
Some tips regarding using notebooks in watsonx.ai studio!

Introduction
Recently one of my partner saw my LinkedIn post regarding an article I amplified “Automate document analysis with highly intelligent agents” written by Aakriti Aggarwal.
The question was simple: how to use the following sample (an implementation of Docling capacities within an AI Agent built with CrewAI) docling_crewai.ipynb not in a local notebook, but on IBM Cloud using watsonx.ai studio?
Q/As…
Hereafter the list of questions and answers provided. As a heads-up, this is a work on some testing the concepts, not implementing a production application!
To begin, this is the original notebook’s code ⬇️
from crewai import LLM, Agent, Task, Crew, Process
from IPython.display import Markdown
from crewai.knowledge.source.crew_docling_source import CrewDoclingSource
from dotenv import load_dotenv
from composio_crewai import Action, App, ComposioToolSet
from typing import Dict
from pydantic import BaseModel, Field
load_dotenv()
True
import os
print("Current working directory:", os.getcwd())
import os
file_path = os.path.abspath("nda.txt")
print(file_path)
# Initialize knowledge source
content_source = CrewDoclingSource(
file_paths=["..."]
)
# LLM setup
WATSONX_MODEL_ID = "watsonx/meta-llama/llama-3-8b-instruct"
parameters = {
"decoding_method": "sample",
"max_new_tokens": 1000,
"temperature": 0.7,
"top_k": 50,
"top_p": 1,
"repetition_penalty": 1
}
llm = LLM(
model=WATSONX_MODEL_ID,
parameters=parameters,
max_tokens=1000,
temperature=0
)
# Toolset initialization
tool_set = ComposioToolSet()
rag_tools = tool_set.get_tools(
apps=[App.RAGTOOL],
actions=[
Action.FILETOOL_LIST_FILES,
Action.FILETOOL_CHANGE_WORKING_DIRECTORY,
Action.FILETOOL_FIND_FILE,
]
)
rag_query_tools = tool_set.get_tools(apps=[App.RAGTOOL])
[2025-01-11 17:49:26,071][INFO] Actions cache is outdated, refreshing cache...
# Pydantic models for output
class AgentOutput(BaseModel):
"""Output of each clause agent"""
analysis: str = Field(description="An analysis of the section in laymen terms")
recommendation: str = Field(
description="How the current clause deviates from the benchmark documents"
)
class FinalOutput(BaseModel):
data: Dict[str, AgentOutput]
# Agents
corporate_lawyer_agent = Agent(
role="Corporate Lawyer",
goal="Ingest NDAs and build a robust knowledge base for comparing NDA clauses.",
backstory="""You are a seasoned corporate lawyer specializing in NDAs. Your expertise lies in identifying best practices
and deviations across various clauses. You have access to tools to ingest and query relevant documents.""",
# tools=rag_tools,
verbose=True,
llm=llm,
)
clause_analysis_agent = Agent(
role="Clause Analysis Specialist",
goal="Analyze and evaluate NDA clauses against benchmark documents.",
backstory="""You are an expert in evaluating NDA clauses, ensuring they align with legal best practices.
Your attention to detail allows you to identify gaps and improvements across all key sections of NDAs.""",
# tools=rag_query_tools,
verbose=True,
llm=llm,
)
# Task templates
EXPECTED_TASK_OUTPUT = """
A JSON that has two keys: an `analysis` of the current clause in laymen terms as a paragraph as well as a `recommendation` of how the current clause deviates from the benchmark clauses (in short, numbered points)."""
def create_accumulating_task(original_task, key):
def accumulating_task(agent, context):
result = original_task.function(agent, context)
if "accumulated_results" not in context:
context["accumulated_results"] = {}
context["accumulated_results"][key] = result
return context["accumulated_results"]
return Task(
description=original_task.description,
agent=original_task.agent,
function=accumulating_task,
expected_output=original_task.expected_output,
output_pydantic=original_task.output_pydantic,
context=original_task.context,
)
def get_tasks(input_document):
tasks = []
# Task: Ingest benchmark NDAs
ingest_documents_task = Task(
description="""Ingest benchmark NDAs for comparison. Check all files in the 'ndas' folder
with 'docx', 'doc', or 'pdf' extensions and ingest them using the RAG tool.""",
expected_output=EXPECTED_TASK_OUTPUT,
agent=corporate_lawyer_agent,
)
tasks.append(create_accumulating_task(ingest_documents_task, "ingest_documents"))
# General clause analysis task
clauses = [
("Parties Clause", "identify_parties"),
("Obligations of Receiving Party", "obligations"),
("Terms and Termination", "terms_and_termination"),
("Remedies Clause", "remedies"),
("Additional Information", "additional_info"),
]
for clause_name, key in clauses:
task = Task(
description=f"""Analyze the {clause_name} in the document: `{input_document}`.
Compare it to similar clauses in our database and identify how well it aligns with legal best practices.""",
expected_output=EXPECTED_TASK_OUTPUT,
agent=clause_analysis_agent,
output_pydantic=AgentOutput,
)
tasks.append(create_accumulating_task(task, key))
return tasks
# Crew setup
def get_crew(input_doc):
crew = Crew(
agents=[corporate_lawyer_agent, clause_analysis_agent],
tasks=get_tasks(input_doc),
knowledge_sources=[content_source],
process=Process.sequential,
verbose=True,
)
return crew
# Function to execute the crew and get results
def get_agent_output(document):
crew = get_crew(document)
result = crew.kickoff()
if isinstance(result, dict) and "accumulated_results" in result:
return result["accumulated_results"]
else:
return {"final_recommendation": result}
result = get_agent_output("https://docs.google.com/document/d/117dEIoTJQEEQlrBHPYBiG3ZqjEmL_HFd/edit?usp=sharing&ouid=110583291928749264455&rtpof=true&sd=true")
print(result)
from IPython.display import Markdown
result_str = str(result['final_recommendation'])
Markdown(result_str)
{ "analysis": "The Additional Information clause in the provided NDA document lacks specifics regarding the confidentiality obligation, fails to define critical terms, and does not address the method of data destruction or return of intellectual property upon termination. It also neglects to detail the procedure for dealing with potential disputes, breaches, or disagreements between parties. The clause should be revised to provide clear guidelines for handling sensitive information, defining key terms, and outlining procedures for data destruction, return of intellectual property, and dispute resolution.", "recommendation": [ 1. "Specify the method and scope of data destruction or return of intellectual property upon termination to ensure compliance with confidentiality obligations and avoid potential disputes.", 2. "Define critical terms such as 'Confidential Information' and 'Intellectual Property' to establish a clear understanding of what is protected.", 3. "Outline procedures for dealing with potential disputes, breaches, or disagreements between parties, including methods for notification, resolution, and conflict resolution.", 4. "Establish consequences for failure to comply with confidentiality obligations, including damages or legal action, to strengthen the clause's effectiveness.", 5. "Address the method of notice delivery to ensure receipt and proof of delivery in relation to termination or dispute resolution." ] }- How use environment variables in a Jupyter Notebook?
WATSONX_URL="https://us-south.ml.cloud.ibm.com"
WATSONX_APIKEY="XXXXX"
WATSONX_PROJECT_ID="XXXX"
SERPER_API_KEY="XXXX"
WATSONX_MODEL_ID="watsonx/meta-llama/llama-3-8b-instruct"
COMPOSIO_API_KEY="XXXX"
os.environ["WATSONX_URL"] = WATSONX_URL
os.environ["WATSONX_APIKEY"] = WATSONX_APIKEY
os.environ["WATSONX_PROJECT_ID"] = WATSONX_PROJECT_ID
os.environ["SERPER_API_KEY"] = SERPER_API_KEY
os.environ["WATSONX_MODEL_ID"] = WATSONX_MODEL_ID
os.environ["COMPOSIO_API_KEY"] = COMPOSIO_API_KEYThis way you can bypass the “load_dotenv()” and test any variable live in your notebook.
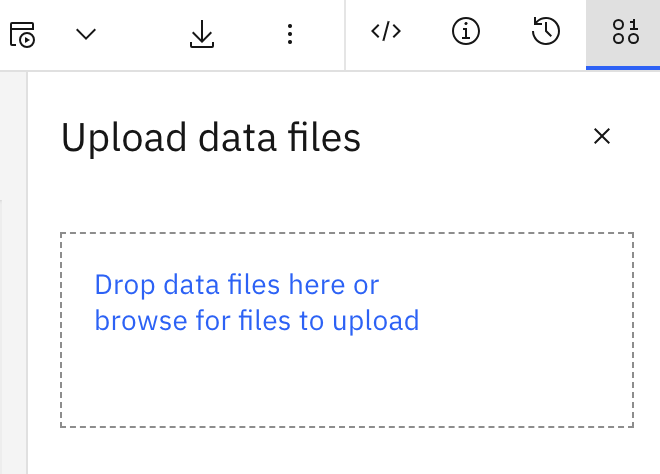
- In the sample provided, a file is used containing sample data. How use it on a cloud environment (original code excerpt provided below)?
import os
file_path = os.path.abspath("nda.txt")
print(file_path)Quite easily 😉, when you are in edit mode inside the notebook, click on the far right button.

Upload your data file.
# Read the content of nda.txt
try:
import os, types
import pandas as pd
from botocore.client import Config
import ibm_boto3
def __iter__(self): return 0
# @hidden_cell
# The following code accesses a file in your IBM Cloud Object Storage. It includes your credentials.
# You might want to remove those credentials before you share the notebook.
cos_client = ibm_boto3.client(service_name='s3',
ibm_api_key_id='api-generated',
ibm_auth_endpoint="https://iam.cloud.ibm.com/identity/token",
config=Config(signature_version='oauth'),
endpoint_url='https://s3.direct.us-south.cloud-object-storage.appdomain.cloud')
bucket = 'your-bucket-referenced-here'
object_key = 'nda__da__crxq8b2hmy.txt'
# load data of type "text/plain" into a botocore.response.StreamingBody object.
# Please read the documentation of ibm_boto3 and pandas to learn more about the possibilities to load the data.
# ibm_boto3 documentation: https://ibm.github.io/ibm-cos-sdk-python/
# pandas documentation: http://pandas.pydata.org/
streaming_body_1 = cos_client.get_object(Bucket=bucket, Key=object_key)['Body']
with open("nda.txt", "r") as f:
nda_content = f.read()
print("Content of nda.txt has been read.")
except FileNotFoundError:
print("Error: nda.txt not found in the current directory.")
nda_content = ""
# Initialize knowledge source
content_source = CrewDoclingSource(
file_paths=["..."]
)That’s all folks ✌, hope this is helpful.
Last words
watsonx.ai studio provides all needed elements to manage the full model and application process.
No need to scramble to pull together what you need for model training and generative AI development. Access a variety of powerful, low-cost, fit-for-purpose models, MLOps pipelines and AI runtimes that reside in one place for more efficient building of powerful applications with trusted data and built-in governance that you can effectively manage, monitor and govern across the AI lifecycle.
Links
watsonx.ai studio: https://eu-de.dataplatform.cloud.ibm.com/registration/stepone?context=wx&preselect_region=true
watsonx.ai LLMs and foundation models: https://www.ibm.com/products/watsonx-ai/info/trial