Large Language Models (LLMs) are everywhere now – GPT-4, Claude 3, Gemini, LLaMA, Mistral, and more. Everyone talks about which is "the best," but surprisingly, real side-by-side performance comparisons are rare. So, I built one myself.
I tested over 50 LLMs – both cloud-based and local – on my own hardware, using real-world developer tasks. And the results? Shocking.
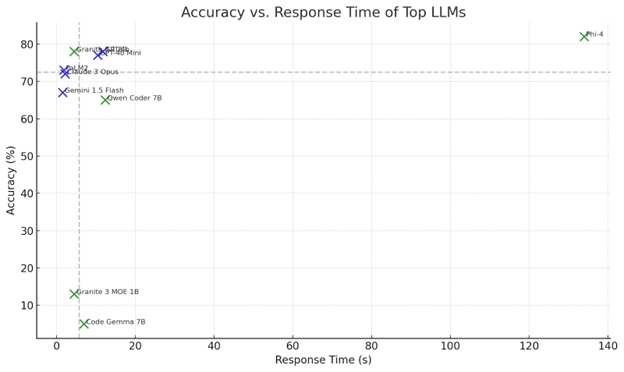
- Microsoft's Phi-4 was the most accurate model overall (yes, a local model!).
- IBM’s Granite models outperformed many of OpenAI’s most hyped offerings.
- Speed vs. accuracy is a serious tradeoff – and the best choice depends on your workflow.
Here's a breakdown of how I tested, what I found, and how you can pick the right model.
🛠️ Testing Setup
I used the Pieces C# SDK to build a test harness that could consistently run prompts across cloud and local models. Each test was repeated five times, and I averaged the results based on:
- Time to first token
- Time to complete response
- Output accuracy (measured against expected results)
My Hardware
- M3 MacBook Air (24GB RAM)
- Tested models with up to 15B parameters (anything larger couldn't run on-device)
- All cloud models supported by Pieces Copilot were included
👉 Want more details on the testing setup? Check out my long-form article on the Pieces blog.
📌 Test Scenarios
I didn’t just throw synthetic benchmarks at these models – I used actual developer tasks, simulating real-world usage. Where applicable, tasks leveraged Pieces' Long-Term Memory (LTM) for better context.
Tasks included:
- 🗂 Converting JSON into Markdown tables
- ✉️ Summarizing email chains
- 🛠 Answering GitHub issues & NuGet docs
- 📝 Suggesting code fixes in VS Code
- 🔎 Extracting insights from Reddit threads
⚡ Fastest Models
⏳ Fastest to First Token (Cloud)
🥇 Claude 3 Opus – 2.2s
🥈 Gemini 2.0 Flash – 2.4s
🥉 Gemini 1.5 Flash – 2.5s
Even the slowest cloud model (GPT-4 Chat) was only 0.9s behind Claude 3 Opus. Cloud models are clearly optimized for speed.
🚀 Fastest Local Model
🥇 Code Gemma 1.1 7B – 7s to first token
😬 Accuracy? Just 5%.
🎯 Most Accurate Models
This was unexpected.
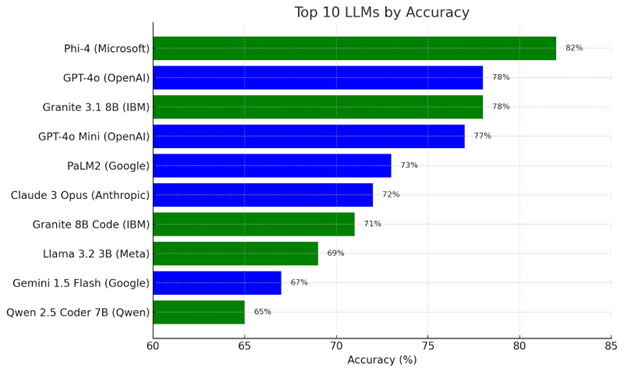
🥇 Phi-4 (Microsoft, Local) – 82% accuracy
🥈 GPT-4o (OpenAI, Cloud) – 78% accuracy
🥉 Granite 3.1 Dense 8B (IBM, Local) – 78% accuracy
Mind-blowing: The top-performing model doesn't need a cloud API or premium pricing – it's free, downloadable, and runs locally (if your hardware can handle it). Also, IBM’s Granite models beat Claude and Gemini in multiple tasks.
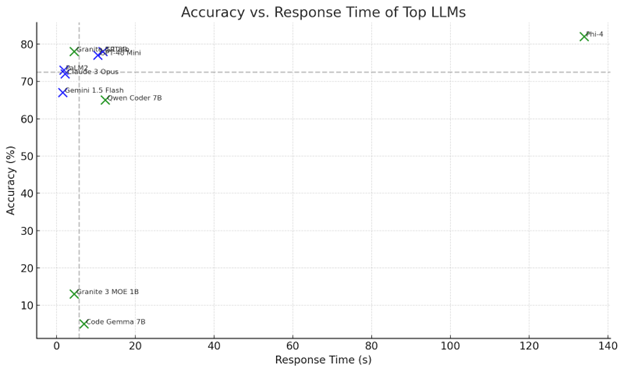
🏆 Fastest to Full Response
🥇 Gemini 1.5 Flash – 1.6s
🥈 Gemini 2.0 Flash – 1.7s
🥉 PaLM2 (deprecated) – 1.9s
For local models, Granite 3 MOE 1B was the fastest (4.5s), though accuracy was just 13%. Meanwhile, Phi-4 – the most accurate model – took 2+ minutes to generate responses. That’s the tradeoff.
🤔 Why Do LLMs Perform So Differently?
Even with the same input and context, LLMs return wildly different results. Why?
- System Prompts Matter – Some models need different prompt engineering (e.g., reasoning vs. conversational models).
- Context Window Limits – A 4K token model can't process as much as a 128K token model.
- Training Data & Architecture – Code-tuned models (e.g., Qwen Coder) behave differently from general LLMs.
- Hardware Constraints – Bigger local models hit bottlenecks on lower-end devices, forcing CPU fallback = slower output.
- Parameter Count – More parameters ≠ better, but generally lead to deeper reasoning.
🏅 Overall Winner: GPT-4o (OpenAI)
Scoring System
- 50–1 points per metric (accuracy, first token, full response)
- Accuracy weighted 2x more
🥇 GPT-4o took the crown – not the fastest, but the most balanced.
🥈 GPT-4o Mini & PaLM2 followed closely.
Biggest surprise? Google deprecated PaLM2 in October 2024, yet it still outperformed newer models. 🤷♂️
🔍 So… What Should You Use?
There’s no one-size-fits-all LLM. But here’s a cheat sheet:
| Need | Model Recommendation |
|---|---|
| Accuracy + Local Execution | 🏆 Phi-4 (if your hardware can handle it) |
| Speed + Good-enough Results | ⚡ Gemini 1.5 Flash / Claude 3 Opus |
| Balanced Performance | 🎯 GPT-4o Mini |
My Personal Picks
- Local: Granite 3.1 Dense 8B – accurate, more practical than Phi-4
- Cloud: GPT-4o Mini – fast, reliable, accurate
This content was written by Jim Bennett, head of Devrel at Pieces for Developers. You can find more interesting visualization images of the analysis like below here - https://pieces.app/blog/best-llm-models
