In the modern data stack, the lakehouse has emerged as a hybrid solution that combines the scalability of a data lake with the transactional power of a data warehouse. But with this convergence comes a heightened need to manage secure data responsibly - whether it’s personally identifiable information (PII), health records, or financial transactions.
In this blog, we’ll walk through how to treat secure data in a Lakehouse architecture, from ingestion and storage to governance and auditing.
What is Lakehouse?
Lakehouse is a modern data architecture that combines the best of both data lake and data warehouse. It aims to deliver the scalability and flexibility of a data lake with the reliability, performance, and governance of a warehouse. By unifying raw and structured data in one platform, lakehouses support analytics, BI, and machine learning without the need for complex ETL pipelines.
The goal is to get the benefits of both systems while simplifying data workflows. However, while powerful, it also facing challenges on query performance, governance maturity, and integration with legacy tools comparing with each of them.
Keep it secure
Convert existing data
In many data systems, certain columns contain sensitive information(user name, email, ID...)that must be handled differently to comply with privacy regulations and national security policies. To protect this data, various techniques can be applied depending on the use case.
If only specific teams (ex> research department) need access to the original values, the data can be encrypted using keys that are only shared with those teams. When the original value is not needed but uniqueness is required—for example, for joining datasets—hashing is a suitable approach. In cases where partial visibility is acceptable (ex> showing only the last four digits of a phone number), string masking can be used to obscure parts of the value while retaining some context.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, from_json, udf
from pyspark.sql.types import StructType, StringType
from cryptography.fernet import Fernet # assume using fernet for encryption
import base64
# ---------- Setup ----------
spark = SparkSession.builder.appName("SecureSample").getOrCreate()
# ---------- Sample Schema ----------
schema = StructType([
StructField("name", StringType()),
StructField("email", StringType()),
])
SECRET_KEY = b"..."
fernet = Fernet(SECRET_KEY)
def encrypt_email(email: str) -> str:
if email is None:
return None
encrypted = fernet.encrypt(email.encode())
return encrypted.decode()
encrypt_udf = udf(encrypt_email, StringType())
# ---------- Read from Kafka ----------
kafka_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "broker-server-host:9092") \
.option("subscribe", "kafka-topic-name") \
.load()
json_df = kafka_df.selectExpr("CAST(value AS STRING)") \
.select(from_json(col("value"), schema).alias("data")) \
.select("data.*")
# encrypt email column
encrypted_df = json_df \
.withColumn("email_encrypted", encrypt_udf(col("email"))) \
.drop("email")
# ... do something with encrypted data frame ...Access limitation
Fine-grained access control ensures that only authorized users can access specific data fields, rows, or columns—crucial for protecting sensitive information in a lakehouse.
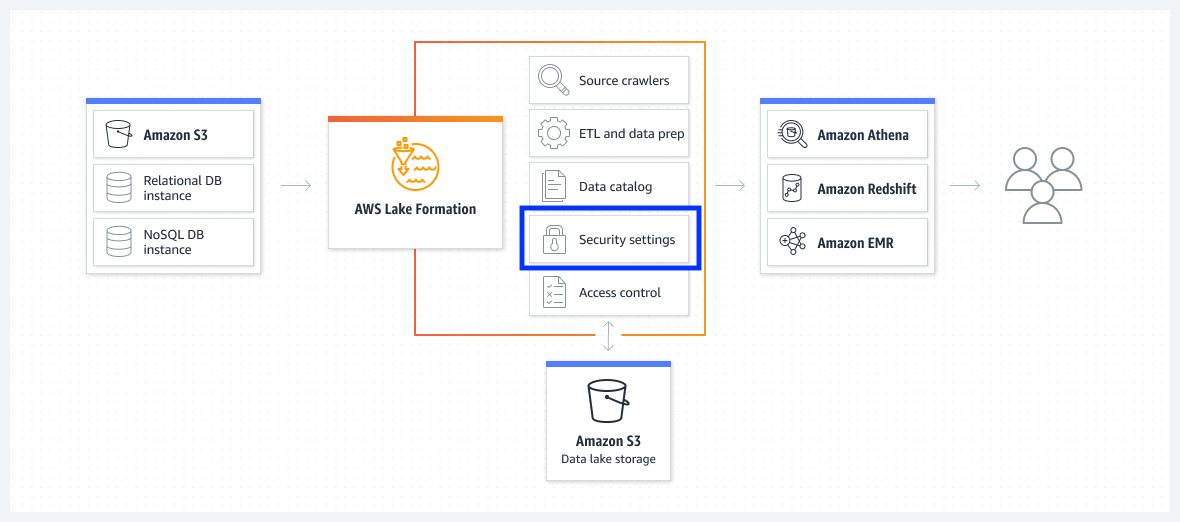
AWS offers this through Lake Formation, which allows you to define column/row level permissions on tables stored in S3. You can grant access to specific users or groups using IAM roles, and manage access using the central Lake Formation console. Integration with AWS Glue Data Catalog ensures governance across multiple tools.
GCP also provides column-level security in BigQuery, where you can restrict access to specific columns using Data Catalog tags and IAM policies. For row-level security, authorized views or row access policies can be applied to show only the data a user is allowed to see.
Both platforms support auditing, logging, and attribute-based access control (ABAC) to track and enforce data governance at scale. These features are key to meeting compliance requirements like GDPR or HIPAA while keeping analytics flexible and secure.