This blog was initially posted to Crawlbase Blog
When planning trips, most travellers turn to Google to find hotels. The platform shows hotel listings, prices, reviews, and availability all in one place. For businesses, analysts, or travel platforms, this data is gold. Scraping Google Hotels can help you track pricing trends, monitor competitors, and analyze market opportunities in the travel industry.
In this guide, we’ll show you how to scrape Google Hotels using Python and the Crawlbase Crawling API. With this method, you can collect hotel data at scale without worrying about blocks, CAPTCHAs, or IP bans. We’ll cover everything from setting up your environment to writing a complete scraper for hotel listings and individual hotel pages.
Let’s start.
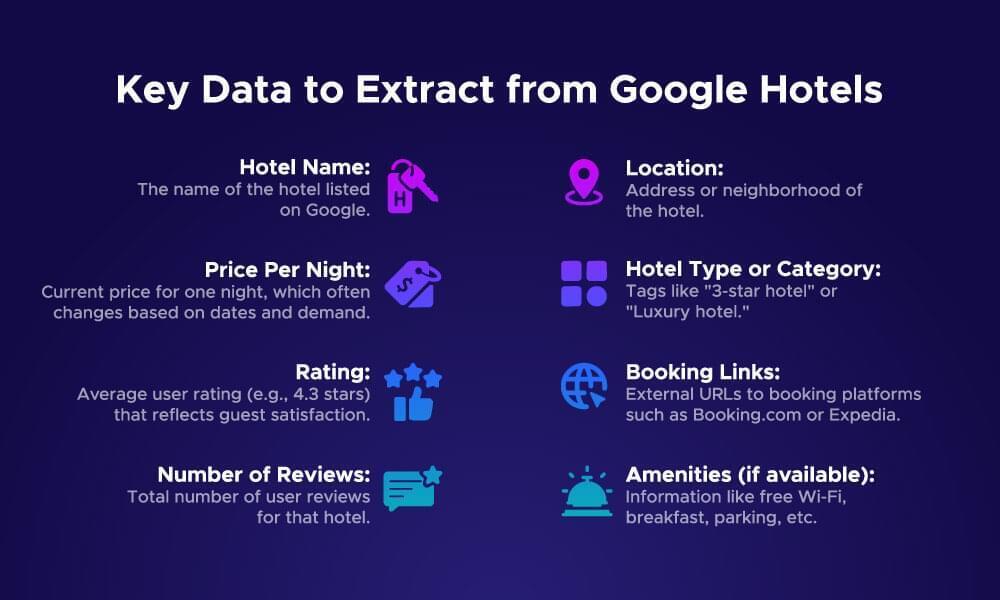
Key Data to Extract from Google Hotels
When scraping Google Hotels, it’s important to know which data points matter most. These details are useful for price monitoring, competitive analysis, and building travel tools.
The image below shows some of the most valuable fields you can extract:
Setting Up Your Python Environment
Before scraping Google Hotels, you need to prepare your Python environment. This includes installing Python itself and a few essential libraries for sending requests and extracting data.
🐍 Install Python
If you haven’t installed Python yet, download and install the latest version from the official Python website. During installation, make sure to check the box that says "Add Python to PATH" — this will let you run Python from the command line.
To check if Python is installed, run this in your terminal or command prompt:
python --versionYou should see the installed version number.
✅ Install Required Libraries
To scrape Google Hotels, we’ll use:
-
carwlbase– to send HTTP requests use Crawlbase Crawling API. -
beautifulsoup4– to parse and extract content from HTML.
Install them using pip:
pip install requests
pip install beautifulsoup4📝 Create Your Python File
Create new files where you’ll write your scraping code, for example:
touch google_hotels_listing_scraper.py
touch google_hotel_details_scraper.pyOr just create them manually in your preferred code editor.
🔑 Get Your Crawlbase Token
If you haven’t already, sign up at Crawlbase and get your API token. You’ll need this token to authenticate your scraping requests.
from crawlbase import CrawlingAPI
# Replace CRAWLBSE_JS_TOKEN with your actual token.
crawling_api = CrawlingAPI({ 'token': 'CRAWLBASE_JS_TOKEN' })Note: Crawlbase provides two types of tokens. A normal token for static sites and a JS Token for JS-rendered sites. For Google Hotels scraping, we need a JS token. See the documentation for more.
Now, your setup is complete. Next, we’ll inspect the HTML structure of Google Hotels and start writing the scraper.
Scraping Google Hotels Search Results
In this section, we’ll scrape hotel listings from Google Hotels using Python, BeautifulSoup, and the Crawlbase Crawling API. You’ll learn how to extract hotel details, handle pagination, and save data into a JSON file.
🧩 Inspecting the HTML for Selectors
First, open Google Hotels in your browser, search a location (e.g., “New York”), and inspect the page.
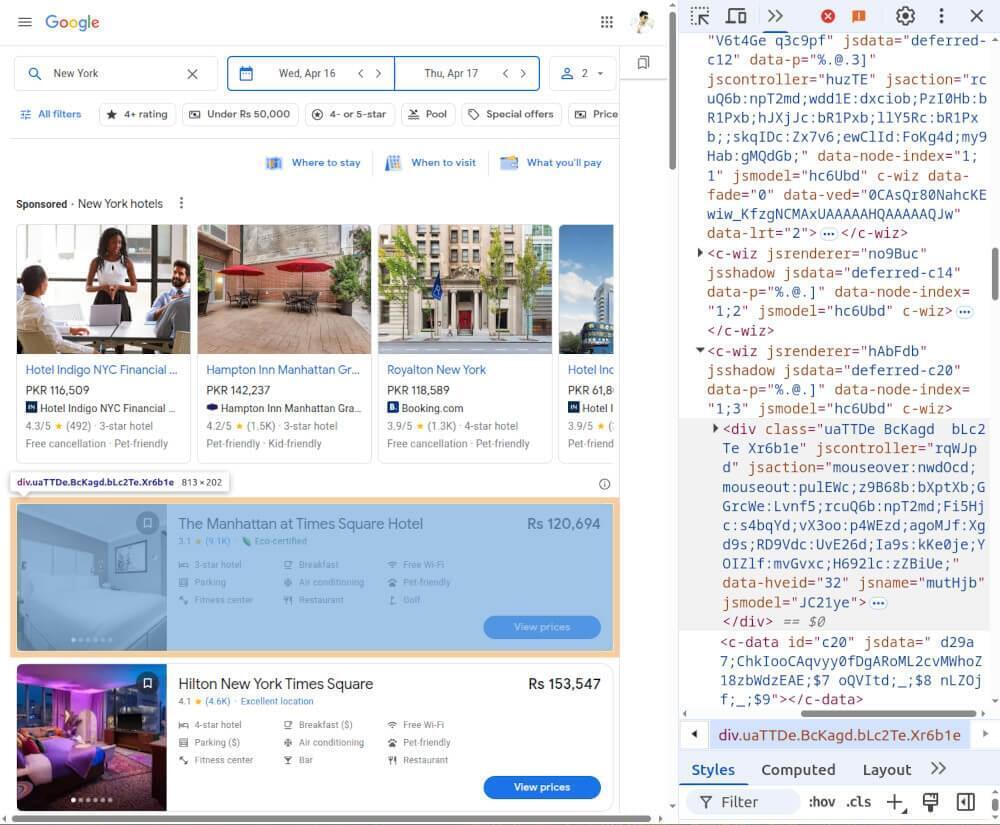
Here are some key CSS classes used in the hotel listings:
- Hotel card:
div.BcKagd - Hotel name:
h2.BgYkof - Price:
span.qQOQpe.prxS3d - Rating:
span.KFi5wf.lA0BZ
We’ll use these selectors in our scraper.
🧪 Writing the Hotels Listings Scraper
Now, let’s write a function to extract hotel data using Crawlbase and BeautifulSoup.
from crawlbase import CrawlingAPI
from bs4 import BeautifulSoup
import json
crawling_api = CrawlingAPI({ 'token': 'CRAWLBASE_JS_TOKEN' })
def make_crawlbase_request(url):
response = crawling_api.get(url)
if response['headers']['pc_status'] == '200':
return response['body'].decode('utf-8')
return None
def parse_hotel_listings(html):
soup = BeautifulSoup(html, "html.parser")
hotel_data = []
hotels = soup.find_all("div", class_="BcKagd")
for hotel in hotels:
name = hotel.find("h2", class_="BgYkof")
price = hotel.find("span", class_="qQOQpe prxS3d")
rating = hotel.find("span", class_="KFi5wf lA0BZ")
link = hotel.find("a", class_="PVOOXe")
hotel_data.append({
"name": name.text if name else "N/A",
"price": price.text if price else "N/A",
"rating": rating.text if rating else "N/A",
"link": "https://www.google.com" + link["href"] if link else "N/A"
})
return hotel_data🔁 Handling Pagination
Google Hotels loads more results across multiple pages. Using the Crawlbase Crawling API, we can simulate button clicks with the css_click_selector parameter. We can also use the ajax_wait parameter to make sure the content is fully loaded after the click. This ensures the Crawling API returns the full HTML of the next page after the button is clicked and the content is rendered.
Let’s update our make_crawlbase_request function to include these parameters and add exception handling for better reliability:
def make_crawlbase_request(url, css_click_element=None):
try:
options = {}
if css_click_element:
options['css_click_selector'] = css_click_element
options['ajax_wait'] = 'true'
response = crawling_api.get(url, options)
if response['headers'].get('pc_status') == '200':
return response['body'].decode('utf-8')
return response
except Exception as e:
print(f"Error during Crawlbase request: {e}")
return {}💾 Saving Data in a JSON File
Once you’ve collected all the hotel data, save it to a JSON file:
def save_to_json(data, filename="google_hotels.json"):
with open(filename, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)✅ Complete Code Example
Here is the complete code that combines all the steps above:
from crawlbase import CrawlingAPI
from bs4 import BeautifulSoup
import json
crawling_api = CrawlingAPI({ 'token': 'CRAWLBASE_JS_TOKEN' })
def make_crawlbase_request(url, css_click_element=None):
try:
options = {}
if css_click_element:
options['css_click_selector'] = css_click_element
options['ajax_wait'] = 'true'
response = crawling_api.get(url, options)
if response['headers'].get('pc_status') == '200':
return response['body'].decode('utf-8')
return response
except Exception as e:
print(f"Error during Crawlbase request: {e}")
return {}
def parse_hotel_listings(html):
soup = BeautifulSoup(html, "html.parser")
hotel_data = []
hotels = soup.find_all("div", class_="BcKagd")
for hotel in hotels:
name = hotel.find("h2", class_="BgYkof")
price = hotel.find("span", class_="qQOQpe prxS3d")
rating = hotel.find("span", class_="KFi5wf lA0BZ")
link = hotel.find("a", class_="PVOOXe")
hotel_data.append({
"name": name.text if name else "N/A",
"price": price.text if price else "N/A",
"rating": rating.text if rating else "N/A",
"link": "https://www.google.com" + link["href"] if link else "N/A"
})
return hotel_data
def save_to_json(data, filename="google_hotels.json"):
with open(filename, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
def main():
url = "https://www.google.com/travel/hotels/New-York?q=New+York¤cy=USD"
all_hotels = []
max_pages = 2
page_count = 0
while page_count < max_pages:
html = ''
if page_count == 0:
# For 1st page
html = make_crawlbase_request(url)
else:
# For next pages
html = make_crawlbase_request(url, 'button[jsname="OCpkoe"]')
if not html:
break
hotels = parse_hotel_listings(html)
all_hotels.extend(hotels)
page_count += 1
save_to_json(all_hotels)
print(f"Scraped {len(all_hotels)} hotels and saved to google_hotels.json")
if __name__ == "__main__":
main()Example Output:
[
{
"name": "31 Street Broadway Hotel",
"price": "$59",
"rating": "2.5",
"link": "https://www.google.com/travel/search?q=New%20York&qs=MihDaG9JeFBLSXpvWDR6SWZMQVJvTkwyY3ZNVEZ3ZDJnMU4yYzFOUkFCOAA¤cy=USD&ved=2ahUKEwiY1rucg9CMAxUIAPkAHXyaE5EQyvcEegQIAxA-&ap=KigKEgm4tF8JXhxEQBF5jsg3iI5SwBISCfZ7hYTLm0RAEXmOyLfKcVLA&ts=CAESCgoCCAMKAggDEAAaXAo-EjwKCS9tLzAyXzI4NjIlMHg4OWMyNGZhNWQzM2YwODNiOjB4YzgwYjhmMDZlMTc3ZmU2MjoITmV3IFlvcmsSGhIUCgcI6Q8QBBgQEgcI6Q8QBBgRGAEyAhAAKgcKBToDVVNE"
},
{
"name": "The One Boutique Hotel",
"price": "$90",
"rating": "3.3",
"link": "https://www.google.com/travel/search?q=New%20York&qs=MidDaGtJZ0t6dDBjdkZ6dG1jQVJvTUwyY3ZNWEUxWW14eWF6a3pFQUU4AA¤cy=USD&ved=2ahUKEwiY1rucg9CMAxUIAPkAHXyaE5EQyvcEegQIAxBV&ap=KigKEgm4tF8JXhxEQBF5jsg3iI5SwBISCfZ7hYTLm0RAEXmOyLfKcVLA&ts=CAESCgoCCAMKAggDEAAaXAo-EjwKCS9tLzAyXzI4NjIlMHg4OWMyNGZhNWQzM2YwODNiOjB4YzgwYjhmMDZlMTc3ZmU2MjoITmV3IFlvcmsSGhIUCgcI6Q8QBBgQEgcI6Q8QBBgRGAEyAhAAKgcKBToDVVNE"
},
{
"name": "Ly New York Hotel",
"price": "$153",
"rating": "4.4",
"link": "https://www.google.com/travel/search?q=New%20York&qs=MihDaG9JbU9UeXpldUN6cnlrQVJvTkwyY3ZNVEYyY0d3MGJuSXpZaEFCOAA¤cy=USD&ved=2ahUKEwiY1rucg9CMAxUIAPkAHXyaE5EQyvcEegQIAxBu&ap=KigKEgm4tF8JXhxEQBF5jsg3iI5SwBISCfZ7hYTLm0RAEXmOyLfKcVLA&ts=CAESCgoCCAMKAggDEAAaXAo-EjwKCS9tLzAyXzI4NjIlMHg4OWMyNGZhNWQzM2YwODNiOjB4YzgwYjhmMDZlMTc3ZmU2MjoITmV3IFlvcmsSGhIUCgcI6Q8QBBgQEgcI6Q8QBBgRGAEyAhAAKgcKBToDVVNE"
},
{
"name": "King Hotel Brooklyn Sunset Park",
"price": "$75",
"rating": "3.4",
"link": "https://www.google.com/travel/search?q=New%20York&qs=MihDaG9JbllMLW1iTG5uLTNDQVJvTkwyY3ZNVEZ5ZDNKNWQyUXdiQkFCOAA¤cy=USD&ved=2ahUKEwiY1rucg9CMAxUIAPkAHXyaE5EQyvcEegUIAxCJAQ&ap=KigKEgm4tF8JXhxEQBF5jsg3iI5SwBISCfZ7hYTLm0RAEXmOyLfKcVLA&ts=CAESCgoCCAMKAggDEAAaXAo-EjwKCS9tLzAyXzI4NjIlMHg4OWMyNGZhNWQzM2YwODNiOjB4YzgwYjhmMDZlMTc3ZmU2MjoITmV3IFlvcmsSGhIUCgcI6Q8QBBgQEgcI6Q8QBBgRGAEyAhAAKgcKBToDVVNE"
},
{
"name": "Aman New York",
"price": "$2,200",
"rating": "4.4",
"link": "https://www.google.com/travel/search?q=New%20York&qs=MidDaGtJc3Q3dF80YmhzWW9ZR2cwdlp5OHhNV1kyTW1Sd2VIbHNFQUU4AA¤cy=USD&ved=2ahUKEwiY1rucg9CMAxUIAPkAHXyaE5EQyvcEegUIAxCiAQ&ap=KigKEgm4tF8JXhxEQBF5jsg3iI5SwBISCfZ7hYTLm0RAEXmOyLfKcVLA&ts=CAESCgoCCAMKAggDEAAaXAo-EjwKCS9tLzAyXzI4NjIlMHg4OWMyNGZhNWQzM2YwODNiOjB4YzgwYjhmMDZlMTc3ZmU2MjoITmV3IFlvcmsSGhIUCgcI6Q8QBBgQEgcI6Q8QBBgRGAEyAhAAKgcKBToDVVNE"
},
.... more
]