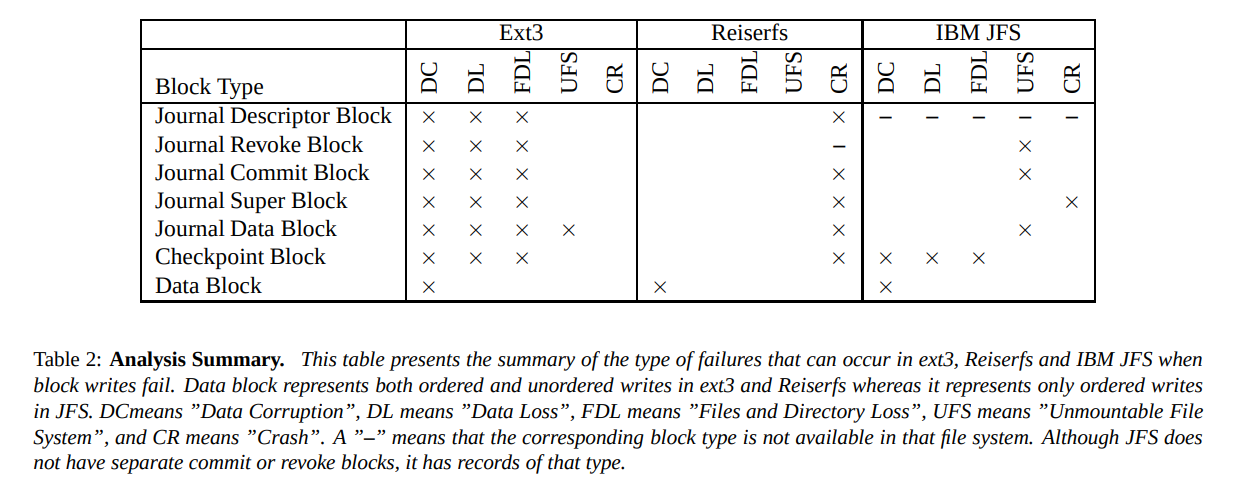
As you can mention - every file system can leave content of block (Data Block) in inconsistent state (DC, Data Corruption).
Conclusion: do not rely heavily on file system journaling.
I also found research for NTFS (163 p.) - even with metadata redundancy file system can be corrupted and become unrecoverable.
What about COW and log structured?
In this research (26 p.) btrfs was tested on SSD and after some power outages file system has become unusable and unrecoverable.
On the other hand, journaled ext4 survived 1406.
As for log-structured - I couldn't find any research about them.
Magic number
We can outline 2 main components in file, that we should update - file size and data blocks.
What we should update first?
If file size, then in case of failure garbage can be found in file - file size can be larger, but data in new block contains some garbage.
It can be compared to garbage that stored in initialized variables on stack or in just allocated memory (i.e. using
mallocin C)
From file system perspective - there is no inconsistency. But there may be in case of application - garbage in data.
We can protect ourselves by using special markers in file - after we read some chunk of data first check that marker.
Usually, it is some predefined constant.
This approach is used by:
- Postgres - add "magic number" in header of WAL page
Postgres code
/*
* Each page of XLOG file has a header like this:
*/
#define XLOG_PAGE_MAGIC 0xD114 /* can be used as WAL version indicator */
typedef struct XLogPageHeaderData
{
uint16 xlp_magic; /* magic value for correctness checks */
// ...
} XLogPageHeaderData;
- Kafka - "magic number" used as a version
Kafka magic number
public class FileLogInputStream implements LogInputStream<FileLogInputStream.FileChannelRecordBatch> {
@Override
public FileChannelRecordBatch nextBatch() throws IOException {
// ...
byte magic = logHeaderBuffer.get(MAGIC_OFFSET);
final FileChannelRecordBatch batch;
if (magic < RecordBatch.MAGIC_VALUE_V2)
batch = new LegacyFileChannelRecordBatch(offset, magic, fileRecords, position, size);
else
batch = new DefaultFileChannelRecordBatch(offset, magic, fileRecords, position, size);
return batch;
}
}
- SQLite - use ASCII constant string "SQLite format 3" for main database file or random bytes for journal
SQLite magic numbers
// Header for undo journal
/*
** Journal files begin with the following magic string. The data
** was obtained from /dev/random. It is used only as a sanity check.
*/
static const unsigned char aJournalMagic[] = {
0xd9, 0xd5, 0x05, 0xf9, 0x20, 0xa1, 0x63, 0xd7,
};
static int readJournalHdr(
Pager *pPager, /* Pager object */
int isHot,
i64 journalSize, /* Size of the open journal file in bytes */
u32 *pNRec, /* OUT: Value read from the nRec field */
u32 *pDbSize /* OUT: Value of original database size field */
){
int rc; /* Return code */
unsigned char aMagic[8]; /* A buffer to hold the magic header */
i64 iHdrOff; /* Offset of journal header being read */
/* Read in the first 8 bytes of the journal header. If they do not match
** the magic string found at the start of each journal header, return
** SQLITE_DONE. If an IO error occurs, return an error code. Otherwise,
** proceed.
*/
if( isHot || iHdrOff!=pPager->journalHdr ){
rc = sqlite3OsRead(pPager->jfd, aMagic, sizeof(aMagic), iHdrOff);
if( rc ){
return rc;
}
if( memcmp(aMagic, aJournalMagic, sizeof(aMagic))!=0 ){
return SQLITE_DONE;
}
}
// ...
}
// Header of main database file
#ifndef SQLITE_FILE_HEADER /* 123456789 123456 */
# define SQLITE_FILE_HEADER "SQLite format 3"
#endif
/*
** The header string that appears at the beginning of every
** SQLite database.
*/
static const char zMagicHeader[] = SQLITE_FILE_HEADER;
static int lockBtree(BtShared *pBt){
// ...
if( nPage>0 ){
/* EVIDENCE-OF: R-43737-39999 Every valid SQLite database file begins
** with the following 16 bytes (in hex): 53 51 4c 69 74 65 20 66 6f 72 6d
** 61 74 20 33 00. */
if( memcmp(page1, zMagicHeader, 16)!=0 ){
goto page1_init_failed;
}
// ...
page1_init_failed:
pBt->pPage1 = 0;
return rc;
}
Additionally, there are some predefined headers for different file formats. For example, BOM, JPEG or PNG.
Checksum
But this is just a constant, that does not depend on stored data - it is used to definetely say "this is a garbage".
What go wrong? For example, we send write request and it failed in the middle of operation. Then checksum in file header will be valid, but contents of file are not.
One can think that we should move magic number to the end of such chunk, but who said that data starts to be written from begin to end and not from end to begin?
Even so, what happens if data in the middle of page will be corrupted?
Magic number will not detect this, so we need some small digest of our chunk.
We will use it to compare our stored data with those that we have read to ensure integrity.
This small digest called checksum. This is just small fixed-sized byte array computed using some hash functions over all contents of file.
Checksum can be stored both at the begginning and at the end of chunk.
If you have such choice, I recommend store it in the end - data locality: page (OS) with high probability will be already in cache (same for cpu cache, L1/2/3).
Checksum is widely used:
- Postgres - uses CRC32C for WAL records:
Postgres WAL CRC
typedef struct XLogRecord
{
// ...
pg_crc32c xl_crc; /* CRC for this record */
} XLogRecord;
- etcd - uses CRC for WAL records
etcd sliding crc
type Record struct {
Crc uint32 `protobuf:"varint,2,opt,name=crc" json:"crc"`
}
- KurrentDB (formerly EventStore) - uses MD5
EventStore MD5
public class ChunkFooter {
// ...
public readonly byte[] MD5Hash;
// ...
}
File System consistency model
Before going ahead, we should talk about consistency model.
In programming languages there is such a thing as "memory model".
In short, our program can be described in terms of store/load operations (assign value to a variable/read variable's value) and memory model describes which operations can be reordered (more accurately, which reoderings are prohibited).
Such reordering can give some performance improvements, but when we are moving to multi-threaded/concurrent execution these reorderings can spoil everything.
Given example:
void function() {
// 1
a = 123;
b = 244;
// 2
int c = a;
b = 555;
}Questions:
- In 1 case - are we allowed to write
band only thena, so perform store/store reordering - In 2 case, are we allowed to write
band only then read froma, so perform store/load reodering.
The memory order answers these questions. For PLs and hardware there is documentation with memory model explanation:
Let's leave programming languages for later. The main thing is that we can define such rules for the file system as well.
This is called persistency semantics (name from this paper).
Study "All File Systems Are Not Created Equal" identified these "basic" operations:
- File chunk overwrite
- Append data to file
- Rename
- Directory operations
After conducting the experiment, this table was compiled:
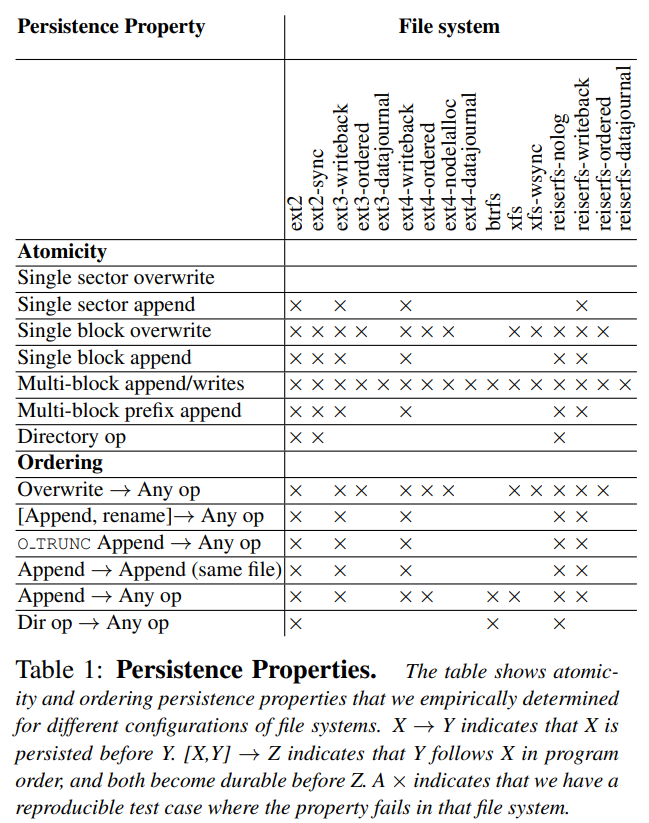
Also note, that table shows only found bugs - if bug is not found, it does not mean that is does not exist.
For simplicity, I will continue use term "journaled" for file systems that have some kind of buffer, in which all operations stored before being applied - COW, log-structured, journaled and so on.
Atomicity
Single logical operation may consists of multiple physical operations. For example, append to a file (write to end) consists of:
- Update size of file
- Add new data block
Atomicity in that case means transactional atomicity, like in databases - if we fail to perform even single operation, we must be able rollback state to the initial (with same metadata).
We can draw the following conclusions:
- No file system can atomically append some data blocks to file (except single block)
- Overwrite of 1 disk sector is atomic
- Non-journaled file system almost always do not provide atomicity of operations
- Directory operations almost always atomic, except non-journaled file systems
What happens in case of failure during non-atomic operation?
The worst case - file system will be corrupted and you will have to run fsck (and pray to God it will be fixed).
As for files:
- There will be garbage in file (in case of apppend) - just allocated new block and updated length
- Part on block will be overwritten - overwrite operation failed in the middle
The same study also presented comparison matrix of behaviour in case of failure during some common file operation patterns.
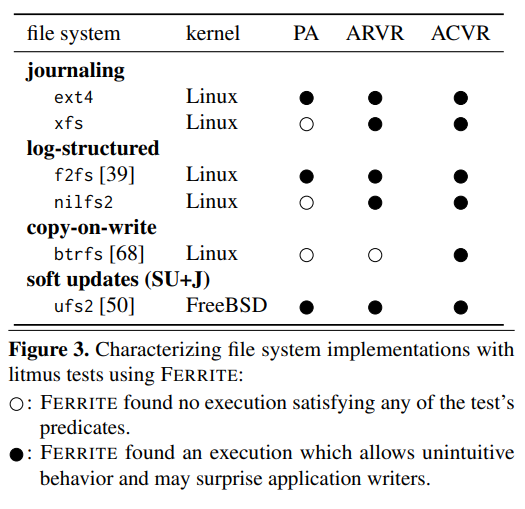
Legend:
-
PA(Prefix Append) - safe append of new data bloc{ks -
ARVR(Atomic Replace Via Rename) - rename file to update large amount of data -
ACVR(Atomic Create Via Rename) - create new file with initialized contents by renaming file
As you can see each file system is not perfect and can become inconsistent in case of interruption during operation.
Study covered behaviour for You can see, that there is no After application reboot we observe that file is empty, because only To fix this, we should add But, file system developers known about this pattern and add some hacks (to flush data to disk before And the last question - is If newpath already exists, it will be atomically replaced, so that there is no point at which another process attempting to access newpath will find it missing. So, If newpath exists but the operation fails for some reason, rename() guarantees to leave an instance of newpath in place. That means, that in case of errors, contents in In GNU C documentation I have found the following behaviour description: If there is a system crash during the operation, it is possible for both names to still exist; but newname will always be intact if it exists at all. Finally - target file (which is replaced) does not changes in case of failure. So, conlusion: Important ARVR/ACVR assumption made
ACVR/ARVR and showed that even these operation can be non-atomic.
But, then there was a note - there is no fsync call in those experments.
Take a look at tests specification:
# Atomic Replace Via Rename (ARVR)
initial:
g <- creat("file", 0600)
write(g, old)
main:
f <- creat("file.tmp", 0600)
write(f, new)
rename("file.tmp", "file")
exists?:
content("file") 6= old ^ content("file") 6= new
# Atomic create via rename (ACVR)
main:
f <- creat("file.tmp", 0600)
write(f, data)
rename("file.tmp", "file")
exists?:
content("file") 6= ∅ ^ content("file") 6= datafsync call between write and rename. What is happening:
rename operation performed on empty file.fsync call before rename.rename):
auto_da_alloc
flushoncommit (description took from here, but wiki is archieved, so I do not known whether it is true anymore)the sync-after-rename behaviour was suggested and rejected for xfs
rename itself atomic?
Of course, we can write data to temporary file, fsync it, but what the point if everything breaks during rename call?
Documentation says the following:
rename is "atomic" only from multi-*process*ing point of view, but not fault-tolerance.
Then, we find:
newpath stay the same.
But still, no information about fault-tolerance.
rename is atomic, but you should call fsync before to guarantee, that new data actually present on disk and file is not empty/half-full.
Reorderings
As for operations reordering, we can make such conclusion: if file system is journaled, then order of operations in most cases is preserved.
But that's not true for ext2, ext3-writeback, ext4-writeback, reiserfs-writeback so operations can be reordered.
Also, do not forget about directory operations - they are handled in the same way as regular file operations.
That means, that if we are writing to a file and then rename, actual operations can be rename empty file and start appending data blocks.
All file systems can do this, so always call fsync!
Write barrier
In memory model there is a definition of "write barrier" - machanism, that prohibit reordering of store/load operations.
As you can notice, file systems also have such machanism - it is fsync.
We can give such semantics:
All write operations happens before
fsync(for same file)
We can say nothing about reordering of write operations before fsync, but definetely say - not after fsync.
Actually, fsync is not real barrier, just we can use such semantics for it.
But similar discussion has been raised - there was suggestion to add fbarrier syscall, but Linus rejected this idea, considering that it will add unnecessary complexity.
Other file systems
Previous studyings were oriented primarly on widely-used *nix file systems, but of course there are many others.
NTFS
NTFS - is a "standard" file system on Windows. I didn't find any research about it's fault tolerance.
The only I can do is draw conclusions based on file system properties:
- Only metadata is journaled - there may be garbage in files after operations
- Metadata is duplicated - in case of some hardware fault, you always have a "second chance" to recover it
- Have it's own transactional API (TxF), but developers should not use it
APFS
APFS (Apple File System) - file system for Apple, which should replace HFS+.
According to papers and blogs (everything that I could find):
- Uses Copy on write (not journaling) - main reason because it fits well for SSD
- Have
Atomic Safe-Savetechnique to guarantee atomicrename - Uses checksums for metadata only, but not user data
I have highlighted last point specifically, because I didn't understand the article I relied on.
It states:
apfs doesn’t checksum data because “[apfs] engineers contend that Apple devices basically don’t return bogus data”
But, if you go to the referenced article, you will see:
APFS checksums its own metadata but not user data
The misunderstanding is caused by the fact that in referenced article there was comparison with ZFS (which have checksum for user data), but in first - there is no mention about this.
Appliction fsync error handling
In previous section we were talking about fsync and it's errors. We saw how OS handles fsync errors (in my optinion, fsync should be special function in interface of a file system driver, so OS also should handle such error), but how real applications respond to errors?
Here we will use paper "Can Applications Recover from fsync Failures?". The title is selfdescriptive - this paper shows how different software and file systems behaves when encounters an error returned by fsync.
First table shows behaviour of file system:

ext4 data - means journaled mode
This table says:
-
fsyncerrors arise only during writing of data blocks or journal. But for metadata errors behaviour differs: xfs and btrfs will be remounted in read-only mode, and ext4 just log it (to OS) and continue to work - When error occurres during data block writing, metadata will not rollback. So size can be increased, but content of file will contain garbage.
- After file system recover in runtime (error occurred and file system driver has been unloaded and loaded), state in memory can left unmodifed. In example, there is btrfs - after recovery, metadata can be changed, but file descriptor is old and points to a position in file outside of it.
All file systems mark pages "clean" but that because tests were run on Linux
The next table shows behaviour of applications in case of fsync error arising:

Legend:
- OV (old value) - return old value, instead of new
- FF (false failure) - return user error, but actually it's ok
- KC/VC (ke/value corruption) - data was corrupted (tests were run on key-value storage)
- KNF (key not found) - return user that all ok, but new value not saved (get lost)
We can make such conclusions:
- If an
fsyncerror occurres not immediately, then error amount increases - COW file systems better handle
fsyncerrors, compared to regular journaled - Many applications in case of
fsyncerror just halt and rollback to previous state (-and|in table)
Storage
And the last layer - persistent storage. We will talk about HDD and SSD.
They have different storage technologies under the hood, but now we are focused on their parameters:
- Time to failure
- ECC (error correction codes)
- Access controller
There are other storage devices beside HDD and SSD. For example: We will not talk about them in the rest part, but mention here. Tape drives seems ideal option for backup storage. Compared to HDD, tape drives has more longevity and capacity/cost fraction. But they are not suitable for modern workloads with lots of random access. CD/DVD/Blu-ray disks also not forgotten. According to this research sales of optical disks only increasing. Also, there are some technologies like PCM (Phase-Change Memory), FRAM (Ferroelectric RAM) and MRAM (Magnetoresistive RAM). I couldn't find enough information on them, so I won't say anything so as not to misinform.Beyond HDD and SSD
Again, optical disks are not well suited for extensive workloads.
Time to failure
Every piece of equipment wears out. In case of processing hardware (CPU or GPU) will break down, we just replace it and that's all.
But, if our persistence will break down, we might loose data. Blackbaze released a report for 2023 year with disk failure statistics. We can draw such conclusions:
- AFR (Annualized Failure Rate) depends on many factors. For example, vendor and disk size, but average across the board is about 65 months (5.5 years)
- Compared to 2022 year AFR increased
As for SSD, they have report for 2022. According to it, AFR for SSD - 0.92% (lower than HDD). But take into account, that SSD was took into operations only in 2018 year, so statistics can be not accurate.
Now, something about the impact of physical world on HDD/SSD operations:
- HDD has more moving parts, so it is more susceptible to physical damage. There is a bright example - "Shouting in the Datacenter". This video shows that even such small action is enough to affect HDD - response time increases. Digging deeper, this study analyzed the effect of noise on HDD operations - HDD was forced to work in noise (ADoS - Acoustice Denial of Service). As a result, positioning errors rate increases and sometimes there are disk failures occurred.
- SSD, on the other hand, does not have moving parts, but it heavily relies on elictricity. It is very sensible to sudden power outage! This research have tested behaviour of SSD for such power outage. And suddenly, such sudden power outage can lead to: data integrity violation, data loss or even trun SSD into a brick.
ECC
Often, HDD and SSD has builtin support for ECC - Error Correction Codes.
- HDD supports Advanced Format layout. It allows to store ECC for whole sector. But, this requires additional support from OS (nowadays almost everyone support this). Also note, that file systems can know about Advanced Format and can adjust to it, but this is out of article's scope.
- SSD also has such support, but only for NAND storage technology and NOR (for microcontrollers). But this is supported at storage level, not OS.
But ECC is much smaller than stored data, so sometimes it will not be able to fix all errors. In this study compared HDD and SSD lifecycles (using their own tests). Next plots show how many Uncorrectable Errors (UE) occurred until disk failure - errors, that ECC can not handle.
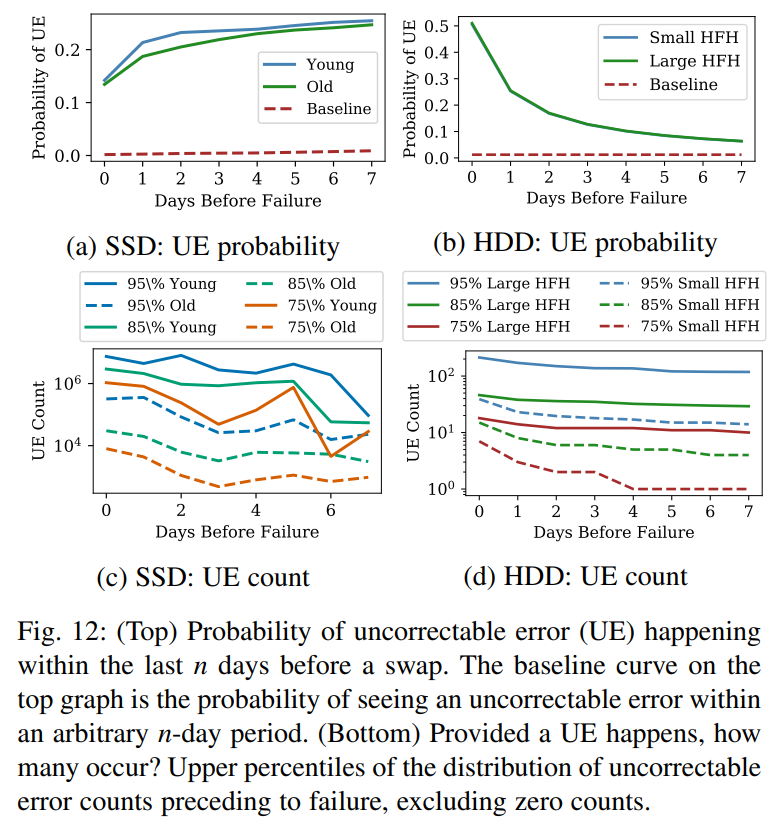
Conclusions:
- Amount of UE in SSD depends on lifetime of disk, whereas HDD depends on head flying hours.
- Amount of errors on HDD increases dramatically 2 days before failure.
- Amount of UE on SSD is higher, than on HDD.
Principal conclusion: modern hardware (with modern OS) have ECC, but we should not rely on it heavily.
P.S. point 1 - is another reason to consider data locality (the longer HDD's lifetime, the less disk head moves)
Access controller
Last component - is a disk access controller. It is stored in disk itself and handles all requests to disk. Important detail here - is a disk cache.
Recall fsync - it must make sure all changes were flush to disk. But if you look more closely to it's man, you will see:
The fsync() implementations in older kernels and lesser used filesystems do not know how to flush disk caches. In these cases disk caches need to be disabled using hdparm(8) or sdparm(8) to guarantee safe operation.
In old kernel versions (for Linux it's less than 2.2) fsync did not know how to correctly flush disk cache, just as some filesystems. According to blog article "Ensuring data reaches disk" there is barrier mount option for ext3/4, btfs and xfs filesystems that enables barriers (disk cache flushing).
I have researched some Linux kernel code and figured out, that only "readonly" filesystems do not have fsync implementation (i.e. efs and isofs do not register custom fsync).
Also, there is a generic fsync implementation (i.e. for non-journaled file systems)
HFS fsync implementation
// https://github.com/torvalds/linux/blob/a4145ce1e7bc247fd6f2846e8699473448717b37/block/bdev.c#L203
/*
* Write out and wait upon all the dirty data associated with a block
* device via its mapping. Does not take the superblock lock.
*/
int sync_blockdev(struct block_device *bdev)
{
if (!bdev)
return 0;
return filemap_write_and_wait(bdev->bd_inode->i_mapping);
}
EXPORT_SYMBOL(sync_blockdev);
// https://github.com/torvalds/linux/blob/a4145ce1e7bc247fd6f2846e8699473448717b37/mm/filemap.c#L779
/**
* file_write_and_wait_range - write out & wait on a file range
* @file: file pointing to address_space with pages
* @lstart: offset in bytes where the range starts
* @lend: offset in bytes where the range ends (inclusive)
*
* Write out and wait upon file offsets lstart->lend, inclusive.
*
* Note that @lend is inclusive (describes the last byte to be written) so
* that this function can be used to write to the very end-of-file (end = -1).
*
* After writing out and waiting on the data, we check and advance the
* f_wb_err cursor to the latest value, and return any errors detected there.
*
* Return: %0 on success, negative error code otherwise.
*/
int file_write_and_wait_range(struct file *file, loff_t lstart, loff_t lend)
{
int err = 0, err2;
struct address_space *mapping = file->f_mapping;
if (lend < lstart)
return 0;
if (mapping_needs_writeback(mapping)) {
err = __filemap_fdatawrite_range(mapping, lstart, lend,
WB_SYNC_ALL);
/* See comment of filemap_write_and_wait() */
if (err != -EIO)
__filemap_fdatawait_range(mapping, lstart, lend);
}
err2 = file_check_and_advance_wb_err(file);
if (!err)
err = err2;
return err;
}
EXPORT_SYMBOL(file_write_and_wait_range);
// https://github.com/torvalds/linux/blob/a4145ce1e7bc247fd6f2846e8699473448717b37/fs/hfs/inode.c#L661
static int hfs_file_fsync(struct file *filp, loff_t start, loff_t end,
int datasync)
{
// ...
file_write_and_wait_range(filp, start, end);
// ...
sync_blockdev(sb->s_bdev);
// ...
return ret;
}
Again, access controller is not bad thing. For example, it allows SSD to live longer by smart utilizing blocks as they have limited number or P/E cycles (roughly speaking, access controller plays more crucial part in SSD than HDD).
Persistence properties
At the end, let's talk about persistence properties provided by HDD and SSD: atomicity and PowerSafe OverWrite.
Atomicity
IO is very slow, compared to other operations. Here reference to "Latency Numbers every programmer should know" (extended version by year) - even for 2020 year HDD spends 2ms just for seek.
As we can not eliminate disk seeks (from HDD) or increase memory cells (for SSD) the only thing we can do is to add some optimizations. Main optimization is to batch operations by blocks. So, even when you request to read/write single byte actually you will read/write whole block.
Today, we have 2 block sizes: 512 bytes and 4Kb. But for HDD name of such unit is "sector" and for SSD are "page" and "block" for read and write accordingly.
Reading can not corrupt data, but write can, so we will focus primarly on write operations, so use "unit for write".
There is already an answer to such question on StackOverflow:
a sector write sent by the kernel is likely atomic
But under conditions:
- Access controller has a spare battery (if power outage occurres during operations)
- SCSI disk vendor gives guarantees for write atomicity
- (for NVMe) special atomic write function is called
That sounds quite logical, so I'll believe it.
PowerSafe OverWrite
PowerSafe OverWrite (PSOW) - is a term, used by SQLite developers to describe behaviour of file systems and disk in case of sudden power outage.
The meaning is as follows:
When an application writes a range of bytes in a file, no bytes outside of that range will change, even if the write occurs just before a crash or power failure.
Practically, it means that there is a spare battery in disk that will be used to safe write remaining data. If there is no such thing, then when we write single unit of write (either or both):
- One part of write range will contain new data and another old
- Part of same sector that not in write range will contain garbage
At first glance, one can think atomicity and PowerSafe OverWrite are same, but that's not true. For example let's imagine such situation - we want to overwrite part of file and during write operation power outage occurred. Depending on different combinations of properties, we can get different consequences. To be specific, we have 3 sectors/unit of write which all contains 0 (old data) and we want to write range of 1. Then, we have situations: NOTE: data outside the sector is not affected/corrupted/changed How can this happen? For example, battery is enough to write that single page but only for it - when we finish writing that page, disk head will randomly walk, affecting stored data with remaining magnetic energy. Repository hashcorp/raft-wal have README with collected assumptions of different applications about persistence guarantees:Atomicity and PSOW are not the same
А Б В
Sectors: |000000000|000000000|000000000|
Write: |------------------|
| A: | 000011111 | 000000000 | 000000000 |
| --- |
| B: | 000000000 | 111111111 | 000000000 |
| --- |
| C: | 000000000 | 000000000 | 111100000 |
| --- |
| A: | 000011010 | 000000000 | 000000000 |
| --- |
| B: | 000000000 | 110011010 | 000000000 |
| --- |
| C: | 000000000 | 000000000 | 001000000 |
| --- |
| A: | 000011111 | 001011100 | 000000000 |
| --- |
| B: | 000000000 | 111111111 | 001000000 |
| --- |
| C: | 000001010 | 111000110 | 111100000 |
| --- |
| A: | 111111111 | 000000000 | 000000000 |
| --- |
| B: | 000000000 | 111111111 | 000000000 |
| --- |
| C: | 000000000 | 000000000 | 111111111 |
| --- |
You can think that's all, but we did not cover one important layer, that many modern programming langauges have - runtime.
Runtime
At the very beginning we went from PL to OS directly, but some languages have some managed layer - runtime:
- Runtime itself - Nodejs, .NET, JVM
- Interpreter - Python, Ruby
In case of C/C++ we can make syscall directly (just invoke fsync), but other langauges may have some abstraction layer. Now, we will talk about invoking fsync as it is necessary to ensure data is persisted.
For java it is very simple - function force(true). According to documentation:
Forces any updates to this channel's file to be written to the storage device that contains it.
So, we will not directly call fsync - we are programming in abstractions that runtime provides to us. So, the same is applied to .NET - class FileStream has overloaded method Flush(bool flushToDisk). When passing true all data must be flushed to disk:
Use this overload when you want to ensure that all buffered data in intermediate file buffers is written to disk. When you call the Flush method, the operating system I/O buffer is also flushed.
Again note - there is no word about fsync as it is platform-dependent implementation detail. But, I'm not used to blindly rely on words, so let's take a look at .NET source code - we file such piece of code (call chain):
FileStream.Flush call chain
public class FileStream
{
private readonly FileStreamStrategy _strategy;
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/libraries/System.Private.CoreLib/src/System/IO/FileStream.cs#L389
public virtual void Flush(bool flushToDisk)
{
if (_strategy.IsClosed)
{
ThrowHelper.ThrowObjectDisposedException_FileClosed();
}
_strategy.Flush(flushToDisk);
}
}
internal abstract class OSFileStreamStrategy : FileStreamStrategy
{
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/libraries/System.Private.CoreLib/src/System/IO/Strategies/OSFileStreamStrategy.cs#L137
internal sealed override void Flush(bool flushToDisk)
{
if (flushToDisk && CanWrite)
{
FileStreamHelpers.FlushToDisk(_fileHandle);
}
}
}
internal static partial class FileStreamHelpers
{
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/libraries/System.Private.CoreLib/src/System/IO/Strategies/FileStreamHelpers.Unix.cs#L40
internal static void FlushToDisk(SafeFileHandle handle)
{
if (Interop.Sys.FSync(handle) < 0)
{
Interop.ErrorInfo errorInfo = Interop.Sys.GetLastErrorInfo();
switch (errorInfo.Error)
{
case Interop.Error.EROFS:
case Interop.Error.EINVAL:
case Interop.Error.ENOTSUP:
// Ignore failures for special files that don't support synchronization.
// In such cases there's nothing to flush.
break;
default:
throw Interop.GetExceptionForIoErrno(errorInfo, handle.Path);
}
}
}
}
internal static partial class Interop
{
internal static partial class Sys
{
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/libraries/Common/src/Interop/Unix/System.Native/Interop.FSync.cs#L11
[LibraryImport(Libraries.SystemNative, EntryPoint = "SystemNative_FSync", SetLastError = true)]
internal static partial int FSync(SafeFileHandle fd);
}
}
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/native/libs/System.Native/pal_io.c#L736
int32_t SystemNative_FSync(intptr_t fd)
{
int fileDescriptor = ToFileDescriptor(fd);
int32_t result;
while ((result =
#if defined(TARGET_OSX) && HAVE_F_FULLFSYNC
fcntl(fileDescriptor, F_FULLFSYNC)
#else
fsync(fileDescriptor)
#endif
< 0) && errno == EINTR);
return result;
}
So, when we are passing true, then there is fsync must occur. But let's look what happens in reality. I have written such code for this and trace it with strace:
using var file = new FileStream("sample.txt", FileMode.OpenOrCreate);
file.Write("hello, world"u8);
file.Flush(true);Here is part of strace output:
openat(AT_FDCWD, "/path/sample.txt", O_RDWR|O_CREAT|O_CLOEXEC, 0666) = 19
lseek(19, 0, SEEK_CUR) = 0
pwrite64(19, "hello, world", 12, 0) = 12
fsync(19) = 0
flock(19, LOCK_UN) = 0
close(19) = 0Steps:
-
openat- open file and file descriptor is 19 -
lseek- position file at the very beginning -
pwrite64- our data is written -
fsync(19)-fsynccall happened -
close(19)- file is closed
That's all fine - fsync is called. But I used .NET 8.0.1 for that, next I wanted to test behaviour on another version - 7.0.11. Source code is the same but output is different:
openat(AT_FDCWD, "/path/sample.txt", O_RDWR|O_CREAT|O_CLOEXEC, 0666) = 19
lseek(19, 0, SEEK_CUR) = 0
pwrite64(19, "hello, world", 12, 0) = 12
flock(19, LOCK_UN) = 0
close(19) = 0There is no fsync! Moreover, if we call Flush(true) again it will appear and all subsequent calls will invoke fsync (add second Flush(true)):
openat(AT_FDCWD, "/path/sample.txt", O_RDWR|O_CREAT|O_CLOEXEC, 0666) = 19
lseek(19, 0, SEEK_CUR) = 0
pwrite64(19, "hello, world", 12, 0) = 12
fsync(19) = 0
flock(19, LOCK_UN) = 0
close(19) = 0So, I have concluded that first Flush(true) is ignored (for some reason, idk), but subsequent are not.
Also, I must note that developer often is limited to abstractions and programming model provided by runtime. Take .NET as an example again.
Remember that directories are also files and we must call fsync after operations. In .NET we can not open directories (Windows legacy):
-
Directoryclass does not haveOpenmethod (or someSync) - If we call
FileStreamwith directory path (even when specifying readonly mode), then we getUnauthorizedAccessException.
I have found a rough workaround - call open function using P/Invoke, get directory file descriptor and wrap it with SafeFileHandle. In this case, there is no excpetion and we can use fsync.
var directory = Directory.CreateDirectory("sample-directory");
const int directoryFlags = 65536; // O_DIRECTORY | O_RDONLY
var handle = Open(directory.FullName, directoryFlags);
using var stream = new FileStream(new SafeFileHandle(handle, true), FileAccess.ReadWrite);
stream.Flush(true);
[DllImport("libc", EntryPoint = "open")]
static extern nint Open(string path, int flags);Here is strace output:
openat(AT_FDCWD, "/path/sample-directory", O_RDONLY|O_DIRECTORY) = 19
lseek(19, 0, SEEK_CUR) = 0
lseek(19, 0, SEEK_CUR) = 0
fsync(19) = 0
close(19) = 0Key takeways
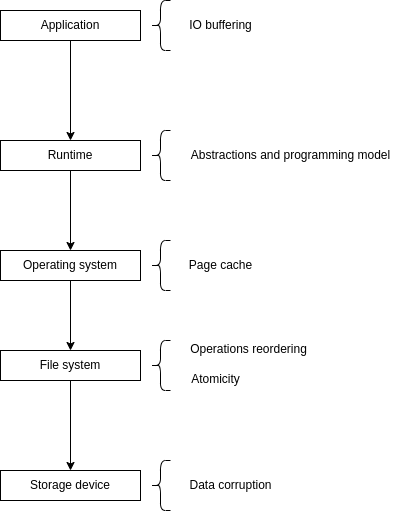
To sum up, we can see that IO stack has multiple details that we must take into account to ensure data integrity. Each layer has own semantics and characteristics.
Neglecting them means neglecting our data: data corruption, data loss, garbage occurrence and other unpleasant events.
Here a small diagram briefly summarizing all above:
File operations patterns
After considering possible problems, that can arise during operations with files, let's consider opposite - how to fight with these problems.
As a developers we create huge systems with lots of connected subsystems. The most illustrative example is a database (persistent, not in-memory).
So most of example implementation will be given in DBMSs source code.
Create new file
Let's kick off from the very beginning - creating a new file.
If we want a new empty file then we should just call fsync on parent directory after we have created it:
-
creat("/dir/data")- create new file -
fsync("/dir")- sync directory's contents
Initially, file is empty, but what if file must have initial data, i.e. header with metadata. As we have seen, just fsync is not enough because if operation is interrupted then file either will not exist or will be half-full (which is not acceptable).
We already have seen such pattern - Atomic Create Via Rename. Again, the title is selfdescriptive - to create initialized file we need to swap it (rename) with another initialized file.
Algorithm is the following:
-
creat("/dir/data.tmp")- create temporary file -
write("/dir/data.tmp", new_data)- write required data to it -
fsync("/dir/data.tmp")- flush contents of temporary file to disk -
fsync("/dir")- flush updates to parent directory -
rename("/dir/data.tmp", "/dir/data")- rename (replace) temporary file with target one -
fsync("/dir")- flush rename to parent directory
Pratical example: creation of new log segment (file with operations being performed on data) in etcd:
I have commented steps of our defined algorithm with numbers. As you can see, steps performed in same sequence. Also, target file is reopened in the end. This is done to correctly display target filename, not temporary (does not affect correctness).Creation of new log segment file in etcd
// cut closes current file written and creates a new one ready to append.
// cut first creates a temp wal file and writes necessary headers into it.
// Then cut atomically rename temp wal file to a wal file.
func (w *WAL) cut() error {
// Название для нового файла сегмента
fpath := filepath.Join(w.dir, walName(w.seq()+1, w.enti+1))
// 1. Create temporary file
newTail, err := w.fp.Open()
if err != nil {
return err
}
// 2. Write data to temporary file
// update writer and save the previous crc
w.locks = append(w.locks, newTail)
prevCrc := w.encoder.crc.Sum32()
w.encoder, err = newFileEncoder(w.tail().File, prevCrc)
if err != nil {
return err
}
if err = w.saveCrc(prevCrc); err != nil {
return err
}
if err = w.encoder.encode(&walpb.Record{Type: MetadataType, Data: w.metadata}); err != nil {
return err
}
if err = w.saveState(&w.state); err != nil {
return err
}
// atomically move temp wal file to wal file
// 3-4. Flush file data to disk
if err = w.sync(); err != nil {
return err
}
// 5. Rename temporary file to target
if err = os.Rename(newTail.Name(), fpath); err != nil {
return err
}
// 6. Flush "rename" of parent directory to disk
if err = fileutil.Fsync(w.dirFile); err != nil {
return err
}
// reopen newTail with its new path so calls to Name() match the wal filename format
newTail.Close()
if newTail, err = fileutil.LockFile(fpath, os.O_WRONLY, fileutil.PrivateFileMode); err != nil {
return err
}
w.locks[len(w.locks)-1] = newTail
prevCrc = w.encoder.crc.Sum32()
w.encoder, err = newFileEncoder(w.tail().File, prevCrc)
if err != nil {
return err
}
return nil
}
File modification
File is created and now we must make some modifications - write new data to it or update (overwrite) existing. Here we have 2 options:
Change of a small file
If our file is small enough, then we can apply sibling of previous pattern - Atomic Replace Via Rename (btrfs call this overwrite-by-rename). Algorithm is almost the same:
-
creat("/dir/data.tmp")- create temporary file -
write("/dir/data.tmp", new_data)- write new data to it -
fsync("/dir/data.tmp")- flush data to disk -
fsync("/dir")- update parent directory contents (new file creation) -
rename("/dir/data.tmp", "/dir/data")- rename (replace) old file with a new one -
fsync("/dir")- update parent directory contents (file rename)
Earlier I said that some file systems can detect this pattern and perform fsync themselves. But as a developers we target on multiple systems and do not rely on specific tehnologies - specific file system features in this case.
Pratical example: LevelDB flush memtable to disk.
LevelDB stores data in memory using special MemTable. When it becomes too big it is flushed to disk - this is called "Compaction" Steps performed the same. Also, if you saw the code, you could mention usage of macOS specific - it requires usage of LevelDB flush memtable to disk
// https://github.com/google/leveldb/blob/068d5ee1a3ac40dabd00d211d5013af44be55bea/db/db_impl.cc#L549
void DBImpl::CompactMemTable() {
// ...
// Replace immutable memtable with the generated Table
if (s.ok()) {
edit.SetPrevLogNumber(0);
edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed
s = versions_->LogAndApply(&edit, &mutex_); // Versionset->LogAndApply
}
// ...
}
// https://github.com/google/leveldb/blob/068d5ee1a3ac40dabd00d211d5013af44be55bea/db/version_set.cc#L777
Status VersionSet::LogAndApply(VersionEdit* edit, port::Mutex* mu) {
// 1. Create new state - apply patches to current state (in-memory for now)
Version* v = new Version(this);
{
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
}
Finalize(v);
// Initialize new descriptor log file if necessary by creating
// a temporary file that contains a snapshot of the current version.
std::string new_manifest_file;
Status s;
if (descriptor_log_ == nullptr) {
// 2. Create temporary file
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
s = env_->NewWritableFile(new_manifest_file, &descriptor_file_);
if (s.ok()) {
// 3. Write data (new snapshot) to temporary file
descriptor_log_ = new log::Writer(descriptor_file_);
s = WriteSnapshot(descriptor_log_);
}
}
{
if (s.ok()) {
// 4. Flush data to disk
s = descriptor_file_->Sync();
}
// If we just created a new descriptor file, install it by writing a
// new CURRENT file that points to it.
if (s.ok() && !new_manifest_file.empty()) {
// 5. Rename temporary file to target
s = SetCurrentFile(env_, dbname_, manifest_file_number_);
}
mu->Lock();
}
return s;
}
// https://github.com/google/leveldb/blob/068d5ee1a3ac40dabd00d211d5013af44be55bea/util/env_posix.cc#L334
class PosixWritableFile: public WritableFile {
public:
Status Sync() override {
Status status = SyncDirIfManifest();
status = FlushBuffer();
return SyncFd(fd_, filename_);
}
private:
static Status SyncFd(int fd, const std::string& fd_path) {
#if HAVE_FULLFSYNC
// On macOS and iOS, fsync() doesn't guarantee durability past power
// failures. fcntl(F_FULLFSYNC) is required for that purpose. Some
// filesystems don't support fcntl(F_FULLFSYNC), and require a fallback to
// fsync().
if (::fcntl(fd, F_FULLFSYNC) == 0) {
return Status::OK();
}
#endif // HAVE_FULLFSYNC
#if HAVE_FDATASYNC
bool sync_success = ::fdatasync(fd) == 0;
#else
bool sync_success = ::fsync(fd) == 0;
#endif // HAVE_FDATASYNC
if (sync_success) {
return Status::OK();
}
return PosixError(fd_path, errno);
}
}
// https://github.com/google/leveldb/blob/068d5ee1a3ac40dabd00d211d5013af44be55bea/db/filename.cc#L123
Status SetCurrentFile(Env* env, const std::string& dbname,
uint64_t descriptor_number) {
// ...
if (s.ok()) {
// Rename temporary file to target
s = env->RenameFile(tmp, CurrentFileName(dbname));
}
return s;
}fcntl instead of fsync.
UNDO log
This example is given for a small file, but what if file is large or free disk space is low?
So far we saw many atomic operations + fsync and now we will use them to create atomic file overwrite. But what does mean "atomically" here? Actually, we can go in both directions: undo operation (rollback operation) and reapply new operation (redo operation). Thus, we come to the 2 main conceptions:
- UNDO log - contains information about how to rollback to previous state if operation fails
- REDO log - contains information about what operation we wanted to perform in order to redo it if some failure occurred
First, we describe UNDO log and REDO log come after.
Undo log contains information to rollback operations. In case of file rewrite it can store original data that we are overwriting. So, after restart (there is a failure occurred) we check for some incomplete operation in that log and undo them.
Example for undo/redo log is borrowed from "Files Are Hard".
Our example is following: we want to write new data (new_data) starting from 10 byte (start) with length of 15 bytes (length), so undo log will contain bytes from 10 to 25 of original data (old_data).
Algorithm is the following:
-
creat("/dir/undo.log")- create undo log -
write("/dir/undo.log", "[check_sum, start, length, old_data]")- store original data, that we want to overwrite:-
start- start position -
length- length of byte range -
old_data- actual data in that range -
check_sum- chech-sum, computed for the data
-
-
fsync("/dir/undo.log")- persist undo log on disk -
fsync("/dir")- sync parent directory contents (undo log creation) -
write("/dir/data", new_data)- overwrite original file -
fsync("/dir/data")- flush file updates to disk -
unlink("/dir/undo.log")- remove undo log -
fsync("/dir")- sync parent directory contents (undo log deletion)
What is taken into account in this example:
- Fault can occur even right after UNDO log creation or data can be corrupted during reboot - so store checksum of that stored data
- Always call
fsynceven for undo log - without this undo log can disappear after we have modified main data file - Call
fsynceven after deletion of undo log - otherwise we would think that operation was not completed at time of halt and perform rollback
Actually, you do not need to constantly create and remove undo log - you can just create it once and use special markers to detect that operation is completed successfully.
But you still need to callfsyncwhen performing changes in that file.
At this time you have probably already figured out how to rollback:
- Check undo-log existence (or there are some operations "in-progress")
- Check correctness of records (checksums)
- Find all undo operations (start byte, length, data)
- Write that original data
- Remove undo-log (mark operations "aborted")
- Flush changes to disk
Even if there is another fault during rollback we always can retry because our algorithm is idempotent (additionally, you should consider atomicity and PSOW).
SQLite developers use undo log and developed 2 optimizations (as new file creation is a costly operation):
- Truncate file after operation is complete:
PRAGMA journal_mode=TRUNCATE - Set file header to all 0 -
PRAGMA journal_mode=PERSIST
Practical example: undo log in SQLite
This algorithm is described in documentation - Atomic Commit In SQLiteSQLite undo log
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/btree.c#L4388
int sqlite3BtreeCommit(Btree *p){
int rc;
// First phase - create log and update data in database file
rc = sqlite3BtreeCommitPhaseOne(p, 0);
if( rc==SQLITE_OK ){
// Second phase - remove/trancate/nullify log
rc = sqlite3BtreeCommitPhaseTwo(p, 0);
}
return rc;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/btree.c#L4267
int sqlite3BtreeCommitPhaseOne(Btree *p, const char *zSuperJrnl){
int rc = SQLITE_OK;
if( p->inTrans==TRANS_WRITE ){
rc = sqlite3PagerCommitPhaseOne(pBt->pPager, zSuperJrnl, 0);
}
return rc;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L6437
int sqlite3PagerCommitPhaseOne(
Pager *pPager, /* Pager object */
const char *zSuper, /* If not NULL, the super-journal name */
int noSync /* True to omit the xSync on the db file */
){
int rc = SQLITE_OK; /* Return code */
if( 0==pagerFlushOnCommit(pPager, 1) ){
// ...
}else{
if( pagerUseWal(pPager) ){
// ...
}else{
// 1. Save original data to log
rc = pager_incr_changecounter(pPager, 0);
// 2. Sync data to disk (call fsync)
rc = syncJournal(pPager, 0);
if( rc!=SQLITE_OK ) goto commit_phase_one_exit;
// 3. Write updated data to main database file
pList = sqlite3PcacheDirtyList(pPager->pPCache);
if( /* ... */ ){
rc = pager_write_pagelist(pPager, pList);
}
if( rc!=SQLITE_OK ) goto commit_phase_one_exit;
// 4. Flush main database file to disk
if( /* ... */ ){
rc = sqlite3PagerSync(pPager, zSuper);
}
}
}
commit_phase_one_exit:
return rc;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L4259
static int syncJournal(Pager *pPager, int newHdr){
int rc; /* Return code */
if( /* ... */ ){
if( /* ... */ ){
if( /* ... */ ){
// Write total amount of pages equal to 0 (just in case)
if( rc==SQLITE_OK && 0==memcmp(aMagic, aJournalMagic, 8) ){
static const u8 zerobyte = 0;
rc = sqlite3OsWrite(pPager->jfd, &zerobyte, 1, iNextHdrOffset);
}
if( /* ... */ ){
// Flush written data
rc = sqlite3OsSync(pPager->jfd, pPager->syncFlags);
if( rc!=SQLITE_OK ) return rc;
}
// Write header with metadata
rc = sqlite3OsWrite(
pPager->jfd, zHeader, sizeof(zHeader), pPager->journalHdr
);
if( rc!=SQLITE_OK ) return rc;
}
if( /* ... */ ){
// Flush data to disk again
rc = sqlite3OsSync(pPager->jfd, pPager->syncFlags|
(pPager->syncFlags==SQLITE_SYNC_FULL?SQLITE_SYNC_DATAONLY:0)
);
if( rc!=SQLITE_OK ) return rc;
}
}else{
pPager->journalHdr = pPager->journalOff;
}
}
return SQLITE_OK;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L6372
int sqlite3PagerSync(Pager *pPager, const char *zSuper){
int rc = SQLITE_OK;
if( /* ... */ ){
// fsync
rc = sqlite3OsSync(pPager->fd, pPager->syncFlags);
}
return rc;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/btree.c#L4356
int sqlite3BtreeCommitPhaseTwo(Btree *p, int bCleanup){
if( p->inTrans==TRANS_WRITE ){
int rc;
rc = sqlite3PagerCommitPhaseTwo(p->pBt->pPager);
if( rc!=SQLITE_OK && bCleanup==0 ){
sqlite3BtreeLeave(p);
return rc;
}
}
return SQLITE_OK;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L6674
int sqlite3PagerCommitPhaseTwo(Pager *pPager){
int rc = SQLITE_OK; /* Return code */
rc = pager_end_transaction(pPager, pPager->setSuper, 1);
return pager_error(pPager, rc);
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L2033
static int pager_end_transaction(Pager *pPager, int hasSuper, int bCommit){
int rc = SQLITE_OK;
int rc2 = SQLITE_OK;
if( isOpen(pPager->jfd) ){
if( sqlite3JournalIsInMemory(pPager->jfd) ){
// ...
}else if( pPager->journalMode==PAGER_JOURNALMODE_TRUNCATE ){
// PRAGMA journal_mode=TRUNCATE
// Truncate file to 0
if( pPager->journalOff==0 ){
rc = SQLITE_OK;
}else{
rc = sqlite3OsTruncate(pPager->jfd, 0);
if( rc==SQLITE_OK && pPager->fullSync ){
rc = sqlite3OsSync(pPager->jfd, pPager->syncFlags);
}
}
pPager->journalOff = 0;
}else if( pPager->journalMode==PAGER_JOURNALMODE_PERSIST){
// PRAGMA journal_mode=PERSIST
// Nullify header
rc = zeroJournalHdr(pPager, hasSuper||pPager->tempFile);
pPager->journalOff = 0;
}else{
// PRAGMA journal_mode=DELETE
// Remove undo log file
int bDelete = !pPager->tempFile;
sqlite3OsClose(pPager->jfd);
if( bDelete ){
rc = sqlite3OsDelete(pPager->pVfs, pPager->zJournal, pPager->extraSync);
}
}
}
// ...
return (rc==SQLITE_OK?rc2:rc);
}
// sqlite3OsDelete implementation for *nix
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/os_unix.c#L6533
static int unixDelete(
sqlite3_vfs *NotUsed, /* VFS containing this as the xDelete method */
const char *zPath, /* Name of file to be deleted */
int dirSync /* If true, fsync() directory after deleting file */
){
int rc = SQLITE_OK;
// Remove file itself
if( osUnlink(zPath)==(-1) ){
rc = unixLogError(SQLITE_IOERR_DELETE, "unlink", zPath);
return rc;
}
// Sync directory contents
if( (dirSync & 1)!=0 ){
int fd;
rc = osOpenDirectory(zPath, &fd);
if( rc==SQLITE_OK ){
// "Improved fsync"
if( full_fsync(fd,0,0) ){
rc = unixLogError(SQLITE_IOERR_DIR_FSYNC, "fsync", zPath);
}
}else{
rc = SQLITE_OK;
}
}
return rc;
}
// "Improved fsync" - is just fsync that counts in specifics of some OS
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/os_unix.c#L3638
static int full_fsync(int fd, int fullSync, int dataOnly){
int rc;
/* If we compiled with the SQLITE_NO_SYNC flag, then syncing is a
** no-op. But go ahead and call fstat() to validate the file
** descriptor as we need a method to provoke a failure during
** coverage testing.
*/
#ifdef SQLITE_NO_SYNC
{
struct stat buf;
rc = osFstat(fd, &buf);
}
#elif HAVE_FULLFSYNC
if( fullSync ){
rc = osFcntl(fd, F_FULLFSYNC, 0);
}else{
rc = 1;
}
/* If the FULLFSYNC failed, fall back to attempting an fsync().
** It shouldn't be possible for fullfsync to fail on the local
** file system (on OSX), so failure indicates that FULLFSYNC
** isn't supported for this file system. So, attempt an fsync
** and (for now) ignore the overhead of a superfluous fcntl call.
** It'd be better to detect fullfsync support once and avoid
** the fcntl call every time sync is called.
*/
if( rc ) rc = fsync(fd);
#elif defined(__APPLE__)
/* fdatasync() on HFS+ doesn't yet flush the file size if it changed correctly
** so currently we default to the macro that redefines fdatasync to fsync
*/
rc = fsync(fd);
#else
rc = fdatasync(fd);
#if OS_VXWORKS
if( rc==-1 && errno==ENOTSUP ){
rc = fsync(fd);
}
#endif /* OS_VXWORKS */
#endif /* ifdef SQLITE_NO_SYNC elif HAVE_FULLFSYNC */
if( OS_VXWORKS && rc!= -1 ){
rc = 0;
}
return rc;
}
REDO log
REDO log works similarly. The main difference is that we write to log new data instead of old.
-
creat("/dir/redo.log")- create new REDO log -
write("/dir/redo.log", "[check_sum, start, length, new_data]")- write new data to log:-
start- starting position of data -
length- length of new data -
new_data- new data being written -
check_sum- checksum for new data
-
-
fsync("/dir/redo.log")- flush new redo log file changes to disk -
fsync("/dir")- sync parent directory contents (create redo-log) -
write("/dir/data", new_data)- write new data to main file -
fsync("/dir/data")- flush changes of main file to disk -
unlink("/dir/redo.log")- remove redo-log (mark completed) -
fsync("/dir")- sync parent directory contents (remove redo-log)
Main advantage of REDO log, that is widely used by multiple dbms, is that we can return response to user right after we made record to redo-log (step 4).
We can be sure changes will be applied - later (flush to file in background) or during recovery.
As in the UNDO log here we can apply some optimizations. Again, main optimization is to persist this file instead of constant creation/deletions. When we perform commit we just mark record as applied (or can just create new special record that previous record is applied ~ "commit record").
REDO log has alternative name - WAL, Write Ahead Log.
Practical example: WAL in Postgres.
As I said, WAL is widely used in databases. It is used in Oracle, MySQL, Postgres, SQLite, SQL Server. This example is splited into 2 parts: Here we can see advantage that I have highlighted earlier - it's enough to make record in WAL to return response to user and continue processing other requests. Dirty page will be flushed to table file later, during checkpoint.WAL in Postgres
COMMIT - save data to WAL
// 1. "COMMIT;"
// https://github.com/postgres/postgres/blob/cc6e64afda530576d83e331365d36c758495a7cd/src/backend/access/transam/xact.c#L2158
static void
CommitTransaction(void)
{
// ...
RecordTransactionCommit();
// ...
}
// https://github.com/postgres/postgres/blob/97d85be365443eb4bf84373a7468624762382059/src/backend/access/transam/xact.c#L1284
static TransactionId
RecordTransactionCommit(void)
{
// ...
XactLogCommitRecord(GetCurrentTransactionStopTimestamp(),
nchildren, children, nrels, rels,
ndroppedstats, droppedstats,
nmsgs, invalMessages,
RelcacheInitFileInval,
MyXactFlags,
InvalidTransactionId, NULL /* plain commit */ );
// ...
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/backend/access/transam/xact.c#L5736
XLogRecPtr
XactLogCommitRecord(TimestampTz commit_time,
int nsubxacts, TransactionId *subxacts,
int nrels, RelFileLocator *rels,
int ndroppedstats, xl_xact_stats_item *droppedstats,
int nmsgs, SharedInvalidationMessage *msgs,
bool relcacheInval,
int xactflags, TransactionId twophase_xid,
const char *twophase_gid)
{
// ...
return XLogInsert(RM_XACT_ID, info);
}
XLogRecPtr
XLogInsertRecord(XLogRecData *rdata,
XLogRecPtr fpw_lsn,
uint8 flags,
int num_fpi,
bool topxid_included)
{
// ...
XLogFlush(EndPos);
// ...
}
// https://github.com/postgres/postgres/blob/dbfc44716596073b99e093a04e29e774a518f520/src/backend/access/transam/xlog.c#L2728
void
XLogFlush(XLogRecPtr record)
{
// ...
XLogWrite(WriteRqst, insertTLI, false);
// ...
}
// https://github.com/postgres/postgres/blob/dbfc44716596073b99e093a04e29e774a518f520/src/backend/access/transam/xlog.c#L2273
static void
XLogWrite(XLogwrtRqst WriteRqst, TimeLineID tli, bool flexible)
{
while (/* Have data to write */)
{
// 1. Create new WAL segment file or open existing
if (/* Размер сегмента превышен */)
{
openLogFile = XLogFileInit(openLogSegNo, tli);
}
if (openLogFile < 0)
{
openLogFile = XLogFileOpen(openLogSegNo, tli);
}
// 2. Write data to WAL
do
{
written = pg_pwrite(openLogFile, from, nleft, startoffset);
} while (/* Have data to write */);
// 3. Flush WAL to disk
if (finishing_seg)
{
issue_xlog_fsync(openLogFile, openLogSegNo, tli);
}
}
}
// https://github.com/postgres/postgres/blob/dbfc44716596073b99e093a04e29e774a518f520/src/backend/access/transam/xlog.c#L8516
void
issue_xlog_fsync(int fd, XLogSegNo segno, TimeLineID tli)
{
// fsync behaviour can be adjusted by GUC (configuration)
switch (wal_sync_method)
{
case WAL_SYNC_METHOD_FSYNC:
pg_fsync_no_writethrough(fd);
break;
case WAL_SYNC_METHOD_FSYNC_WRITETHROUGH:
pg_fsync_writethrough(fd);
break;
case WAL_SYNC_METHOD_FDATASYNC:
pg_fdatasync(fd);
break;
// ...
}
}
// 2. Flush "dirty" pages to disk, table file itself
// https://github.com/postgres/postgres/blob/97d85be365443eb4bf84373a7468624762382059/src/backend/storage/buffer/bufmgr.c#L3437
static void
FlushBuffer(BufferDesc *buf, SMgrRelation reln, IOObject io_object,
IOContext io_context)
{
// 3. Flush change to WAL
if (buf_state & BM_PERMANENT)
XLogFlush(recptr);
// Flush changes to table file
smgrwrite(reln,
BufTagGetForkNum(&buf->tag),
buf->tag.blockNum,
bufToWrite,
false);
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/include/storage/smgr.h#L121
static inline void
smgrwrite(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum,
const void *buffer, bool skipFsync)
{
smgrwritev(reln, forknum, blocknum, &buffer, 1, skipFsync);
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/backend/storage/smgr/smgr.c#L631
void
smgrwritev(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum,
const void **buffers, BlockNumber nblocks, bool skipFsync)
{
smgrsw[reln->smgr_which].smgr_writev(reln, forknum, blocknum,
buffers, nblocks, skipFsync);
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/backend/storage/smgr/md.c#L928
void
mdwritev(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum,
const void **buffers, BlockNumber nblocks, bool skipFsync)
{
// 5. Write data to table file
while (/* Have more data blocks */)
{
FileWriteV(v->mdfd_vfd, iov, iovcnt, seekpos,
WAIT_EVENT_DATA_FILE_WRITE);
}
// 6. Flush data to disk
register_dirty_segment(reln, forknum, v);
}
// https://github.com/postgres/postgres/blob/6b41ef03306f50602f68593d562cd73d5e39a9b9/src/backend/storage/file/fd.c#L2192
ssize_t
FileWriteV(File file, const struct iovec *iov, int iovcnt, off_t offset,
uint32 wait_event_info)
{
// Perform write directly
returnCode = pg_pwritev(vfdP->fd, iov, iovcnt, offset);
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/backend/storage/smgr/md.c#L1353
static void
register_dirty_segment(SMgrRelation reln, ForkNumber forknum, MdfdVec *seg)
{
if (/* Failed to ask checkpointer to perform fsync */)
{
// Perform fsync directly
FileSync(seg->mdfd_vfd, WAIT_EVENT_DATA_FILE_SYNC);
}
}
// https://github.com/postgres/postgres/blob/c20d90a41ca869f9c6dd4058ad1c7f5c9ee9d912/src/backend/storage/file/fd.c#L2297
int
FileSync(File file, uint32 wait_event_info)
{
pg_fsync(VfdCache[file].fd);
}
Segmented log + Snapshot
Since we are talking about WAL, it's worth talking about pair of segmented log and snapshot. Segmented log - is a pattern of representing single "logical" log as multiple "physical" segments.
The benefit we get with this approach is significant. Earlier we have only one big file. Huge systems with highload might have this file have size of thousands TB. You might think that this is OK because we huge amount of storage, but remember that file is stored in file system that might have limit for file size.
Even if we use zfs or xfs (with file size limit of 8 exbibytes) there are engineering problems - maintaince.
But, if we split this big file into several small/medium sized files we get not only ability to grow WAL indefinitely, but also comfortable engineering experience - old WAL segments can be stored in some other place (and possible compressed).
The segmented log itself is a good tool for transactional processing (ability to rollback), but if our server works some months, then this log can become too large and starup time will become impractical (several hours). And here comes "Snapshot" - serialized application state to which WAL records applied up to certain record.
There is illustration from Raft paper that better describes relationship between these 2 components:
As a result, we have 2 "files" representing application state:
- Snapshot - file with serialized state after applying some WAL records, and
- Segmented log/WAL - multiple files representing single logical sequence of commands that must be applied to state to bring it up to date
Actual state = Snapshot + WAL records.
Finally, main magic - now we can work with both files atomically:
- To create or update snapshot - use
ACVR/ARVR - When some command comes from user - add to WAL/Segmented log (and return response)
- New WAL segments created -
ACVR
Also, when using Snapshot we actual do not need old WAL segments, because they are already applied in snapshot. If we were using not segmented log, but a monolog (came up with the name myself), then freeing up a disk space will be problematic: atomic operation will require ARVR, but for large file it will consume to much resources. As for segmented log - we can just remove some log segments (or send to another storage/archive).
Some examples:
- Postgres: WAL represented as multiple segments
- Apache Kafka: each partition consists of several segments
- etcd: data stored in snapshot and segmented WAL
- log-cabin: data stored in snapshot and segmented WAL
Actually, we can think of table files in Postgres in terms of Snapshot.
But in Raft snapshot is immutable and Postgres performs changes on such "snapshot" directly.
Such approach for the organization of data storage has advantages:
- Fault-tolerant update of application state: fault-tolerant WAL write and snapshot updates
- Increase data update speed: response right after WAL saved record + data locality and sequential access when writing to WAL
- Replication is more effective: streaming replication of state (just send WAL records sequentially) and/or send immutable snapshot
- Application startup speed increases: we need to deserialize application state and apply some records from WAL (instead of applying all records for all time, without snapshot)
Conclusion
In this blog-post we went through the main layers that write request passes. But some topics are not covered:
- Network file systems
- More deep description of storage devices
- Architecture and implementation of different file systems
- Comparison of file systems
- Ephemeral file systems (i.e. OverlayFS used in Docker)
- Cross-platform
- Bugs in implementation of each layer
- Behaviours in emulators/virtual machines
Hope this article was useful. Bye!