

If your team is managing large volumes of historical data using platforms like Snowflake, Amazon Redshift, or Google BigQuery, you’ve probably noticed a shift happening in the data engineering world. A new generation of data infrastructure is forming — one that prioritizes openness, interoperability, and cost-efficiency. At the center of that shift is Apache Iceberg.
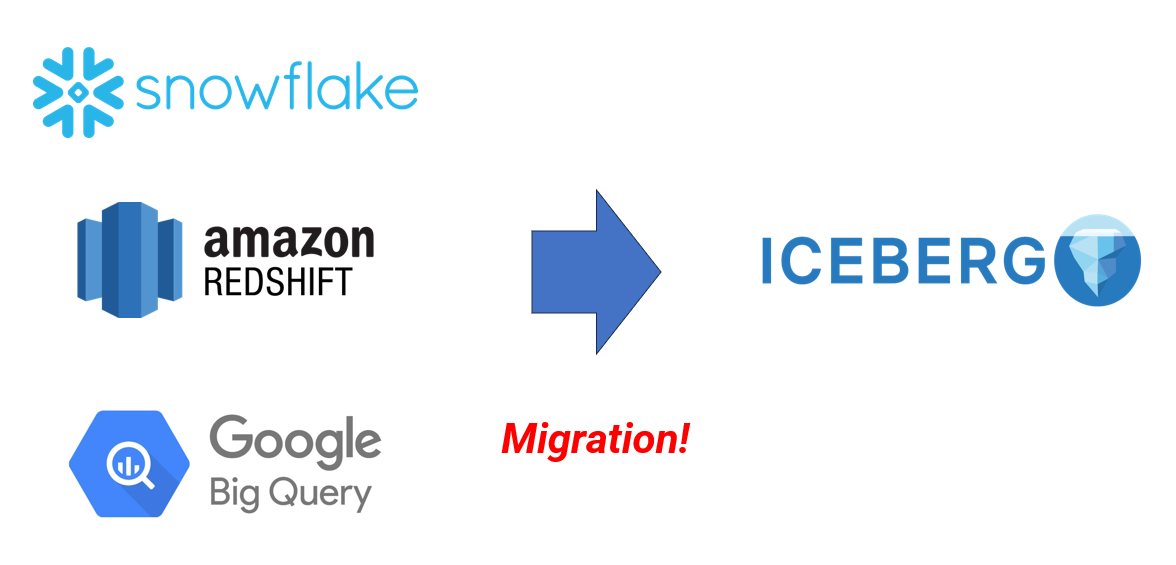
Iceberg has quietly become the foundation of the modern data lakehouse. More and more engineering teams are adopting it to store and manage analytical data in cloud storage — like Amazon S3, Google Cloud Storage, or Azure Data Lake Storage — while freeing themselves from the limitations of closed systems.
If you’re curious whether your team should join them, this guide will help you frame the conversation with your boss.
Why Apache Iceberg Deserves a Seat at the Table
Let’s start from the basics. Apache Iceberg is an open table format built for high-performance, petabyte-scale analytics on cloud object stores like S3 and GCS. Traditionally, table formats have been something only backend teams worry about.
That’s no longer the case.
Choosing Iceberg isn’t just a technical decision — it’s a strategic one. It impacts not just your engineering team but your entire organization. Here’s why.
No Vendor Lock-In
Iceberg decouples storage from compute. That means your data isn’t trapped inside one proprietary system. Instead, it lives in open file formats (like Apache Parquet) and is managed by an open, vendor-neutral metadata layer (Apache Iceberg).
Want to use Snowflake today and switch to Trino tomorrow? Prefer to experiment with a free tool like DuckDB for smaller tasks? Iceberg supports it all.
In the past, migrating platforms was a major engineering lift — often involving data duplication, reprocessing, and long-term lock-in. With Iceberg, switching compute engines becomes a configuration change, not a months-long migration project.
This gives your organization long-term strategic flexibility, something that’s increasingly important as cloud costs rise and workloads diversify.
Mix and Match Compute Engines
Different workloads need different tools.
- Your analytics team might prefer Snowflake for its mature BI integrations.
- Data scientists might want to use Python notebooks with DuckDB or Spark.
- Real-time pipelines might need RisingWave or Apache Kafka.
Iceberg allows multiple engines to read and write to the same table, with full isolation and transactional guarantees. You can adopt best-of-breed tools for each use case without duplicating data.
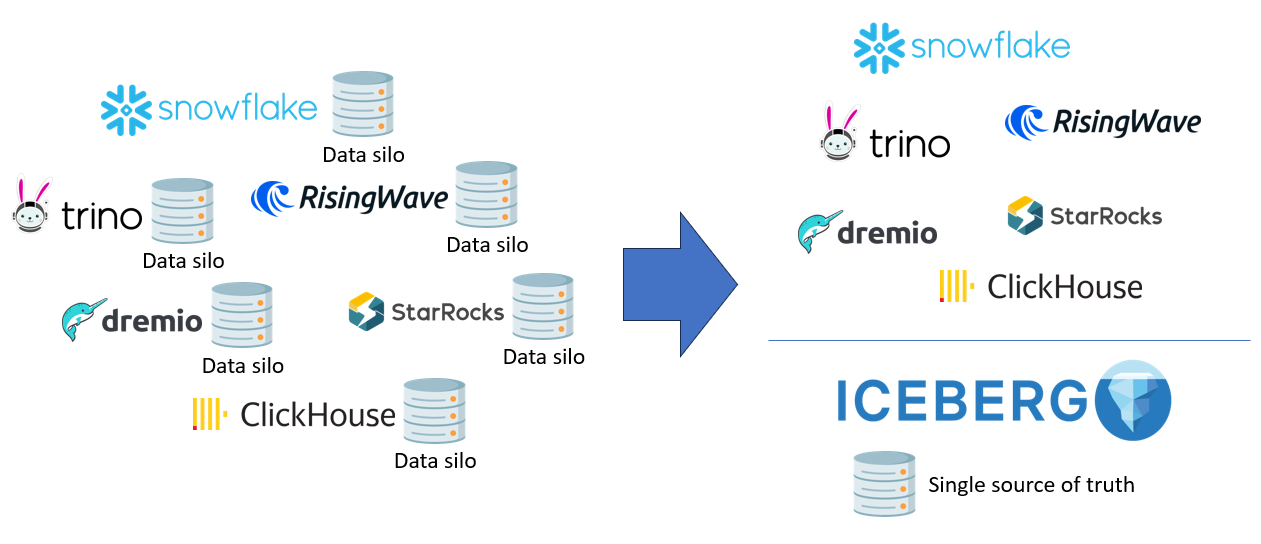
For example, one of our users still runs their core dashboards on Snowflake but uses DuckDB for lightweight analysis on snapshots of historical data. This saves them both time and money — DuckDB runs locally with no infrastructure overhead.
Iceberg doesn’t replace your favorite engine — it amplifies its capabilities by giving you an open, flexible storage foundation.
Powerful Language Interoperability
In traditional data warehouses, you’re usually limited to SQL. That’s fine for dashboards, but it’s a poor fit for modern machine learning and data scienceworkflows, which rely heavily on Python and pandas.
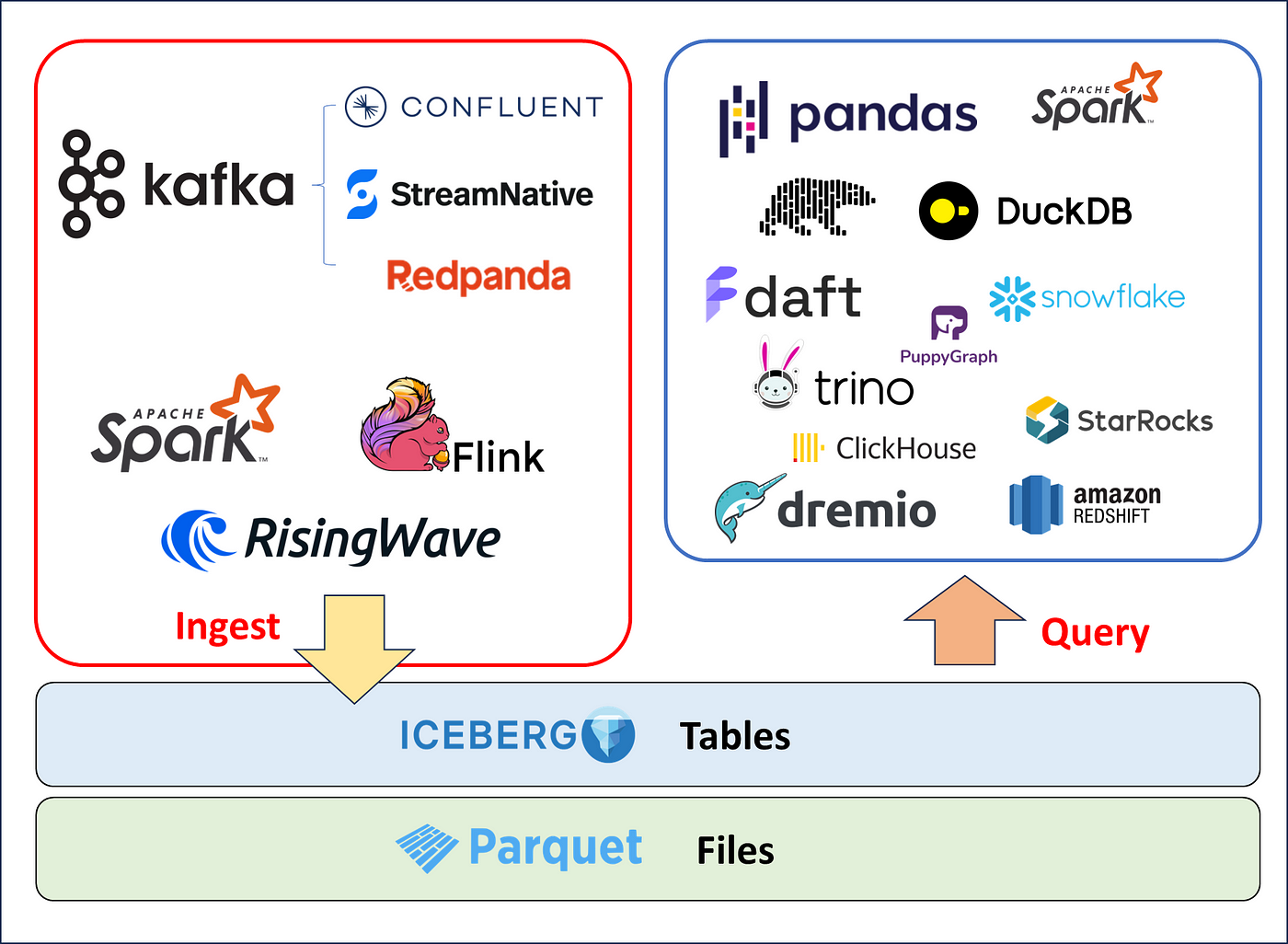
Iceberg solves this by offering multi-language access to the same dataset. Your analytics engineers can query Iceberg with Trino or Spark SQL. Your ML engineers can load the exact same table using Python libraries and work in their Jupyter notebooks.
This lowers team friction and eliminates the need for brittle data exports or duplication. Everyone — regardless of their preferred language or tool — gets consistent, governed access to the data they need.
What Types of Teams Are Already Using Iceberg?
We’ve worked with dozens of organizations on their journey to Iceberg. Most fall into one of four categories:
1. Snowflake Customers Looking to Cut Costs
This is one of the most common motivations we see. Snowflake is a powerful platform, but costs can scale quickly — especially with long-term storage and frequent queries on cold data.
Some teams are offloading their cold and historical data to Iceberg tables on cloud storage. Then, they use DuckDB or Trino to query that data at a fraction of the cost. This doesn’t replace Snowflake entirely — it complements it, reducing usage and helping teams hit budget goals.
In larger enterprises, adopting Iceberg also becomes a strategic bargaining chip. When procurement time rolls around, being able to say, “We can move to Iceberg,” gives teams leverage in contract negotiations.
2. Hive Users Modernizing Their Stack
Organizations that built their data lakes on Apache Hive in the Hadoop era are now facing a critical decision. Hive is outdated — slow, rigid, and difficult to manage. But Iceberg offers a smooth migration path forward.
Why Iceberg?
- ACID transactions remove the need for fragile job orchestration.
- Time travel and versioning support advanced auditing and debugging.
- Schema evolution allows teams to change their data models without downtime.
- GDPR compliance becomes much easier with transactional deletes.
Iceberg is the natural successor if your team wants to sunset Hive and move to a modern, cloud-native architecture.
3. Enterprises Building Greenfield Platforms
Some companies aren’t migrating from anything — they’re building something entirely new. These forward-looking teams want a future-proof, open foundation for their data strategy.
They might already use Snowflake, Redshift, or BigQuery for other workloads, but for their next-gen platform, they’re choosing Iceberg. Why? Because they want:
- Full control over storage
- Easy integration with multiple compute layers
- Freedom to scale without rewriting everything down the line
These enterprises are investing in data mesh architectures, real-time pipelines, and multi-cloud strategies, all of which benefit from the open nature of Iceberg.
4. Startups Choosing Iceberg as Their First Data Warehouse
Even small teams are getting in on the action.
Startups often face a tough decision: invest heavily in a warehouse like Snowflake, or stitch together a homegrown system using S3 and SQL engines. Iceberg gives them a middle path — a modern, scalable format with support from the open-source and cloud ecosystem.
These startups:
- Start with simple ingestion pipelines into Iceberg tables
- Use DuckDB or Trino for analysis
- Scale to Spark as data grows
- Avoid vendor lock-in from day one
The result is a lean, flexible architecture that scales as the business grows — without racking up sky-high bills.
How to Pitch Iceberg to Your Boss
You’re convinced. But how do you bring your boss — and your team — on board?
Try framing your pitch in terms of the outcomes they care about:
- For your CFO:“We can cut down Snowflake spend by offloading cold data to S3 and querying it using DuckDB or Trino.”
- For your CTO:“Iceberg gives us architectural flexibility — we can evolve our stack over time without reprocessing data.”
- For your head of data science:“Iceberg allows Python-based access to the same tables used in BI — no more messy exports or data inconsistencies.”
- For your platform team:“Iceberg works with our current tools. We can start small and scale incrementally, without a full replatform.”
Final Thoughts
Adopting Apache Iceberg isn’t just a technology decision — it’s a strategic move toward a more flexible, efficient, and future-proof data platform.
It opens the door to multi-engine analytics, cost optimization, and AI readiness. It gives you leverage over closed platforms and helps your team stay agile in a fast-changing data landscape.
So next time someone asks, “Why Iceberg?” you’ll know exactly what to say.
